IBM-Mainframes werden von Organisationen für kritische Rechenaufgaben verwendet. In den letzten Jahren haben viele Unternehmen, die auf Mainframes angewiesen sind, auf eine Migration in die Cloud hingearbeitet. Mit Mainframe Connector können Sie Ihre Mainframe-Daten zuGoogle Cloud verschieben, um CPU-intensive Berichtslasten auf Google Cloudauszulagern.
Wichtige Vorteile von Mainframe Connector
Hier sind die wichtigsten Vorteile der Verwendung von Mainframe Connector zum Verschieben von Mainframe-Daten nach Google Cloud:
- Vereinfachte Datenübertragung:Vereinfacht die Übertragung von Mainframe-Daten inGoogle Cloud Speicherdienste wie Cloud Storage und BigQuery.
- Batchjob-Integration:Sie können BigQuery-Jobs mit Mainframe-Batchjobs einreichen, die in der Job Control Language (JCL) definiert sind. Da Abfragen aus Datasets oder Dateien gelesen werden, können Analysten geplante Jobs mit minimalen Kenntnissen und Verständnis von Mainframe-Umgebungen verwenden.
- Einfache Überwachung:Mainframe-Betriebspersonal muss keine andere Umgebung überwachen, da Jobs mit vertrauten Zeitplänen über JCL gesendet werden.
- Weniger MIPS:Der Mainframe Connector verwendet für die meisten Verarbeitungsvorgänge eine Java Virtual Machine (JVM), um die Mainframe-Prozessorlast bei der Datenübertragung zu minimieren. Dadurch werden die Millionen von Anweisungen pro Sekunde (MIPS) reduziert und die Kosten gesenkt. Mainframe Connector lagert die meisten prozessorintensiven Aufgaben auf Hilfsprozessoren aus. Wenn die Hilfsprozessoren überlastet sind, können Sie Mainframe Connector auch so konfigurieren, dass Transcodierung und Konvertierung mit Compute Engine durchgeführt werden. Weitere Informationen zu Mainframe Connector-Konfigurationen finden Sie unter Mainframe Connector-Konfigurationen.
Streaming-Transformation:Dateien werden in die Formate ORC, JSON oder CSV transcodiert, die mit Google Cloud -Diensten wie BigQuery kompatibel sind. Mainframe Connector unterstützt die Transcodierung für die folgenden Dateitypen:
- QSAM- oder VSAM-Mainframe-Datasets, die COBOL-Copybooks im Extended Binary Coded Decimal Interchange Code (EBCDIC) zugeordnet sind
- Dateien in ASCII UTF-8
Standardmäßig transcodiert Mainframe Connector Datasets aus dem Zeichensatz US EBCDIC: Cp037 in die Formate ORC, JSON und CSV. Mainframe Connector unterstützt jedoch auch die Transkodierung von Datasets aus den folgenden regionalen EBCDIC-Zeichensätzen:
- Französisch: Cp297
- Deutsch: Cp1141
- Spanisch: Cp1145
Ein benutzerdefinierter Zeichensatz kann implementiert werden, wenn kein geeigneter Zeichensatz in der IBM JVM enthalten ist.
Funktionsweise von Mainframe Connector
Mit dem Mainframe-Connector können Sie Daten, die sich auf Ihrem Mainframe befinden, in Cloud Storage verschieben und aus Cloud Storage verschieben sowie BigQuery-Jobs aus Mainframe-basierten Batchjobs, die in JCL definiert sind, senden. Mit Mainframe Connector können Sie Mainframe-Datasets direkt in das Optimized Row Columnar (ORC)-Format transkodieren.
Die Transcodierung ist der Prozess der Konvertierung von Informationen von einer Form der codierten Darstellung in eine andere, in diesem Fall in ORC. ORC ist ein spaltenorientiertes Open-Source-Datenformat, das häufig in Verbindung mit Apache Hadoop genutzt wird und von BigQuery unterstützt wird.
Mainframe Connector bietet eine Teilmenge der Google Cloud SDK-Befehlszeilenprogramme, mit denen Sie Daten übertragen und mit Google Cloud -Diensten interagieren können. Der Shell-Interpreter und JVM-basierte Implementierungen der gsutil- und bq-Befehlszeilentools ermöglichen es Ihnen, eine vollständige ELT-Pipeline (Extrahieren, Laden, Transformieren) vollständig über IBM z/OS zu verwalten und gleichzeitig Ihren vorhandenen Job Scheduler beizubehalten.
