Ce tutoriel explique la méthode recommandée pour créer une configuration Looker en cluster pour les instances hébergées par le client.
Présentation
Les déploiements de Looker hébergés par le client peuvent s'exécuter sur un seul nœud ou en cluster :
- Une application Looker à nœud unique, qui correspond à la configuration par défaut, comporte tous les services qui composent l'application Looker exécutés sur un seul serveur.
- Une configuration Looker en cluster est plus complexe. Elle implique généralement des serveurs de base de données, des équilibreurs de charge et plusieurs serveurs exécutant l'application Looker. Chaque nœud d'une application Looker en cluster est un serveur exécutant une seule instance Looker.
Voici les deux principales raisons pour lesquelles une organisation peut souhaiter exécuter Looker en tant que cluster :
- Équilibrage de charge
- Disponibilité et basculement améliorés
Selon les problèmes de scaling, un cluster Looker peut ne pas être la solution. Par exemple, si un petit nombre de requêtes volumineuses épuisent la mémoire système, la seule solution consiste à augmenter la mémoire disponible pour le processus Looker.
Alternatives à l'équilibrage de charge
Avant d'équilibrer la charge de Looker, envisagez d'augmenter la mémoire et éventuellement le nombre de processeurs d'un seul serveur exécutant Looker. Looker recommande de configurer une surveillance détaillée des performances pour l'utilisation de la mémoire et du processeur afin de s'assurer que le serveur Looker est correctement dimensionné pour sa charge de travail.
Les requêtes volumineuses nécessitent plus de mémoire pour de meilleures performances. Le clustering peut améliorer les performances lorsque de nombreux utilisateurs exécutent de petites requêtes.
Pour les configurations comptant jusqu'à 50 utilisateurs qui utilisent Looker de manière occasionnelle, Looker recommande d'exécuter un seul serveur équivalant à une instance AWS EC2 de grande taille (M4.large : 8 Go de RAM, 2 cœurs de processeur). Pour les configurations avec plus d'utilisateurs ou de nombreux utilisateurs expérimentés actifs, vérifiez si le processeur atteint des pics d'utilisation ou si les utilisateurs constatent un ralentissement de l'application. Si c'est le cas, déplacez Looker vers un serveur plus grand ou exécutez une configuration Looker en cluster.
Disponibilité/basculement améliorés
L'exécution de Looker dans un environnement en cluster peut atténuer les temps d'arrêt en cas de panne. La haute disponibilité est particulièrement importante si l'API Looker est utilisée dans des systèmes métier essentiels ou si Looker est intégré à des produits destinés aux clients.
Dans une configuration Looker en cluster, un serveur proxy ou un équilibreur de charge réachemine le trafic lorsqu'il détermine qu'un nœud est hors service. Looker gère automatiquement les nœuds qui quittent le cluster et ceux qui le rejoignent.
Composants requis
Les composants suivants sont requis pour une configuration Looker en cluster :
- Base de données d'application MySQL
- Nœuds Looker (serveurs exécutant le processus Java Looker)
- Équilibreur de charge
- Système de fichiers partagé
- Version appropriée des fichiers JAR de l'application Looker
Le schéma suivant illustre les interactions entre les composants. En règle générale, un équilibreur de charge distribue le trafic réseau entre les nœuds Looker en cluster. Chaque nœud communique avec une base de données d'application MySQL partagée, un répertoire de stockage partagé et les serveurs Git pour chaque projet LookML.
