保护并配置数据库后,您就可以将数据库连接到 Looker 了。
您可以在 Looker 中的将数据库连接到 Looker 页面上创建数据库连接。您可以通过以下两种方式打开将数据库连接到 Looker 页面:
- 在管理面板的数据库部分中,选择关联。在连接页面上,点击添加连接按钮。
- 点击左侧导航面板中的创建按钮,然后选择连接菜单项。
如需详细了解如何将用户属性应用于连接设置,请参阅用户属性文档页面中的连接部分。
本页介绍了 Looker 在将数据库连接到 Looker 页面上显示的常见字段。页面上显示的确切字段取决于您的方言设置。
点击此处可查看 Looker 文档中针对特定方言的说明链接。
- Actian Avalanche
- AlloyDB for PostgreSQL
- Amazon Aurora PostgreSQL
- Amazon Athena
- Amazon Aurora MySQL
- Amazon RDS for MySQL
- Amazon RDS for PostgreSQL
- Amazon Redshift
- Apache Druid
- Apache Hive 2.3 及更高版本和 3.1.2 及更高版本
- Apache Spark 3 及更高版本
- ClickHouse
- Cloudera Impala 3.1 及更高版本
- Databricks
- DataVirtuality
- Denodo
- Dremio
- Exasol
- Google BigQuery 旧版 SQL
- Google BigQuery 标准 SQL
- Google Cloud SQL for MySQL
- Google Cloud SQL for PostgreSQL
- Google Spanner
- Greenplum
- IBM DB2 on AS400
- IBM DB2 on LUW
- MariaDB
- Microsoft Azure Synapse Analytics
- Microsoft Azure SQL 数据库
- Microsoft Azure PostgreSQL
- Microsoft SQL Server (MSSQL)
- 适用于 BI 的 MongoDB 连接器
- MySQL
- Oracle
- Oracle ADWC
- PostgreSQL
- PrestoDB
- SAP HANA
- SingleStore(原名 MemSQL)
- Snowflake
- TeraData
- Trino
- 矢量
- Vertica
输入数据库连接设置后,您可以选择将数据库连接到 Looker 页面上的测试按钮,以测试连接并确保其配置正确。点击测试以验证连接是否成功。如需了解问题排查信息,请参阅测试数据库连接文档页面。如果 Looker 显示可以连接,请按连接以创建连接。然后,您的数据库连接会添加到 Looker 连接管理页面上的列表中。
常规设置
名称
您想要引用的连接名称。您需要在 LookML 模型的 connection 参数中使用此数据库连接名称。数据库连接名称也是 Looker 的连接 管理页面上连接的标识方式。请勿为此设置使用任何文件夹的名称。此值不必与数据库中的任何内容相匹配;Name 是在 Looker 界面中标识此连接的标签。
连接范围
选择连接是否可用于所有项目,还是仅可用于一个项目:
- 所有项目:实例上的所有 LookML 项目都可以访问该连接,因此可以在相应项目中的模型文件的
connection参数中指定连接名称。 - 所选项目:实例上只能有一个 LookML 项目可以访问该连接。选择此选项后,“连接”界面会显示一个下拉菜单,其中列出了实例中的项目。选择可访问相应连接的项目。
将此选项与以下权限搭配使用,以委托连接管理和模型配置:
方言
