本頁面說明如何使用 API,在搜尋結果中取得搜尋摘要。本文也說明搜尋摘要提供的選項。 僅適用於非結構化資料和網站資料。
如要瞭解如何透過生成式 AI 回覆,查詢醫療照護資料,請參閱「使用自然語言查詢並取得生成式 AI 回覆」。
事前準備
視應用程式類型而定,請完成下列要求:
網站搜尋應用程式:開啟下列功能:
進階網站索引。需要驗證網域。
取得搜尋摘要
搜尋摘要是搜尋回覆中,最相關的一或多筆搜尋結果的簡短摘要。摘要本身是從回應中傳回的擷取答案取得。因此,如要取得摘要,您也必須在搜尋結果中取得擷取式答案。詳情請參閱「取得擷取式答案 (搶先體驗版)」。
下圖顯示使用 summaryResultCount 設為 5 查詢資料儲存庫中的 PDF 時的摘要。摘要內容可能因應用程式設定而異。
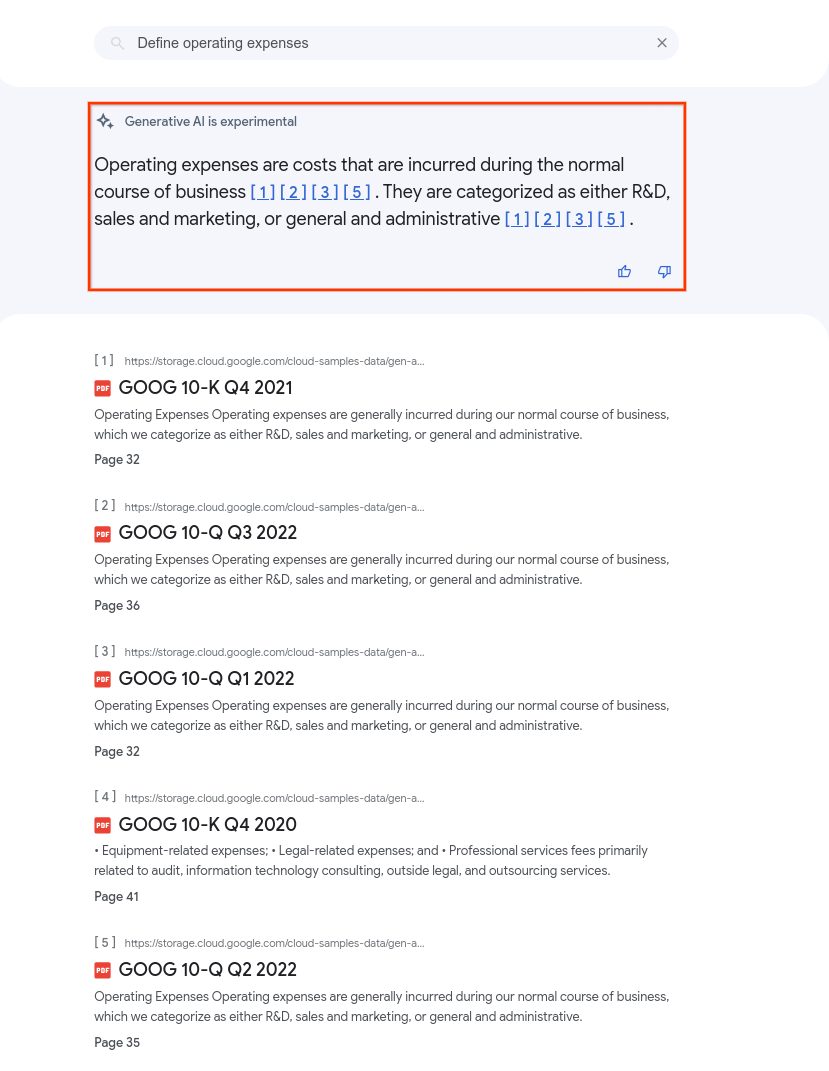
搜尋摘要可包含 Markdown 格式的文字,以及 Markdown 剖析器普遍能解讀的簡單 HTML 標記。因此,建議您在應用程式中使用 Markdown 剖析器,以便算繪 Markdown 文字。
如要取得搜尋摘要,請按照下列步驟操作:
提交搜尋要求,其中包含
contentSearchSpec.summarySpec,並指定summaryResultCount和maxExtractiveAnswerCount的值。如要進一步瞭解如何提交搜尋要求,請參閱「取得搜尋結果」。在下列範例中,
summarySpec表示您想要搜尋摘要,且摘要應從前三項搜尋結果生成。"contentSearchSpec": { "summarySpec": { "summaryResultCount": 3 }, "extractiveContentSpec": { "maxExtractiveAnswerCount" : 1} }summaryResultCount:用來生成搜尋摘要的頂端結果數量。如果傳回的結果數少於summaryResultCount,系統會根據所有結果生成摘要。maxExtractiveAnswerCount:每個搜尋結果要傳回的擷取答案數量。預設值為 0,最大值為 1。
從搜尋回應中取得摘要。每個回應都會傳回一個
summary屬性。以下是搜尋回覆結尾傳回的摘要範例:
"summary": { "summaryText": "BigQuery is Google Cloud's fully managed and completely serverless enterprise data warehouse. BigQuery supports all data types, works across clouds, and has built-in machine learning and business intelligence, all within a unified platform." }
從語意區塊生成摘要
開啟 use_semantic_chunks 即可根據最相關的文件區塊生成摘要。與使用擷取式答案的預設行為相比,使用語意區塊生成摘要可提高回憶率和檢索率。
如果開啟摘要的語意分塊功能,回應會傳回摘要,以及摘要使用的每個分塊內容。
如要使用語意區塊生成摘要,請按照下列步驟操作:
提交包含
contentSearchSpec.summarySpec的搜尋要求,並指定"use_semantic_chunks": true。如要進一步瞭解如何提交搜尋要求,請參閱「取得搜尋結果」。以下
summarySpec範例表示您希望搜尋摘要使用語意區塊、要納入多少結果,以及是否要加入引文。"contentSearchSpec": { "summarySpec": { "useSemanticChunks": SEMANTIC_CHUNK_BOOLEAN, "summaryResultCount": SUMMARY_RESULT_COUNT, "includeCitations": CITATIONS_BOOLEAN, } }SEMANTIC_CHUNK_BOOLEAN:布林值,用於指定是否使用語意區塊生成搜尋摘要。如果設為true,系統會使用語意區塊。SUMMARY_RESULT_COUNT:用來生成搜尋摘要的頂端結果數量。最大值為10。CITATIONS_BOOLEAN:布林值,用於指定是否傳回引文。如果您在建立資料儲存庫時開啟了區塊模式,引文就會參照區塊。否則,引文會參照來源文件。如要進一步瞭解區塊模式,請參閱「剖析及區塊化文件」。
從搜尋回應中取得摘要。
以下是搜尋回應的範例,其中包含從區塊生成的摘要和引文。回應的
references部分包含摘要的生成來源區塊內容。回應
{ "results": [ { "id": "123xyz", "document": { "name": "projects/exampleproject/locations/global/collections/default_collection/dataStores/exampledatastore/branches/0/documents/123xyz", "id": "123xyz", "derivedStructData": { "link": "gs://examplebucket/alphabet-investor-pdfs/2004_google_annual_report.pdf" } } } ], "totalSize": 8375, "attributionToken": "abcdefg", "nextPageToken": "hijklmnop", "guidedSearchResult": {}, "summary": { "summaryText": "Google's search technology uses a combination of techniques to determine the importance of a web page independent of a particular search query and to determine the relevance of that page to a particular search query. [1]", "summaryWithMetadata": { "summary": "Google's search technology uses a combination of techniques to determine the importance of a web page independent of a particular search query and to determine the relevance of that page to a particular search query.", "citationMetadata": { "citations": [ { "endIndex": "216", "sources": [ {} ] } ] }, "references": [ { "document": "projects/exampleproject/locations/global/collections/default_collection/dataStores/exampledatastore/branches/0/documents/123xyz", "chunkContents": [ { "content": "Groups contains more than 1 billion messages from Usenet Internet discussion groups dating back to 1981.The\ndiscussions in these groups cover a broad range of discourse and provide a comprehensive look at evolving\nviewpoints, debate and advice on many subjects.The new Google Groups adds in the ability to create your own\ngroups for you and your friends and an improved user interface.Google Mobile.Google Mobile offers people the ability to search and view both the "mobile web,"\nconsisting of pages created specifically for wireless devices, and the entire Google index of more than 8 billion\nweb pages.Google Mobile works on devices that support WAP, WAP 2.0, i-mode or j-sky mobile Internet\nprotocols.In addition, users can access a variety of information using Google SMS by typing a query to the\nGoogle shortcode.Google Mobile is available through many wireless and mobile phone services