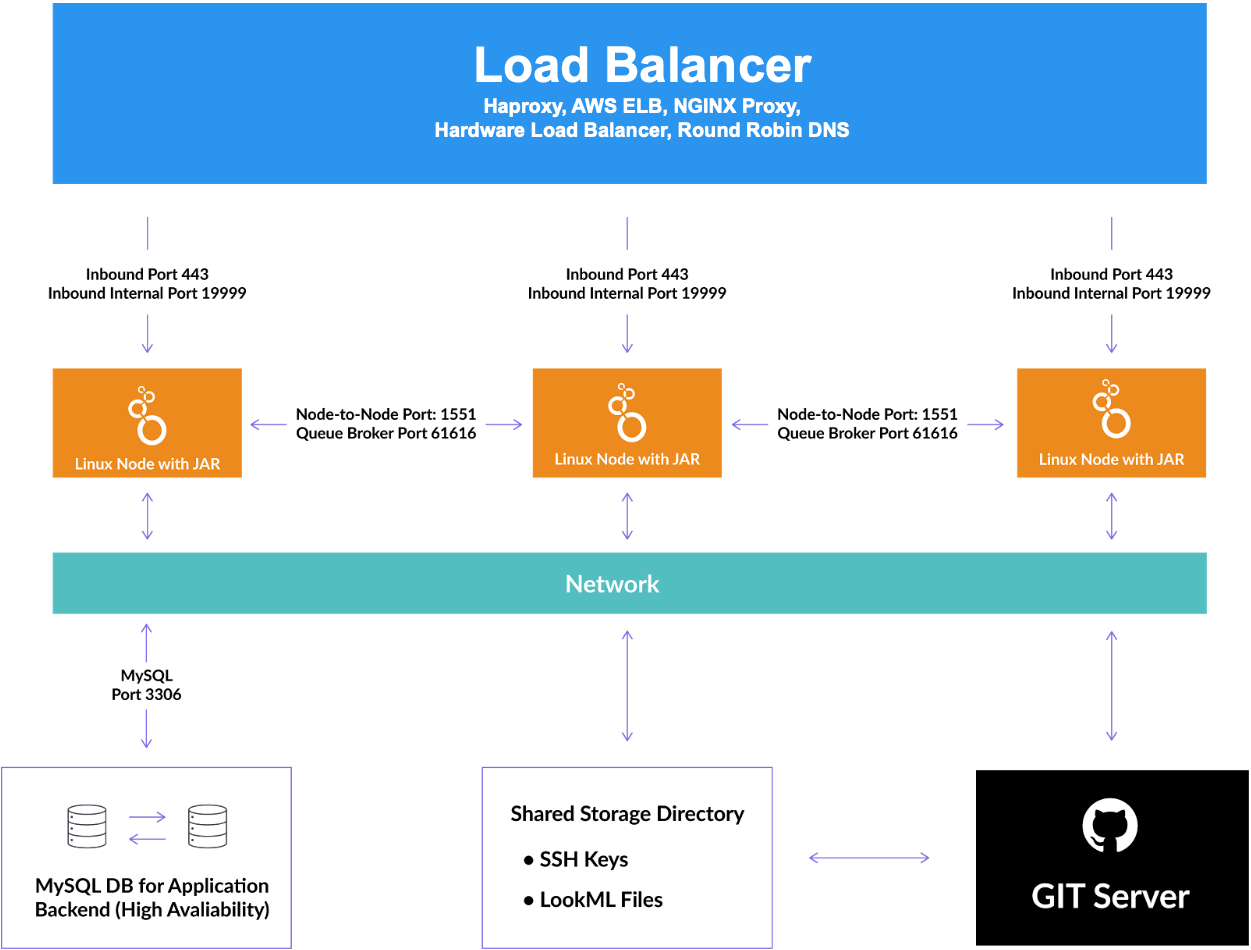
Base de données d'application MySQL
Looker utilise une base de données d'application (souvent appelée base de données interne) pour stocker les données de l'application. Lorsque Looker s'exécute en tant qu'application à nœud unique, il utilise normalement une base de données HyperSQL en mémoire.
Dans une configuration Looker en cluster, l'instance Looker de chaque nœud doit pointer vers une base de données transactionnelle partagée (base de données interne ou d'application partagée). La prise en charge de la base de données d'application pour les instances Looker en cluster est la suivante :
- Seul MySQL est compatible avec la base de données d'application pour les instances Looker en cluster. Amazon Aurora et MariaDB ne sont pas acceptés.
