Começar a usar as recomendações de mídia
Crie rapidamente um app de recomendações de mídia de última geração. As recomendações de mídia permitem que seu público descubra um conteúdo mais personalizado, como o que assistir ou ler em seguida, com resultados com qualidade do Google e personalizados por objetivos de otimização.
Para informações gerais sobre a Vertex AI para Pesquisa em mídia, consulte Introdução à pesquisa e recomendações de mídia.Neste tutorial para começar, você vai usar o conjunto de dados Movielens para demonstrar como fazer upload do seu catálogo de conteúdo de mídia e eventos do usuário para a Vertex AI para Pesquisa, além de treinar um modelo personalizado de recomendação de filme. O conjunto de dados Movielens contém um catálogo de filmes (documentos) e classificações de filmes do usuário (eventos do usuário).
Neste tutorial, você vai treinar um modelo de recomendação do tipo "Outras categorias que você pode gostar" otimizado para taxa de cliques (CTR, na sigla em inglês). Após o treinamento, o modelo pode recomendar filmes com base em um ID de usuário e em um filme semente.
Para atender aos requisitos mínimos de dados do modelo, cada classificação positiva de filmes (4 ou mais) é tratada como um evento de item de visualização.
Tempo estimado para concluir este tutorial:
- Etapas iniciais para iniciar o treinamento do modelo: aproximadamente 1,5 hora.
- Aguardando o treinamento do modelo: aproximadamente 24 horas. (Treinar o modelo)
- Avaliação das previsões do modelo e limpeza: aproximadamente 30 minutos. (Recomendações de prévia)
Se você concluiu o tutorial Introdução à pesquisa de mídia e ainda tiver o repositório de dados (nome sugerido quickstart-media-data-store), será possível usar esse repositório em vez de
criar outro. Nesse caso, inicie o tutorial em
Criar um app para recomendações de mídia.
Objetivos
- Saiba como importar documentos de mídia e dados de eventos do usuário do BigQuery para a Vertex AI para Pesquisa.
- Treine e avalie modelos de recomendação.
Antes de seguir este tutorial, siga as etapas descritas em Antes de começar.
Para seguir as instruções detalhadas desta tarefa diretamente no console do Google Cloud , clique em Orientação:
Antes de começar
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the AI Applications, Cloud Storage, BigQuery APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Make sure that you have the following role or roles on the project: Discovery Engine Admin
Check for the roles
-
In the Google Cloud console, go to the IAM page.
Go to IAM - Select the project.
-
In the Principal column, find all rows that identify you or a group that you're included in. To learn which groups you're included in, contact your administrator.
- For all rows that specify or include you, check the Role column to see whether the list of roles includes the required roles.
Grant the roles
-
In the Google Cloud console, go to the IAM page.
Acessar o IAM - Selecione o projeto.
- Clique em Conceder acesso.
-
No campo Novos principais, insira seu identificador de usuário. Normalmente, é o endereço de e-mail de uma Conta do Google.
- Na lista Selecionar um papel, escolha um.
- Para conceder outros papéis, adicione-os clicando em Adicionar outro papel.
- Clique em Salvar.
-
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the AI Applications, Cloud Storage, BigQuery APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Make sure that you have the following role or roles on the project: Discovery Engine Admin
Check for the roles
-
In the Google Cloud console, go to the IAM page.
Go to IAM - Select the project.
-
In the Principal column, find all rows that identify you or a group that you're included in. To learn which groups you're included in, contact your administrator.
- For all rows that specify or include you, check the Role column to see whether the list of roles includes the required roles.
Grant the roles
-
In the Google Cloud console, go to the IAM page.
Acessar o IAM - Selecione o projeto.
- Clique em Conceder acesso.
-
No campo Novos principais, insira seu identificador de usuário. Normalmente, é o endereço de e-mail de uma Conta do Google.
- Na lista Selecionar um papel, escolha um.
- Para conceder outros papéis, adicione-os clicando em Adicionar outro papel.
