將 FHIR R4 資料匯入醫療照護搜尋應用程式後,即可查詢匯入的資料,取得相關結果。你可以使用下列類型的查詢進行搜尋:
- 關鍵字查詢
- 自然語言查詢
- 以自然語言查詢並取得生成式 AI 回覆
此外,您也可以使用依日期篩選的查詢來篩選搜尋結果。詳情請參閱定義 resource_datetime 篩選器。
在 Google Cloud 控制台中搜尋時,您必須先提供病患 ID,且一次只能搜尋單一病患的資料。使用 REST API 搜尋時,可以搜尋整個資料儲存庫。
本頁面說明如何使用各種查詢類型搜尋醫療保健資料。
Vertex AI Search 搜尋醫療照護資料的預期用途
Vertex AI Search 的用途並非提供與疾病預防、診斷或治療相關的資訊。產品不會回答有關診斷或治療建議的問題。本產品的預期用途是擷取及摘要使用者提供的現有醫療資訊。
由於測試資料有限,這項產品可能適用於 0 到 18 歲和 85 歲以上年齡層,也可能不適用。因此,在查看生成的輸出內容時,顧客必須考量來源資料中子母體的代表性。
以下列舉幾個產品的預期用途:
探索性查詢,尋找與主題相關的病患資訊:
- 「阿斯匹靈的用途摘要」
- 「血壓」
- 「糖尿病控管?」
導覽查詢:尋找可對應至結構化查詢的特定資源。
- 「Show me the most recent a1c」(顯示最近一次的糖化血色素)
擷取問題和答案,回答證據可能散布在各個資源中的特定問題:
- 「這位病患是否曾接受頭孢子素治療?」
- 「病患是否曾接受精神醫學評估」
以下是不建議的使用方式:
診斷建議和治療建議:
- 「What is the differential diagnosis for this patient?」(這位病患的鑑別診斷結果為何?)
- 「我應該為病患開立哪些藥物?」
查詢指南
請參考下列指引,建構可提供更優質搜尋結果的查詢:
搜尋特定意圖的查詢:由於模型不知道你要找什麼,因此最好提供明確的查詢,而非模糊的查詢。舉例來說,搜尋「高血壓」這個關鍵字,會比搜尋「摘要」這個關鍵字更有效。查詢「高血壓」會從相關文件中找出特定結果,但查詢「摘要」可能會從不相關的文件中找出結果。
保留脈絡:由於搜尋不是對話,因此最好為每項查詢提供完整脈絡。舉例來說,如果您的初始查詢是「高血壓」,且想追蹤同一主題,那麼「何時診斷出高血壓」會比「何時診斷出這個」更適合做為第二個查詢。
簡化查詢:盡可能將複雜查詢拆解為簡單查詢。舉例來說,如果想瞭解肌酸酐、白蛋白和肌酸酐白蛋白比值,請分別建立「肌酸酐」、「白蛋白」和「肌酸酐白蛋白比值」的查詢,而不是搜尋「肌酸酐和白蛋白」。
避免要求推論:如果模型能從搜尋的文件中原封不動地傳回資訊,而不是根據搜尋到的資訊計算或推論,搜尋結果會更精確。舉例來說,您可以查詢「列出病患最近 10 次就診的體重」,然後另外計算體重變化,而不必查詢「病患體重變化有多大」。
