Neste tutorial, explicamos o método recomendado para criar uma configuração do Looker em cluster para instâncias hospedadas pelo cliente.
Visão geral
As implantações hospedadas pelo cliente do Looker podem executar um único nó ou em cluster:
- Um aplicativo Looker de nó único, a configuração padrão, tem todos os serviços que compõem o aplicativo Looker em execução em um único servidor.
- Uma configuração em cluster do Looker é mais complexa e geralmente envolve servidores de banco de dados, balanceadores de carga e vários servidores executando o aplicativo Looker. Cada nó em um aplicativo do Looker em cluster é um servidor que executa uma única instância do Looker.
Há dois motivos principais para uma organização querer executar o Looker como um cluster:
- Balanceamento de carga
- Melhoria na disponibilidade e no failover
Dependendo dos problemas de escalonamento, um Looker em cluster pode não oferecer a solução. Por exemplo, se um pequeno número de consultas grandes estiver usando a memória do sistema, a única solução é aumentar a memória disponível para o processo do Looker.
Alternativas de balanceamento de carga
Antes de fazer o balanceamento de carga do Looker, considere aumentar a memória e, possivelmente, a contagem de CPUs de um único servidor que executa o Looker. O Looker recomenda configurar um monitoramento detalhado de desempenho para utilização de memória e CPU para garantir que o servidor do Looker tenha o tamanho adequado para a carga de trabalho.
Consultas grandes precisam de mais memória para ter um desempenho melhor. O clustering pode melhorar o desempenho quando muitos usuários executam consultas pequenas.
Para configurações com até 50 usuários que usam o Looker de forma leve, recomendamos executar um único servidor no equivalente a uma instância grande do AWS EC2 (M4.large: 8 GB de RAM, 2 núcleos de CPU). Em configurações com mais usuários ou muitos usuários avançados ativos, observe se há picos de uso da CPU ou se os usuários notam lentidão no aplicativo. Se for o caso, mova o Looker para um servidor maior ou execute uma configuração de cluster do Looker.
Maior disponibilidade/failover
Executar o Looker em um ambiente de cluster pode reduzir o tempo de inatividade em caso de interrupção. A alta disponibilidade é especialmente importante se a API Looker for usada em sistemas comerciais principais ou se o Looker estiver incorporado a produtos voltados ao cliente.
Em uma configuração de cluster do Looker, um servidor proxy ou balanceador de carga vai redirecionar o tráfego quando determinar que um nó está inativo. O Looker processa automaticamente a saída e a entrada de nós no cluster.
Componentes obrigatórios
Os seguintes componentes são necessários para uma configuração em cluster do Looker:
- Banco de dados de aplicativos MySQL
- Nós do Looker (servidores que executam o processo Java do Looker)
- Balanceador de carga
- Sistema de arquivos compartilhados
- Versão correta dos arquivos JAR do aplicativo Looker
O diagrama a seguir ilustra como os componentes interagem. Em geral, um balanceador de carga distribui o tráfego de rede entre nós do Looker em cluster. Os nós se comunicam com um banco de dados de aplicativos MySQL compartilhado, um diretório de armazenamento compartilhado e os servidores Git de cada projeto do LookML.
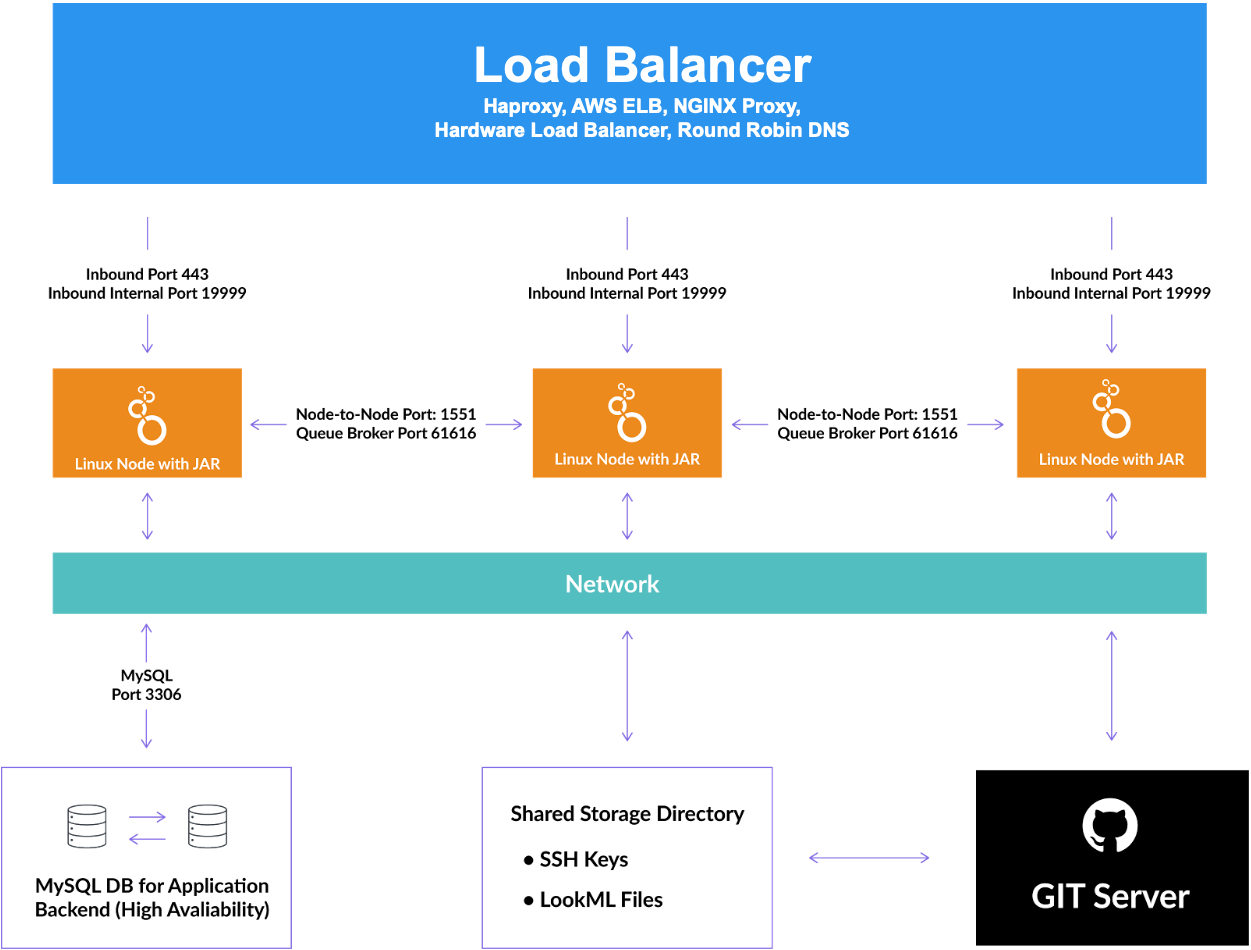
Banco de dados de aplicativos MySQL
O Looker usa um banco de dados de aplicativo (geralmente chamado de banco de dados interno) para armazenar dados de aplicativos. Quando o Looker é executado como um aplicativo de nó único, ele normalmente usa um banco de dados HyperSQL na memória.
Em uma configuração em cluster do Looker, a instância do Looker de cada nó precisa apontar para um banco de dados transacional compartilhado (o aplicativo compartilhado ou o banco de dados interno). O suporte para o banco de dados de aplicativos do Looker em cluster é o seguinte:
- Somente o MySQL é compatível com o banco de dados de aplicativos para instâncias do Looker em cluster. O Amazon Aurora e o MariaDB não são compatíveis.
- As versões 5.7 e 8.0 do MySQL são compatíveis.
- Bancos de dados em cluster, como o Galera, não são compatíveis.
O Looker não gerencia a manutenção e os backups desse banco de dados. No entanto, como o banco de dados hospeda quase todos os dados de configuração do aplicativo Looker, ele precisa ser provisionado como um banco de dados de alta disponibilidade e ter backups diários.
Nós do Looker
Cada nó é um servidor com o processo Java do Looker em execução. Os servidores no cluster do Looker precisam conseguir se comunicar entre si e com o banco de dados do aplicativo Looker. As portas padrão estão listadas em Abrir as portas para a comunicação dos nós nesta página.
Balanceador de carga
Para balancear a carga ou redirecionar solicitações a nós disponíveis, é necessário um balanceador de carga ou um servidor proxy (por exemplo, NGINX ou AWS ELB) para direcionar o tráfego a cada nó do Looker. O balanceador de carga processa as verificações de integridade. Em caso de falha de um nó, o balanceador de carga precisa ser configurado para redirecionar o tráfego aos nós íntegros restantes.
Ao escolher e configurar o balanceador de carga, verifique se ele pode ser configurado para operar somente na camada 4. O Amazon Classic ELB é um exemplo. Além disso, o balanceador de carga precisa ter um tempo limite longo (3.600 segundos) para evitar que as consultas sejam encerradas.
