Esta página é um ponto de partida para planejar e arquitetar pipelines de CI/CD GitOps para o Kubernetes. O GitOps, junto com ferramentas como o Config Sync, tem benefícios como a melhoria da estabilidade do código, melhor legibilidade e automação.
O GitOps é uma abordagem em rápido crescimento para gerenciar a configuração do Kubernetes em grande escala. Dependendo dos requisitos do seu pipeline de CI/CD, há muitas opções de arquitetura e organização do código de configuração e do aplicativo. Aprenda algumas práticas recomendadas do GitOps para criar uma arquitetura estável, bem organizada e segura.
Esta página é destinada a administradores, arquitetos e operadores que querem implementar o GitOps em um ambiente. Para saber mais sobre papéis comuns e tarefas de exemplo mencionados no conteúdo do Google Cloud , consulte Tarefas e funções de usuário comuns do GKE.
Organizar os repositórios
Ao configurar sua arquitetura GitOps, separe os repositórios com base nos tipos de arquivos de configuração armazenados em cada um deles. Em geral, você pode considerar pelo menos quatro tipos de repositórios:
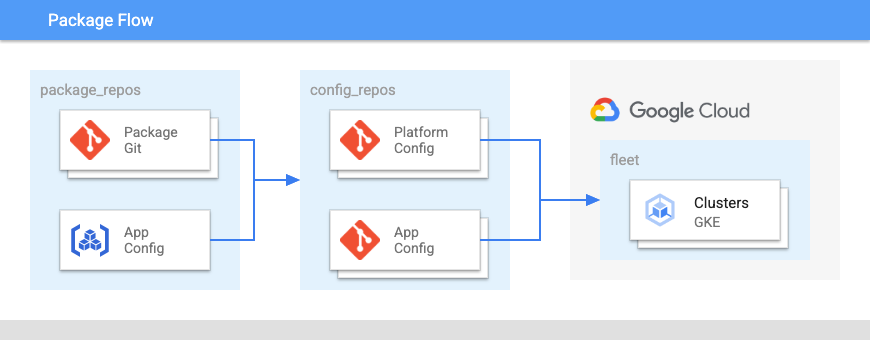
- Um repositório de pacotes para grupos de configurações relacionadas.
- Um repositório de plataforma para a configuração de frotas inteiras de clusters e namespaces.
- Um repositório de configuração de aplicativo.
- Um repositório de código do aplicativo.
O diagrama a seguir mostra o layout desses repositórios:
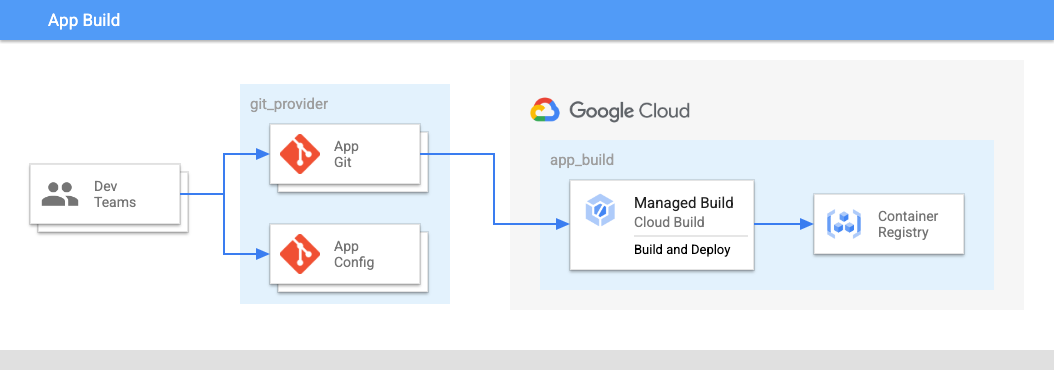
Na Figura 2:
- As equipes de desenvolvimento enviam os códigos e as configurações dos aplicativos a um repositório.
- O código dos aplicativos e das configurações é armazenado no mesmo local, e as equipes de aplicativo têm controle sobre esses repositórios.
- As equipes de aplicativos enviam o código a um build.
Usar um repositório de pacotes privado e centralizado
Use um repositório central para pacotes públicos ou internos, como gráficos do Helm, para que as equipes encontrem os pacotes facilmente. Por exemplo, quando você usa um repositório centralizado e privado, com estrutura lógica ou com um readme, as equipes encontram informações mais rapidamente. Use serviços como o
Artifact Registry ou repositórios Git para organizar o repositório central.
Por exemplo, a equipe de plataforma da organização pode implementar políticas em que as equipes de aplicativos só podem usar pacotes do repositório central.
É possível limitar as permissões de gravação ao repositório a apenas um pequeno número de engenheiros. O restante da organização pode ter acesso de leitura. Recomendamos implementar um processo para promover pacotes no repositório central e transmitir atualizações.
