Auf dieser Seite finden Sie einen Ausgangspunkt, um CI/CD-GitOps-Pipelines für Kubernetes zu planen und zu entwerfen. GitOps und Tools wie Config Sync bieten Vorteile wie eine verbesserte Codestabilität, bessere Lesbarkeit und Automatisierung.
GitOps ist ein schnell wachsender Ansatz für die Verwaltung der Kubernetes-Konfiguration im großen Maßstab. Je nach Ihren Anforderungen an die CI/CD-Pipeline gibt es viele Möglichkeiten, wie Sie Ihren Anwendungs- und Konfigurationscode entwerfen und organisieren können. Wenn Sie einige Best Practices für GitOps kennen, können Sie eine stabile, gut organisierte und sichere Architektur erstellen.
Diese Seite richtet sich an Administratoren, Architekten und Betreiber, die GitOps in ihrer Umgebung implementieren möchten. Weitere Informationen zu gängigen Rollen und Beispielaufgaben, auf die wir in Google Cloud -Inhalten verweisen, finden Sie unter Häufig verwendete GKE-Nutzerrollen und -Aufgaben.
Repositories organisieren
Trennen Sie beim Einrichten Ihrer GitOps-Architektur Ihre Repositories nach den Arten der Konfigurationsdateien, die in den einzelnen Repositories gespeichert sind. Generell sollten Sie mindestens vier Arten von Repositories in Betracht ziehen:
- Ein Paket-Repository für Gruppen ähnlicher Konfigurationen.
- Ein Plattform-Repository für die flottenweite Konfiguration von Clustern und Namespaces.
- Ein Anwendungskonfigurations-Repository.
- Ein Anwendungscode-Repository.
Das folgende Diagramm zeigt das Layout dieser Repositories:
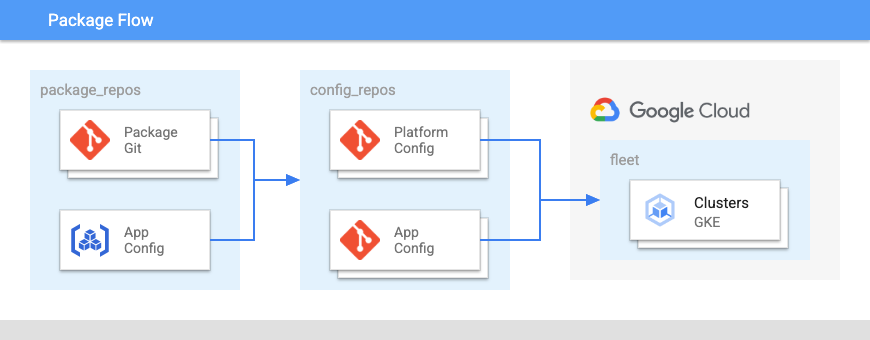
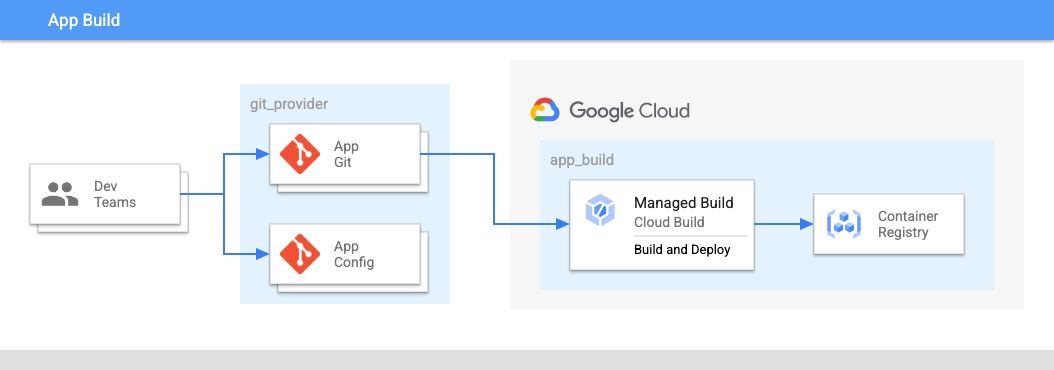
In Abbildung 2:
- Die Entwicklungsteams übertragen Code für Anwendungen und Anwendungskonfigurationen in ein Repository.
- Der Code für Apps und Konfigurationen wird am selben Ort gespeichert und die Anwendungsteams haben die Kontrolle über diese Repositories.
- Die Anwendungsteams schieben Code in einen Build.