Eine der größten Herausforderungen bei der Übertragung von Mainframedaten in die Cloud und aus der Cloud ist, dass es sich um einen mehrstufigen Prozess handelt, der normalerweise die folgenden Schritte umfasst:
- Daten auf einen Dateiserver kopieren
- Kopieren Sie Daten vom Dateiserver an einen anderen Ort zur Verarbeitung.
- Verwenden Sie einen Datenverarbeitungs-Stack, um die Daten in ein modernes Format zu konvertieren.
- Die verarbeiteten Daten werden an einem weiteren Speicherort gespeichert.
- Die verarbeiteten Daten werden in eine Datenbank oder ein Data Warehouse geladen, in dem sie abgefragt oder verwendet werden können.
Die folgende Abbildung zeigt den mehrstufigen Prozess, der normalerweise zum Übertragen von Daten von einem Mainframe zu Google Cloudverwendet wird.
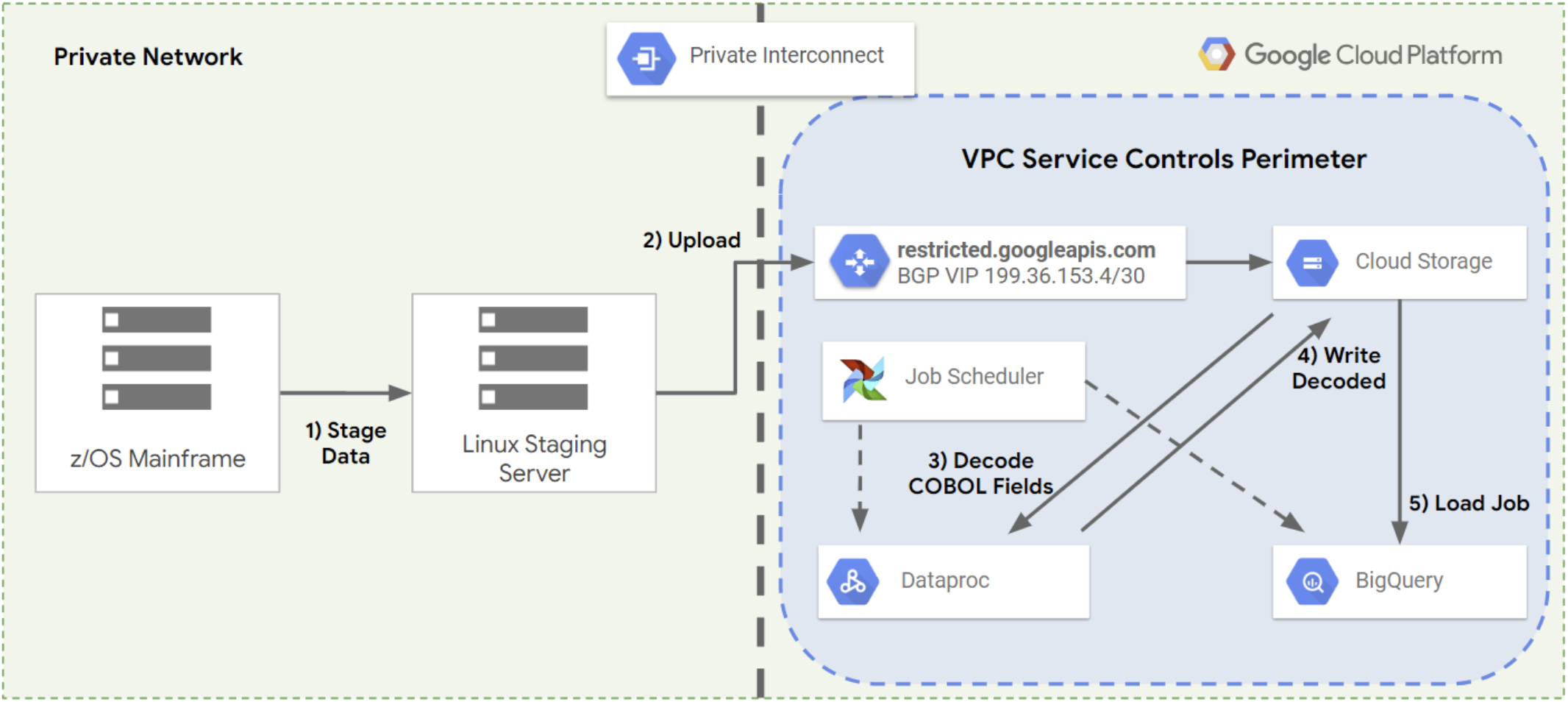
Mit dem Mainframe-Connector können Sie alle diese Schritte mit einem einzigen Befehl ausführen und Cloud Storage als Zwischenspeicherort verwenden. Dadurch wird die Zeit verkürzt, die benötigt wird, um die Mainframe-Daten zu verarbeiten und in einer Datenbank oder einem Data Warehouse verfügbar zu machen, wie in der folgenden Abbildung dargestellt.