- Les versions 5.7 et ultérieures de MySQL sont compatibles.
- Les bases de données en cluster telles que Galera ne sont pas acceptées.
Looker ne gère pas la maintenance ni les sauvegardes de cette base de données. Toutefois, comme la base de données héberge la quasi-totalité des données de configuration de l'application Looker, elle doit être provisionnée en tant que base de données à haute disponibilité et sauvegardée au moins une fois par jour.
Nœuds Looker
Chaque nœud est un serveur sur lequel s'exécute le processus Java de Looker. Les serveurs du cluster Looker doivent pouvoir se joindre mutuellement et accéder à la base de données de l'application Looker. Les ports par défaut sont listés dans Ouvrir les ports pour la communication des nœuds sur cette page.
Équilibreur de charge
Pour équilibrer la charge ou rediriger les requêtes vers les nœuds disponibles, un équilibreur de charge ou un serveur proxy (par exemple, NGINX ou AWS ELB) est nécessaire pour diriger le trafic vers chaque nœud Looker. L'équilibreur de charge gère les vérifications de l'état. En cas de défaillance d'un nœud, l'équilibreur de charge doit être configuré pour rediriger le trafic vers les nœuds opérationnels restants.
Lorsque vous choisissez et configurez l'équilibreur de charge, assurez-vous qu'il peut être configuré pour fonctionner uniquement en tant que couche 4. L'équilibreur de charge classique Amazon ELB en est un exemple. De plus, l'équilibreur de charge doit avoir un délai avant expiration long (3 600 secondes) pour éviter que les requêtes ne soient interrompues.
Système de fichiers partagé
Vous devez utiliser un système de fichiers partagé conforme à POSIX (tel que NFS, AWS EFS, Gluster, BeeGFS, Lustre ou de nombreux autres). Looker utilise le système de fichiers partagé comme dépôt pour diverses informations utilisées par tous les nœuds du cluster.
Application Looker (fichier JAR exécutable)
Vous devez utiliser un fichier JAR d'application Looker version 3.56 ou ultérieure.
Looker recommande vivement que chaque nœud d'un cluster exécute la même version de Looker et le même correctif, comme indiqué dans Démarrer Looker sur les nœuds sur cette page.
Configurer le cluster
Les tâches suivantes sont obligatoires :
- Installer Looker
- Configurer une base de données d'application MySQL
- Configurer le système de fichiers partagé
- Partagez le dépôt de clés SSH (selon votre situation).
- Ouvrez les ports pour que les nœuds puissent communiquer.
- Démarrer Looker sur les nœuds
Installer Looker
Assurez-vous d'avoir installé Looker sur chaque nœud à l'aide des fichiers JAR de l'application Looker et des instructions de la page de documentation Procédure d'installation hébergée par le client.
Configurer une base de données d'application MySQL
Pour une configuration Looker en cluster, la base de données de l'application doit être une base de données MySQL. Si vous disposez d'une instance Looker non clusterisée existante qui utilise HyperSQL pour la base de données d'application, vous devez migrer les données d'application depuis les données HyperSQL vers votre nouvelle base de données d'application MySQL partagée.
Consultez la page de documentation Migrer vers MySQL pour savoir comment sauvegarder Looker, puis migrer la base de données de l'application de HyperSQL vers MySQL.
Configurer le système de fichiers partagé
Seuls certains types de fichiers (fichiers de modèle, clés de déploiement, plug-ins et éventuellement fichiers manifestes d'application) appartiennent au système de fichiers partagé. Pour configurer le système de fichiers partagé :
- Sur le serveur qui stockera le système de fichiers partagé, vérifiez que vous avez accès à un autre compte pouvant
suau compte utilisateur Looker. - Sur le serveur du système de fichiers partagé, connectez-vous au compte utilisateur Looker.
