Mainframe Connector supporta due versioni dell'interprete di file di copia:
- Analizzatore sintattico dei file di copia di tipo nativo: l'analizzatore sintattico dei file di copia di tipo nativo implementa un parser basato su ANTLR4, supporta i file di copia COBOL ed è la versione consigliata dell'analizzatore sintattico.
- Parser di libri di copie legacy: il parser di libri di copie legacy è una versione precedente del parser che supporta un numero molto limitato di formati di libri di copie.
Puoi definire il parser da utilizzare in base al tuo copybook. Per ulteriori informazioni sulla definizione del parser da utilizzare, consulta Definire il parser del libro di copie.
Parser di libri mastri nativi
L'analisi del codice del libro mastro nativo è la versione più recente del parser e viene utilizzata per impostazione predefinita. L'analizzatore di libri di copie nativo implementa un parser basato su ANTLR4 e supporta i libri di copie COBOL.
Questa sezione elenca le attività di preelaborazione eseguite dall'analizzatore sintattico del testo pubblicitario nativo. Inoltre, illustra i tipi di dati supportati dall'interprete di file di copia nativi e le limitazioni per il suo utilizzo.
Pre-elaborazione
Prima di analizzare un libro mastro, l'analizzatore del libro mastro nativo pre-elabora i dati ed esegue le seguenti attività:
- Rimuove le righe di commento.
- Risolvi il proseguimento della riga.
- Elimina le aree dei numeri di riga e della colonna 73.
- Mantiene le istruzioni specifiche del preprocessore come
EJECT,SPACEeTITLE. Questi campi vengono analizzati, ma ignorati. I report contenenti parametri di preelaborazione che possono essere utilizzati daCOPY REPLACINGnon sono supportati dall'analisi sintattica dei report nativi. In questi modelli, gli identificatori sono racchiusi tra due due punti (:).
Tipi di dati supportati e limitazioni
Di seguito sono riportati i tipi di dati supportati dall'analizzatore di file di copia nativo e le limitazioni per il suo utilizzo:
- I livelli 66 (ALIAS) o 77 (STANDALONE) non sono supportati.
- Utilizza solo i campi PICTURE. Sono supportati i seguenti campi PICTURE:
- Pic A, Pic, B, Pic G (DBCS), Pic N (nazionale o DBCS), Pic U (UTF8), Pic X e decimale con zona (precisione massima 38, scala massima 38)
- È supportato il numero in virgola mobile esadecimale IBM (HFP).
- I valori REDEFINE non sono supportati.
- Utilizza solo i seguenti campi COMP. ALIGN e OCCURS non sono supportati.
- COMP
- COMP4
- BINARY
- COMP3
- PACKED-DECIMAL
- DATE e TIMESTAMP sono supportati.
- Gli indicatori di valori nulli sono supportati.
- I campi Pic G e Pic N del set di caratteri a due byte (DBCS) sono supportati e devono essere utilizzati al posto di Pic T, che ora è deprecato. Per usare il campo Pic N come DBCS senza specificare
USAGE DISPLAY-1, devi impostare la variabile di ambienteNSYMBOLsuDBCS. Per impostazione predefinita,NSYMBOLè impostato suNATIONAL, che impostaUSAGE NATIONALsui campi Pic N che non hanno una clausolaUSAGE. Tieni presente cheNSYMBOLpuoi essere impostato solo suNATIONALoDBCS. - Sono supportate le stringhe di caratteri a lunghezza variabile.
- La clausola SIGN è supportata.
- Devi giustificare tutti i campi e utilizzare un unico livello di rientro.
- I commenti sono supportati.
Supporto per i campi data e timestamp
Mainframe Connector supporta lo spostamento di dati relativi a date e timestamp in e da BigQuery. A questo scopo, devi definire variabili di ambiente che iniziano con la parola SUFFIX nel seguente formato:
SUFFIX_SUFFIX_STRING="command --format FORMAT --timezone TIMEZONE"
L'elenco seguente descrive il formato in maggiore dettaglio:
SUFFIX_SUFFIX_STRING: la variabile di ambiente che puoi utilizzare per definire i dati relativi a data e timestamp. Il nome SUFFIX_STRING corrisponde ai suffissi-SUFFIX_STRINGo_SUFFIX_STRINGche devono essere interpretati come data o timestamp se utilizzati come suffisso di un nome di campo in un modello. Assicurati che SUFFIX_STRING non contenga un trattino o un'underscore.command: definisce il decodificatore da utilizzare per analizzare il campo. I comandi supportati sonodate-converteretimestamp-converter.--format: un parametro che definisce il formato della data o del timestamp. Puoi specificare fino a cinque formati diversi separati da virgole. Se più formati possono corrispondere a un determinato input, viene utilizzato il primo formato corrispondente per il caricamento in BigQuery. Se vengono specificati più formati per l'esportazione, viene utilizzato solo il primo. Per ulteriori informazioni sui formati validi, consulta Formati di data e timestamp supportati.--timezone: un parametro facoltativo per il tipoTIMESTAMP. Per impostazione predefinita, il fuso orario è UTC. Per ulteriori informazioni sui formati dei fusi orari supportati, consulta Formati dei fusi orari supportati.--omitsuffix(facoltativo): se questo parametro è specificato,-SUFFIX_STRINGo_SUFFIX_STRINGviene rimosso dal nome del campo visualizzato in BigQuery.
