Nachdem Sie Ihre Datenbank geschützt und konfiguriert haben, können Sie sie mit Looker verbinden.
Sie erstellen eine Datenbankverbindung in Looker auf der Seite Datenbank mit Looker verbinden. Es gibt zwei Möglichkeiten, die Seite Datenbank mit Looker verbinden zu öffnen:
- Wählen Sie im Bereich Admin im Abschnitt Database (Datenbank) die Option Connections (Verbindungen) aus. Klicken Sie auf der Seite Verbindungen auf die Schaltfläche Verbindung hinzufügen.
- Klicken Sie im linken Navigationsbereich auf die Schaltfläche Erstellen und wählen Sie dann den Menüpunkt Verbindung aus.
Weitere Informationen zum Anwenden von Nutzerattributen auf Verbindungseinstellungen finden Sie im Abschnitt Verbindungen auf der Dokumentationsseite Nutzerattribute.
Auf dieser Seite werden häufige Felder beschrieben, die in Looker auf der Seite Datenbank mit Looker verbinden angezeigt werden. Die genauen Felder, die auf der Seite angezeigt werden, richten sich nach Ihrer Dialekt-Einstellung.
Klicken Sie hier, um die Links zur dialektspezifischen Anleitung in der Looker-Dokumentation aufzurufen.
- Actian Avalanche
- AlloyDB for PostgreSQL
- Amazon Aurora PostgreSQL
- Amazon Athena
- Amazon Aurora MySQL
- Amazon RDS for MySQL
- Amazon RDS for PostgreSQL
- Amazon Redshift
- Apache Druid
- Apache Hive 2.3+ und 3.1.2+
- Apache Spark 3+
- ClickHouse
- Cloudera Impala 3.1 und höher
- Databricks
- DataVirtuality
- Denodo
- Dremio
- Exasol
- Google BigQuery Legacy SQL
- Google BigQuery-Standard-SQL
- Google Cloud SQL for MySQL
- Google Cloud SQL for PostgreSQL
- Google Spanner
- Greenplum
- IBM DB2 auf AS400
- IBM DB2 auf LUW
- MariaDB
- Microsoft Azure Synapse Analytics
- Microsoft Azure SQL-Datenbank
- Microsoft Azure PostgreSQL
- Microsoft SQL Server (MSSQL)
- MongoDB Connector for BI
- MySQL
- Oracle
- Oracle ADWC
- PostgreSQL
- PrestoDB
- SAP HANA
- SingleStore (ehemals MemSQL)
- Snowflake
- Teradata
- Trino
- Vector
- Vertica
Nachdem Sie die Einstellungen für die Datenbankverbindung eingegeben haben, können Sie auf der Seite Datenbank mit Looker verbinden die Schaltfläche Testen auswählen, um die Verbindung zu testen und sicherzustellen, dass sie richtig konfiguriert ist. Klicken Sie auf Testen, um zu prüfen, ob die Verbindung erfolgreich ist. Informationen zur Fehlerbehebung finden Sie auf der Dokumentationsseite Datenbankkonnektivität testen. Wenn in Looker Can Connect (Kann verbunden werden) angezeigt wird, klicken Sie auf Connect (Verbinden), um die Verbindung herzustellen. Ihre Datenbankverbindung wird dann der Liste auf der Looker-Administratorenseite Verbindungen hinzugefügt.
Allgemeine Einstellungen
Name
Der gewünschte Name für die Verbindung. Sie benötigen diesen Datenbankverbindungsnamen für den Parameter connection Ihres LookML-Modells. Der Name der Datenbankverbindung wird auch verwendet, um die Verbindung auf der Seite Verbindungen Administrator in Looker zu identifizieren. Verwenden Sie für diese Einstellung nicht den Namen von Ordnern. Dieser Wert muss keine Übereinstimmung in Ihrer Datenbank haben. Name ist ein Label, mit dem diese Verbindung in der Looker-Benutzeroberfläche identifiziert wird.
Verbindungszugehörigkeit
Wählen Sie aus, ob die Verbindung mit allen Projekten oder nur mit einem Projekt verwendet werden soll:
- Alle Projekte: Alle LookML-Projekte in der Instanz können auf die Verbindung zugreifen. Der Verbindungsname kann also im Parameter
connectionvon Modelldateien in diesem Projekt angegeben werden. - Ausgewähltes Projekt: Nur ein LookML-Projekt in der Instanz kann auf die Verbindung zugreifen. Wenn Sie diese Option auswählen, wird auf dem Bildschirm „Verbindung“ ein Drop-down-Menü mit den Projekten in der Instanz angezeigt. Wählen Sie das Projekt aus, das auf diese Verbindung zugreifen kann.
Verwenden Sie diese Option zusammen mit den folgenden Berechtigungen, um die Verbindungsverwaltung und Modellkonfiguration zu delegieren:
Dialekt
Der SQL-Dialekt, der Ihrer Verbindung entspricht. Hierbei ist es wichtig, den richtigen Wert zu wählen, damit Ihnen die richtigen Verbindungsoptionen angezeigt werden und Looker Ihre LookML richtig in SQL übersetzen kann.