在結果中醒目顯示相符的項目
相符處醒目顯示設定會醒目顯示搜尋結果中,與搜尋查詢在情境上相符的文字部分。
下列資源類型的結果支援醒目顯示相符項目:
- 撰寫:醒目顯示「
Composition.section[].text.div」欄位中的情境文字。 - DiagnosticReport:醒目顯示「
DiagnosticReport.conclusion」欄位中的情境文字。 DocumentReference:醒目顯示
DocumentReference.content[0].attachment.url欄位所參照文件中的關聯文字。系統會將醒目顯示的文字 放在定界框內。搜尋回應中的兩組標準化座標代表了邊界框。支援比對醒目顯示的文件包括 PDF 檔案,以及支援類型的圖片檔案。下圖顯示如何從 DocumentReference 資源類型掃描的文件中醒目顯示文字:
圖 1. 在掃描的 DocumentReference 文件中醒目顯示相符項目。
使用 REST API 搜尋時,您必須在搜尋要求中,使用 matchHighlightingCondition 欄位啟用相符項目醒目顯示功能。回應中包含 match_highlighting 欄位,可用於在搜尋應用程式中顯示醒目顯示的文字:
- 如果是 Composition 和 DiagnosticReport 文件,
match_highlighting欄位會包含必須醒目顯示的權杖開始和結束索引。 - 如果是 DocumentReference 文件,
match_highlighting欄位會包含醒目顯示文字的定界框座標。定界框以兩組標準化座標表示,原點位於文件左上角。這個欄位也會巢狀內嵌page_number欄位,圖片會設為0,PDF 檔案的第一頁則會設為1。
使用 Google Cloud 控制台預覽搜尋結果時,系統預設會啟用相符項目醒目顯示功能。
事前準備
執行搜尋前,請先完成下列步驟:
- 建立醫療照護搜尋應用程式和醫療照護搜尋資料儲存庫,並匯入 FHIR R4 資料。詳情請參閱「建立醫療保健搜尋應用程式」和「建立醫療保健搜尋資料儲存庫」。
- 設定醫療照護資料的搜尋結果。
- 如要在搜尋時取得實用的查詢建議,請開啟自動完成功能。這是預先發布版功能。
- 查看 Vertex AI Search 支援的 FHIR R4 資源清單。詳情請參閱「Healthcare FHIR R4 資料結構定義參考資料」。
使用關鍵字搜尋
您可以使用關鍵字搜尋醫療照護資料儲存庫。舉例來說,您可以使用「糖化血色素」、「胰島素」或「潰瘍」等關鍵字進行搜尋,取得相關的 FHIR 資源。
下圖顯示關鍵字為「脂質」時的搜尋結果。這個範例不含摘要或生成式 AI 回覆。