Zentralisiertes, privates Paket-Repository verwenden
Verwenden Sie ein zentrales Repository für öffentliche oder interne Pakete, z. B. Helm-Diagramme,damit Teams Pakete leichter finden. Wenn das Repository beispielsweise logisch strukturiert ist oder eine readme enthält, können zentralisierte, private Paket-Repositories Teams dabei helfen, Informationen schnell zu finden. Sie können Dienste wie Artifact Registry oder Git-Repositories verwenden, um Ihr zentrales Repository zu organisieren.
Das Plattformteam Ihrer Organisation kann beispielsweise Richtlinien implementieren, mit denen Anwendungsteams nur Pakete aus dem zentralen Repository verwenden können.
Sie können die Schreibberechtigungen für das Repository auf eine kleine Anzahl von Entwicklern beschränken. Der Rest der Organisation kann Lesezugriff haben. Wir empfehlen, einen Prozess zur Freigabe von Paketen in das zentrale Repository und zum Übertragen von Updates zu implementieren.
Die Verwaltung eines zentralen Repositories kann zwar zusätzlichen Aufwand bedeuten, da jemand das zentrale Repository verwalten muss, und es bedeutet zusätzliche Abläufe für Anwendungsteams, aber dieser Ansatz bietet viele Vorteile:
- Ein zentrales Team kann öffentliche Pakete in einem bestimmten Rhythmus hinzufügen, um Unterbrechungen durch Verbindungsprobleme oder Änderungen in der Upstream-Umgebung zu vermeiden.
- Eine Kombination aus automatisierten und manuellen Prüfern kann Pakete auf Probleme prüfen, bevor sie allgemein verfügbar gemacht werden.
- Das zentrale Repository bietet Teams die Möglichkeit, herauszufinden, was verwendet und unterstützt wird. So können Teams beispielsweise die Standard-Redis-Bereitstellung im zentralen Repository finden.
- Sie können Änderungen an Upstream-Paketen automatisieren, damit sie interne Standards wie Standardwerte, Labels und Container-Image-Repositories erfüllen.
WET-Repositories erstellen
WET steht für „Write Everything Twice“ (Alles zweimal schreiben). Sie steht im Gegensatz zu DRY, was für „Don't Repeat Yourself“ (Nicht wiederholen) steht. Diese Ansätze stehen für zwei verschiedene Arten von Konfigurationsdateien:
- DRY-Konfigurationen, bei denen eine einzelne Konfigurationsdatei einer Transformationsaktion unterzogen wird, um Felder mit unterschiedlichen Werten für verschiedene Umgebungen zu befüllen. Sie können beispielsweise eine freigegebene Clusterkonfiguration haben, die für unterschiedliche Umgebungen mit einer anderen Region oder anderen Sicherheitseinstellungen ausgefüllt wird.
- WET-Konfigurationen (manchmal auch „vollständig hydratisierte“ Konfigurationen), bei denen jede Konfigurationsdatei den Endstatus repräsentiert.
Auch wenn WET-Repositories zu einigen wiederholten Konfigurationsdateien führen können, haben sie für einen GitOps-Workflow folgende Vorteile:
- Teammitglieder können Änderungen leichter überprüfen.
- Es ist keine Verarbeitung erforderlich, um den gewünschten Status einer Konfigurationsdatei zu sehen.
Frühere Tests bei der Validierung von Konfigurationen
Wenn Sie warten, bis Config Sync mit der Synchronisierung beginnt, um nach Problemen zu suchen, kann dies zu unnötigen Git-Commits und einer langen Feedbackschleife führen. Mithilfe von kpt-Validatorfunktionen können viele Probleme gefunden werden, bevor eine Konfiguration auf einen Cluster angewendet wird.
Sie müssen Ihrem Commit-Prozess zwar zusätzliche Tools und Logik hinzufügen, aber das Testen vor dem Anwenden von Konfigurationen bietet folgende Vorteile:
- Wenn Sie Konfigurationsänderungen in einer Änderungsanfrage angeben, können Sie Fehler vermeiden, die in ein Repository gelangen.
- Die Auswirkungen von Problemen in freigegebenen Konfigurationen werden reduziert.
Ordner anstelle von Verzweigungen verwenden
Verwenden Sie Ordner für Varianten von Konfigurationsdateien anstelle von Zweigen. Bei Ordnern können Sie mit dem Befehl tree Varianten aufrufen. Bei Zweigen können Sie nicht erkennen, ob das Delta zwischen einem Produktions- und einem Entwicklungszweig eine bevorstehende Konfigurationsänderung oder eine dauerhafte Abweichung zwischen der prod- und der dev-Umgebung ist.