- Clique em Salvar.
-
- Abra o console doGoogle Cloud .
- Selecionar o projeto Google Cloud .
- Anote o ID do projeto no card Informações do projeto na página do painel. Você vai precisar do ID do projeto para os procedimentos a seguir.
Clique no botão Ativar o Cloud Shell na parte superior do console. Uma sessão do Cloud Shell é aberta dentro de um novo frame na parte inferior do consoleGoogle Cloud , e exibe um prompt de linha de comando. Para outras maneiras de iniciar o Cloud Shell, consulte Iniciar o Cloud Shell.

Execute o comando a seguir usando o ID do projeto para definir o projeto padrão para a linha de comando.
gcloud config set project PROJECT_IDCrie um conjunto de dados do BigQuery:
bq mk movielensCarregue
movies.csvem uma nova tabelamoviesdo BigQuery:bq load --skip_leading_rows=1 movielens.movies \ gs://cloud-samples-data/gen-app-builder/media-recommendations/movies.csv \ movieId:integer,title,genresCarregue
ratings.csvem uma nova tabelaratingsdo BigQuery:bq load --skip_leading_rows=1 movielens.ratings \ gs://cloud-samples-data/gen-app-builder/media-recommendations/ratings.csv \ userId:integer,movieId:integer,rating:float,time:timestampCrie uma visualização que converta a tabela de filmes na imagem definida pelo Google no Esquema
Document:bq mk --project_id=PROJECT_ID \ --use_legacy_sql=false \ --view ' WITH t AS ( SELECT CAST(movieId AS string) AS id, SUBSTR(title, 0, 128) AS title, SPLIT(genres, "|") AS categories FROM `PROJECT_ID.movielens.movies`) SELECT id, "default_schema" as schemaId, null as parentDocumentId, TO_JSON_STRING(STRUCT(title as title, categories as categories, CONCAT("http://mytestdomain.movie/content/", id) as uri, "2023-01-01T00:00:00Z" as available_time, "2033-01-01T00:00:00Z" as expire_time, "movie" as media_type)) as jsonData FROM t;' \ movielens.movies_viewAgora a nova visualização tem o esquema esperado pela API AI Applications.
Acesse a página do BigQuery no console Google Cloud .
