Esta página explica como a arquitetura do Memorystore for Redis Cluster suporta e oferece alta disponibilidade (HA). Esta página também explica as configurações recomendadas que contribuem para melhorar o desempenho e a estabilidade das instâncias.
Para mais informações sobre considerações específicas da região, consulte o artigo Geografia e regiões.
Alta disponibilidade
O Memorystore for Redis Cluster é criado numa arquitetura de elevada disponibilidade em que os seus clientes acedem diretamente às VMs do Memorystore for Redis Cluster geridas. Os seus clientes fazem isto estabelecendo ligação a endereços de rede de fragmentos individuais, conforme descrito no artigo Estabeleça ligação a uma instância do Memorystore for Redis Cluster.
A ligação direta a fragmentos oferece as seguintes vantagens:
A ligação direta evita qualquer ponto único de falha, porque cada fragmento foi concebido para falhar de forma independente. Por exemplo, se o tráfego de vários clientes sobrecarregar um espaço (parte do espaço de chaves), a falha de fragmentação limita o impacto ao fragmento responsável pela publicação do espaço.
A ligação direta evita saltos intermédios, o que minimiza o tempo de ida e volta (latência do cliente) entre o cliente e a VM do Redis.
Configurações recomendadas
Recomendamos que crie instâncias multizonais de alta disponibilidade em vez de instâncias de zona única devido à melhor fiabilidade que oferecem. No entanto, se optar por aprovisionar uma instância sem réplicas, recomendamos que escolha uma instância de zona única. Para mais informações, consulte o artigo Escolha uma instância de zona única se a sua instância não usar réplicas.
Para ativar a elevada disponibilidade da sua instância, tem de aprovisionar, pelo menos, 1 nó de réplica para cada fragmento. Pode fazê-lo quando criar a instância ou dimensionar o número de réplicas para, pelo menos, 1 réplica por fragmento. As réplicas oferecem comutação por falha automática durante a manutenção planeada e a falha inesperada de fragmentos.