ID des Abrechnungsprojekts
Bei Google BigQuery-Verbindungen ist die Billing Project ID die Google Cloud Projekt-ID.
Host
Der Hostname Ihrer Datenbank, mit dem Looker eine Verbindung zu Ihrem Datenbankhost herstellen soll.
Wenn Sie mit einem Looker-Analysten zusammengearbeitet haben, um einen SSH-Tunnel zu Ihrer Datenbank zu konfigurieren, geben Sie im Feld Host "localhost" ein.
Port
Der Port Ihrer Datenbank, mit dem Looker eine Verbindung zu Ihrem Datenbankhost herstellen soll.
Wenn Sie mit einem Looker-Analysten zusammengearbeitet haben, um einen SSH-Tunnel für Ihre Datenbank zu konfigurieren, geben Sie im Feld Port die Portnummer ein, die zu Ihrer Datenbank weiterleitet. Diese sollte Ihnen von Ihrem Looker-Analysten zur Verfügung gestellt worden sein.
Datenbank
Der Name der Datenbank auf Ihrem Host. Sie haben beispielsweise einen Hostnamen von my-instance.us-east-1.redshift.amazonaws.com, auf dem sich eine Datenbank namens sales_info befindet. In diesem Feld würden Sie sales_info eingeben. Wenn Sie über mehrere Datenbanken auf demselben Host verfügen, müssen Sie möglicherweise mehrere Verbindungen herstellen, um sie zu verwenden. (Mit Ausnahme von MySQL. Hier bedeutet das Wort database etwas geringfügig anderes als in den meisten SQL-Dialekten.)
Schema
Das von Looker verwendete Standardschema, wenn kein Schema angegeben ist. Dies wird bei der Verwendung von SQL Runner, bei der LookML-Projekterstellung und bei der Abfrage von Tabellen verwendet.
Authentifizierung
Wählen Sie für Google BigQuery-, Snowflake-, Trino- und Databricks-Verbindungen den Authentifizierungstyp aus, den Looker für den Zugriff auf Ihre Datenbank verwenden soll:
- Bei Google BigQuery-Verbindungen haben Sie die Möglichkeit, OAuth oder ein Dienstkonto zu konfigurieren, das Looker zur Authentifizierung bei Ihrer Datenbank verwendet.
- Bei Snowflake-, Trino- und Databricks-Verbindungen haben Sie die Möglichkeit, OAuth oder ein Datenbankkonto zu konfigurieren, das Looker zur Authentifizierung bei Ihrer Datenbank verwendet.
Wenn Sie OAuth verwenden, müssen sich Ihre Nutzer in Ihrer Datenbank anmelden, um Abfragen über Looker auszuführen. Weitere Informationen zum Konfigurieren von OAuth für eine Verbindung zu Looker finden Sie in den Verfahren für Google BigQuery-, Snowflake-, Trino- oder Databricks-Verbindungen.
Nutzername
Der Nutzername eines Nutzerkontos in Ihrer Datenbank, mit dem Looker eine Verbindung zu Ihrer Datenbank herstellen kann.
Passwort
Das Passwort eines Nutzerkontos in Ihrer Datenbank, mit dem Looker eine Verbindung zu Ihrer Datenbank herstellen kann.
Optionale Einstellungen
SSH-Server
Die Option SSH-Server ist nur dann verfügbar, wenn die Instanz in einer Kubernetes-Infrastruktur bereitgestellt wird und wenn die Fähigkeit aktiviert wurde, Ihrer Looker-Instanz Informationen zur SSH-Serverkonfiguration hinzuzufügen. Wenn diese Option in Ihrer Looker-Instanz nicht aktiviert ist und Sie sie aktivieren möchten, wenden Sie sich an einen Google Cloud Vertriebsexperten oder stellen Sie eine Supportanfrage.
Der SSH-Server wählt den localhost-Port automatisch für Sie aus. Die Angabe des localhost-Ports ist nicht möglich. Wenn Sie eine SSH-Verbindung erstellen müssen, für die Sie einen localhost-Port angeben müssen, erstellen Sie eine Supportanfrage.
Wenn Sie über einen SSH-Tunnel eine Verbindung zu Ihrer Datenbank herstellen möchten, aktivieren Sie die Ein/Aus-Schaltfläche und wählen Sie in der Drop-down-Liste eine SSH-Serverkonfiguration aus.
Lokaler Port
Standardmäßig wählt Looker automatisch einen verfügbaren lokalen Port für den SSH-Tunnel aus. Wenn Sie einen lokalen Port manuell auswählen möchten, wählen Sie Manuelle Eingabe aus und geben Sie eine Portnummer in das Feld Benutzerdefinierter lokaler Port ein. Achten Sie darauf, dass der lokale Port auf Ihrer Instanz verfügbar ist.