Sistema de arquivos compartilhados
É necessário usar um sistema de arquivos compartilhados compatível com POSIX, como NFS, AWS EFS, Gluster, BeeGFS, Lustre ou muitos outros. O Looker usa o sistema de arquivos compartilhados como um repositório para várias informações usadas por todos os nós do cluster.
Aplicativo Looker (executável JAR)
Use um arquivo JAR de aplicativo do Looker que seja da versão 3.56 ou mais recente.
O Looker recomenda que cada nó em um cluster execute a mesma versão de lançamento e patch do Looker, conforme discutido em Iniciar o Looker nos nós nesta página.
Como configurar o cluster
As seguintes tarefas são necessárias:
- Instalar o Looker
- Configurar um banco de dados de aplicativos MySQL
- Configurar o sistema de arquivos compartilhado
- Compartilhe o repositório de chaves SSH (dependendo da sua situação).
- Abra as portas para que os nós se comuniquem
- Iniciar o Looker nos nós
Como instalar o Looker
Confirme se o Looker está instalado em cada nó usando os arquivos JAR do aplicativo Looker e as instruções na página de documentação Etapas de instalação hospedada pelo cliente.
Como configurar um banco de dados de aplicativo MySQL
Para uma configuração em cluster do Looker, o banco de dados do aplicativo precisa ser um banco de dados MySQL. Se você tiver uma instância do Looker não clusterizada que usa o HyperSQL para o banco de dados de aplicativos, migre os dados do aplicativo do HyperSQL para o novo banco de dados de aplicativos MySQL compartilhado.
Consulte a página de documentação Migrar para o MySQL para saber como fazer backup do Looker e migrar o banco de dados do aplicativo do HyperSQL para o MySQL.
Como configurar o sistema de arquivos compartilhados
Somente tipos de arquivos específicos (arquivos de modelo, chaves de implantação, plug-ins e, possivelmente, arquivos de manifesto de aplicativos) pertencem ao sistema de arquivos compartilhados. Para configurar o sistema de arquivos compartilhados:
- No servidor que vai armazenar o sistema de arquivos compartilhados, verifique se você tem acesso a outra conta que pode
supara a conta de usuário do Looker. - No servidor do sistema de arquivos compartilhados, faça login na conta de usuário do Looker.
- Se o Looker estiver em execução, encerre a configuração dele.
- Se você estava usando scripts do Linux inotify para clustering, pare, remova e exclua esses scripts do cron.
- Crie um compartilhamento de rede e faça a montagem em cada nó do cluster. Confirme se ele está configurado para montagem automática em cada nó e se o usuário do Looker pode ler e gravar nele. No exemplo a seguir, o compartilhamento de rede é chamado de
/mnt/looker-share. Em um nó, copie as chaves de implantação e mova os plug-ins e os diretórios
looker/modelselooker/models-user-*, que armazenam os arquivos do modelo, para o compartilhamento de rede. Exemplo:mv looker/models /mnt/looker-share/ mv looker/models-user-* /mnt/looker-share/Para cada nó, adicione a configuração
--shared-storage-diraoLOOKERARGS. Especifique o compartilhamento de rede, conforme mostrado neste exemplo:--shared-storage-dir /mnt/looker-shareLOOKERARGSprecisa ser adicionado a$HOME/looker/lookerstart.cfgpara que as configurações não sejam afetadas por atualizações. Se osLOOKERARGSnão estiverem listados nesse arquivo, talvez alguém os tenha adicionado diretamente ao script shell$HOME/looker/looker.Cada nó no cluster precisa gravar em um diretório
/logexclusivo ou pelo menos em um arquivo de registro exclusivo.
Compartilhar o repositório de chaves SSH
- Você está criando um cluster de sistema de arquivos compartilhados com base em uma configuração do Looker, e
- Você tem projetos criados no Looker 4.6 ou em versões anteriores.
Configure o repositório de chaves SSH para ser compartilhado:
No servidor de arquivos compartilhados, crie um diretório chamado
ssh-share. Por exemplo,/mnt/looker-share/ssh-share.Verifique se o diretório
ssh-sharepertence ao usuário do Looker e se as permissões são 700. Além disso, verifique se os diretórios acima dessh-share(como/mnte/mnt/looker-share) não são graváveis por todos ou por grupos.Em um nó, copie o conteúdo de
$HOME/.sshpara o novo diretóriossh-share. Exemplo:cp $HOME/.ssh/* /mnt/looker-share/ssh-sharePara cada nó, faça um backup do arquivo SSH atual e crie um link simbólico para o diretório
ssh-share. Exemplo:cd $HOME mv .ssh .ssh_bak ln -s /mnt/looker-share/ssh-share .sshFaça isso em todos os nós.