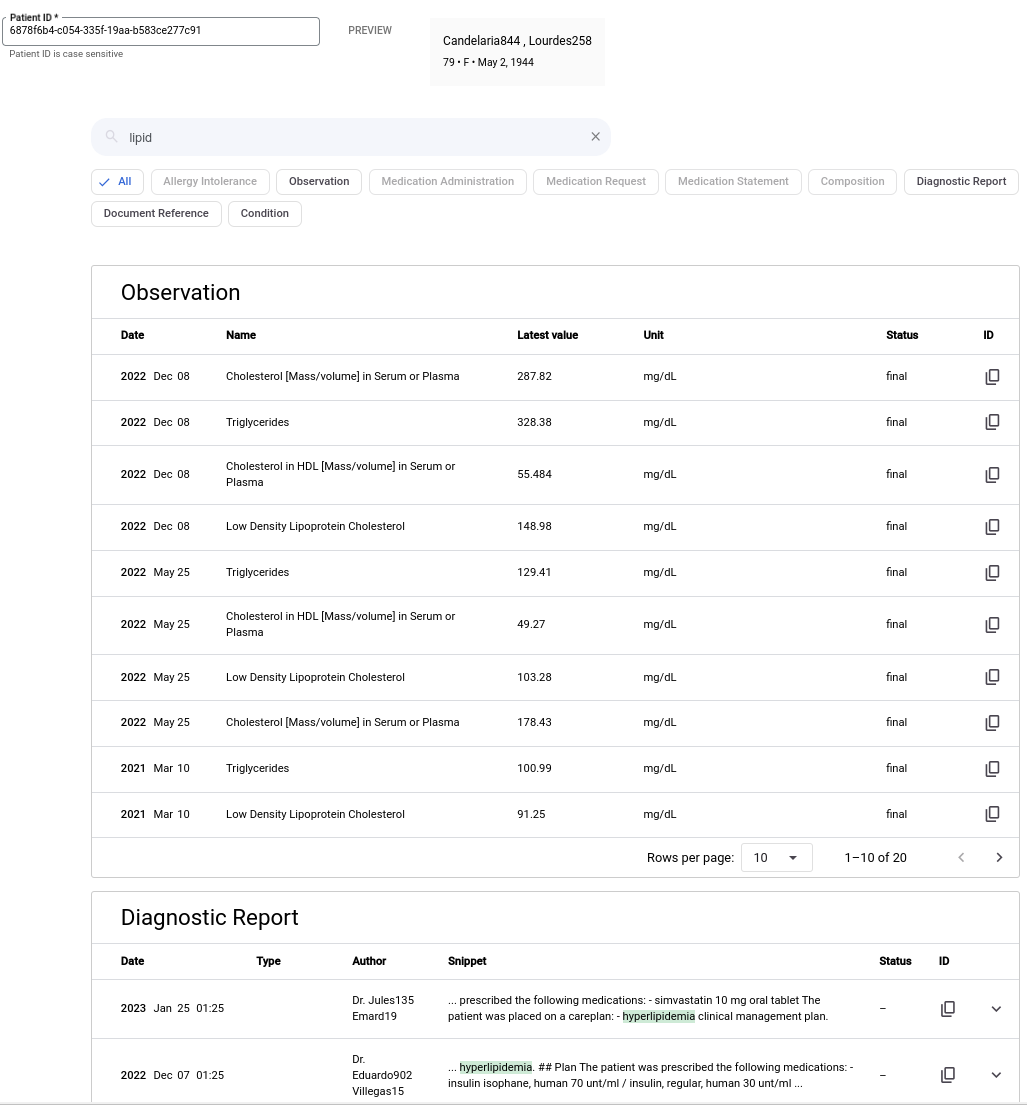
如要使用關鍵字搜尋,請完成下列步驟。
控制台
前往 Google Cloud 控制台的「AI Applications」頁面。
選取要查詢的健康搜尋應用程式。
在導覽選單中,按一下「預覽」。
在「Patient ID」(病患 ID) 欄位中,輸入要查詢資料的病患 ID。病患 ID 須區分大小寫。
按下 Enter 鍵或點選「預覽」,即可提交病患 ID。
在「在這裡搜尋」搜尋列中輸入關鍵字。
如果已啟用自動完成功能,輸入內容時,搜尋列下方會顯示自動完成建議清單。
按下 Enter 鍵提交查詢。
- 搜尋結果會顯示在分頁表格中,並依據 FHIR 資源類型分類。
- 根據預設,系統會以逆時序顯示所有 FHIR 資源類型的搜尋結果。
(選用步驟) 如要篩選結果,請選取搜尋列下方的一或多個 FHIR 資源類別。
(選用步驟) 如要依據文章、DocumentReference 和 DiagnosticReport 資源的關聯性排序結果,請按一下「排序:依時間順序倒序」篩選器,然後從清單中選取「關聯性」。詳情請參閱「排序醫療保健搜尋結果」。
REST
下列範例說明如何在醫療保健搜尋應用程式中,使用關鍵字搜尋單一病患的 FHIR R4 資料。這個範例使用 servingConfigs.search 方法。
根據預設,搜尋結果會依時間遞減順序傳回。 搜尋 Composition、DiagnosticReport 和 DocumentReference 資源時,您可以根據相關性排序搜尋結果。詳情請參閱「醫療保健搜尋結果排序」。
使用關鍵字搜尋。
curl -X POST -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ "https://us-discoveryengine.googleapis.com/v1alpha/projects/PROJECT_ID/locations/us/collections/default_collection/engines/APP_ID/servingConfigs/default_search:search" \ -d '{ "query": "KEYWORD_QUERY", "filter": "patientId: ANY(\"PATIENT_ID\")", "contentSearchSpec":{"snippetSpec":{"returnSnippet":true}} "displaySpec": { "matchHighlightingCondition": "MATCH_HIGHLIGHTING_CONDITION" } }'更改下列內容:
PROJECT_ID:您的 Google Cloud 專案 ID。APP_ID:要查詢的 Vertex AI Search 應用程式 ID。KEYWORD_QUERY:您想在經過篩選的病患臨床資料中搜尋的關鍵字,例如「糖尿病」或「糖化血色素」。PATIENT_ID:您要搜尋資料的病患資源 ID。MATCH_HIGHLIGHTING_CONDITION:字串,可包含下列值:MATCH_HIGHLIGHTING_DISABLED:關閉所有文件中的相符內容醒目顯示功能。MATCH_HIGHLIGHTING_ENABLED:開啟所有文件的相符內容醒目顯示功能。如果將這個欄位留空或未指定,系統會將相符內容醒目顯示功能設為MATCH_HIGHLIGHTING_DISABLED,並在所有文件中關閉這項功能。
使用自然語言查詢進行搜尋
使用 Vertex AI Search,您可以取得複雜自然語言查詢的結果。舉例來說,下圖顯示自然語言查詢「與糖尿病相關的實驗室結果」的結果。
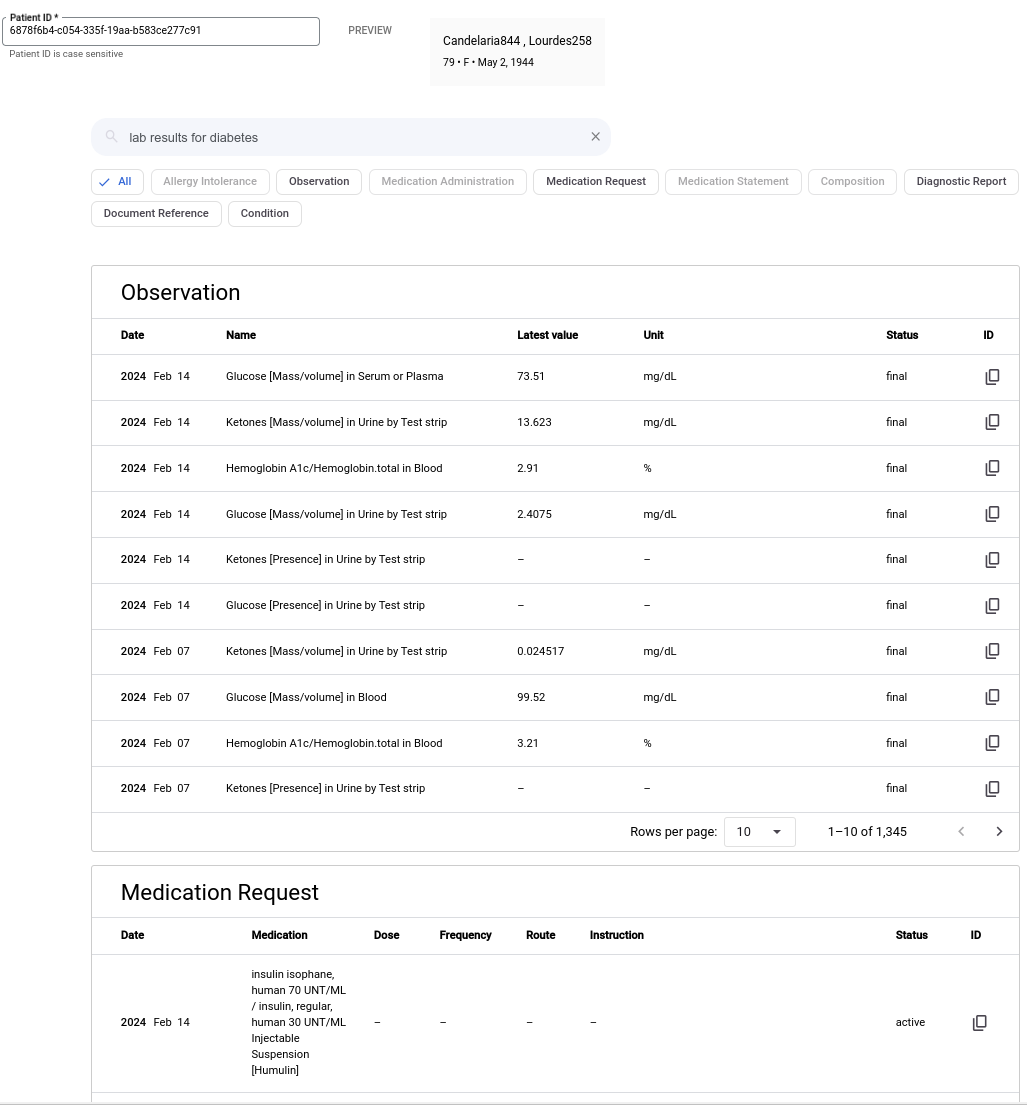
如要使用自然語言查詢進行搜尋,請完成下列步驟。
控制台
前往 Google Cloud 控制台的「AI Applications」頁面。
選取要查詢的健康搜尋應用程式。
在導覽選單中,按一下「預覽」。
在「病患 ID」欄位中,輸入要查詢資料的病患 ID。病患 ID 須區分大小寫。
按下 Enter 鍵或點選「預覽」,即可提交病患 ID。
在「Search here」(在這裡搜尋) 搜尋列中,輸入自然語言查詢,例如「與糖尿病相關的檢驗結果」。
如果已啟用自動完成功能,輸入內容時,搜尋列下方會顯示自動完成建議清單。
按下 Enter 鍵提交查詢。
- 搜尋結果會顯示在分頁表格中,並依據 FHIR 資源類型分類。
- 根據預設,系統會依時間順序由新至舊,顯示所有 FHIR 資源類型的搜尋結果。
(選用步驟) 選取搜尋列下方的一或多個 FHIR 資源類別,即可篩選結果。
(選用步驟) 如要依據文章、DocumentReference 和 DiagnosticReport 資源的關聯性排序結果,請按一下「排序:依時間順序倒序」篩選器,然後從清單中選取「關聯性」。詳情請參閱「排序醫療保健搜尋結果」。
REST
以下範例說明如何使用自然語言查詢,在醫療保健搜尋應用程式中搜尋單一病患的 FHIR R4 資料。這個範例使用 servingConfigs.search 方法。如要使用自然語言查詢進行搜尋,請務必在要求主體中加入 naturalLanguageQueryUnderstandingSpec 欄位。
根據預設,搜尋結果會依時間遞減順序傳回。 搜尋 Composition、DiagnosticReport 和 DocumentReference 資源時,您可以根據相關性排序搜尋結果。詳情請參閱「醫療保健搜尋結果排序」。