Persistente abgeleitete Tabellen (PDTs)
PDTs aktivieren
Aktivieren Sie den Schalter PDTs aktivieren, um persistente abgeleitete Tabellen zu aktivieren. Wenn PDTs aktiviert sind, werden im Fenster Verbindung zusätzliche PDT-Felder und der Bereich PDT-Überschreibungen angezeigt. Die Ein/Aus-Schaltfläche PDTs aktivieren wird in Looker nur angezeigt, wenn der Datenbankdialekt die Verwendung von PDTs unterstützt.
Beachten Sie Folgendes zu PDTs:
- PDTs werden für Snowflake-Verbindungen, die OAuth verwenden, nicht unterstützt.
- Wenn Sie PDTs für eine Verbindung deaktivieren, werden die Datengruppen, die mit Ihren PDTs verknüpft sind, nicht deaktiviert. Auch wenn Sie PDTs deaktivieren, werden für vorhandene Datengruppen weiterhin die
sql_trigger-Abfragen für die Datenbank ausgeführt. Wenn Sie verhindern möchten, dass für eine Datengruppe diesql_trigger-Abfrage für Ihre Datenbank ausgeführt wird, müssen Sie den Parameterdatagroupaus Ihrem LookML-Projekt löschen oder auskommentieren. Alternativ können Sie die Einstellung Wartungszeitplan für Datengruppen und PDTs für die Verbindung so aktualisieren, dass Looker PDTs und Datengruppen nur sehr selten oder nie prüft. - Bei Snowflake-Verbindungen legt Looker den Wert für den Parameter
AUTOCOMMITaufTRUE(Snowflake-Standardwert) fest.AUTOCOMMITist für SQL-Befehle erforderlich, die Looker zur Verwaltung des PDT-Registrierungssystems ausführt.
Temporäre Datenbank
Obwohl dieses Label Temporäre Datenbank lautet, geben Sie je nach Ihrem SQL-Dialekt entweder den Datenbank- oder Schemanamen ein, den Looker zum Erstellen persistenter abgeleiteter Tabellen verwenden soll. Diese Datenbank oder dieses Schema sollten Sie im Voraus mit den entsprechenden Schreibberechtigungen konfigurieren. Wählen Sie auf der Dokumentationsseite Anweisungen zur Datenbankkonfiguration Ihren Datenbankdialekt aus, um die entsprechenden Anweisungen für diesen Dialekt einzublenden.
Jede Verbindung muss eine eigene temporäre Datenbank oder ein eigenes Schema haben. Mehrere Verbindungen können sich diese nicht teilen.
Max. Anzahl der Verbindungen für PDT-Generator
Mit der Einstellung Max. Anzahl der Verbindungen für PDT-Generator können Sie angeben, wie viele gleichzeitige Tabellen-Builds der Looker-Regenerator für Ihre Datenbankverbindung initiieren kann. Die Einstellung Maximale Anzahl von PAT-Builder-Verbindungen gilt nur für die Tabellentypen, für die der Looker-Regenerator Neuerstellungen initiiert:
- Auslöser-persistente Tabellen (persistente abgeleitete Tabellen und aggregierte Tabellen, die die Persistenzstrategie
datagroup_triggerodersql_trigger_valueverwenden). - Persistente Tabellen, die die Strategie
persist_forverwenden, aber nur, wenn diepersist_for-Tabelle Teil einer Kaskade abgeleiteter Tabellen ist, in der sie von einer Tabelle abhängig ist, die die Persistenzstrategiedatagroup_triggerodersql_trigger_valueverwendet. In diesem Fall erstellt der Looker-Regenerator einepersist_for-Tabelle neu, da die Tabelle für die Neuerstellung einer anderen Tabelle in der Kaskade benötigt wird. Andernfalls initiiert der Regenerator keine Erstellungen fürpersist_for-Tabellen.
Die Einstellung Maximale Anzahl von PAT-Builder-Verbindungen ist standardmäßig auf 1 festgelegt, kann aber auf bis zu 10 erhöht werden. Der Wert darf jedoch nicht höher sein als der Wert, der im Feld Max. connections per node oder in der per-user-query-limit festgelegt ist, die in den Startoptionen von Looker festgelegt ist.
Wählen Sie diesen Wert mit Bedacht. Ist der Wert zu hoch, überlastet dies möglicherweise Ihre Datenbank. Wenn der Wert niedrig ist, können PDTs oder aggregierte Tabellen mit langer Ausführungszeit die Erstellung anderer persistenter Tabellen verzögern oder andere Abfragen für die Verbindung verlangsamen. Datenbanken, die mehrere Mandanten unterstützen, wie BigQuery, Snowflake und Redshift, können eine bessere Leistung bei der Verarbeitung paralleler Abfrageerstellungen zeigen.