No painel Explorer, expanda o nome do seu projeto, o conjunto de dados
movielense clique emmovies_viewpara abrir a página de consulta para essa visualização.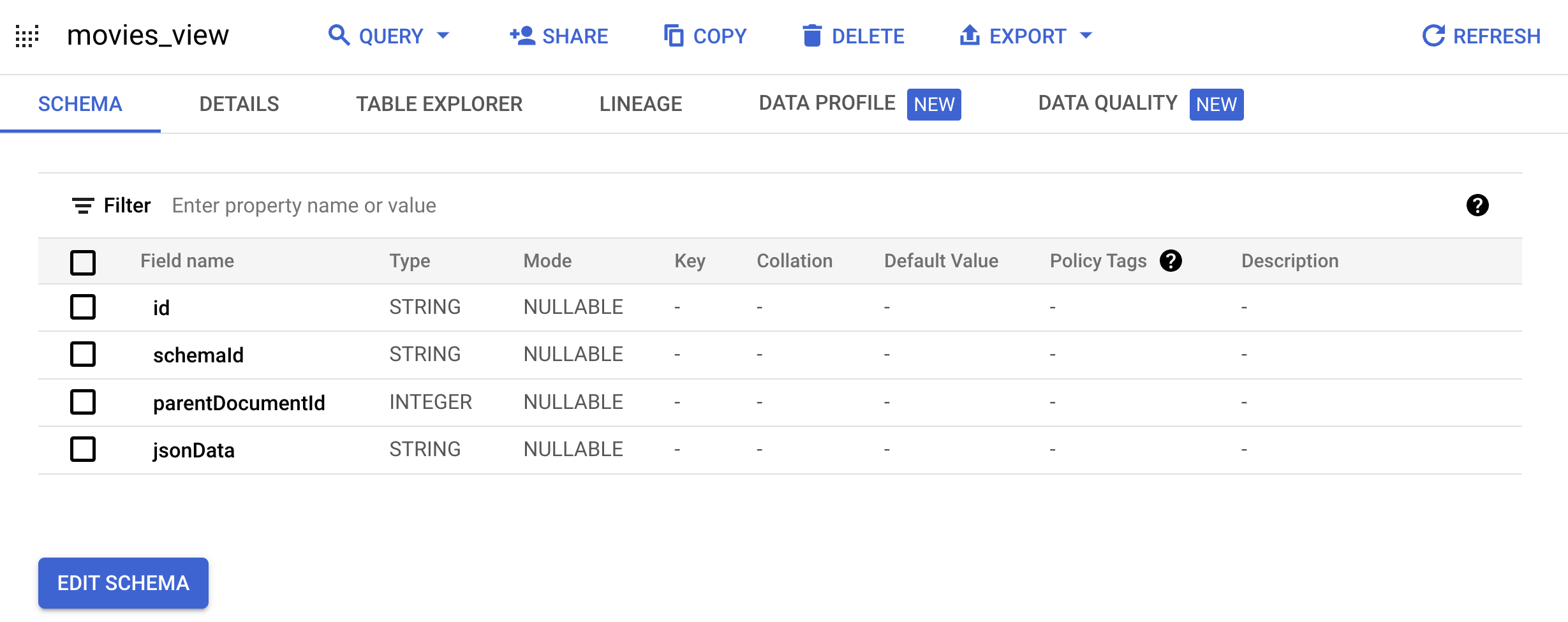
Acesse a guia Explorador de tabelas.
No painel Consulta gerada, clique no botão Copiar para consulta. O editor de consultas é aberto.
Clique em Executar para ver os dados do filme na visualização que você criou.
Crie eventos de usuário fictícios a partir de classificações de filmes executando o seguinte comando do Cloud Shell:
bq mk --project_id=PROJECT_ID \ --use_legacy_sql=false \ --view ' WITH t AS ( SELECT MIN(UNIX_SECONDS(time)) AS old_start, MAX(UNIX_SECONDS(time)) AS old_end, UNIX_SECONDS(TIMESTAMP_SUB( CURRENT_TIMESTAMP(), INTERVAL 90 DAY)) AS new_start, UNIX_SECONDS(CURRENT_TIMESTAMP()) AS new_end FROM `PROJECT_ID.movielens.ratings`) SELECT CAST(userId AS STRING) AS userPseudoId, "view-item" AS eventType, FORMAT_TIMESTAMP("%Y-%m-%dT%X%Ez", TIMESTAMP_SECONDS(CAST( (t.new_start + (UNIX_SECONDS(time) - t.old_start) * (t.new_end - t.new_start) / (t.old_end - t.old_start)) AS int64))) AS eventTime, [STRUCT(movieId AS id, null AS name)] AS documents, FROM `PROJECT_ID.movielens.ratings`, t WHERE rating >= 4;' \ movielens.user_eventsNo console Google Cloud , acesse a página Aplicativos de IA.
Opcional: clique em Permitir que o Google faça amostragens seletivas de entradas e respostas do modelo.
Clique em Continuar e ativar a API.
No console Google Cloud , acesse a página Aplicativos de IA.
Clique em
Criar app .Na página Criar app, em Recomendações de mídia, clique em Criar.
No campo Nome do app, insira um nome para seu app, como
quickstart-media-recommendations. O ID do app aparece abaixo do nome dele.Em Tipo de recomendação, selecione Outras recomendações que você pode gostar.
Em Objetivo de negócio, verifique se a opção Taxa de cliques (CTR) está selecionada.
Clique em Continuar.
Crie um repositório de dados.
Na página Repositórios de dados, clique em Criar repositório de dados.