worldwide.", "pageIdentifier": "17" }, { "content": "Google Labs is our playground for our engineers and for adventurous Google users.On Google\nLabs, we post product prototypes and solicit feedback on how the technology could be used or improved.Current Google Labs examples include:Google Personalized Search—provides customized search results based on an individual user's interests.Froogle Wireless—gives people the ability to search for product information from their mobile phones\nand other wireless devices.Google Maps—enables users to see maps, get directions, and find local businesses and services quickly\nand easily.Google Maps has several unique features, including draggable maps, integrated local search\nfrom Google Local, and keyboard shortcuts.Google Scholar—enables users to search specifically for scholarly literature, including peer-reviewed\npapers, theses, books, preprints, abstracts and technical reports from all broad areas of research.Google\nScholar can be used to find articles from a wide variety of academic publishers, professional societies,\npreprint repositories and universities, as well as scholarly articles available across the web.Google Suggest—guesses what you're typing and offers suggestions in real time.This is similar to\nGoogle's "Did you mean?"feature that offers alternative spellings for your query after you search, except\nthat it works in real time.", "pageIdentifier": "17" }, { "content": "Groups contains more than 1 billion messages from Usenet Internet discussion groups dating back to 1981.The\ndiscussions in these groups cover a broad range of discourse and provide a comprehensive look at evolving\nviewpoints, debate and advice on many subjects.The new Google Groups adds in the ability to create your own\ngroups for you and your friends and an improved user interface.Google Mobile.Google Mobile offers people the ability to search and view both the "mobile web,"\nconsisting of pages created specifically for wireless devices, and the entire Google index of more than 8 billion\nweb pages.Google Mobile works on devices that support WAP, WAP 2.0, i-mode or j-sky mobile Internet\nprotocols.In addition, users can access a variety of information using Google SMS by typing a query to the\nGoogle shortcode.Google Mobile is available through many wireless and mobile phone services worldwide.\n\nGoogle Local.Google Local enables users to find relevant local businesses near a city, postal code, or specific\naddress.This service combines Yellow Page listings with information found on web pages, and plots their\nlocations on interactive maps.Google Print.Google Print brings information online that had previously not been available to web\nsearchers.Under this program, we enable a number of publishers to host their content and show their\npublications at the top of our search results.", "pageIdentifier": "17" }, { "content": "Votes cast by important web pages with high PageRank weigh more heavily and are\nmore influential in deciding the PageRank of pages on the web.Text-Matching Techniques.Our technology employs text-matching techniques that compare search queries\nwith the content of web pages to help determine relevance.Our text-based scoring techniques do far more than\ncount the number of times a search term appears on a web page.For example, our technology determines the\nproximity of individual search terms to each other on a given web page, and prioritizes results that have the\nsearch terms near each other.Many other aspects of a page's content are factored into the equation, as is the\ncontent of pages that link to the page in question.By combining query independent measures such as PageRank\nwith our text-matching techniques, we are able to deliver search results that are relevant to what people are\ntrying to find.