Wenn Sie die Einstellung Maximale Anzahl von PAT-Builder-Verbindungen erhöhen möchten, empfiehlt es sich, sie jeweils um 1 zu erhöhen. Wenn unerwartetes Verhalten auftritt, setzen Sie den Wert wieder auf den Standardwert 1 zurück. Wenn die Abfrageleistung nicht beeinträchtigt wird, können Sie den Wert schrittweise um 1 erhöhen und die Leistung bei jeder Erhöhung prüfen, bevor Sie die Einstellung weiter erhöhen.
Hinweise zur Einstellung Maximale Anzahl von PAT-Builder-Verbindungen:
- Die Einstellung Maximale Anzahl von PAT-Builder-Verbindungen gilt nur für Verbindungen, die für das Neuerstellen von Tabellen erforderlich sind, nicht für die Verbindungen, die für Triggerprüfungen benötigt werden. Eine Auslöserprüfung ist die Abfrage zum Prüfen, ob die Persistenzstrategie der Tabelle ausgelöst wird. Diese Auslöserprüfungsabfragen werden immer nacheinander ausgeführt. Daher gilt die Einstellung Maximale Anzahl von PDT-Builder-Verbindungen für sie nicht.
- In einer geclusterten Looker-Instanz wird der Regenerator nur für den Hauptknoten ausgeführt. Die Einstellung Maximale Anzahl von PAT-Builder-Verbindungen gilt nur für den Hauptknoten und legt daher den Grenzwert für den gesamten Cluster fest.
- Die Einstellung Maximale Anzahl von PAT-Builder-Verbindungen gilt nicht für die nachfolgend aufgeführten Tabellentypen. Diese Tabellentypen werden nacheinander erstellt:
- Tabellen, die über den Parameter
persist_forbeibehalten werden, sofern die Tabelle nicht von Tabellen mit den Strategiendatagroup_triggerodersql_trigger_valueabhängig ist. - Tabellen im Entwicklungsmodus
- Tabellen, die mit der Option Abgeleitete Tabellen neu erstellen und ausführen neu erstellt wurden.
- Tabellen, die in einer Abhängigkeits-Kaskade voneinander abhängen. Eine Tabelle kann nicht gleichzeitig mit einer Tabelle erstellt werden, von der sie abhängt. Wenn
table_Bbeispielsweise vontable_Aabhängt, musstable_Aneu erstellt werden, bevortable_Bneu erstellt werden kann.
- Tabellen, die über den Parameter
Wartungszeitplan für Datengruppe und PAT
Der Looker-Regenerator prüft Datengruppen und persistente Tabellen (sowohl zusammengefasste Tabellen als auch persistente abgeleitete Tabellen), die auf sql_trigger_value basieren. Anhand dieser Prüfungen erstellt der Looker-Regenerator persistente Tabellen aus dem Scratch-Schema Ihrer Datenbank neu oder löscht sie.
Der Wert Wartungszeitplan für Datengruppe und PAT legt das cron-Intervall für den Looker-Regenerator fest. Der Looker-Regenerator initiiert einen Regenerator-Zyklus, um Datengruppen und persistente Tabellen im cron-Intervall zu prüfen. Wenn ein Looker-Regeneratorzyklus beim nächsten cron-Intervall noch läuft, wird er abgeschlossen. Der Looker-Regenerator wartet dann bis zum nächsten cron-Intervall, bevor er den nächsten Regeneratorzyklus startet.
Für die Einstellung Wartungszeitplan für Datengruppe und PAT ist ein cron-Ausdruck zulässig. Der Standardwert ist */5 * * * *. Das bedeutet, dass der Looker-Regeneratorzyklus einen Zyklus im Fünf-Minuten-Intervall startet, wenn der vorherige Regeneratorzyklus abgeschlossen ist. Wenn der vorherige Regenerator-Zyklus noch nicht abgeschlossen ist, wird der Looker-Regenerator im nächsten 5-Minuten-Intervall nach Abschluss des Zyklus gestartet.
Der Standardwert von fünf Minuten ist auch das häufigste Intervall, das für den Wartungszeitplan für Datengruppe und PAT unterstützt wird. In Looker wird kein maximales Intervall für den Datagroup and PDT Maintenance Schedule (Datengruppen- und PDT-Wartungszeitplan) erzwungen. Das bedeutet, dass Sie das Intervall zwischen den Regeneratorzyklen von Looker so lange verlängern können, wie es durch einen cron-Ausdruck angegeben werden kann. Längere Looker-Regeneratorzyklen können sich negativ auf die Aktualität der Daten in Ihrem Cache und in persistenten Tabellen auswirken.
Nachdem der Looker-Regenerator alle Prüfungen und PDT-Neuerstellungen in einem Zyklus abgeschlossen hat, wartet er auf das nächste cron-Intervall, um den nächsten Zyklus zu starten. Wenn Sie PDT-Builds haben, die lange dauern, kann es lange dauern, bis der Looker-Regenerator wieder aktiv wird. Die Dauer der Neuerstellung Ihrer Tabellen kann allerdings von anderen Faktoren beeinflusst werden. Weitere Informationen finden Sie auf der Seite Abgeleitete Tabellen in Looker im Abschnitt Wichtige Überlegungen zur Implementierung persistenter Tabellen.