Deve configurar o seu cliente de acordo com as orientações nas práticas recomendadas do cliente Redis. A utilização das práticas recomendadas permite que o seu cliente Redis de OSS processe automaticamente e sem problemas a função (failovers automáticos) e as alterações de atribuição de slots (substituição de nós, escalabilidade horizontal/vertical de consumidores) para o seu cluster sem tempo de inatividade.
Réplicas
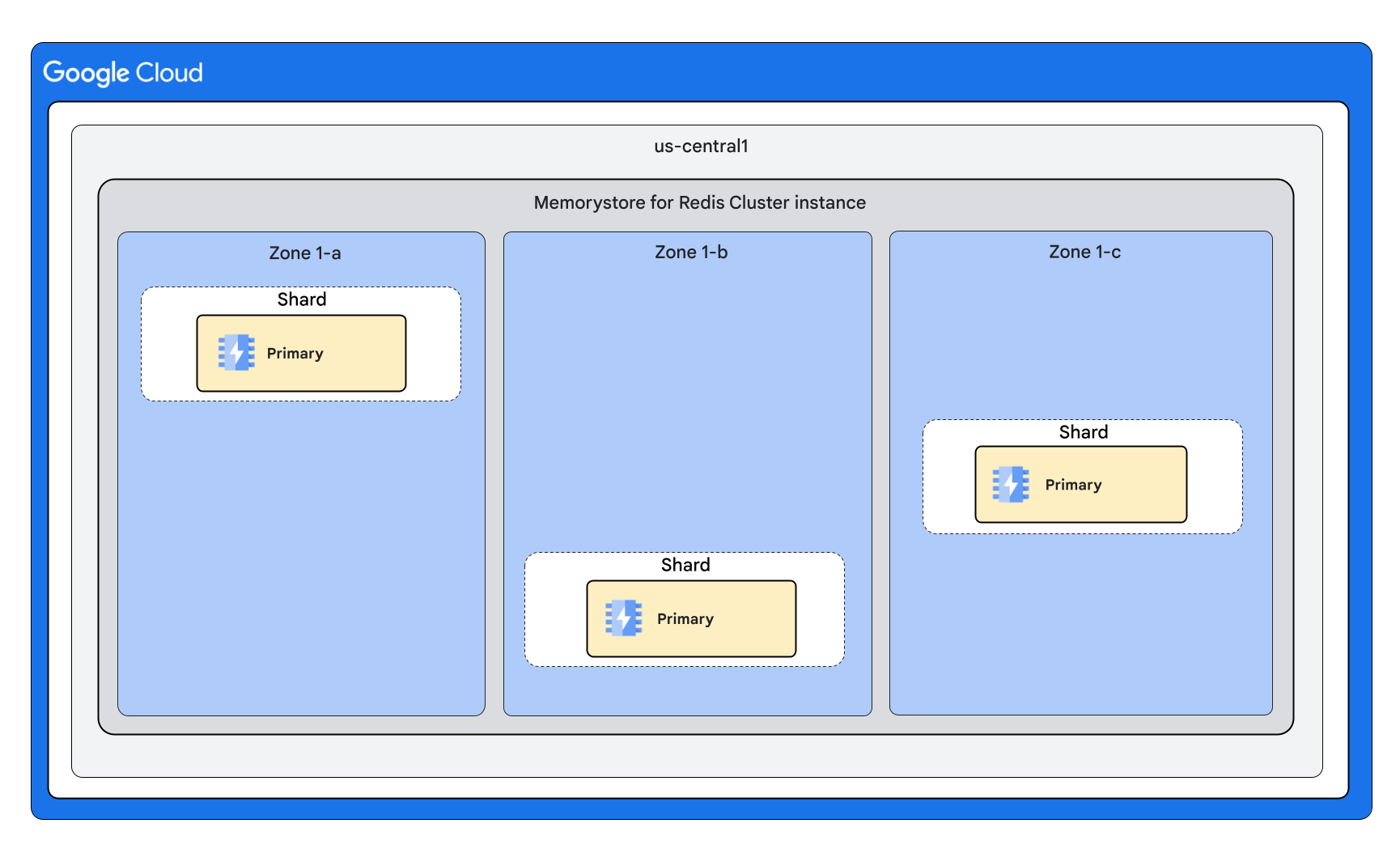
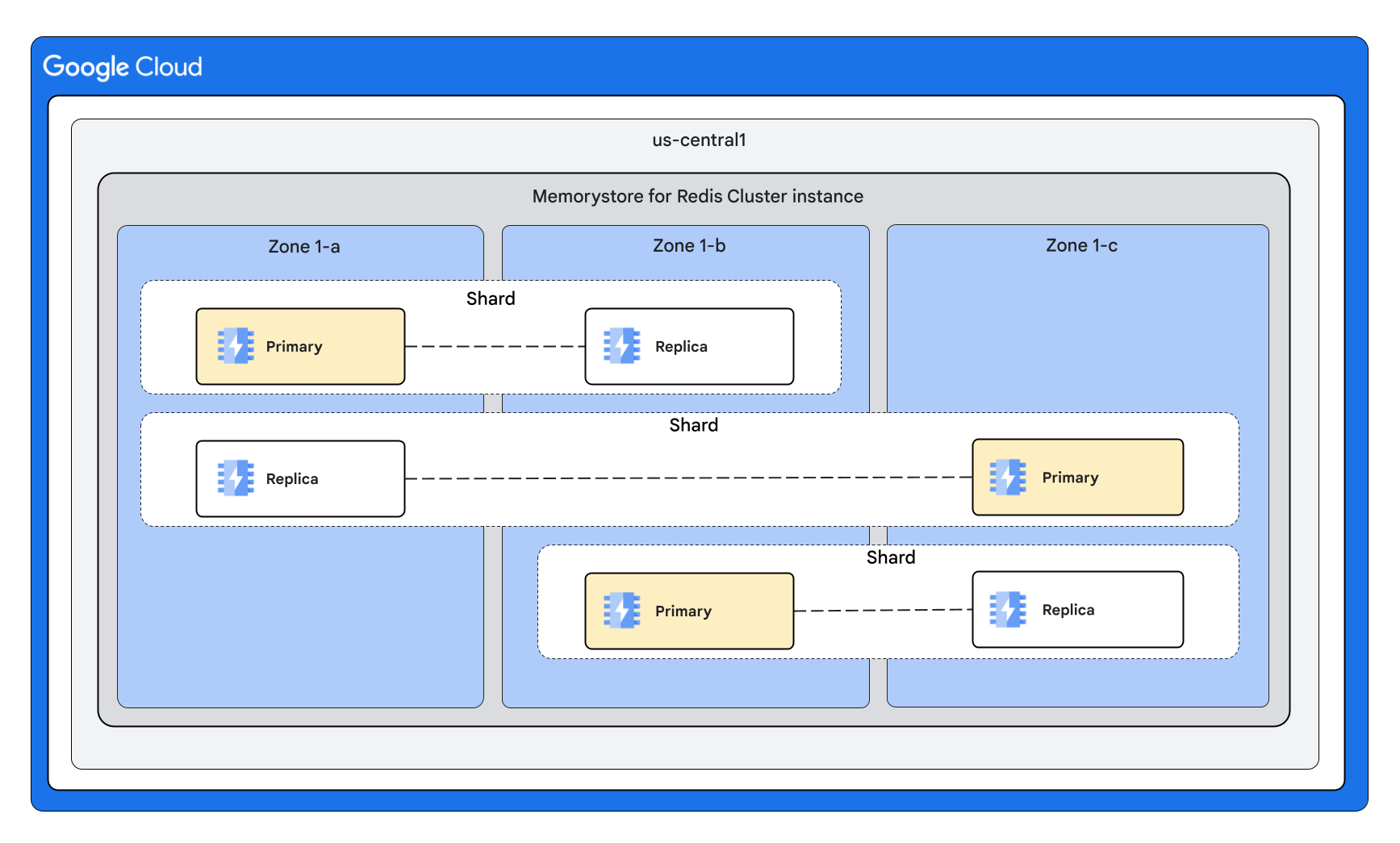
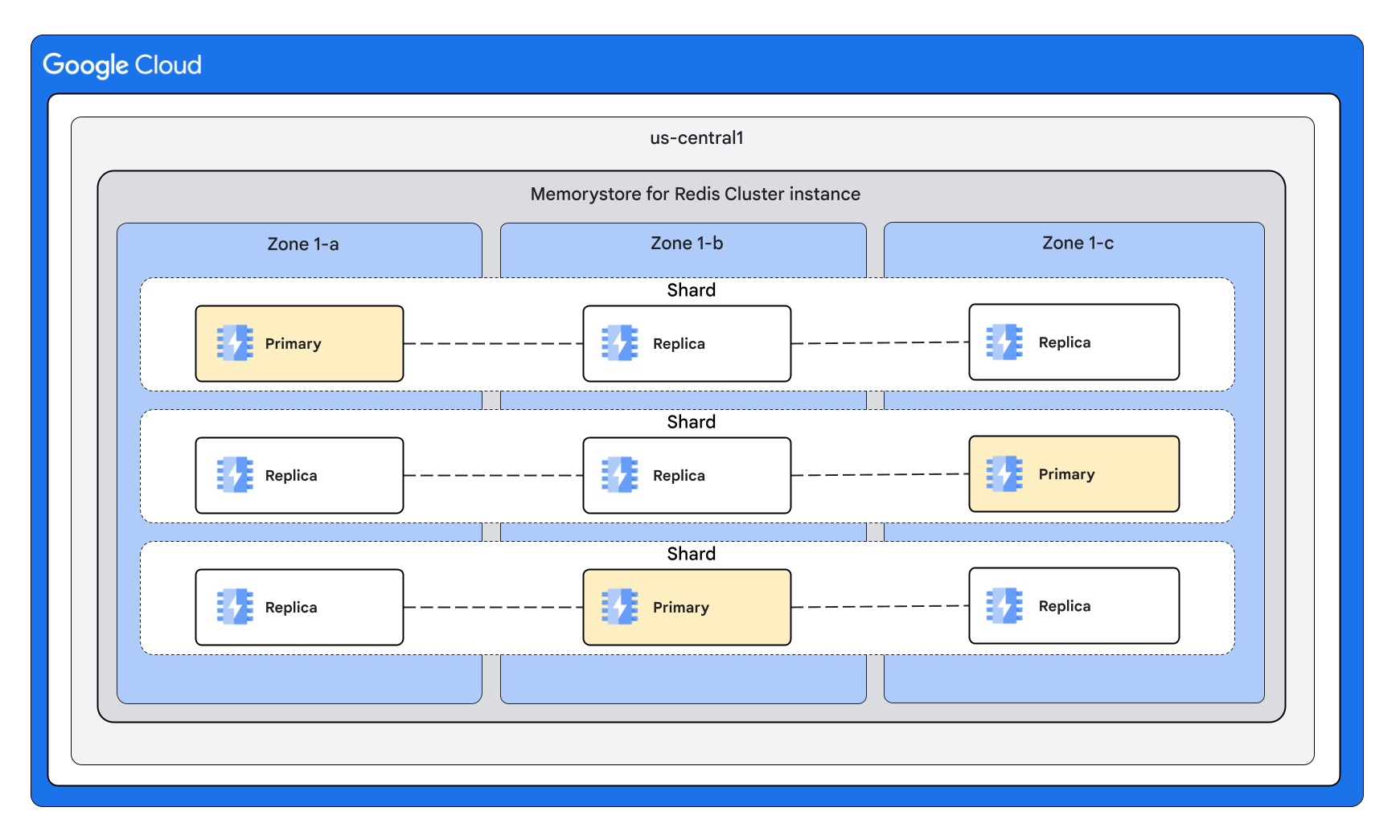
Uma instância do Memorystore for Redis Cluster de alta disponibilidade é um recurso regional. Isto significa que as VMs primárias e de réplica de fragmentos são distribuídas por várias zonas para salvaguardar contra uma indisponibilidade zonal. O Memorystore for Redis Cluster suporta instâncias com 0, 1 ou 2 réplicas por nó.
Pode usar réplicas para aumentar a taxa de transferência de leitura ao dimensionar as leituras.
Para o fazer, tem de usar o comando READONLY para estabelecer uma ligação que permita ao seu cliente ler a partir de réplicas. Para mais detalhes sobre a leitura de réplicas, consulte o artigo Escale com o Redis Cluster.
Forma de cluster com 0 réplicas por nó
Forma de cluster com 1 réplica por nó
Forma de cluster com 2 réplicas por nó
Failover automático
As comutações automáticas por falha num fragmento podem ocorrer devido a manutenção ou a uma falha inesperada do nó principal. Durante uma comutação por falha, uma réplica é promovida a principal. Pode configurar réplicas explicitamente. O serviço também pode aprovisionar temporariamente réplicas adicionais durante a manutenção interna para evitar qualquer tempo de inatividade.
As comutações automáticas por falha evitam a perda de dados durante as atualizações de manutenção. Para ver detalhes sobre o comportamento de comutação por falha automática durante a manutenção, consulte o artigo Comportamento de comutação por falha automática durante a manutenção.
Duração da comutação por falha e da reparação de nós
As comutações automáticas podem demorar dezenas de segundos para eventos não planeados, como uma falha do processo do nó principal ou uma falha de hardware. Durante este período, o sistema deteta a falha e elege uma réplica para ser a nova principal.
