En la página se describen las métricas de OpenTelemetry disponibles para supervisar los recursos del Sincronizador de configuración.
Precios
Las métricas de Sincronizador de configuración usan Google Cloud Managed Service para Prometheus para cargar métricas en Cloud Monitoring. Cloud Monitoring cobra por la transferencia de estas métricas según la cantidad de muestras transferidas.
Para obtener más información, consulta los precios de Cloud Monitoring.
Cómo recopila métricas el Sincronizador de configuración
El Sincronizador de configuración usa OpenCensus para crear y registrar métricas, y OpenTelemetry para exportar sus métricas a Prometheus y Cloud Monitoring. En las siguientes guías, se explica cómo exportar métricas:
- Cloud Monitoring
- Prometheus
- Sistema de supervisión personalizado (no se recomienda)
Para configurar el recopilador de OpenTelemetry, de forma predeterminada, el Sincronizador de configuración crea un ConfigMap llamado otel-collector. La Deployment de otel-collector se ejecuta en el espacio de nombres config-management-monitoring.
La creación del ConfigMap otel-collector configura el exportador prometheus, que expone un extremo de métricas para que Prometheus lo analice.
Cuando ejecutas Sincronizador de configuración en GKE o en otro entorno de Kubernetes configurado con credenciales de Google Cloud , Sincronizador de configuración crea un ConfigMap llamado otel-collector-google-cloud. otel-collector-google-cloud anula la configuración en el ConfigMap de otel-collector. El Sincronizador de configuración revierte cualquier cambio en los ConfigMaps otel-collector o otel-collector-google-cloud.
La creación del ConfigMap otel-collector-google-cloud también agrega el exportador cloudmonitoring, que exporta a Cloud Monitoring, y el exportador kubernetes, que exporta al servicio de métricas interno de Google. El exportador kubernetes envía métricas seleccionadas y anonimizadas a Google para ayudar a mejorar el Sincronizador de configuración.
Cloud Monitoring almacena las métricas que le envías en tu proyecto deGoogle Cloud . Los exportadores de cloudmonitoring y kubernetes usan la misma cuenta de servicioGoogle Cloud , que necesita permiso de IAM para escribir en Cloud Monitoring. Para configurar estos permisos, consulta Cómo otorgar permiso de escritura de métricas para Cloud Monitoring.
Métricas de OpenTelemetry
El Sincronizador de configuración y el controlador de grupo de recursos recopilan las siguientes métricas con OpenCensus y las ponen a disposición a través del recopilador de OpenTelemetry . En la columna Etiquetas, se enumeran las etiquetas específicas de Sincronizador de configuración que se aplican a cada métrica. Las métricas con etiquetas representan varias medidas, una para cada combinación de valores de etiqueta.
Métricas del Sincronizador de configuración
| Nombre | Tipo | Etiquetas | Descripción |
|---|---|---|---|
| api_duration_seconds | Distribución | operación, estado | La distribución de latencia de las llamadas al servidor de la API. |
| apply_duration_seconds | Distribución | estado | La distribución de latencia de la aplicación de recursos declarados desde la fuente de información a un clúster. |
| apply_operations_total | Recuento | operación, estado, controlador | La cantidad total de operaciones que se realizaron para sincronizar recursos de la fuente de información con un clúster. |
| declared_resources | Último valor | La cantidad de recursos declarados que se analizaron en Git. | |
| internal_errors_total | Recuento | fuente | La cantidad total de errores internos que activó la Sincronizador de configuración. Es posible que la métrica no aparezca en los resultados de la consulta si no se produjo ningún error interno. |
