开始使用媒体推荐
您可以快速构建领先的媒体推荐应用。借助媒体推荐,您的受众群体可以发现更加个性化的内容,例如接下来要观看或阅读的内容,并提供根据优化目标自定义的 Google 品质的结果。
如需了解有关 Vertex AI Search for Media 的一般信息,请参阅媒体搜索和推荐简介。在本入门教程中,您将使用 Movielens 数据集来演示如何将媒体内容目录和用户事件上传到 Vertex AI Search 并训练个性化影片推荐模型。Movielens 数据集包含电影(文档)清单和用户电影评分(用户事件)。
在本教程中,您将训练一个针对点击率 (CTR) 进行优化的“您可能喜欢的其他内容”类型的推荐模型。训练完成后,模型可以根据用户 ID 和种子电影推荐电影。
为了满足模型的最低数据要求,每个正面的电影评分(4 分或以上)都被视为一个视图项事件。
预计完成本教程所需的时间:
如果您已完成媒体搜索使用入门教程,但仍有数据存储区(建议名称为 quickstart-media-data-store),则可以使用该数据存储区,无需另外创建一个。在这种情况下,您应该从创建用于媒体推荐的应用这一步开始学习本教程。
目标
- 了解如何将媒体文档和用户事件数据从 BigQuery 导入 Vertex AI Search。
- 训练和评估推荐模型。
在学习本教程之前,确保您已完成准备工作中的步骤。
如需在 Google Cloud 控制台中直接遵循有关此任务的分步指导,请点击操作演示:
准备工作
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Vertex AI Search (Discovery Engine), Cloud Storage, BigQuery APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Make sure that you have the following role or roles on the project: Discovery Engine Admin
Check for the roles
-
In the Google Cloud console, go to the IAM page.
Go to IAM - Select the project.
-
In the Principal column, find all rows that identify you or a group that you're included in. To learn which groups you're included in, contact your administrator.
- For all rows that specify or include you, check the Role column to see whether the list of roles includes the required roles.
Grant the roles
-
In the Google Cloud console, go to the IAM page.
前往 IAM - 选择项目。
- 点击 授予访问权限。
-
在新的主账号字段中,输入您的用户标识符。 这通常是 Google 账号的电子邮件地址。
- 在选择角色列表中,选择一个角色。
- 如需授予其他角色,请点击 添加其他角色,然后添加其他各个角色。
- 点击 Save(保存)。
-
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Vertex AI Search (Discovery Engine), Cloud Storage, BigQuery APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Make sure that you have the following role or roles on the project: Discovery Engine Admin