以自然語言發布查詢。
curl -X POST -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ "https://us-discoveryengine.googleapis.com/v1alpha/projects/PROJECT_ID/locations/us/collections/default_collection/engines/APP_ID/servingConfigs/default_search:search" \ -d '{ "query": "NATURAL_LANGUAGE_QUERY", "filter": "patientId: ANY(\"PATIENT_ID\")", "contentSearchSpec":{"snippetSpec":{"returnSnippet":true}}, "naturalLanguageQueryUnderstandingSpec":{"filterExtractionCondition":"ENABLED"}, "displaySpec": { "matchHighlightingCondition": "MATCH_HIGHLIGHTING_CONDITION" } }'更改下列內容:
PROJECT_ID:您的 Google Cloud 專案 ID。APP_ID:要查詢的 Vertex AI Search 應用程式 ID。NATURAL_LANGUAGE_QUERY:以自然語言提出的查詢,例如「與糖尿病相關的檢驗結果」或「病患目前是否正在服用任何藥物」。PATIENT_ID:您要搜尋資料的病患資源 ID。MATCH_HIGHLIGHTING_CONDITION:字串,可包含下列值:MATCH_HIGHLIGHTING_DISABLED:關閉所有文件中的相符內容醒目顯示功能。MATCH_HIGHLIGHTING_ENABLED:開啟所有文件的相符內容醒目顯示功能。如果將這個欄位留空或未指定,系統會將相符內容醒目顯示功能設為MATCH_HIGHLIGHTING_DISABLED,並在所有文件中關閉這項功能。
使用自然語言查詢,並取得生成式 AI 回覆
使用自然語言查詢病患的 FHIR 資料時,您可以選擇在搜尋結果中加入生成式 AI 回覆。答案會歸納搜尋結果,並顯示用來生成答案的參考資料。
使用控制台時,您可以選取生成式 AI 回覆所用的 LLM。詳情請參閱「設定醫療保健資料的搜尋結果」。
使用 REST API 時,您可以在 version 欄位中指定下列任一大型語言模型,取得生成式 AI 回覆:
gemini-1.5-flash-001/answer_gen/v1或stable:以gemini-1.5-flash-001模型為基礎的穩定模型,通常可供使用。詳情請參閱正式發布 (GA) 的模型。gemini-1.5-pro-002或preview:以gemini-1.5-pro模型為基礎的預覽模型。
下圖顯示自然語言查詢的範例,以及生成式 AI 回覆。搜尋摘要會根據相關結果的摘要,提供查詢的答案。您可以展開有引文的區隔,查看用於產生所選區隔的參考資料。並非所有生成的答案都會附上引文。
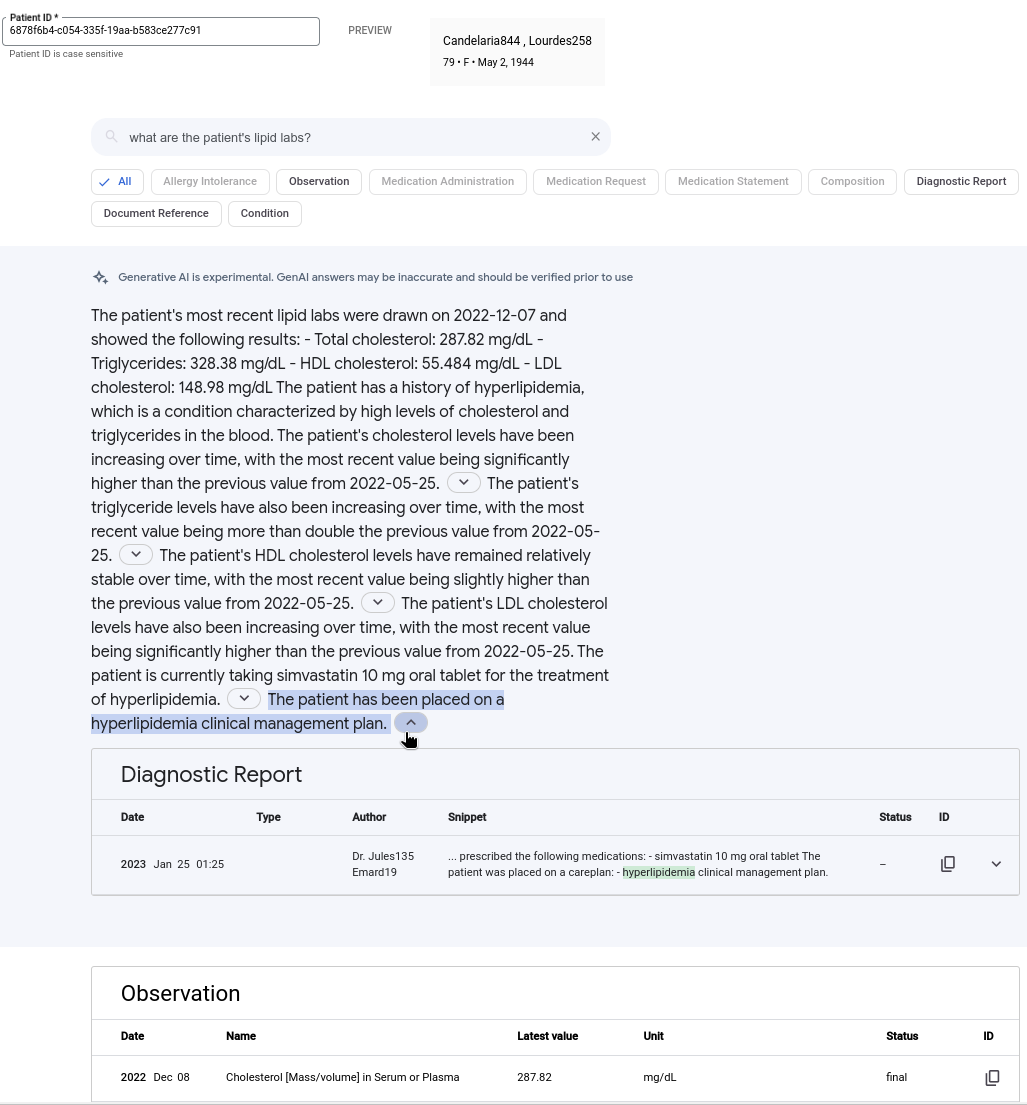
如要使用生成式 AI 回覆進行搜尋,請按照下列步驟操作:
控制台
前往 Google Cloud 控制台的「AI Applications」頁面。
選取要查詢的健康搜尋應用程式。
在導覽選單中,按一下「Configurations」(設定)。
自訂搜尋小工具:
- 在「搜尋類型」欄位中,選取「搜尋並提供答案」。
- 選取要用來生成摘要的模型。詳情請參閱「設定醫療保健資料的搜尋結果」。
- 儲存並發布偏好設定。
在導覽選單中,按一下「預覽」。
在「病患 ID」欄位中,輸入要查詢資料的病患 ID。病患 ID 須區分大小寫。
按下 Enter 鍵或點選「預覽」,即可提交病患 ID。
在「在這裡搜尋」搜尋列中,輸入自然語言查詢,例如「NSAID」、「病患的血脂實驗室為何?」或「最近一次的 A1C 結果為何?」。
如果已啟用自動完成功能,輸入內容時,搜尋列下方會顯示自動完成建議清單。
按下 Enter 鍵提交查詢。
- 生成式 AI 回覆會顯示在搜尋列下方。
- 搜尋結果會顯示在分頁表格中,並依據 FHIR 資源類型分類。
- 根據預設,系統會依時間順序由新至舊,顯示所有 FHIR 資源類型的搜尋結果。
(選用步驟) 展開附有引文的回答片段,即可查看搜尋結果中的參考資料。
(選用步驟) 選取搜尋列下方的一或多個 FHIR 資源類別,即可篩選結果。
(選用步驟) 如要依據文章、DocumentReference 和 DiagnosticReport 資源的關聯性排序結果,請按一下「排序:依時間順序倒序」篩選器,然後從清單中選取「關聯性」。詳情請參閱「排序醫療保健搜尋結果」。
REST
下列範例說明如何在醫療照護搜尋應用程式中,使用自然語言查詢並搭配生成式 AI 回覆,搜尋單一病患的 FHIR R4 資料。這個範例使用 servingConfigs.search 方法。
- 如要使用自然語言查詢進行搜尋,請在要求主體中新增
naturalLanguageQueryUnderstandingSpec欄位。 - 如要加入內文引用索引,請務必新增
includeCitations欄位。 這是布林值欄位,預設值為false。