Insira um nome de exibição para seu repositório de dados, como
quickstart-media-data-store, e clique em Criar.
Selecione o repositório de dados que você acabou de criar e clique em Criar para criar seu app.
Em Origens nativas na página Importar documentos, selecione o BigQuery.
Digite o nome da visualização
moviesdo BigQuery que você criou e clique em Importar.PROJECT_ID.movielens.movies_viewAguarde até que todos os documentos sejam importados, o que leva cerca de 15 minutos. Haverá 86537 documentos após a conclusão.
Verifique o status da operação de importação na guia Atividade. Quando a importação for concluída, o status da operação de importação será alterado para Concluído.
Na guia Eventos, clique em Importar eventos.
Em Origens nativas na página "Importar documentos", selecione o BigQuery.
Digite o nome da visualização
user_eventsdo BigQuery que você criou e clique em Importar.PROJECT_ID.movielens.user_eventsAguarde até que pelo menos um milhão de eventos tenham sido importados antes de prosseguir para a próxima etapa, a fim de atender aos requisitos de dados para treinar um novo modelo.
Verifique o status da operação na guia Atividade. O processo leva cerca de uma hora para ser concluído, porque você está importando milhões de linhas.
Para saber se os requisitos foram atendidos, acesse a guia Qualidade de dados > Requisitos. Mesmo depois que os eventos do usuário forem importados, pode levar algum tempo para que a guia Requisitos atualize o status para Requisitos de dados atendidos.
Acesse a página Configurações.
Clique na guia Exibição. Uma configuração de exibição já foi criada.
Se você quiser ajustar as configurações de Rebaixamento de recomendação ou Diversificação de resultados, faça isso nesta página.
Clique na guia Treinamento.
Depois que os requisitos de dados forem atendidos, o modelo começará o treinamento automaticamente. Confira o status de treinamento e ajuste nesta página.
Pode levar alguns dias para o modelo ser treinado e ficar pronto para consulta. O campo Pronto para consulta indica Sim quando o processo é concluído. É necessário atualizar a página para ver a mudança de Não para Sim.
No menu de navegação, clique em
Visualizar .Clique no campo ID do documento. Uma lista de IDs de documentos é exibida.
Digite o código do documento de origem, como
4993, para "O Senhor dos Anéis" (2001).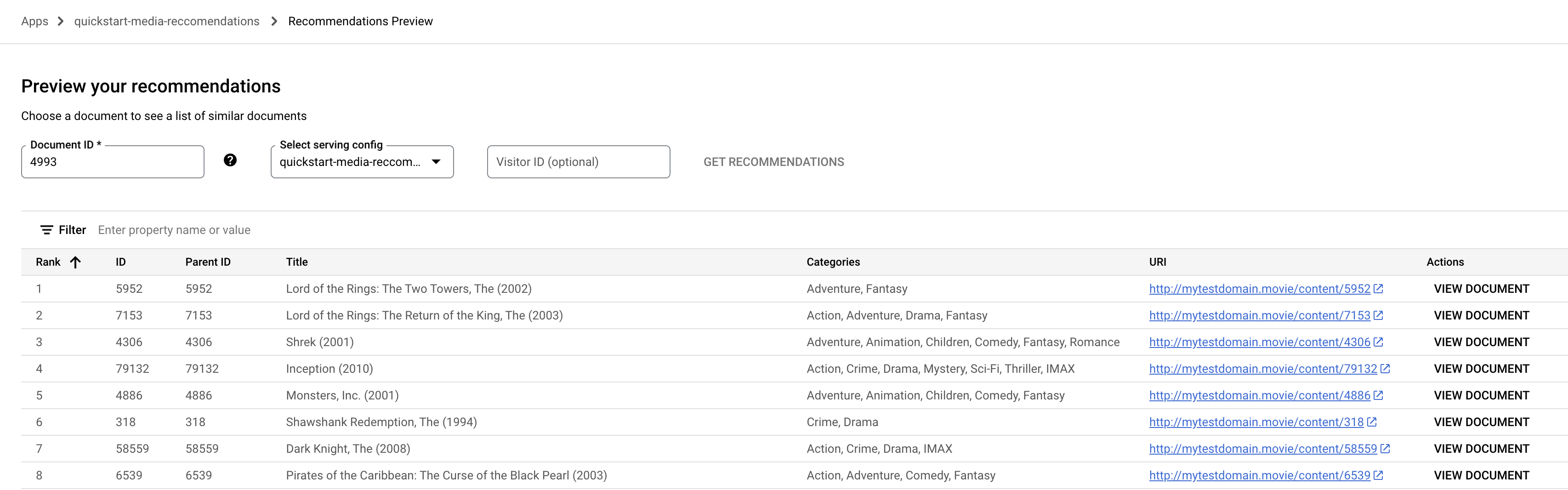
Selecione o nome da Configuração de exibição no menu suspenso.