Der Hauptnachteil dieses Ansatzes besteht darin, dass Sie mit Ordnern keine Konfigurationsänderungen mithilfe einer Änderungsanfrage für dieselben Dateien freigeben können. Die Verwendung von Ordnern anstelle von Verzweigungen hat jedoch folgende Vorteile:
- Die Erkennung von Ordnern ist einfacher als von Zweigen.
- Unterschiede bei Ordnern lassen sich mit vielen Befehlszeilen- und GUI-Tools erheben. Für Zweige sind diese Tools außerhalb von Git-Anbietern weniger verbreitet.
- Mit Ordnern lässt sich leichter zwischen dauerhaften und nicht beförderten Unterschieden unterscheiden.
- Sie können Änderungen in einer Änderungsanfrage für mehrere Cluster und Namespaces bereitstellen. Für Zweige sind dagegen mehrere Änderungsanfragen für verschiedene Zweige erforderlich.
Nutzung von ClusterSelectors minimieren
Mit ClusterSelectors können Sie bestimmte Teile einer Konfiguration auf eine Teilmenge von Clustern anwenden. Anstatt ein RootSync- oder RepoSync-Objekt zu konfigurieren, können Sie entweder die angewendete Ressource ändern oder den Clustern Labels hinzufügen. Dies ist zwar eine einfache Möglichkeit, einem Cluster Merkmale hinzuzufügen, aber wenn die Anzahl der ClusterSelectors im Laufe der Zeit zunimmt, kann es schwierig werden, den Endzustand des Clusters zu verstehen.
Da Sie mit Config Sync mehrere RootSync- und RepoSync-Objekte gleichzeitig synchronisieren können, können Sie die entsprechende Konfiguration einem separaten Repository hinzufügen und dann mit den gewünschten Clustern synchronisieren. So lässt sich der Endzustand des Clusters leichter nachvollziehen und Sie können die Konfigurationen für den Cluster in einem Ordner zusammenstellen, anstatt diese Konfigurationsentscheidungen direkt auf den Cluster anzuwenden.
Jobs nicht mit Config Sync verwalten
In den meisten Fällen sollten Jobs und andere situative Aufgaben von einem Dienst verwaltet werden, der die Lebenszyklusverwaltung übernimmt. Sie können diesen Dienst dann mit Config Sync verwalten, anstatt die Jobs selbst zu verwalten.
Config Sync kann Jobs zwar für Sie anwenden, Jobs eignen sich jedoch aus den folgenden Gründen nicht gut für GitOps-Bereitstellungen:
Unveränderliche Felder: Viele Jobfelder sind unveränderlich. Wenn Sie ein unveränderliches Feld ändern möchten, muss das Objekt gelöscht und neu erstellt werden. Config Sync löscht Ihr Objekt jedoch erst, wenn Sie es aus der Quelle entfernen.
Unbeabsichtigtes Ausführen von Jobs: Wenn Sie einen Job mit Config Sync synchronisieren und dieser Job dann aus dem Cluster gelöscht wird, betrachtet Config Sync dies als Abweichung vom ausgewählten Status und erstellt den Job neu. Wenn Sie eine Job-TTL (Time to Live) angeben, löscht Config Sync den Job automatisch und erstellt ihn dann wieder neu und startet ihn, bis Sie ihn aus der Source of Truth löschen.
Abgleichsprobleme: Normalerweise wartet Config Sync nach der Anwendung von Objekten auf den Abgleich. Jobs gelten jedoch als abgeglichen, wenn sie ausgeführt werden. Das bedeutet, dass Config Sync nicht auf den Abschluss des Jobs wartet, bevor andere Objekte angewendet werden. Wenn der Job jedoch später fehlschlägt, gilt dies als Fehler bei der Abstimmung. In einigen Fällen kann dies die Synchronisierung anderer Ressourcen verhindern und Fehler verursachen, bis Sie das Problem beheben. In anderen Fällen kann die Synchronisierung erfolgreich sein und nur der Abgleich schlägt fehl.
Aus diesen Gründen empfehlen wir nicht, Jobs mit Config Sync zu synchronisieren.
Unstrukturierte Repositories verwenden
Config Sync unterstützt zwei Strukturen für die Organisation eines Repositories: unstrukturiert und hierarchisch.
Die unstrukturierte Methode wird empfohlen, da Sie damit ein Repository so organisieren können, wie es für Sie am praktischsten ist.