| last_sync_timestamp | Último valor | estado | La marca de tiempo de la sincronización más reciente de Git. |
| parser_duration_seconds | Distribución | estado, activador, fuente | Es la distribución de latencia de las diferentes etapas involucradas en la sincronización desde la fuente de información a un clúster. |
| pipeline_error_observed | Último valor | name, reconciler, component | El estado de los recursos personalizados de RootSync y RepoSync Un valor de 1 indica un error. |
| reconcile_duration_seconds | Distribución | estado | Distribución de latencia de los eventos de conciliación manejados por el administrador de conciliación. |
| reconciler_errors | Último valor | componente, clase de error | Es la cantidad de errores que se encontraron durante la sincronización de recursos de la fuente de información con un clúster. |
| remediate_duration_seconds | Distribución | estado | Distribución de latencia de los eventos de conciliación del remediador. |
| resource_conflicts_total | Recuento | La cantidad total de conflictos de recursos que resultan de una discrepancia entre los recursos almacenados en caché y los recursos del clúster. Es posible que la métrica no aparezca en los resultados de la consulta si no se produjo un conflicto de recursos. | |
| resource_fights_total | Recuento | La cantidad total de recursos que se sincronizan con demasiada frecuencia. Cualquier resultado mayor que cero indica un problema. Para obtener más información, consulta KNV2005: ResourceFightWarning. Es posible que la métrica no aparezca en los resultados de la consulta si no se realizó una competencia de recursos. |
Métricas del controlador de grupos de recursos
El controlador de grupos de recursos es un componente del Sincronizador de configuración que realiza un seguimiento de los recursos administrados y verifica si cada recurso individual está listo o conciliado. Las siguientes métricas están disponibles.
| Nombre | Tipo | Etiquetas | Descripción |
|---|---|---|---|
| rg_reconcile_duration_seconds | Distribución | stallreason | La distribución del tiempo necesario para conciliar una CR de ResourceGroup |
| resource_group_total | Último valor | La cantidad actual de la CR de ResourceGroup | |
| resource_count | Último valor | resourcegroup | La cantidad total de recursos rastreados por un ResourceGroup |
| ready_resource_count | Último valor | resourcegroup | La cantidad total de recursos listos en un ResourceGroup |
| resource_ns_count | Último valor | resourcegroup | La cantidad de espacios de nombres que usan los recursos en un ResourceGroup |
| cluster_scoped_resource_count | Último valor | resourcegroup | La cantidad de recursos con permisos de clúster en un ResourceGroup |
| crd_count | Último valor | resourcegroup | La cantidad de CRD en un ResourceGroup |
| kcc_resource_count | Último valor | resourcegroup | La cantidad total de recursos KCC en un ResourceGroup |
| pipeline_error_observed | Último valor | name, reconciler, component | El estado de los recursos personalizados de RootSync y RepoSync Un valor de 1 indica un error. |
Etiquetas de métricas del Sincronizador de configuración
Las etiquetas de métricas se pueden usar para agregar datos de métricas en Cloud Monitoring y Prometheus. Se pueden seleccionar en la lista desplegable "Agrupar por" de la Consola de Monitoring.
Para obtener más información sobre la etiqueta de Cloud Monitoring y la etiqueta de métrica de Prometheus, consulta los Componentes del modelo de métrica y el Modelo de datos de Prometheus.
Etiquetas de métricas
El Sincronizador de configuración y las métricas del controlador de grupos de recursos usan las siguientes etiquetas, disponibles cuando se supervisan con Cloud Monitoring y Prometheus.