Check for the roles
-
In the Google Cloud console, go to the IAM page.
Go to IAM - Select the project.
-
In the Principal column, find all rows that identify you or a group that you're included in. To learn which groups you're included in, contact your administrator.
- For all rows that specify or include you, check the Role column to see whether the list of roles includes the required roles.
Grant the roles
-
In the Google Cloud console, go to the IAM page.
前往 IAM - 选择项目。
- 点击 授予访问权限。
-
在新的主账号字段中,输入您的用户标识符。 这通常是 Google 账号的电子邮件地址。
- 在选择角色列表中,选择一个角色。
- 如需授予其他角色,请点击 添加其他角色,然后添加其他各个角色。
- 点击 Save(保存)。
-
- 打开Google Cloud 控制台。
- 选择您的 Google Cloud 项目。
- 记下信息中心页面上的项目信息卡片中的项目 ID。您需要项目 ID 才能执行以下程序。
点击控制台顶部的激活 Cloud Shell 按钮。一个 Cloud Shell 会话随即会在Google Cloud 控制台底部的新框架内打开,并显示命令行提示符。 如需了解启动 Cloud Shell 的其他方法,请参阅启动 Cloud Shell。

使用您的项目 ID 运行以下命令,为命令行设置默认项目。
gcloud config set project PROJECT_ID创建 BigQuery 数据集:
bq mk movielens将
movies.csv加载到新的moviesBigQuery 表中:bq load --skip_leading_rows=1 movielens.movies \ gs://cloud-samples-data/gen-app-builder/media-recommendations/movies.csv \ movieId:integer,title,genres将
ratings.csv加载到新的ratingsBigQuery 表中:bq load --skip_leading_rows=1 movielens.ratings \ gs://cloud-samples-data/gen-app-builder/media-recommendations/ratings.csv \ userId:integer,movieId:integer,rating:float,time:timestamp创建一个将影片表转换为 Google 定义的
Document架构的视图:bq mk --project_id=PROJECT_ID \ --use_legacy_sql=false \ --view ' WITH t AS ( SELECT CAST(movieId AS string) AS id, SUBSTR(title, 0, 128) AS title, SPLIT(genres, "|") AS categories FROM `PROJECT_ID.movielens.movies`) SELECT id, "default_schema" as schemaId, null as parentDocumentId, TO_JSON_STRING(STRUCT(title as title, categories as categories, CONCAT("http://mytestdomain.movie/content/", id) as uri, "2023-01-01T00:00:00Z" as available_time, "2033-01-01T00:00:00Z" as expire_time, "movie" as media_type)) as jsonData FROM t;' \ movielens.movies_view现在,新视图具有 Discovery Engine API 所需的架构。