A reparação de nós pode demorar alguns minutos para que o serviço substitua o nó com falhas. Isto aplica-se a todos os nós primários e de réplica. Para instâncias que não estão altamente disponíveis (sem réplicas aprovisionadas), a reparação de um nó principal com falhas também demora alguns minutos.
Comportamento do cliente durante uma comutação por falha não planeada
É provável que as ligações de cliente sejam repostas consoante a natureza da falha. Após a recuperação automática, as ligações devem ser repetidas com recuo exponencial para evitar a sobrecarga dos nós primários e de réplica.
Os clientes que usam réplicas para a taxa de transferência de leitura devem estar preparados para uma degradação temporária da capacidade até que o nó com falhas seja substituído automaticamente.
Escritas perdidas
Durante uma comutação por falha resultante de uma falha inesperada, as escritas reconhecidas podem ser perdidas devido à natureza assíncrona do protocolo de replicação do Redis.
As aplicações cliente podem tirar partido do comando WAIT do Redis para melhorar a segurança dos dados do mundo real. É uma abordagem de melhor esforço que tem compromissos, conforme explicado na documentação de comandos do Redis.WAIT
Impacto do espaço de chaves de uma interrupção de zona única
Esta secção descreve o impacto de uma indisponibilidade de uma única zona numa instância do Memorystore for Redis Cluster.
Instâncias multizona
Instâncias de HA: se uma zona tiver uma indisponibilidade, todo o espaço de chaves está disponível para leituras e escritas, mas, uma vez que algumas réplicas de leitura estão indisponíveis, a capacidade de leitura é reduzida. Recomendamos vivamente o aprovisionamento excessivo da capacidade do cluster para que a instância tenha capacidade de leitura suficiente, no caso raro de uma indisponibilidade de uma única zona. Quando a indisponibilidade terminar, as réplicas na zona afetada são restauradas e a capacidade de leitura do cluster volta ao valor configurado. Para mais informações, consulte o artigo Padrões para apps fiáveis e escaláveis.
Instâncias não de HA (sem réplicas): se uma zona tiver uma indisponibilidade, a parte do espaço de chaves aprovisionada na zona afetada sofre uma descarga de dados e fica indisponível para escritas ou leituras durante a indisponibilidade. Quando a indisponibilidade terminar, os nós primários na zona afetada são restaurados e a capacidade do cluster regressa ao valor configurado.
Instâncias de zona única
- Instâncias de HA e não HA: se a zona na qual a instância é aprovisionada tiver uma indisponibilidade, o cluster fica indisponível e os dados são eliminados. Se uma zona diferente tiver uma indisponibilidade, o cluster continua a processar pedidos de leitura e escrita. Assim que a indisponibilidade terminar, a capacidade configurada do cluster é restaurada.
Práticas recomendadas
Esta secção descreve as práticas recomendadas para a alta disponibilidade e as réplicas.
Adicione uma réplica
A adição de uma réplica requer um instantâneo RDB. Os instantâneos RDB usam um processo fork e um mecanismo de "copy-on-write" para tirar um instantâneo dos dados do nó. Consoante o padrão de escritas nos nós, a memória usada dos nós aumenta à medida que as páginas afetadas pelas escritas são copiadas. A memória usada pode ser até o dobro do tamanho dos dados no nó.
Para garantir que os nós têm memória suficiente para concluir a captura instantânea, mantenha ou defina maxmemory a 80% da capacidade do nó, para que 20% seja reservado para custos gerais. Esta sobrecarga de memória, além de monitorizar os instantâneos, ajuda a gerir a sua carga de trabalho para ter instantâneos bem-sucedidos. Além disso, quando adiciona réplicas, reduza o tráfego de gravação o máximo possível. Para mais informações, consulte o artigo Monitorize um cluster com uma carga de gravação elevada.