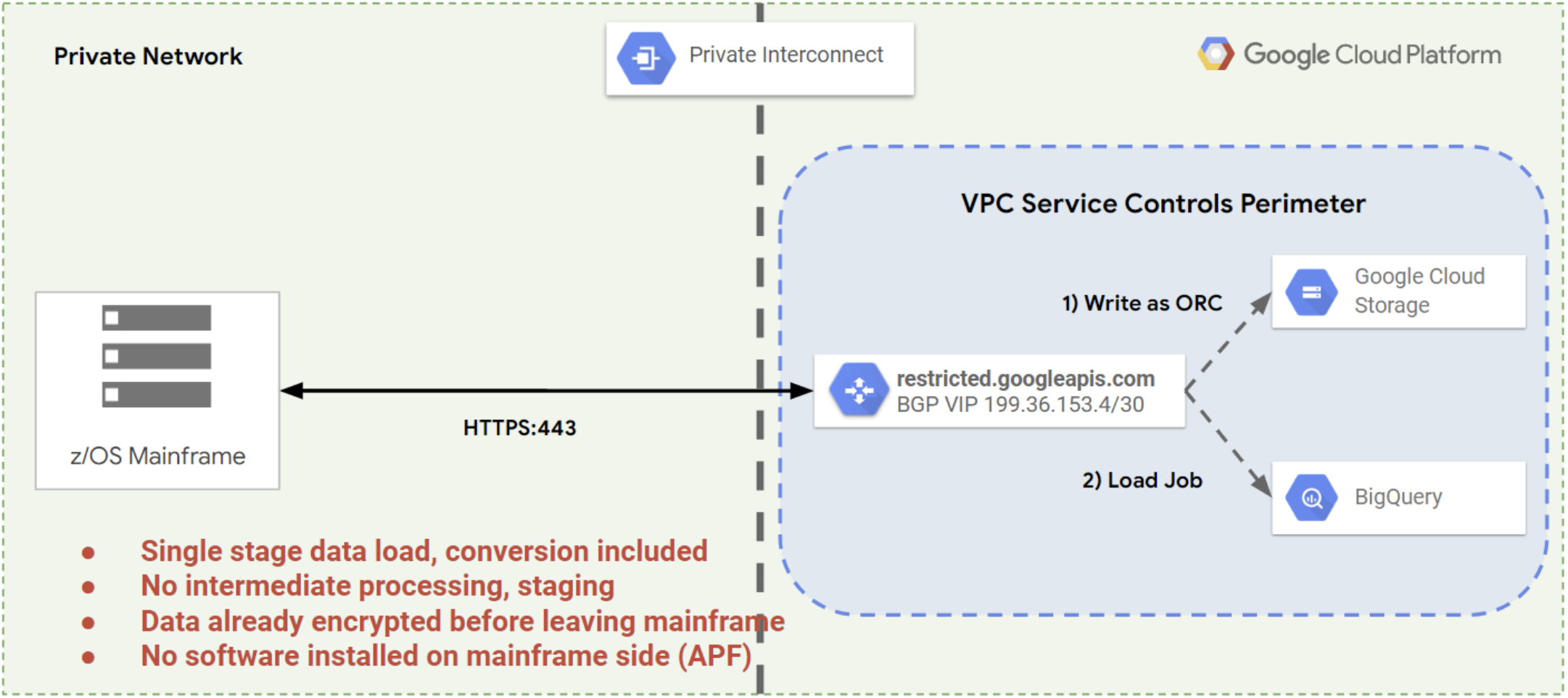
Nächste Schritte
- Mainframe Connector-Architektur
- Mainframe Connector-Konfigurationen
- Mainframe Connector installieren