Per aggiungere un alias per un SUFFIX_SUFFIX_STRING, puoi impostare una variabile di ambiente SUFFIX_SUFFIX_ALIAS=$SUFFIX_SUFFIX_STRING.
Esempi:
- Se definisci una variabile di ambiente come
SUFFIX_DT8="date-converter --format yyyyMMdd", un campo con suffisso-DT8o_DT8sarà un campo di tipoDATEin BigQuery e il relativo pattern saràyyyyMMdd. - Se definisci una variabile di ambiente come
SUFFIX_DT10="date-converter --format MM-dd-yyyy", un campo con suffisso-DT10o_DT10sarà un campo di tipoDATEin BigQuery e il relativo pattern saràMM-dd-yyyy. - Se definisci una variabile di ambiente come
SUFFIX_DT="date-converter --format 'MM-dd-yyyy,MM/dd/yyyy'", un campo con suffisso-DTo_DTsarà un campo di tipoDATEin BigQuery e il relativo pattern saràMM-dd-yyyyoMM/dd/yyyy. - Se definisci due variabili di ambiente come
SUFFIX_TIMESTAMP="timestamp-converter --format yyyy-MM-dd SUFFIX_TIMESTAMP=timestamp-converter --format 'yyyy-MM-dd HH.mm.ss.SSSSSS' --timezone America/New_York"eSUFFIX_TS=$SUFFIX_TIMESTAMP, un campo con uno dei seguenti suffissi:-TIMESTAMP,_TIMESTAMP,-TSo_TSsarà un campo di tipoTIMESTAMPin BigQuery e il relativo pattern saràyyyy-MM-dd HH:mm:ss.SSSSSScon il fuso orarioAmerica/New_York.
Supporto degli indicatori null
Mainframe Connector supporta gli indicatori null iniziando dalla versione
5.13.0. Per utilizzare gli indicatori null, devi definire le variabili di ambiente che iniziano con la parola SUFFIX nel seguente formato:
SUFFIX_NULL_INDICATOR_NAME="command --null-value NULL_VALUE --not-null-value NOT_NULL_VALUE"
NULL_INDICATOR_NAME corrisponde ai suffissi
-NULL_INDICATOR_NAME o _NULL_INDICATOR_NAME che vengono interpretati come indicatore di valore nullo se utilizzati come suffisso di un nome di campo in un
copybook.
L'elenco seguente descrive i parametri che puoi utilizzare con queste variabili di ambiente:
command: il valore deve esserenull-indicator.–null-value: il valorenull indicatorindica che il campo a cui si fa riferimento è null. Il valore di--null-valuedeve essere una stringa o un numero decimale.–not-null-value: (facoltativo) se specificato, il valorenull indicatorindica che il campo a cui si fa riferimento non è null. Se questo parametro non è impostato, viene accettato qualsiasi valore diverso da–value-null. Il valore di–not-null-valuedeve essere una stringa o un numero decimale.–keep: (Facoltativo) Se specificato, il camponull-indicatorviene mantenuto come colonna nel formato file ORC (Optimized Row Columnar). Per impostazione predefinita, questo campo non viene mantenuto nel formato ORC.-force-type: (facoltativo) supporta due opzioni,bytesebinary, che forzano la decodifica di un campo come byte o in formato binario, rispettivamente. Per i byte, i valori dinullenot-nullsono espressi comeHEX(ad esempio,FA3AB5). Sono disponibili le costantiHIGHeLOWequivalenti a tutti i valoriFFo00. Per i valori binari, i valori sono numeri interi regolari.
Se null-indicator non ha un campo a cui fa riferimento,
Mainframe Connector visualizza un messaggio di errore e interrompe l'elaborazione dei
file.