与您的连接匹配的 SQL 方言。请务必选择正确的值,以便您看到正确的连接选项,并确保 Looker 可以将您的 LookML 正确转换为 SQL。
结算项目 ID
对于 Google BigQuery 连接,结算项目 ID 是 Google Cloud 项目 ID。
主机
Looker 应该用于连接到数据库主机的数据库主机名。
如果您曾与 Looker 分析师合作配置 SSH 隧道以连接到数据库,请在主机字段中输入 "localhost"。
端口
Looker 应该用于连接到数据库主机的数据库端口。
如果您曾与 Looker 分析师合作配置 SSH 隧道以连接到数据库,请在端口字段中输入重定向到数据库的端口号(Looker 分析师应已提供此端口号)。
数据库
主机上的数据库的名称。例如,您可能有一个主机名 my-instance.us-east-1.redshift.amazonaws.com,其中包含一个名为 sales_info 的数据库。您可以在此字段中输入 sales_info。如果您在同一主机上有多个数据库,可能需要创建多个连接才能使用它们(MySQL 除外,在 MySQL 中,数据库一词的含义与大多数 SQL 方言略有不同)。
架构
Looker 在未指定架构时使用的默认架构。这适用于以下情况:您在使用 SQL Runner、在 LookML 项目生成期间以及在查询表时。
身份验证
对于 Google BigQuery、Snowflake、Trino 和 Databricks 连接,请选择您希望 Looker 用于访问数据库的身份验证类型:
- 对于 Google BigQuery 连接,您可以选择配置 OAuth 或服务账号,供 Looker 用于向数据库进行身份验证。
- 对于 Snowflake、Trino 和 Databricks 连接,您可以选择配置 OAuth 或数据库账号,供 Looker 用于向数据库进行身份验证。
使用 OAuth 时,您的用户必须登录数据库才能从 Looker 发出查询。如需详细了解如何为 Looker 连接配置 OAuth,请参阅 Google BigQuery、Snowflake、Trino 或 Databricks 连接程序。
用户名
Looker 可用于连接到数据库的数据库用户账号中的用户名。
密码
Looker 可用于连接到数据库的数据库用户账号的密码。
可选设置
SSH 服务器
只有当实例部署在 Kubernetes 基础设施上,并且向 Looker 实例中添加 SSH 服务器配置信息的功能已启用时,SSH 服务器选项才可用。如果您的 Looker 实例未启用此选项,但您想启用它,请与 Google Cloud 销售专家联系或提交支持请求。
SSH 服务器会自动为您选择 localhost 端口,您无法指定 localhost 端口。如果您需要创建需要指定本地主机端口的 SSH 连接,请提交支持请求。
如需使用 SSH 隧道连接到数据库,请开启相应切换开关,然后从下拉列表中选择一个 SSH 服务器配置。
本地端口
默认情况下,Looker 会自动为 SSH 隧道选择可用的本地端口。如需手动选择本地端口,请选择手动输入,然后在自定义本地端口字段中输入端口号。确保您的实例上有可用的本地端口。
永久性派生表 (PDT)
启用 PDT
开启启用 PDT 开关,以启用永久性派生表。启用 PDT 后,“连接”窗口会显示额外的 PDT 字段和“PDT 覆盖”部分。只有当数据库方言支持使用 PDT 时,Looker 才会显示启用 PDT 切换开关。
请注意以下有关 PDT 的事项:
- 使用 OAuth 的 Snowflake 连接不支持 PDT。
- 停用连接中的 PDT 不会停用与 PDT 关联的数据组。即使您停用 PDT,现有数据组仍会针对数据库运行其