| Nombre | Valores | Descripción |
|---|---|---|
operation |
crear, aplicar parche, actualizar, borrar | El tipo de operación que se realizó |
status |
correcto, error | El estado de ejecución de una operación |
reconciler |
rootsync, repositoriosync | El tipo de conciliador |
source |
analizador, diferente, remediador | La fuente del error interno |
trigger |
reintento, watchUpdate, managementConflict, resync, reimportación | El activador de un evento de conciliación |
name |
El nombre del conciliador | El nombre del conciliador |
component |
análisis, fuente, sincronización, renderización, preparación | El nombre del componente o la etapa actual de la conciliación |
container |
conciliador, git-sync | El nombre del contenedor |
resource |
cpu, memoria | El tipo de recurso |
controller |
aplicador, remediador | El nombre del controlador en un conciliador raíz o de espacio de nombres |
type |
Cualquier recurso de Kubernetes, por ejemplo, ClusterRole, Namespace, NetworkPolicy, Role, etcétera. | El tipo de API de Kubernetes |
commit |
---- | Hash de la confirmación sincronizada más reciente |
Etiquetas de recursos
Las métricas del Sincronizador de configuración enviadas a Prometheus y Cloud Monitoring tienen las siguientes etiquetas de métricas configuradas para identificar el Pod de origen:
| Nombre | Descripción |
|---|---|
k8s.node.name |
El nombre del nodo que aloja un Pod de Kubernetes |
k8s.pod.namespace |
El espacio de nombres del Pod |
k8s.pod.uid |
Es el UID del Pod. |
k8s.pod.ip |
IP del Pod |
k8s.deployment.name |
Nombre del Deployment que posee el Pod |
Las métricas del Sincronizador de configuración enviadas a Prometheus y Cloud Monitoring desde los Pods reconciler también tienen las siguientes etiquetas de métricas configuradas para identificar el RootSync o RepoSync que se usa para configurar el conciliador:
| Nombre | Descripción |
|---|---|
configsync.sync.kind |
Es el tipo de recurso que configura este reconciliador: RootSync o RepoSync. |
configsync.sync.name |
Nombre del RootSync o RepoSync que configura este reconciliador |
configsync.sync.namespace |
Es el espacio de nombres de RootSync o RepoSync que configura este reconciliador. |
Etiquetas de recursos de Cloud Monitoring
Las etiquetas de recursos de Cloud Monitoring se usan para indexar métricas en el almacenamiento, lo que significa que tienen un efecto insignificante en la cardinalidad, a diferencia de las etiquetas de las métricas, en las que la cardinalidad es un problema de rendimiento importante. Consulta los tipos de recursos supervisados para obtener más información.
El tipo de recurso k8s_container establece las siguientes etiquetas de recursos para identificar el contenedor de origen:
| Nombre | Descripción |
|---|---|
container_name |
El nombre del contenedor |
pod_name |
El nombre del Pod |
namespace_name |
El espacio de nombres del Pod |
location |
Región o zona del clúster que aloja el nodo |
cluster_name |
Nombre del clúster que aloja el nodo |
project |
ID del proyecto que aloja el clúster |
Configura el filtrado de métricas personalizadas
Puedes ajustar las métricas personalizadas que Sincronizador de configuración exporta a Prometheus, Cloud Monitoring y el servicio de supervisión interno de Google. Ajusta las métricas personalizadas para optimizar las métricas incluidas o configurar diferentes back-ends.
Para modificar las métricas personalizadas, crea y, luego, edita un ConfigMap llamado otel-collector-custom. Usar este ConfigMap garantiza que Sincronizador de configuración no revierta ninguna de las modificaciones que realices. Si modificas los ConfigMaps otel-collector o otel-collector-google-cloud, el Sincronizador de configuración revierte los cambios.
Para ver ejemplos de cómo ajustar este ConfigMap, consulta Custom Metric Filtering en la documentación de código abierto del Sincronizador de configuración.
Comprende la métrica pipeline_error_observad
La métrica pipeline_error_observed es una métrica que puede ayudarte a identificar con rapidez los CR de RepoSync o RootSync que no estén sincronizados o contengan recursos que no se concilian con el estado deseado.