根據預設,搜尋結果會依時間遞減順序傳回。 搜尋 Composition、DiagnosticReport 和 DocumentReference 資源時,您可以根據相關性排序搜尋結果。詳情請參閱「醫療保健搜尋結果排序」。
以自然語言發布查詢。
curl -X POST -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ "https://us-discoveryengine.googleapis.com/v1alpha/projects/PROJECT_ID/locations/us/collections/default_collection/engines/APP_ID/servingConfigs/default_search:search" \ -d '{ "query": "QUERY", "filter": "patientId: ANY(\"PATIENT_ID\")", "contentSearchSpec": { "snippetSpec": { "returnSnippet": true }, "displaySpec": { "matchHighlightingCondition": "MATCH_HIGHLIGHTING_CONDITION" } "summarySpec": { "summaryResultCount": 1, "includeCitations": true, "modelSpec": { "version": "MODEL_VERSION" } } }, "naturalLanguageQueryUnderstandingSpec": { "filterExtractionCondition": "ENABLED" } }'更改下列內容:
PROJECT_ID:您的 Google Cloud 專案 ID。APP_ID:要查詢的 Vertex AI Search 應用程式 ID。QUERY:以自然語言提出的查詢,例如「NSAID」、「患者的血脂實驗室結果為何?」或「最近一次的 A1C 結果為何?」如果查詢內容包含單引號',請務必以單引號的數字字元參照'取代。PATIENT_ID:您要搜尋資料的病患資源 ID。MODEL_VERSION:用於生成答案的模型版本。MATCH_HIGHLIGHTING_CONDITION:字串,可包含下列值:MATCH_HIGHLIGHTING_DISABLED:關閉所有文件中的相符內容醒目顯示功能。MATCH_HIGHLIGHTING_ENABLED:開啟所有文件的相符內容醒目顯示功能。如果將這個欄位留空或未指定,系統會將相符內容醒目顯示功能設為MATCH_HIGHLIGHTING_DISABLED,並在所有文件中關閉這項功能。