Hierarchische Repositories erzwingen dagegen eine bestimmte Struktur, z. B. benutzerdefinierte Ressourcendefinitionen (Custom Resource Definitions, CRDs) in einem cluster-Verzeichnis.
Das kann zu Problemen führen, wenn Sie Konfigurationen freigeben müssen. Wenn beispielsweise ein Team ein Paket veröffentlicht, das eine CRD enthält, muss ein anderes Team, das dieses Paket verwenden muss, die CRD in ein cluster-Verzeichnis verschieben. Dies erhöht den Overhead des Prozesses.
Mit einem unstrukturierten Repository können Konfigurationspakete viel einfacher freigegeben und wiederverwendet werden. Ohne einen definierten Prozess oder Richtlinien für die Organisation von Repositories können die Repository-Strukturen jedoch zwischen den Teams variieren, was die Implementierung flottenabdeckungder Tools erschweren kann.
Informationen zum Konvertieren eines hierarchischen Repositorys finden Sie unter Hierarchisches Repository in ein unstrukturiertes Repository konvertieren.
Code- und Konfigurations-Repositories trennen
Beim Hochskalieren eines Monorepositorys ist ein Build für jeden Ordner erforderlich. Die Berechtigungen und Anforderungen für Personen, die am Code und an der Clusterkonfiguration arbeiten, sind in der Regel unterschiedlich.
Die Trennung von Code- und Konfigurations-Repositories bietet folgende Vorteile:
- Vermeidet Schleifen von Commits. Wenn Sie beispielsweise für ein Code-Repository ein Commit durchführen, kann dies eine CI-Anfrage auslösen, die ein Image generiert, für das dann ein Code-Commit erforderlich ist.
- Die Anzahl der erforderlichen Commits kann für die beteiligten Teammitglieder eine Belastung darstellen.
- Sie können unterschiedliche Berechtigungen für Personen verwenden, die am Anwendungscode und an der Clusterkonfiguration arbeiten.
Die Trennung von Code- und Konfigurations-Repositories hat folgende Nachteile:
- Verringert die Erkennung der Anwendungskonfiguration, da sie sich nicht im selben Repository wie der Anwendungscode befindet.
- Das Verwalten vieler Repositories kann zeitaufwendig sein.
Separate Repositories verwenden, um Änderungen zu isolieren
Beim Hochskalieren eines Monorepositories sind für verschiedene Ordner unterschiedliche Berechtigungen erforderlich. Daher können durch die Trennung von Repositories Sicherheitsgrenzen zwischen Sicherheits-, Plattform- und Anwendungskonfigurationen festgelegt werden. Außerdem empfiehlt es sich, Produktions- und Nicht-Produktions-Repositories zu trennen.
Die Verwaltung vieler Repositories kann zwar eine große Aufgabe sein, aber die Isolierung verschiedener Konfigurationstypen in verschiedenen Repositories bietet folgende Vorteile:
- In einer Organisation mit Plattform-, Sicherheits- und Anwendungsteams ist die Häufigkeit von Änderungen und Berechtigungen unterschiedlich.
- Berechtigungen bleiben auf Repository-Ebene. Mit
CODEOWNERS-Dateien können Organisationen die Schreibberechtigung einschränken und gleichzeitig die Leseberechtigung zulassen. - Config Sync unterstützt mehrere Synchronisierungen pro Namespace, was einen ähnlichen Effekt wie die Beschaffung von Dateien aus mehreren Repositories haben kann.
Paketversionen anpinnen
Unabhängig davon, ob Sie Helm oder Git verwenden, sollten Sie die Version des Konfigurationspakets an etwas anpinnen, das nicht versehentlich ohne explizites Roll-out weitergeleitet wird.
Dadurch werden Ihre Roll-outs zwar um zusätzliche Prüfungen ergänzt, wenn eine freigegebene Konfiguration aktualisiert wird, aber das Risiko, dass freigegebene Updates eine größere Auswirkung als beabsichtigt haben, wird verringert.
Workload Identity Federation für GKE verwenden
Sie können die Workload Identity Federation für GKE in GKE-Clustern aktivieren. So können Kubernetes-Arbeitslasten auf sichere und verwaltebare Weise auf Google-Dienste zugreifen.
Einige Dienste, die nicht zuGoogle Cloud gehören, wie GitHub und GitLab, unterstützen die Workload Identity Federation for GKE zwar nicht, Sie sollten sie aber nach Möglichkeit verwenden, da sie für mehr Sicherheit sorgt und die Verwaltung von Secrets und Passwörtern vereinfacht.