Clique em Receber recomendações. Uma lista de documentos recomendados será exibida.
Acesse a página Dados, a guia Documentos e copie o ID de um documento.
Acesse a página Integração. Nesta página, incluímos um comando de amostra para o método
servingConfigs.recommendna API REST.Cole o ID do documento copiado no campo ID do documento.
Deixe o campo PseudoID do usuário como está.
Copie o exemplo de solicitação e execute-o no Cloud Shell.
- Para evitar cobranças do Google Cloud desnecessárias, use o Google Cloud console para excluir o projeto se ele não for mais necessário.
- Se você criou um projeto novo para aprender sobre aplicativos de IA e não precisa mais dele, exclua o projeto.
- Se você usou um projeto do Google Cloud que já existe, exclua os recursos criados para evitar cobranças na sua conta: Para mais informações, consulte Excluir um app.
- Siga as etapas em Desativar a Vertex AI para Pesquisa.
Se você criou um conjunto de dados do BigQuery, exclua-o no Cloud Shell:
bq rm --recursive --dataset movielens
Preparar o conjunto de dados
Você usará o Cloud Shell para importar o conjunto de dados Movielens e reestruturar o conjunto de dados da Vertex AI para Pesquisa para mídia.
Abrir o Cloud Shell
Importar o conjunto de dados
O conjunto de dados do Movielens está disponível em um bucket público do Cloud Storage para facilitar a importação.
Criar visualizações do BigQuery
Nesta etapa, você reestrutura o conjunto de dados do Movielens para que ele siga o formato esperado para recomendações de mídia.
As recomendações de mídia exigem dados de eventos do usuário para criar um modelo.
Neste guia, você vai criar eventos view-item falsos nos últimos 90 dias
com base em classificações positivas (>= 4).
Ativar aplicativos de IA
Criar um app para recomendações de mídia
Os procedimentos nesta seção orientam você na criação e implantação de um app de recomendações de mídia.
Importar dados
Em seguida, importe os filmes e os dados de eventos de usuário que foram formatados anteriormente.
Importar documentos
Importe o documento movies_view criado na seção Criar visualizações do BigQuery para o repositório de dados quickstart-media-data-store.
Importar eventos de usuário
Importe os registros user_events criados na seção Criar visualizações do BigQuery para o repositório de dados.
Treinar o modelo de recomendação
Recomendações de visualização
Quando o modelo estiver pronto para consulta:
Implantar o app para dados estruturados
Não há widget de recomendações para implantar o app. Para testar o app antes da implantação:
Se precisar de ajuda para integrar o app de recomendações ao seu app da Web, consulte os exemplos de código em Receber recomendações de mídia.
Limpar
Para evitar cobranças na conta do Google Cloud pelos recursos usados nesta página, siga as etapas abaixo.
É possível reutilizar o repositório de dados criado para pesquisa de mídia no tutorial Introdução à pesquisa de mídia. Siga o tutorial antes do procedimento de limpeza.