前往 Google Cloud 控制台的 BigQuery 页面。
在探索器窗格中,展开项目名称,展开
movielens数据集,然后点击movies_view以打开此视图的查询页面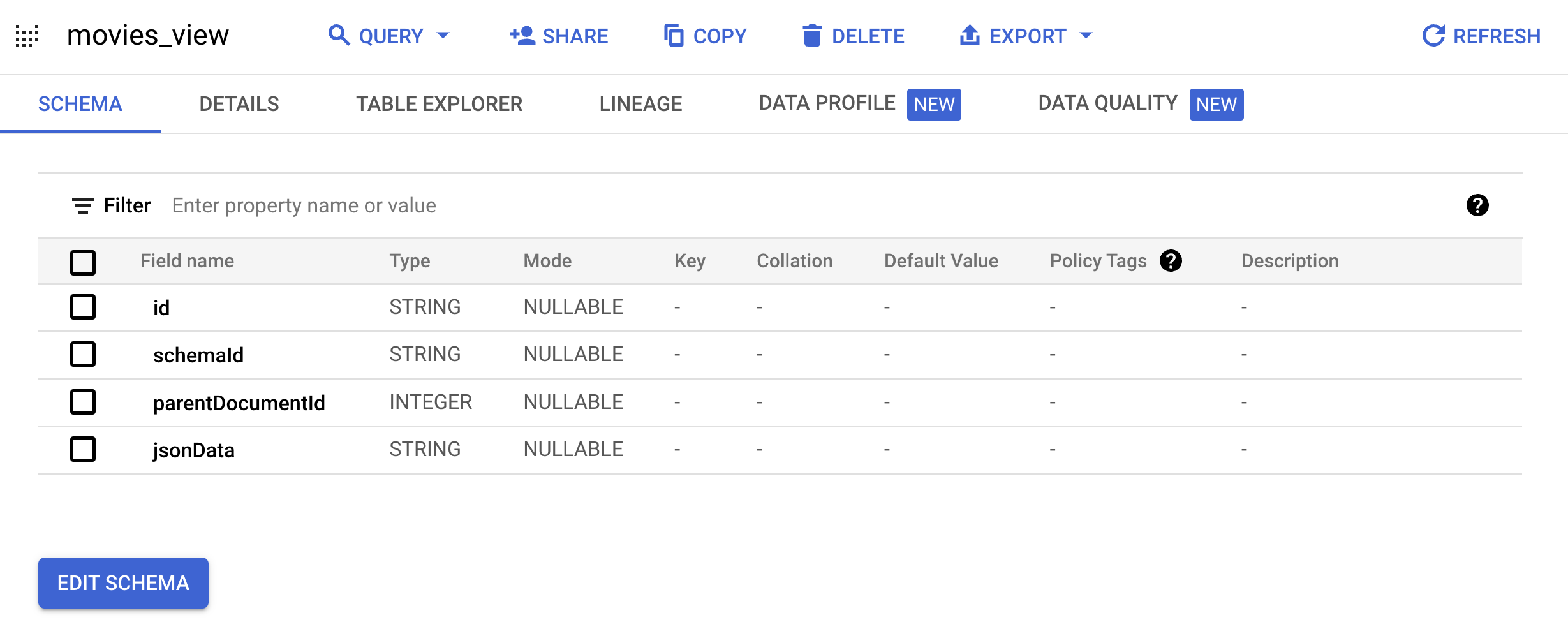
转到表探索器标签页。
在生成的查询窗格中,点击复制到查询按钮。系统随即会打开查询编辑器。
点击运行以在您创建的视图中查看电影数据。
运行以下 Cloud Shell 命令,以根据影片评分创建虚构的用户事件:
bq mk --project_id=PROJECT_ID \ --use_legacy_sql=false \ --view ' WITH t AS ( SELECT MIN(UNIX_SECONDS(time)) AS old_start, MAX(UNIX_SECONDS(time)) AS old_end, UNIX_SECONDS(TIMESTAMP_SUB( CURRENT_TIMESTAMP(), INTERVAL 90 DAY)) AS new_start, UNIX_SECONDS(CURRENT_TIMESTAMP()) AS new_end FROM `PROJECT_ID.movielens.ratings`) SELECT CAST(userId AS STRING) AS userPseudoId, "view-item" AS eventType, FORMAT_TIMESTAMP("%Y-%m-%dT%X%Ez", TIMESTAMP_SECONDS(CAST( (t.new_start + (UNIX_SECONDS(time) - t.old_start) * (t.new_end - t.new_start) / (t.old_end - t.old_start)) AS int64))) AS eventTime, [STRUCT(movieId AS id, null AS name)] AS documents, FROM `PROJECT_ID.movielens.ratings`, t WHERE rating >= 4;' \ movielens.user_events在 Google Cloud 控制台中,前往 AI Applications 页面。
可选:点击允许 Google 有选择性地对模型输入和回答进行采样。
点击继续并激活 API。
在 Google Cloud 控制台中,前往 AI Applications 页面。
点击
创建应用 。在创建应用页面的媒体推荐下方,点击创建。
在应用名称字段中,输入应用的名称,例如
quickstart-media-recommendations。应用 ID 显示在应用名称下方。确保推荐类型下的您可能喜欢的其他内容处于选中状态。
在业务目标下,确保已选择点击率 (CTR)。
点击继续。
创建数据存储区。
在数据存储区页面上,点击创建数据存储区。
为数据存储区输入一个显示名称,例如
quickstart-media-data-store,然后点击创建。
选择您刚刚创建的数据存储区,然后点击创建以创建应用。
在导入文档页面的原生来源下方,选择 BigQuery。
输入您创建的
moviesBigQuery 视图的名称,然后点击导入。PROJECT_ID.movielens.movies_view等待所有文档导入完毕,此过程大约需要 15 分钟。完成后,应该有 86537 个文档。
您可以查看活动标签页,了解导入操作状态。导入完成后,导入操作状态会更改为已完成。