Esempi:
Snippet del modello
10 COL1-NID1 PIC S9(4) USAGE COMP.
10 COL1 PIC S9(6) USAGE COMP.
10 FIELD PIC X(10).
10 FIELD-NID2 PIC X(1).
10 COL2 PIC X(10).
10 COL2-NULL PIC X(1).
Definizione delle variabili di ambiente
SUFFIX_NID1="null-indicator --null-value -1 --not-null-value 0"
# Copybook fields with NID1 suffix null indicator configuration.
SUFFIX_NID2="null-indicator --null-value '?'"
# Copybook fields with NID2 suffix null indicator configuration.
SUFFIX_NULL="null-indicator --null-value '?' --keep"
# Copybook fields with NULL suffix null indicator configuration.
Supporto per i campi DBCS
Quando utilizzi i campi DBCS, assicurati di quanto segue:
- Quando utilizzi i campi DBCS PIC G o Pic N, devi fornire una delle seguenti codificazioni del set di caratteri multibyte (MBCS) valide nell'opzione
encodingo nella variabile di ambienteENCODINGquando utilizzi i comandigsutil cpobq export:- x-IBM930
- x-IBM933
- x-IBM935
- x-IBM937
- x-IBM939
- x-IBM942
- x-IBM942C
- x-IBM943
- x-IBM943C
- x-IBM949
- x-IBM949C
- x-IBM950
- x-IBM964
- x-IBM970
- x-IBM1364
- Quando un campo del codice contiene solo byte DBCS, ma questi byte non sono contornati da shift-out (0x0E) e shift-in (0x0F), devi aggiungere il suffisso
_DBCSal nome del campo per assicurarti che questi byte vengano decodificati come byte DBCS.
Ad esempio, se i dati corrispondenti al campo del modello
03 FLD01 PIC N USAGE DISPLAY-1 contengono i byte 0x43 e
0xC5 nella codifica x-IBM930 che non sono racchiusi tra 0x0E e
0x0F, devi rinominare il nome del campo del modello in
03 FLD01-DBCS PIC N USAGE DISPLAY-1 per decodificare correttamente
i dati DBCS.
Supporto di stringhe di caratteri di lunghezza variabile
L'analizzatore di file di copia nativo supporta i seguenti campistruct:
- 10 var
- 15 var-LEN PIC 9(4) USAGE COMP
- 15 var-TEXT PIC X(n)
Il primo campo nel campo struct è la lunghezza del secondo
campo, il campo di stringa. Potresti dover aggiungere un po' di spaziatura alla fine del
record in base alla sua lunghezza, come mostrato nella figura seguente.
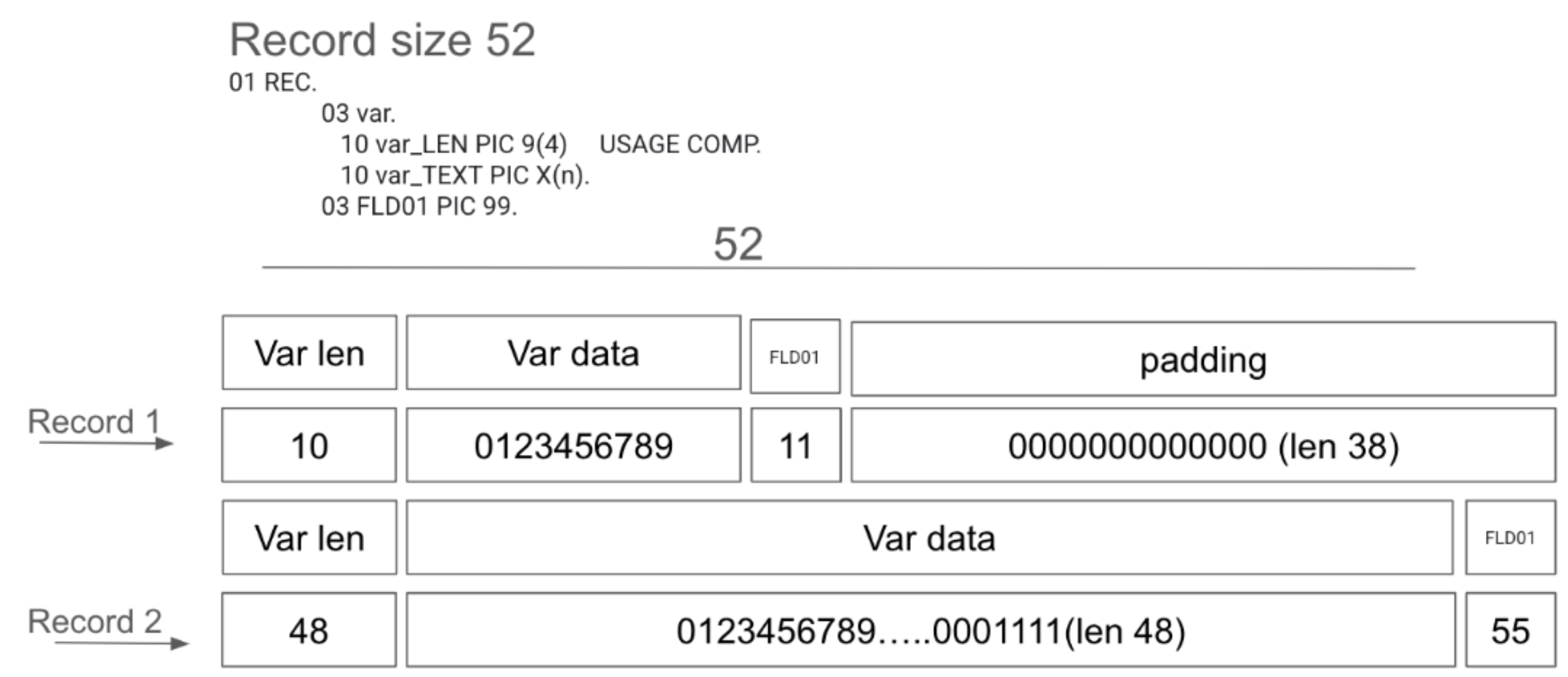
Mainframe Connector rimuove il suffisso dal nome della variabile prima di salvare i dati in BigQuery. In questo esempio, il nome della variabile sarà