sql_trigger查询。如果您想阻止数据组针对数据库运行其sql_trigger查询,您必须从 LookML 项目中删除或注释掉datagroup参数,或者您可以更新连接的数据组和 PDT 维护时间表设置,以便 Looker 非常不频繁地检查 PDT 和数据组,甚至从不检查。 - 对于 Snowflake 连接,Looker 会将
AUTOCOMMIT参数的值设置为TRUE(Snowflake 的默认值)。Looker 运行 SQL 命令来维护其 PDT 注册系统,因此需要AUTOCOMMIT。
临时数据库
虽然此数据库标记为临时数据库,但您应根据自己的 SQL 方言输入数据库名称或架构名称,Looker 应使用该名称来创建永久性派生表。您应提前配置此数据库或架构,并授予适当的写入权限。在数据库配置说明文档页面上,选择您的数据库方言,以查看该方言的说明。
每个连接都必须有自己的临时数据库或架构;临时数据库或架构无法在连接之间共享。
PDT 构建器连接数上限
借助 PDT 构建器连接数上限设置,您可以指定 Looker 重新生成器可以在数据库连接上启动的并发表构建数量。PDT 构建器连接数上限设置仅适用于 Looker 重新生成器会启动重建的表类型:
- 触发器持久性表(使用
datagroup_trigger或sql_trigger_value持久性策略的永久性派生表和汇总表)。 - 使用
persist_for策略的持久化表,但仅当persist_for表是派生表级联的一部分时,其中一个表依赖于使用datagroup_trigger或sql_trigger_value持久化策略的表。在这种情况下,Looker 再生器将重建persist_for表,因为需要该表来重建级联中的另一个表。否则,再生器不会为persist_for表启动 build。
PDT 构建器连接数上限设置的默认值为 1,但最高可设置为 10。不过,该值不能高于在每个节点的最大连接数字段中设置的值,也不能高于在 Looker 的启动选项中设置的 per-user-query-limit。
请谨慎设置此值。如果该值过高,可能会导致数据库过载。如果该值较低,长时间运行的 PDT 或汇总表可能会延迟其他持久表的创建,或减慢连接上的其他查询。支持多租户的数据库(例如 BigQuery、Snowflake 和 Redshift)在处理并行查询构建时可能具有更高的性能。
如果您想增加 PDT 构建器连接数上限设置,一个不错的经验法则是每次增加 1。如果出现任何意外行为,请将其恢复为默认值 1。否则,如果查询性能不受影响,您可以继续以 1 为增量逐步提高该值,并在每次提高后验证性能,然后再进一步提高该设置。
请注意以下有关 PDT 构建器连接数上限设置的信息:
- PDT 构建器连接数上限设置仅适用于表重建所需的连接,而不适用于触发检查所需的连接。触发器检查是一种用于检查表的持久性策略是否已触发的查询;由于这些触发器检查查询始终按顺序运行,因此最大 PDT 构建器连接数设置不适用。
- 在集群 Looker 实例中,重新生成器仅在主节点上运行。PDT 构建器连接数上限设置仅适用于主节点,因此会为整个集群设置上限。
- PDT 构建器连接数上限设置不适用于以下类型的表。这些类型的表格是按顺序构建的:
- 通过
persist_for参数保留的表(除非该表被使用datagroup_trigger或sql_trigger_value策略的表所依赖)。 - 开发模式下的表格。
- 使用重新构建派生表并运行选项重新构建的表。
- 在依赖关系级联中,一个表依赖于另一个表。表无法与其所依赖的表同时构建。例如,如果
table_B依赖于table_A,则table_A必须先完成重建,然后table_B才能开始重建。
- 通过
数据组和 PDT 维护时间表
Looker 重新生成器会检查基于 sql_trigger_value 的数据组和永久性表(包括汇总表和永久性派生表)。根据这些检查,Looker 重新生成器会从数据库的临时架构中重建或删除永久性表。