Para una sincronización exitosa de RootSync o RepoSync, las métricas con todos los componentes (
rendering,source,sync,readiness) se observan con el valor 0.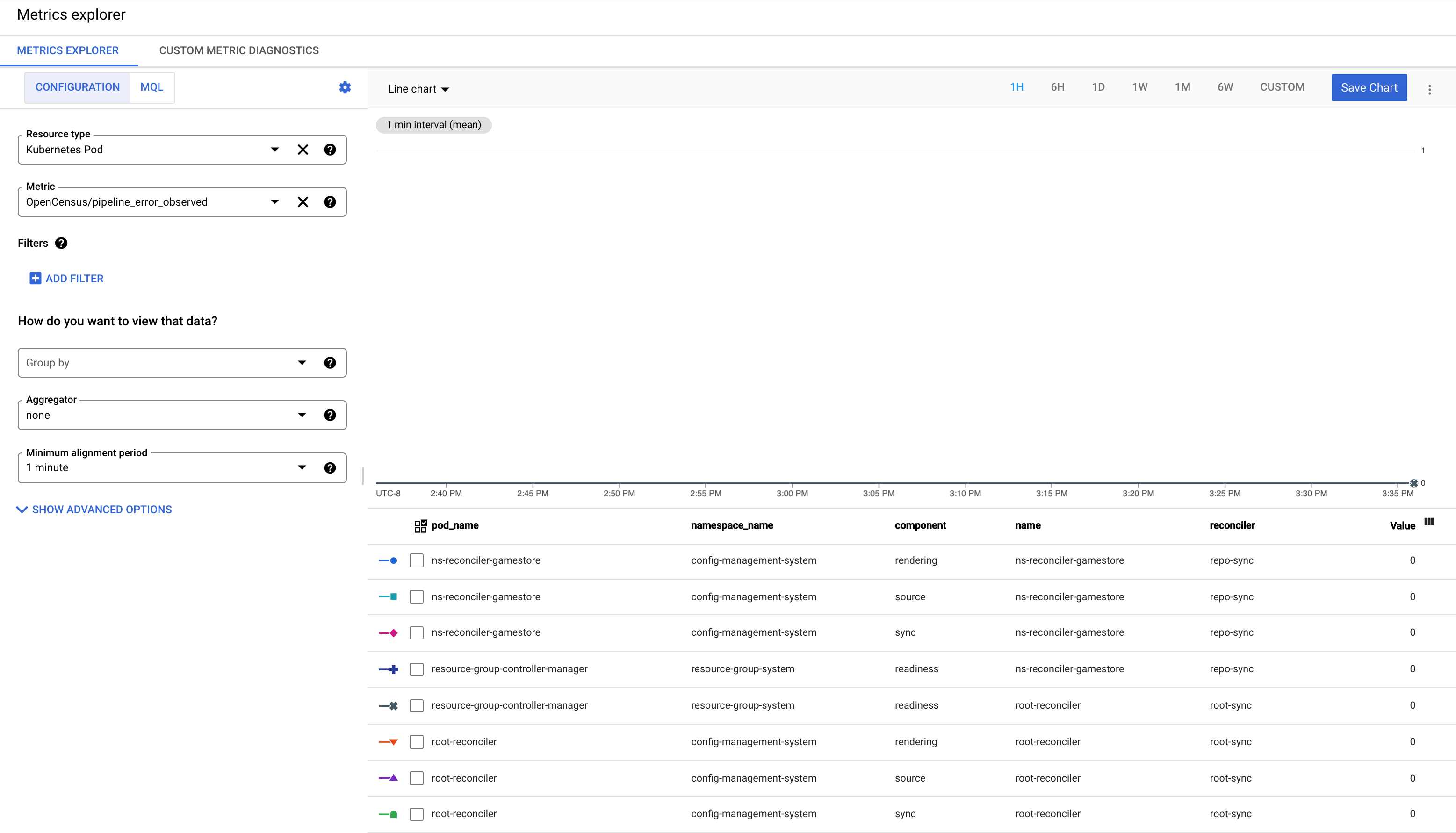
Cuando la última confirmación falla en la renderización automatizada, la métrica con el componente
renderingse observa con el valor 1.Cuando en la revisión de la confirmación más reciente ocurren errores o la última confirmación contiene una configuración no válida, la métrica con el componente
sourcese observa con el valor 1.Cuando algún recurso no se aplica al clúster, la métrica con el componente
syncse observa con el valor 1.Cuando se aplica un recurso, pero no alcanza su estado deseado, la métrica con el componente
readinessse observa con el valor 1. Por ejemplo, una implementación se aplica al clúster, pero los Pods correspondientes no se crean con éxito.
¿Qué sigue?
- Obtén más información sobre cómo supervisar objetos RootSync y RepoSync.
- Obtén más información para usar los SLI del Sincronizador de configuración.