- Si Looker est en cours d'exécution, arrêtez votre configuration Looker.
- Si vous utilisiez auparavant des scripts Linux inotify pour le clustering, arrêtez-les, supprimez-les de cron et supprimez-les.
- Créez un partage réseau et installez-le sur chaque nœud du cluster. Assurez-vous qu'il est configuré pour le montage automatique sur chaque nœud et que l'utilisateur Looker peut y lire et y écrire. Dans l'exemple suivant, le partage réseau est nommé
/mnt/looker-share. Sur un nœud, copiez vos clés de déploiement, puis déplacez vos plug-ins et les répertoires
looker/modelsetlooker/models-user-*, qui stockent vos fichiers de modèle, vers votre partage réseau. Exemple :mv looker/models /mnt/looker-share/ mv looker/models-user-* /mnt/looker-share/Pour chaque nœud, ajoutez le paramètre
--shared-storage-diràLOOKERARGS. Spécifiez le partage réseau, comme indiqué dans cet exemple :--shared-storage-dir /mnt/looker-shareLOOKERARGSdoit être ajouté à$HOME/looker/lookerstart.cfgpour que les paramètres ne soient pas affectés par les mises à jour. Si vosLOOKERARGSne figurent pas dans ce fichier, il est possible que quelqu'un les ait ajoutés directement au script shell$HOME/looker/looker.Chaque nœud du cluster doit écrire dans un répertoire
/logunique, ou au moins dans un fichier journal unique.
Partager le dépôt de clés SSH
- Vous créez un cluster de système de fichiers partagé à partir d'une configuration Looker existante.
- Vous avez des projets créés dans Looker 4.6 ou une version antérieure.
Configurez le dépôt de clés SSH à partager :
Sur le serveur de fichiers partagé, créez un répertoire nommé
ssh-share. Exemple :/mnt/looker-share/ssh-share.Assurez-vous que le répertoire
ssh-shareappartient à l'utilisateur Looker et que les autorisations sont définies sur 700. Assurez-vous également que les répertoires situés au-dessus du répertoiressh-share(comme/mntet/mnt/looker-share) ne sont pas accessibles en écriture par tous les utilisateurs ni par le groupe.Sur un nœud, copiez le contenu de
$HOME/.sshdans le nouveau répertoiressh-share. Exemple :cp $HOME/.ssh/* /mnt/looker-share/ssh-sharePour chaque nœud, effectuez une sauvegarde du fichier SSH existant et créez un lien symbolique vers le répertoire
ssh-share. Exemple :cd $HOME mv .ssh .ssh_bak ln -s /mnt/looker-share/ssh-share .sshVeillez à effectuer cette étape pour chaque nœud.
Ouvrir les ports pour que les nœuds puissent communiquer
Les nœuds Looker en cluster communiquent entre eux via HTTPS avec des certificats autosignés et un schéma d'authentification supplémentaire basé sur des secrets rotatifs dans la base de données de l'application.
Les ports par défaut qui doivent être ouverts entre les nœuds du cluster sont les ports 1551 et 61616. Ces ports sont configurables à l'aide des options de démarrage listées ici. Nous vous recommandons vivement de limiter l'accès réseau à ces ports pour autoriser le trafic uniquement entre les hôtes du cluster.
Démarrer Looker sur les nœuds
Redémarrez le serveur sur chaque nœud avec les indicateurs de démarrage requis.