数据组和 PDT 维护时间表值用于设置 Looker 再生器的 cron 间隔。Looker 重新生成器会启动一个重新生成器周期,以按 cron 间隔检查数据组和永久性表。如果在下一个 cron 时间间隔内,Looker 再生器周期仍在进行中,Looker 再生器将完成正在进行的再生器周期,然后等待到下一个 cron 时间间隔,再开始下一个再生器周期。
数据组和 PDT 维护时间表设置接受 cron 表达式。默认值为 */5 * * * *,这意味着如果上一个再生器周期已完成,Looker 再生器周期将以 5 分钟的间隔启动一个周期。如果上一个重新生成器周期尚未完成,Looker 重新生成器将在其周期完成后,在下一个 5 分钟间隔内启动。
默认值 5 分钟也是数据组和 PDT 维护时间表支持的最频繁间隔。Looker 不会强制执行 Datagroup 和 PDT 维护时间表的最大间隔,这意味着您可以根据 cron 表达式指定的时长来延长 Looker 再生器周期之间的间隔。请注意,较长的 Looker 再生器周期可能会对缓存和持久化表中的数据新鲜度产生不利影响。
Looker 再生器在一个周期内完成所有检查和 PDT 重建后,将等待下一个 cron 时间间隔,然后启动下一个周期。如果您有长时间运行的 PDT build,那么 Looker 再生器周期之间的时间可能会很长。如 Looker 中的派生表页面上的实现持久表的注意事项部分中所述,其他因素也会影响重建表所需的时间。
如果您的数据库不是全天候运行,您可能需要将检查限制在数据库运行的时间段内。以下是一些额外的 cron 表达式:
cron 表达式 |
定义 |
|---|---|
*/5 8-17 * * MON-FRI |
在周一至周五的营业时间内,每隔 5 分钟检查一次数据组和 PDT |
*/5 8-17 * * * |
在工作时间内,每天每隔 5 分钟检查一次数据组和 PDT |
0 8-17 * * MON-FRI |
在周一至周五的营业时间内,每小时检查一次数据组和 PDT |
1 3 * * * |
每天凌晨 3:01 检查数据组和 PDT |
创建 cron 表达式时,请注意以下几点:
- Looker 使用 parse-cron v0.1.3,该版本不支持
cron表达式中的?。 cron表达式使用 Looker 应用时区来确定检查时间。- 如果 PDT 未构建,请将 cron 字符串重置回默认值
*/5 * * * *。
以下是一些可帮助您创建 cron 字符串的资源:
- https://crontab.guru - 帮助编辑和测试
cron字符串。 - http://www.crontab-generator.org - 选择时间设置,生成器会创建相应的
cron字符串。
重试失败的 PDT 构建
重试失败的 PDT 构建切换开关用于配置 Looker 重新生成器尝试重新构建在之前的重新生成器周期中失败的触发持久化表的方式。Looker 再生器是一个进程,用于根据数据组和 PDT 维护时间表连接设置中配置的时间间隔重新构建触发器持久化表(PDT 和汇总表)。启用重试失败的 PDT 构建切换开关后,即使 PDT 的触发条件未满足,Looker 生成器也会尝试重新构建在上一个生成器周期中失败的 PDT。如果停用此设置,Looker 再生器仅会在满足 PDT 的触发条件时尝试重新构建之前失败的 PDT。重试失败的 PDT 构建默认处于停用状态。
如需详细了解 Looker 再生器,请参阅 Looker 中的派生表文档页面。
PDT API 控制
PDT API 控制切换开关用于确定是否可将 start_pdt_build、check_pdt_build 和 stop_pdt_build API 调用用于此连接。当 PDT API 控制切换开关处于停用状态时,如果这些 API 调用引用了此连接上的 PDT,则会失败。PDT API 控制切换开关默认处于停用状态。