在事件标签页上,点击导入事件。
在“导入文档”页面的原生来源下方,选择 BigQuery。
输入您创建的
user_eventsBigQuery 视图的名称,然后点击导入。PROJECT_ID.movielens.user_events等待导入至少一百万个事件后再继续下一步,以便满足训练新模型的数据要求。
您可以查看活动标签页,了解操作状态。由于您正在导入数百万行,因此这个过程大约需要一个小时才能完成。
如需查看是否已满足要求,请依次点击数据质量 > 要求标签页。即使在导入用户事件后,要求标签页可能需要一些时间才能将其状态更新为已满足数据要求。
转到配置页面。
点击服务标签页。已创建服务配置。
点击训练标签页。
满足数据要求后,模型会自动开始训练。您可以在此页面上查看训练和调优状态。
模型可能需要几天时间才能完成训练并准备好进行查询。该过程完成后,可供查询字段会显示是。您需要刷新页面才能看到否变为是。
在导航菜单中,点击
预览 。点击文档 ID 字段。系统会显示文档 ID 列表。
输入种子文档(电影)ID,例如
4993代表“The Lord of the Rings: The Fellowship of the Ring (2001)”。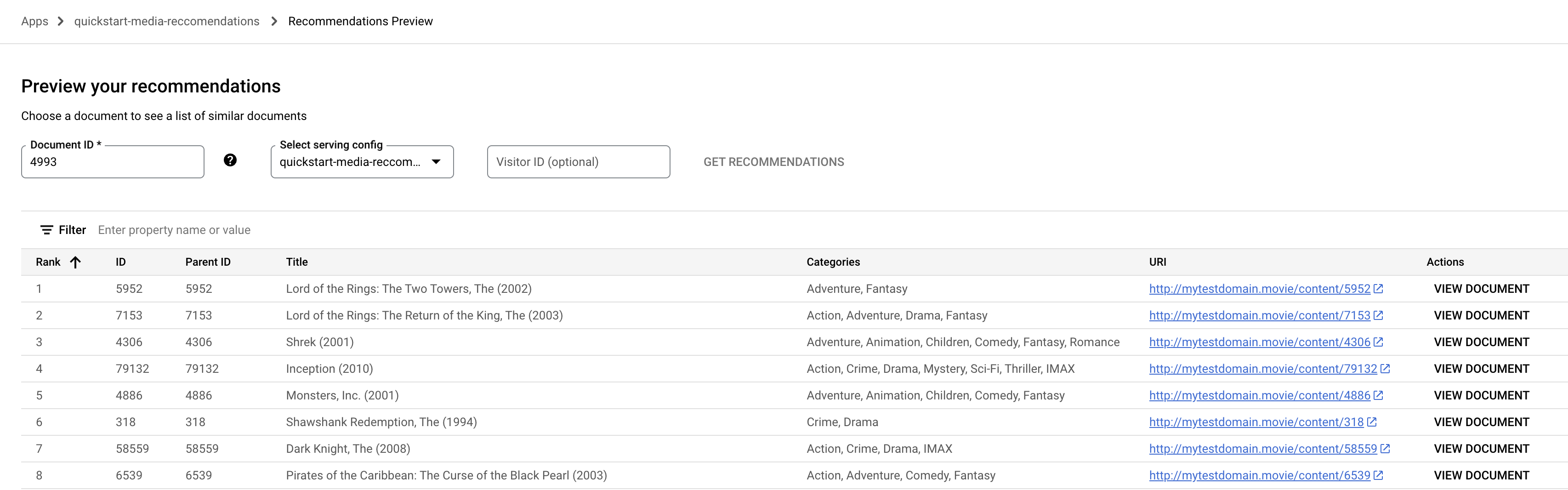
从下拉菜单中选择服务配置名称。
点击获取推荐。系统会显示推荐的文档列表。
前往数据页面、文档标签页,然后复制一个文档 ID。
转到集成页面。此页面包含 REST API 中
servingConfigs.recommend方法的示例命令。将您之前复制的文档 ID 粘贴到文档 ID 字段中。
将用户伪 ID 字段保留为原样。
复制示例请求并在 Cloud Shell 中运行它。
- 若不再需要该项目,请使用Google Cloud console 将其删除,以避免产生不必要的 Google Cloud 费用。
- 如果您为了解 Vertex AI Search 创建了一个新项目,但现在不再需要该项目,请删除项目。
- 如果您使用的是现有 Google Cloud 项目,请删除您创建的资源,以避免您的账号产生费用。如需了解详情,请参阅删除应用。
- 按照关闭 Vertex AI Search 中的步骤操作。
如果您创建了 BigQuery 数据集,请在 Cloud Shell 中将其删除:
bq rm --recursive --dataset movielens
准备数据集
您可以使用 Cloud Shell 导入 Movielens 数据集并为媒体重构 Vertex AI Search 的数据集。
打开 Cloud Shell
导入数据集
为了便于导入,Movielens 数据集位于公共 Cloud Storage 存储桶中。
创建 BigQuery 视图
在此步骤中,您将重构 MovieLens 数据集,使其符合媒体推荐所需的预期格式。
媒体推荐需要用户事件数据才能创建模型。在本指南中,您将基于正向评分 (>= 4) 创建过去 90 天内的模拟 view-item 事件。
激活 Vertex AI Search
创建用于媒体推荐的应用
本部分中的步骤将指导您创建和部署媒体推荐应用。
导入数据
接下来,导入之前设置了格式的影片和用户事件数据。
导入文档
将创建 BigQuery 视图部分中创建的 movies_view 文档导入到您的 quickstart-media-data-store 数据存储区。
导入用户事件
将创建 BigQuery 视图部分中创建的 user_events 记录导入到您的数据存储区。
训练推荐模型
预览推荐
准备好查询模型后:
针对结构化数据部署您的应用
没有用于部署应用的推荐 widget。如需在部署之前测试应用,请执行以下操作:
如需有关将推荐应用集成到 Web 应用的帮助,请参阅获取媒体推荐中的代码示例。
清理
为避免因本页中使用的资源导致您的 Google Cloud 账号产生费用,请按照以下步骤操作。
您可以重复使用在媒体搜索使用入门教程中为媒体搜索创建的数据存储区。在执行此清理过程之前,请先尝试参考该教程。