O repositório central gera mais trabalho (já que alguém precisa cuidar dele) e torna mais complexo o processo das equipes de aplicação, mas também traz muitos benefícios:
- Uma equipe central pode optar por adicionar pacotes públicos em uma frequência definida, o que ajuda a evitar interrupções por conectividade ou desistência upstream.
- Uma combinação de revisores automáticos e humanos pode verificar se há problemas nos pacotes antes de disponibilizá-los para todos.
- No repositório central, as equipes podem descobrir o que está em uso e tem suporte. Por exemplo, as equipes podem encontrar a implantação padrão do Redis armazenada no repositório central.
- É possível automatizar as mudanças nos pacotes upstream para garantir que eles atendam aos padrões internos, como valores padrão, adição de rótulos e repositórios de imagens de contêiner.
Criar repositórios WET
WET significa "Write Everything Twice" ("Escreva tudo duas vezes" em inglês). É o contrário de DRY, que significa "Don't Repeat Yourself" ("Não se repita" em inglês). Essas abordagens representam dois tipos diferentes de arquivos de configuração:
- Configuração DRY, em que um único arquivo de configuração passa por uma ação de transformação para preencher os campos com valores diferentes para diferentes ambientes. Por exemplo, uma configuração de cluster compartilhada, que é preenchida com uma região ou configurações de segurança diferentes para ambientes diferentes.
- Configurações WET (ou às vezes "totalmente hidratadas"), em que cada arquivo de configuração é representativo do estado final.
Embora os repositórios WET possam levar à repetição de alguns arquivos de configuração, eles têm os seguintes benefícios para um fluxo de trabalho do GitOps:
- Assim, fica mais fácil para os membros da equipe analisarem as mudanças.
- Nenhum processamento é necessário para conferir o estado desejado de um arquivo de configuração.
Teste antes ao validar as configurações
Se você só verificar se há problemas quando o Config Sync começar a sincronizar, isso poderá gerar commits desnecessárias do Git e um longo ciclo de feedback. Muitos problemas podem ser encontrados
antes que uma configuração seja aplicada a um cluster, com funções de validador kpt.
Embora seja necessário adicionar outras ferramentas e lógica ao processo de commit, o teste antes de aplicar as configurações tem os seguintes benefícios:
- A exibição de alterações de configuração em uma solicitação de alteração ajuda a evitar erros em um repositório.
- Reduz o impacto de problemas em configurações compartilhadas.
Usar pastas em vez de ramificações
Use pastas para variantes de arquivos de configuração em vez de ramificações. Com pastas, é possível usar o comando tree para mostrar as variantes. Com as ramificações, não
é possível dizer se o delta entre uma ramificação de produção e uma de desenvolvimento é uma
mudança futura na configuração ou uma diferença permanente entre os ambientes prod e dev.
A principal desvantagem dessa abordagem é que o uso de pastas não permite promover mudanças de configuração usando uma solicitação de mudança nos mesmos arquivos. No entanto, o uso de pastas em vez de ramificações tem as seguintes vantagens:
- A descoberta de pastas é mais fácil do que com as ramificações.
- É possível fazer a diferenciação em pastas com muitas ferramentas de CLI e GUI, enquanto a diferença de ramificações é menos comum fora dos provedores Git.
- Com as pastas, é mais fácil distinguir as diferenças permanentes e as não promovidas.
- É possível implantar alterações em vários clusters e namespaces em uma solicitação de alteração, enquanto as ramificações exigem várias solicitações de alteração para ramificações diferentes.
Minimizar o uso de ClusterSelectors
ClusterSelectors permite aplicar determinadas partes de uma configuração a um subconjunto de clusters. Em vez de configurar um objeto RootSync ou RepoSync, é possível modificar o recurso que está sendo aplicado ou adicionar rótulos
aos clusters. Embora essa seja uma maneira leve de adicionar características a um cluster, à medida que o número de ClusterSelectors cresce com o tempo, pode ser complicado entender o estado final do cluster.
O Config Sync permite sincronizar vários RootSync e RepoSync de uma só vez, o que significa que você pode adicionar a configuração relevante a um repositório separado e sincronizá-lo com os clusters que quiser. Isso facilita a compreensão do estado final do cluster, e é possível montar as configurações do cluster em uma pasta em vez de aplicar essas decisões de configuração diretamente no cluster.
Evite gerenciar jobs com o Config Sync
Na maioria dos casos, os jobs e outras tarefas situacionais precisam ser gerenciados por um serviço que faça o gerenciamento do ciclo de vida. Então você gerencia esse serviço com o Config Sync, em vez dos próprios jobs.
Embora o Config Sync possa aplicar jobs para você, eles não são adequados para implantação do Git pelos seguintes motivos:
Campos imutáveis: muitos campos do job são imutáveis. Para alterar um campo imutável, o objeto precisa ser excluído e recriado. No entanto, o Config Sync não exclui seu objeto, a menos que você o remova da origem.