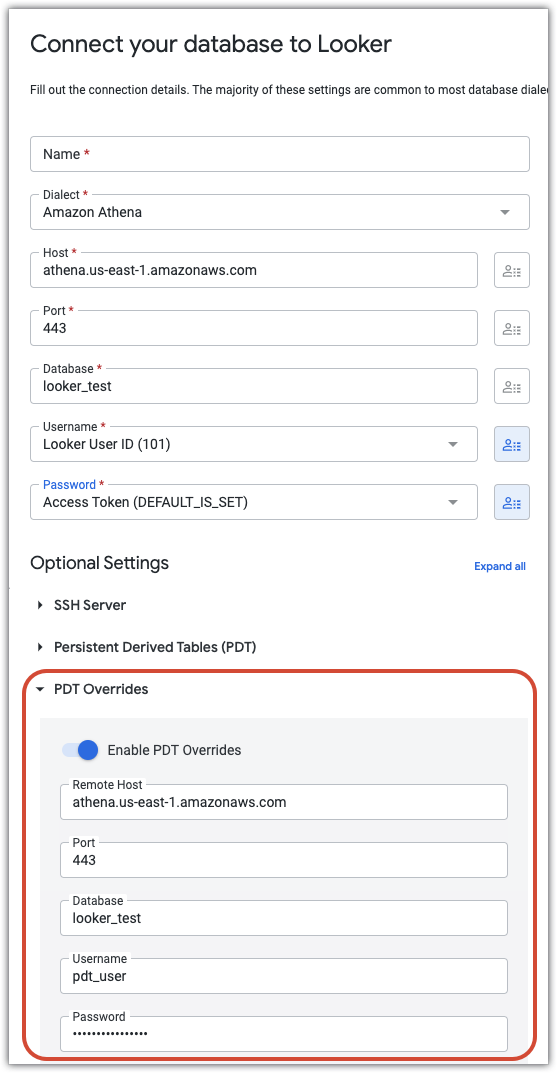
PDT 覆盖
如果您的数据库支持永久性派生表,并且您已在连接设置中开启启用 PDT 开关,Looker 会显示 PDT 替换部分。在 PDT 覆盖设置部分,您可以输入单独的专用于 PDT 进程的 JDBC 参数(主机、端口、数据库、用户名、密码、架构、其他参数和连接后语句)。这在很多方面都很有价值:
- 通过为 PDT 进程创建单独的数据库用户,即使您为数据库登录凭据分配了用户属性或为数据库连接使用了 OAuth,也可以在 Looker 项目中使用 PDT。
- PDT 进程可以通过具有更高优先级的单独数据库用户进行身份验证。这样,数据库就可以优先处理 PDT 作业,而不是不太重要的用户查询。
- 可以撤消标准 Looker 数据库连接的写入权限,并仅授予 PDT 进程将用于身份验证的特殊用户。对于大多数组织而言,这是一种更好的安全策略。
- 对于 Snowflake 等数据库,PDT 进程可以路由到不与其他 Looker 用户共享的更强大的硬件。这样一来,PDT 就可以快速构建,而无需承担全天候运行昂贵硬件的成本。
例如,以下配置显示了一个连接,其中用户名和密码字段设置为用户属性。这样,每位用户都可以使用自己的凭据访问数据库。PDT 替换项部分会创建一个单独的用户 (pdt_user),并为其设置自己的密码。pdt_user 账号将用于所有 PDT 流程,并具有适合 PDT 创建和更新的访问权限级别。
时区
数据库时区
数据库用于存储基于时间的信息的时区。Looker 需要了解这一点,以便为用户转换时间值,从而更轻松地理解和使用基于时间的数据。如需了解详情,请参阅使用时区设置文档页面。
查询时区
只有在停用用户自选时区后,系统才会显示查询时区选项。
停用用户自选时区后,查询时区将成为用户查询基于时间的数据时看到的时区,也是 Looker 将基于时间的数据从数据库时区转换到的时区。
如需了解详情,请参阅使用时区设置文档页面。
其他设置
其他 JDBC 参数
如果需要,您可以在此处为查询添加其他 Java 数据库连接 (JDBC) 参数。
如需在 JDBC 参数中引用用户属性,请使用 Liquid 模板语法:_user_attributes['name_of_attribute']。例如:
my_jdbc_param={{ _user_attributes['name_of_attribute'] }}
每个节点的连接数上限
您可以在此处设置 Looker 可以与数据库建立的连接数上限。在大多数情况下,您设置的是 Looker 可以针对数据库同时运行的查询数量。Looker 还会预留最多 3 个连接用于终止查询。如果连接池非常小,Looker 将预留较少的连接。
请谨慎设置此值。如果该值过高,则可能会让您的数据库过载。如果该值过低,查询就必须共享少量连接。因此,许多查询对用户来说可能显得很慢,因为查询必须等待其他较早的查询返回。
默认值(因 SQL 方言而异)通常是一个合理的起点。大多数数据库还具有自己的设置,用于指定它们将接受的连接数上限。如果数据库配置限制了连接数,请确保每个节点的最大连接数值等于或低于数据库的限制。
连接池超时时间
如果用户请求的连接数超过了每个节点的最大连接数设置,这些请求将等待其他请求完成后再执行。在此处配置请求的最长等待时间。默认设置为 120 秒。
您应谨慎设置此值。如果该值过低,用户可能会发现自己的查询被取消,因为没有足够的时间让其他用户的查询完成。如果该值过高,可能会累积大量查询,导致用户等待很长时间。默认值通常是一个合理的起点。
此连接的并发查询数上限
此可选值限制了 Looker 一次向此数据库连接提交的并发查询数量。如果有更多并发请求到达,要求使用相同的连接,Looker 会将这些请求排入内部队列,并按顺序处理。设置此值会覆盖现有的每个节点的最大连接数值。
此连接的每用户并发查询数上限