Falls Ihre Datenbank nicht rund um die Uhr verfügbar ist, empfiehlt sich die Einschränkung der Prüfungen auf die Zeiten der Datenbankverfügbarkeit. Hier sind einige zusätzliche cron-Ausdrücke:
cron-Ausdruck |
Definition |
|---|---|
*/5 8-17 * * MON-FRI |
Datengruppen und PDTs während der Geschäftszeiten alle 5 Minuten prüfen, montags bis freitags |
*/5 8-17 * * * |
Datengruppen und PDTs während der Geschäftszeiten alle 5 Minuten prüfen, täglich |
0 8-17 * * MON-FRI |
Datengruppen und PDTs während der Geschäftszeiten stündlich prüfen, montags bis freitags |
1 3 * * * |
Datengruppen und PDTs täglich um 3:01 prüfen |
Einige Hinweise zum Erstellen eines cron-Ausdrucks:
- Looker verwendet parse-cron v0.1.3, das
?incron-Ausdrücken nicht unterstützt. - Im Ausdruck
cronwird die Zeitzone der Looker-Anwendung verwendet, um zu bestimmen, wann Prüfungen durchgeführt werden. - Werden keine PDTs erstellt, setzen Sie die cron-Zeichenfolge auf den Standardwert
*/5 * * * *zurück.
Hier finden Sie einige Ressourcen, die Ihnen beim Erstellen von cron-Strings helfen können:
- https://crontab.guru – Hilfe zum Erstellen und Testen von
cron-Strings. - http://www.crontab-generator.org: Wählen Sie die Zeiteinstellungen aus. Der Generator erstellt den entsprechenden
cron-String.
Fehlgeschlagene PAT-Builds wiederholen
Mit der Ein/Aus-Schaltfläche Fehlgeschlagene PDT-Builds wiederholen wird konfiguriert, wie der Looker-Regenerator versucht, Auslöser-persistente Tabellen neu zu erstellen, die im vorherigen Regenerator-Zyklus fehlgeschlagen sind. Der Looker-Regenerator ist der Prozess, mit dem per Auslöser persistente Tabellen (PDTs und aggregierte Tabellen) gemäß dem Intervall neu erstellt werden, das in der Verbindungseinstellung Wartungszeitplan für Datengruppen und PDTs konfiguriert ist. Wenn die Ein/Aus-Schaltfläche Fehlgeschlagene PDT-Builds wiederholen aktiviert ist, versucht der Looker-Regenerator, eine PDT neu zu erstellen, die im vorherigen Regenerator-Zyklus fehlgeschlagen ist, auch wenn die Auslösebedingung der PDT nicht erfüllt ist. Wenn diese Einstellung deaktiviert ist, versucht der Looker-Regenerator nur dann, eine zuvor fehlgeschlagene PDT neu zu erstellen, wenn die Auslösebedingung der PDT erfüllt ist. Retry Failed PDT Builds ist standardmäßig deaktiviert.
Weitere Informationen zum Looker-Regenerator finden Sie auf der Dokumentationsseite Abgeleitete Tabellen in Looker.
API-Steuerung für PAT
Mit dem Schalter API-Steuerung für PAT wird festgelegt, ob die API-Aufrufe start_pdt_build, check_pdt_build und stop_pdt_build für diese Verbindung verwendet werden können. Wenn die Ein/Aus-Schaltfläche PDT API Control deaktiviert ist, schlagen diese API-Aufrufe fehl, wenn sie auf PDTs für diese Verbindung verweisen. Die Ein/Aus-Schaltfläche API-Steuerung für PAT ist standardmäßig deaktiviert.
PAT-Überschreibungen
Wenn Ihre Datenbank persistente abgeleitete Tabellen unterstützt und Sie in den Verbindungseinstellungen die Ein/Aus-Schaltfläche PDTs aktivieren aktiviert haben, wird in Looker der Bereich PDT-Überschreibungen angezeigt. Im Bereich PDT Overrides können Sie separate JDBC-Parameter (Host, Port, Database, Username, Password, Schema, zusätzliche Parameter und After-Connect-Anweisungen) eingeben, die für PDT-Prozesse spezifisch sind. Dies kann aus verschiedenen Gründen hilfreich sein:
- Wenn Sie einen separaten Datenbanknutzer für PDT-Prozesse erstellen, können Sie PDTs in Ihrem Looker-Projekt verwenden, auch wenn Sie Nutzerattribute Ihren Datenbankanmeldedaten zuweisen oder OAuth für Ihre Datenbankverbindung verwenden.
- PDT-Prozesse können durch einen eigenen Datenbankbenutzer authentifiziert werden, der über eine höhere Priorität verfügt. Somit kann die Datenbank PDT-Jobs eine höhere Priorität einräumen als weniger wichtigen Benutzerabfragen.