Execução não intencional de jobs: se você sincronizar um job com o Config Sync e ele for excluído do cluster, o Config Sync vai considerar isso uma discrepância em relação ao estado escolhido e recriar o job. Se você especificar um Time to live (TTL) do job, o Config Sync vai excluir e recriar automaticamente e reiniciar o job até que você o exclua da fonte da verdade.
Problemas de reconciliação: o Config Sync normalmente espera a reconciliação dos objetos após a aplicação. No entanto, os jobs são considerados reconciliados quando começam a ser executados. Isso significa que o Config Sync não espera a conclusão do job para continuar a aplicar outros objetos. No entanto, se o job falhar posteriormente, isso será considerado uma falha de reconciliação. Em alguns casos, isso pode impedir que outros recursos sejam sincronizados e causar erros até que o problema seja corrigido. Em outros casos, a sincronização pode ser bem-sucedida e apenas a reconciliação vai falhar.
Por esses motivos, não recomendamos sincronizar jobs com o Config Sync.
Usar repositórios não estruturados
O Config Sync é compatível com duas estruturas para organizar um repositório: não estruturado e hierárquico.
A abordagem não estruturada é a recomendada porque permite que você organize um repositório da maneira mais conveniente para você.
Já os repositórios hierárquicos impõem uma estrutura específica, como
definições de recursos personalizados (CRDs, na sigla em inglês) em um diretório cluster.
Isso pode causar problemas quando você precisa compartilhar configs. Por exemplo, se uma equipe publicar um pacote que contenha um CRD, outra equipe que precise usar esse pacote terá que mover o CRD para um diretório cluster, adicionando mais sobrecarga ao processo.
Ao usar um repositório não estruturado, fica muito mais fácil compartilhar e reutilizar pacotes de configuração. No entanto, sem um processo ou diretrizes definidos para organizar repositórios, as estruturas podem variar entre as equipes, o que dificulta a implementação de ferramentas para toda a frota.
Para saber como converter um repositório hierárquico, consulte Converter um repositório hierárquico em um repositório não estruturado.
Separar código e repositórios de configuração
Ao escalonar verticalmente um monorepositório, ele exige um build específico para cada pasta. Permissões e preocupações para pessoas que trabalham no código e na configuração do cluster geralmente são diferentes.
A separação de repositórios de código e configuração tem os seguintes benefícios:
- Evita "loops" de commits. Por exemplo, uma commit em um repositório de código pode acionar uma solicitação de CI, que pode produzir uma imagem, o que requer uma commit do código.
- O número de commits necessárias pode ficar pesado para os membros da equipe que contribuem.
- É possível usar permissões diferentes para pessoas que trabalham no código do aplicativo e na configuração do cluster.
Separar código e repositórios de configuração tem as seguintes desvantagens:
- Reduz a descoberta da configuração do aplicativo, já que ele não está no mesmo repositório que o código do aplicativo.
- O gerenciamento de muitos repositórios pode ser demorado.
Usar repositórios separados para isolar alterações
Ao escalonar um repositório mono, permissões diferentes são necessárias em pastas diferentes. Por isso, a separação de repositórios permite limites de segurança entre a segurança, a plataforma e a configuração do aplicativo. Também é uma boa ideia separar os repositórios de produção e não produção.
Embora gerenciar muitos repositórios possa ser uma tarefa grande por si só, isolar diferentes tipos de configuração em repositórios diferentes tem os seguintes benefícios:
- Em uma organização com equipes de plataforma, segurança e aplicativos, a frequência de alterações e permissões é diferente.
- As permissões permanecem no nível do repositório. Os arquivos
CODEOWNERSpermitem que as organizações limitem a permissão de gravação sem impedir a permissão de leitura. - O Config Sync é compatível com várias sincronizações por namespace, o que pode gerar um efeito semelhante ao de buscar arquivos de vários repositórios.
Fixar versões do pacote
Seja usando o Helm ou o Git, você precisa fixar a versão do pacote de configuração em algo que não seja movido acidentalmente sem uma implementação explícita.
Embora isso adicione verificações extras aos seus lançamentos quando uma configuração compartilhada é atualizada, reduz o risco de atualizações compartilhadas terem um impacto maior do que o pretendido.
Usar a Federação de Identidade da Carga de Trabalho para GKE
É possível ativar a Federação de Identidade da Carga de Trabalho para GKE nos clusters do GKE, o que permite que as cargas de trabalho do Kubernetes acessem os serviços do Google de maneira segura e gerenciável.
Embora alguns serviços que não são doGoogle Cloud , como o GitHub e o GitLab, não ofereçam suporte à Federação de Identidade da Carga de Trabalho para GKE, tente usar essa federação sempre que possível devido ao aumento da segurança e à redução da complexidade do gerenciamento de segredos e senhas.