var.
Per utilizzare i campi struct, imposta la variabile di ambiente
BQSH_FEATURE_VARIABLE_LENGTH_ENABLED su yes o
true.
Quando utilizzi i campi struct, assicurati di quanto segue:
- Il suffisso del primo parametro in
structè-LEN. Se vuoi utilizzare un suffisso diverso, devi impostare la variabile di ambienteBQSH_FEATURE_VARIABLE_LENGTH_LEN_SUFFIXsul suffisso che vuoi utilizzare. - Il suffisso del secondo parametro in
structè-TEXT. Se vuoi utilizzare un suffisso diverso, devi impostare la variabile di ambienteBQSH_FEATURE_VARIABLE_LENGTH_DATA_SUFFIXsul suffisso che vuoi utilizzare.
Campi e costrutti non supportati
Le sezioni seguenti descrivono i campi e i costrutti non supportati dalla
Costrutti COBOL
Costruzioni COBOL anche se non sono supportate. Se utilizzi questi costrutti nel tuo copybook, Mainframe Connector mostra un errore.
dataAlignedClausedataBlankWhenZeroClausedataCommonOwnLocalClausedataIntegerStringClausedataJustifiedClausedataOccursClausedataReceivedByClausedataRecordAreaClausedataRenamesClausedataSignClausedataSynchronizedClausedataThreadLocalClausedataTypeClausedataTypeDefClausedataUsingClause
Tipi di dati
I tipi di dati COBOL come COMP-1 e COMP-2 sono supportati.
Parser di libri di copie legacy
L'analizzatore di file di copia legacy è una versione precedente dell'analizzatore che supporta funzionalità non COBOL. Se utilizzi un libro mastro basato su DSL, il parser precedente potrebbe essere più adatto in quanto il parser del libro mastro nativo potrebbe causare errori.
Puoi utilizzare il file di copia DD con le seguenti limitazioni:
- I livelli 66 (ALIAS) o 77 (STANDALONE) non sono supportati.
- I valori REDEFINE non sono supportati.
- Le righe di commento non sono supportate.
- I campi di 10 caratteri il cui nome termina con DATA o DT sono date. La decodifica è diversa per questi campi.
- Utilizza solo i seguenti campi COMP. ALIGN e OCCURS non sono supportati.
- COMP
- COMP4
- BINARY
- COMP3
- PACKED-DECIMAL
- Utilizza solo i campi PICTURE. Definisci i campi PICTURE sulla stessa riga, direttamente dopo il nome del campo.
- Devi giustificare tutti i campi e utilizzare un unico livello. I commenti non sono supportati.
- Assicurati che le colonne da 1 a 6 contengano sempre spazi vuoti.