Como abrir as portas para a comunicação dos nós
Os nós do Looker em cluster se comunicam entre si por HTTPS com certificados autoassinados e um esquema de autenticação adicional baseado em segredos rotativos no banco de dados do aplicativo.
As portas padrão que precisam estar abertas entre os nós do cluster são 1551 e 61616. Essas portas podem ser configuradas usando as flags de inicialização listadas aqui. Recomendamos restringir o acesso da rede a essas portas para permitir o tráfego apenas entre os hosts do cluster.
Como iniciar o Looker nos nós
Reinicie o servidor em cada nó com as flags de inicialização necessárias.
Flags de inicialização disponíveis
A tabela a seguir mostra as flags de inicialização disponíveis, incluindo as necessárias para iniciar ou participar de um cluster:
| Sinalização | Obrigatório? | Valores | Finalidade |
|---|---|---|---|
--clustered |
Sim | Adicione a flag para especificar que este nó está sendo executado no modo clusterizado. | |
-H ou --hostname |
Sim | 10.10.10.10 |
O nome do host que outros nós usam para entrar em contato com este nó, como o endereço IP ou o nome do host do sistema. Precisa ser diferente dos nomes de host de todos os outros nós no cluster. |
-n |
Não | 1551 |
A porta para comunicação entre nós. O padrão é 1551. Todos os nós precisam usar o mesmo número de porta para comunicação entre nós. |
-q |
Não | 61616 |
A porta para enfileirar eventos em todo o cluster. O padrão é 61616. |
-d |
Sim | /path/to/looker-db.yml |
O caminho para o arquivo que contém as credenciais do banco de dados do aplicativo Looker. |
--shared-storage-dir |
Sim | /path/to/mounted/shared/storage |
A opção deve apontar para a configuração de diretório compartilhado acima nesta página que contém os diretórios looker/model e looker/models-user-*. |
Exemplo de LOOKERARGS e especificação de credenciais do banco de dados
Coloque as flags de inicialização do Looker em um arquivo lookerstart.cfg, localizado no mesmo diretório dos arquivos JAR do Looker.
Por exemplo, você pode dizer ao Looker:
- Para usar o arquivo chamado
looker-db.ymlnas credenciais do banco de dados, - que é um nó em cluster e
- que os outros nós do cluster devem entrar em contato com esse host no endereço IP 10.10.10.10.
Você especificaria:
LOOKERARGS="-d looker-db.yml --clustered -H 10.10.10.10"
O arquivo looker-db.yml contém as credenciais do banco de dados, como:
host: your.db.hostname.com
username: db_user
database: looker
dialect: mysql
port: 3306
password: secretPassword
Além disso, se o banco de dados MySQL exigir uma conexão SSL, o arquivo looker-db.yml também vai precisar do seguinte:
ssl: true
Se você não quiser armazenar a configuração no arquivo looker-db.yml no disco, configure a variável de ambiente LOOKER_DB para conter uma lista de chaves e valores para cada linha no arquivo looker-db.yml. Exemplo:
export LOOKER_DB="dialect=mysql&host=localhost&username=root&password=&database=looker&port=3306"
Como encontrar suas chaves de implantação SSH do Git
O local em que o Looker armazena as chaves de implantação SSH do Git depende da versão em que o projeto foi criado:
- Para projetos criados antes do Looker 4.8, as chaves de implantação são armazenadas no diretório SSH integrado do servidor,
~/.ssh. - Para projetos criados no Looker 4.8 ou versões mais recentes, as chaves de implantação são armazenadas em um diretório controlado pelo Looker,
~/looker/deploy_keys/PROJECT_NAME.
Como modificar um cluster do Looker
Depois de criar um cluster do Looker, é possível adicionar ou remover nós sem fazer mudanças nos outros nós em cluster.
Atualizar um cluster para uma nova versão do Looker
As atualizações podem envolver mudanças no esquema do banco de dados interno do Looker que não seriam compatíveis com versões anteriores do Looker. Há dois métodos para atualizar o Looker.
Método mais seguro
- Crie um backup do banco de dados do aplicativo.
- Interrompa todos os nós do cluster.
- Substitua os arquivos JAR em cada servidor.
- Inicie cada nó um de cada vez.
Método mais rápido
Para atualizar usando esse método mais rápido, mas menos completo:
- Crie uma réplica do banco de dados de aplicativos do Looker.
- Inicie um novo cluster apontado para a réplica.
- Aponte o servidor proxy ou o balanceador de carga para os novos nós. Depois disso, você pode parar os nós antigos.