- Der Schreibzugriff kann für die Standard-Looker-Datenbankverbindung entzogen und nur einem bestimmten Benutzer zugewiesen werden, den PDT-Prozesse zur Authentifizierung verwenden. Dies ist für die meisten Unternehmen eine bessere Sicherheitsstrategie.
- Bei Datenbanken wie Snowflake können PDT-Prozesse an leistungsstärkere Hardware weitergeleitet werden, die nicht mit den anderen Looker-Nutzern geteilt wird. Auf diese Weise können PDTs schnell erstellt werden, ohne dass die Notwendigkeit entsteht, jederzeit kostenintensive Hardware vorzuhalten.
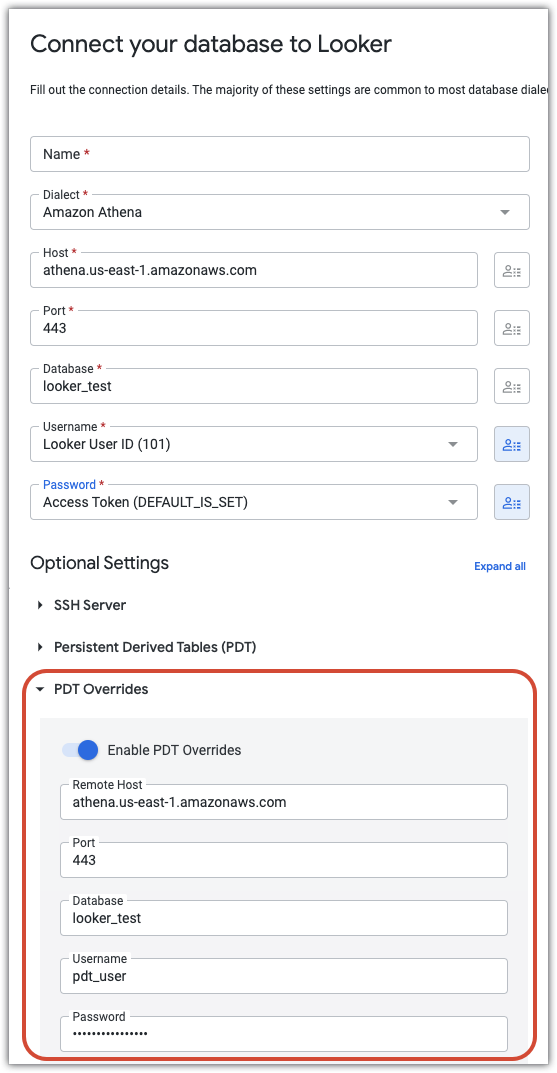
Die folgende Konfiguration zeigt beispielsweise eine Verbindung, in die Felder für Benutzernamen und Passwort auf Benutzerattribute festgelegt sind. Somit kann jeder Benutzer mit seinen eigenen Anmeldedaten auf die Datenbank zugreifen. Im Abschnitt PDT Overrides wird ein separater Nutzer (pdt_user) mit einem eigenen Passwort erstellt. Das Konto pdt_user wird für alle PDT-Prozesse verwendet. Dabei finden entsprechende Zugriffsebenen für die Erstellung und Aktualisierung von PDTs Anwendung.
Zeitzone
Zeitzone der Datenbank
Die Zeitzone, in der Ihre Datenbank zeitbasierte Informationen speichert. Looker muss diese kennen, damit Zeitwerte für Benutzer konvertiert werden können. Dies erleichtert das Verständnis und die Nutzung zeitbasierter Daten. Weitere Informationen finden Sie auf der Dokumentationsseite Zeitzoneneinstellungen verwenden.
Zeitzone der Abfrage
Die Option Zeitzone der Abfrage ist nur sichtbar, wenn Sie Nutzerspezifische Zeitzonen deaktiviert haben.
Wenn Nutzerspezifische Zeitzonen deaktiviert sind, ist die Zeitzone der Abfrage die Zeitzone, die Ihren Nutzern angezeigt wird, wenn sie zeitbasierte Daten abfragen. Außerdem ist sie die Zeitzone, in die Looker zeitbasierte Daten aus der Zeitzone der Datenbank konvertiert.
Weitere Informationen finden Sie auf der Dokumentationsseite Zeitzoneneinstellungen verwenden.
Zusätzliche Einstellungen
Zusätzliche JDBC-Parameter
Bei Bedarf können Sie hier zusätzliche JDBC-Parameter (Java Database Connectivity) für Ihre Abfragen angeben.
Wenn Sie in einem JDBC-Parameter auf ein Nutzerattribut verweisen möchten, verwenden Sie die Liquid-Vorlagensyntax: _user_attributes['name_of_attribute']. Beispiel:
my_jdbc_param={{ _user_attributes['name_of_attribute'] }}
Max. Verbindungen pro Knoten
Hier können Sie die Anzahl der Verbindungen festlegen, die Looker höchstens mit Ihrer Datenbank herstellen kann. Dabei legen Sie überwiegend die Anzahl der Abfragen fest, die Looker gleichzeitig für Ihre Datenbank ausführen kann. Looker reserviert zudem bis zu drei Verbindungen für das Beenden von Abfragen. Ist der Verbindungspool sehr klein, reserviert Looker weniger Verbindungen.