Options de démarrage disponibles
Le tableau suivant présente les options de démarrage disponibles, y compris celles qui sont requises pour démarrer ou rejoindre un cluster :
| Option | Obligatoire ? | Valeurs | Objectif |
|---|---|---|---|
--clustered |
Oui | Ajoutez un indicateur pour spécifier que ce nœud s'exécute en mode cluster. | |
-H ou --hostname |
Oui | 10.10.10.10 |
Nom d'hôte utilisé par les autres nœuds pour contacter ce nœud, tel que l'adresse IP du nœud ou le nom d'hôte de son système. Il doit être différent des noms d'hôte de tous les autres nœuds du cluster. |
-n |
Non | 1551 |
Port pour la communication entre les nœuds. La valeur par défaut est 1551. Tous les nœuds doivent utiliser le même numéro de port pour la communication entre les nœuds. |
-q |
Non | 61616 |
Port pour la mise en file d'attente des événements à l'échelle du cluster. La valeur par défaut est 61616. |
-d |
Oui | /path/to/looker-db.yml |
Chemin d'accès au fichier contenant les identifiants de la base de données de l'application Looker. |
--shared-storage-dir |
Oui | /path/to/mounted/shared/storage |
Cette option doit pointer vers le répertoire partagé configuré plus haut sur cette page, qui contient les répertoires looker/model et looker/models-user-*. |
Exemple de LOOKERARGS et de spécification des identifiants de base de données
Placez les indicateurs de démarrage Looker dans un fichier lookerstart.cfg, situé dans le même répertoire que les fichiers JAR Looker.
Par exemple, vous pouvez demander à Looker :
- Pour utiliser le fichier nommé
looker-db.ymlpour ses identifiants de base de données, - qu'il s'agit d'un nœud en cluster ;
- que les autres nœuds du cluster doivent contacter cet hôte à l'adresse IP 10.10.10.10.
Vous devez indiquer :
LOOKERARGS="-d looker-db.yml --clustered -H 10.10.10.10"
Le fichier looker-db.yml contiendrait les identifiants de la base de données, tels que :
host: your.db.hostname.com
username: db_user
database: looker
dialect: mysql
port: 3306
password: secretPassword
De plus, si votre base de données MySQL nécessite une connexion SSL, le fichier looker-db.yml doit également contenir les éléments suivants :
ssl: true
Si vous ne souhaitez pas stocker la configuration dans le fichier looker-db.yml sur le disque, vous pouvez configurer la variable d'environnement LOOKER_DB pour qu'elle contienne une liste de clés et de valeurs pour chaque ligne du fichier looker-db.yml. Exemple :
export LOOKER_DB="dialect=mysql&host=localhost&username=root&password=&database=looker&port=3306"
Trouver vos clés de déploiement SSH Git
L'emplacement où Looker stocke les clés de déploiement SSH Git dépend de la version dans laquelle le projet a été créé :
- Pour les projets créés avant Looker 4.8, les clés de déploiement sont stockées dans le répertoire SSH intégré du serveur,
~/.ssh. - Pour les projets créés dans Looker 4.8 ou version ultérieure, les clés de déploiement sont stockées dans un répertoire contrôlé par Looker,
~/looker/deploy_keys/PROJECT_NAME.
Modifier un cluster Looker
Une fois que vous avez créé un cluster Looker, vous pouvez ajouter ou supprimer des nœuds sans modifier les autres nœuds du cluster.
Mettre à jour un cluster vers une nouvelle version de Looker
Les mises à jour peuvent impliquer des modifications du schéma de la base de données interne de Looker qui ne seraient pas compatibles avec les versions précédentes de Looker. Il existe deux méthodes pour mettre à jour Looker.
Méthode plus sûre
- Créez une sauvegarde de la base de données de l'application.
- Arrêtez tous les nœuds du cluster.
- Remplacez les fichiers JAR sur chaque serveur.
- Démarrez chaque nœud un par un.
Méthode plus rapide
Pour effectuer la mise à jour à l'aide de cette méthode plus rapide, mais moins complète :
- Créez un réplica de la base de données d'application de Looker.
- Démarrez un cluster pointant vers le réplica.
- Pointez le serveur proxy ou l'équilibreur de charge vers les nouveaux nœuds, après quoi vous pourrez arrêter les anciens.