此可选值限制了 Looker 一次向此数据库连接提交的来自同一用户的并发查询数。如果有更多并发请求到达,要求使用相同的连接,Looker 会将这些请求排入内部队列,并按顺序处理。
SSL
选择是否要使用 SSL 加密来保护 Looker 与数据库之间传输的数据。SSL 只是可用于保护数据的一种选项;如需了解其他安全选项,请参阅启用安全的数据库访问文档页面。
验证 SSL
选择是否需要验证连接所使用的 SSL 证书。如果需要验证,则签署 SSL 证书的 SSL 证书授权机构 (CA) 必须来自客户端的可信来源列表。如果 CA 不是可信来源,则不会建立数据库连接。
如果未选中此框,连接仍会使用 SSL 加密,但不需要验证 SSL 连接,因此当 CA 不在客户端的受信任来源列表中时,也可以建立连接。
SQL Runner 预缓存
在 SQL Runner 中,只要您选择连接和架构,系统就会立即预加载所有表信息。这样一来,您只需点击表名,SQL Runner 即可快速显示表列。不过,对于包含许多表或非常大的表的连接和架构,您可能不希望 SQL Runner 预加载所有信息。
如果您希望 SQL Runner 仅在选择表时加载表信息,可以取消选择 SQL Runner 预缓存选项,以针对相应连接停用 SQL Runner 预加载。
为编写 SQL 提取信息架构
对于某些 SQL 编写功能(例如汇总感知),Looker 会使用数据库的信息架构来优化 SQL 编写。如果信息架构未缓存,Looker 可能偶尔需要阻止向数据库写入 SQL,才能提取信息架构。对于使用 Hadoop 分布式文件系统 (HDFS) 的方言,提取信息架构可能需要很长时间,足以显著影响 Looker 查询的性能。如果您知道自己的信息架构速度较慢,可以为连接停用为编写 SQL 提取信息架构选项。停用此功能会阻止 Looker 针对某些功能进行 SQL 优化,因此您应启用为编写 SQL 提取信息架构选项,除非您知道连接的信息架构特别慢。
费用估算值
费用估算切换开关仅适用于以下数据库连接:
- Snowflake
- Amazon Redshift
- Amazon Aurora
- PostgreSQL、Google Cloud SQL for PostgreSQL 和 Microsoft Azure PostgreSQL
启用费用估算切换开关后,连接会启用以下功能:
如需了解详情,请参阅在 Looker 中探索数据文档页面。
数据库连接池
对于支持数据库连接池的方言,此功能可让 Looker 通过 JDBC 驱动程序使用连接池。数据库连接池可提高查询性能;新查询无需创建新的数据库连接,而是可以使用连接池中的现有连接。连接池功能可确保在查询执行后清理连接,并在查询执行结束后可供重复使用。如需了解详情,请参阅数据库连接池文档页面。
测试连接设置
您可以在 Looker 界面中的多个位置测试连接设置:
- 选择连接设置页面底部的测试按钮。
- 在连接管理页面上,选择连接列表旁边的测试按钮,如连接文档页面中所述。
输入连接设置后,点击测试以验证信息是否正确以及数据库是否能够连接。
如果您的连接未通过一项或多项测试,请尝试以下问题排查方法:
- 请尝试执行测试数据库连接文档页面上的一些问题排查步骤。
- 如果您在 Atlas 上运行的是 Mongo 3.6 版或更低版本,并且遇到通信链路故障,请参阅 Mongo 连接器文档页面。
- 如需接收有关临时架构和 PDT 的成功连接消息,您必须在设置 Looker 数据库时允许该功能。如需了解相关说明,请参阅数据库配置说明文档页面。
如果您仍遇到问题,请提交支持请求。
以用户身份进行测试
如果您已将一个或多个连接参数值设置为用户属性,则会显示以用户身份进行测试选项。选择一个用户,然后点击测试,以验证数据库是否可以以该用户身份连接和运行查询。
后续步骤
将数据库连接到 Looker 后,您就可以为用户配置登录选项了。