Wählen Sie diesen Wert mit Bedacht. Ist der Wert zu hoch, überlastet dies möglicherweise Ihre Datenbank. Ist er zu niedrig, müssen sich Abfragen eine kleine Anzahl an Verbindungen teilen. Das bedeutet, dass viele Abfragen Benutzern langsam erscheinen, da die Abfragen warten müssen, bis andere, frühere Abfragen beantwortet wurden.
Der Standardwert (der je nach verwendetem SQL-Dialekt unterschiedlich ausfällt) ist in der Regel ein guter Ausgangspunkt. Die meisten Datenbanken verfügen außerdem über ihre eigenen Einstellungen für die von ihnen maximal akzeptierte Anzahl Verbindungen. Falls Ihre Datenbankkonfiguration Verbindungen beschränkt, stellen Sie sicher, dass Ihr Wert für Max Connections per node gleich oder kleiner dem Grenzwert Ihrer Datenbank ist.
Zeitlimit für Verbindungspool
Wenn Ihre Nutzer mehr Verbindungen anfordern als mit der Einstellung Max. Verbindungen pro Knoten festgelegt sind, werden diese Anfragen erst nach Abschluss der anderen ausgeführt. Hier wird die maximale Wartezeit für eine Anforderung festgelegt. Die Standardeinstellung beträgt 120 Sekunden.
Diesen Wert sollten Sie mit Bedacht wählen. Ist er zu niedrig, werden die Anfragen von Nutzern abgebrochen, da die Zeit zum Abschluss der Anfragen anderer Nutzer nicht ausreicht. Ist er zu hoch, entsteht möglicherweise eine große Warteschlange mit Benutzeranfragen und lange Wartezeiten für Benutzer. Der Standardwert ist in der Regel ein guter Ausgangspunkt.
Maximale Anzahl gleichzeitiger Abfragen für diese Verbindung
Mit diesem optionalen Wert wird die Anzahl gleichzeitiger Abfragen begrenzt, die Looker zur gleichen Zeit an diese Datenbankverbindung senden kann. Wenn mehrere gleichzeitige Anfragen eingehen, die dieselbe Verbindung erfordern, stellt Looker sie intern in eine Warteschlange und verarbeitet sie der Reihe nach. Wenn Sie diesen Wert festlegen, wird ein vorhandener Wert für Maximale Anzahl von Verbindungen pro Knoten überschrieben.
Maximale Anzahl gleichzeitiger Abfragen pro Nutzer für diese Verbindung
Durch diesen optionalen Wert wird die Anzahl gleichzeitiger Abfragen eines Nutzers begrenzt, die Looker zur gleichen Zeit an diese Datenbankverbindung senden kann. Wenn mehrere gleichzeitige Anfragen eingehen, die dieselbe Verbindung erfordern, stellt Looker sie intern in eine Warteschlange und verarbeitet sie der Reihe nach.
SSL
Wählen Sie aus, ob Ihre Daten bei der Übergabe zwischen Looker und Ihrer Datenbank mit SSL-Verschlüsselung geschützt werden sollen. SSL ist nur eine Option zum Schutz Ihrer Daten. Andere sichere Optionen werden auf der Dokumentationsseite Sicheren Datenbankzugriff aktivieren beschrieben.
SSL überprüfen
Geben Sie an, ob die Verifizierung des von der Verbindung verwendeten SSL-Zertifikats angefordert werden soll. Wird Verifizierung verlangt, muss die SSL-Zertifizierungsstelle, die das SSL-Zertifikat signiert hat, in der Liste der vertrauenswürdigen Quellen des Client aufgeführt sein. Handelt es sich bei der Zertifizierungsstelle um keine vertrauenswürdige Quelle, wird die Datenbankverbindung nicht hergestellt.
Ist diese Option nicht ausgewählt, wird die SSL-Verschlüsselung weiter auf die Verbindung angewendet, es wird jedoch keine Verifizierung der SSL-Verbindung verlangt. Es kann also auch dann eine Verbindung hergestellt werden, wenn die Zertifizierungsstelle nicht in der Liste der vertrauenswürdigen Quellen des Clients aufgeführt ist.
SQL-Runner-Precache
In SQL-Runner werden alle Tabelleninformationen unmittelbar nach der Auswahl einer Verbindung und eines Schemas vorab geladen. Somit kann SQL Runner Tabellenspalten schnell anzeigen, nachdem Sie auf einen Tabellennamen geklickt haben. Für Verbindungen und Schemata mit vielen Tabellen oder sehr großen Tabellen soll SQL-Runner jedoch möglicherweise nicht alle Informationen vorab laden.
Soll SQL-Runner Tabelleninformationen nur nach Auswahl einer Tabelle laden, können Sie die Option SQL Runner Precache deaktivieren, um das Vorabladen für die Verbindung durch SQL-Runner zu deaktivieren.
Fetch Information Schema For SQL Writing
Für einige Funktionen zum Schreiben von SQL, z. B. Aggregate Awareness, verwendet Looker das Informationsschema Ihrer Datenbank, um das Schreiben von SQL zu optimieren. Falls das Informationsschema nicht zwischengespeichert ist, muss Looker das Schreiben von SQL in die Datenbank möglicherweise gelegentlich blockieren, um das Informationsschema abzurufen. Bei Dialekten, die das Hadoop Distributed File System (HDFS) verwenden, kann das Abrufen des Informationsschemas so lange dauern, dass die Leistung Ihrer Looker-Abfragen erheblich beeinträchtigt wird. Wenn Sie wissen, dass Ihr Informationsschema langsam ist, können Sie die Option Informationsschema für SQL-Schreibvorgänge abrufen für die Verbindung deaktivieren. Wenn Sie diese Funktion deaktivieren, wird die SQL-Optimierung von Looker für bestimmte Funktionen verhindert. Sie sollten die Option Fetch Information Schema For SQL Writing aktivieren, es sei denn, Sie wissen, dass das Informationsschema Ihrer Verbindung besonders langsam ist.
Kostenschätzung
Die Ein/Aus-Schaltfläche Kostenschätzung ist nur für die folgenden Datenbankverbindungen anwendbar:
- Snowflake
- Amazon Redshift
- Amazon Aurora
- PostgreSQL, Google Cloud SQL for PostgreSQL und Microsoft Azure PostgreSQL
Mit dem Schalter Kostenschätzung werden die folgenden Funktionen für die Verbindung aktiviert:
- Kostenschätzungen für Explore-Abfragen
- Kostenschätzungen für SQL Runner-Abfragen
- Schätzungen der Recheneinsparungen für Abfragen mit Gesamtbewusstsein
Weitere Informationen finden Sie auf der Dokumentationsseite Daten in Looker untersuchen.
Datenbankverbindungs-Pooling
Bei Dialekten, die Datenbankverbindungspooling unterstützen, kann Looker mit dieser Funktion Pools von Verbindungen über den JDBC-Treiber verwenden. Durch das Pooling von Datenbankverbindungen wird die Abfrageleistung gesteigert. Für eine neue Abfrage muss keine neue Datenbankverbindung erstellt werden, sondern es kann eine vorhandene Verbindung aus dem Verbindungspool verwendet werden. Durch die Funktion für das Verbindungspooling wird sichergestellt, dass eine Verbindung nach der Ausführung einer Abfrage bereinigt wird und nach dem Ende der Abfrageausführung wiederverwendet werden kann. Weitere Informationen finden Sie auf der Dokumentationsseite Database connection pooling (Datenbankverbindungspooling).
Ihre Verbindungseinstellungen testen
Sie können Ihre Verbindungseinstellungen an verschiedenen Stellen in der Looker-Benutzeroberfläche testen:
- Wählen Sie unten auf der Seite Verbindungseinstellungen die Schaltfläche Testen aus.
- Wählen Sie auf der Seite Verbindungen in der Liste der Verbindungen die Schaltfläche Testen aus, wie auf der Dokumentationsseite Verbindungen beschrieben.
Nachdem Sie die Verbindungseinstellungen eingegeben haben, klicken Sie auf Test, um die Richtigkeit der Informationen zu überprüfen und sicherzustellen, dass die Datenbank eine Verbindung herstellen kann.
Sollte Ihre Verbindung einen oder mehrere Tests nicht bestehen, können Sie Folgendes versuchen:
- Führen Sie einige der auf der Dokumentationsseite Datenbankkonnektivität testen aufgeführten Schritte zur Fehlerbehebung durch.
- Wenn Sie Mongo-Version 3.6 oder früher in Atlas verwenden und ein Kommunikationslinkfehler auftritt, lesen Sie die Dokumentationsseite Mongo Connector.
- Meldungen zu erfolgreichen Verbindungen für das Temp-Schema und PDTs erhalten Sie nur, wenn Sie diese Funktion bei der Konfiguration Ihrer Looker-Datenbank aktiviert haben. Entsprechende Anweisungen finden Sie auf der Dokumentationsseite Anweisungen zur Datenbankkonfiguration.
Wenn weiterhin Probleme auftreten, stellen Sie eine Supportanfrage.
Als Nutzer testen
Wenn Sie mindestens einen Verbindungsparameterwert auf ein Nutzerattribut festgelegt haben, wird die Option Als Nutzer testen angezeigt. Wählen Sie einen Nutzer aus und klicken Sie dann auf Test, um zu prüfen, ob die Datenbank eine Verbindung herstellen und Abfragen als dieser Nutzer ausführen kann.
Nächste Schritte
Nachdem Sie Ihre Datenbank mit Looker verbunden haben, können Sie nun Anmeldeoptionen für Ihre Nutzer konfigurieren.