\n\nAdvertising Technology\nOur advertising program serves millions of relevant, targeted ads each day based on search terms people\n\nenter or content they view on the web.The key elements of our advertising technology include:\n\nGoogle AdWords Auction System.We use the Google AdWords auction system to enable advertisers to\nautomatically deliver relevant, targeted advertising.", "pageIdentifier": "21" }, { "content": "Votes cast by important web pages with high PageRank weigh more heavily and are\nmore influential in deciding the PageRank of pages on the web.Text-Matching Techniques.Our technology employs text-matching techniques that compare search queries\nwith the content of web pages to help determine relevance.Our text-based scoring techniques do far more than\ncount the number of times a search term appears on a web page.For example, our technology determines the\nproximity of individual search terms to each other on a given web page, and prioritizes results that have the\nsearch terms near each other.Many other aspects of a page's content are factored into the equation, as is the\ncontent of pages that link to the page in question.By combining query independent measures such as PageRank\nwith our text-matching techniques, we are able to deliver search results that are relevant to what people are\ntrying to find.\n\nAdvertising Technology\nOur advertising program serves millions of relevant, targeted ads each day based on search terms people\n\nenter or content they view on the web.The key elements of our advertising technology include:", "pageIdentifier": "21" }, { "content": "Google Maps—enables users to see maps, get directions, and find local businesses and services quickly\nand easily.Google Maps has several unique features, including draggable maps, integrated local search\nfrom Google Local, and keyboard shortcuts.Google Scholar—enables users to search specifically for scholarly literature, including peer-reviewed\npapers, theses, books, preprints, abstracts and technical reports from all broad areas of research.Google\nScholar can be used to find articles from a wide variety of academic publishers, professional societies,\npreprint repositories and universities, as well as scholarly articles available across the web.Google Suggest—guesses what you're typing and offers suggestions in real time.This is similar to\nGoogle's "Did you mean?"feature that offers alternative spellings for your query after you search, except\nthat it works in real time.Google Video—includes thousands of programs that play on our TVs every day.Google Video enables\nyou to search a growing archive of televised content—everything from sports to dinosaur\ndocumentaries to news shows.\n\n6", "pageIdentifier": "17" }, { "content": "Every search query we process involves the automated\nexecution of an auction, resulting in our advertising system often processing hundreds of millions of auctions per\nday.To determine whether an ad is relevant to a particular query, this system weighs an advertiser's willingness\nto pay for prominence in the ad listings (the CPC) and interest from users in the ad as measured by the click\nthrough rate and other factors.If an ad does not attract user clicks, it moves to a less prominent position on the\npage, even if the advertiser offers to pay a high amount.This prevents advertisers with irrelevant ads from\n"squatting" in top positions to gain exposure.Conversely, more relevant, well-targeted ads that are clicked on\nfrequently move up in ranking, with no need for advertisers to increase their bids.Because we are paid only\nwhen users click on ads, the AdWords ranking system aligns our interests equally with those of our advertisers\nand our users.The more relevant and useful the ad, the better for our users, for our advertisers and for us.\n\nThe AdWords auction system also incorporates our AdWords discounter, which automatically lowers the\namount advertisers actually pay to the minimum needed to maintain their ad position.", "pageIdentifier": "21" }, { "content": "Web Search Technology\nOur web search technology uses a combination of techniques to determine the importance of a web page\nindependent of a particular search query and to determine the relevance of that page to a particular search\nquery.We do not explain how we do ranking in great detail because some people try to manipulate our search\nresults for their own gain, rather than in an attempt to provide high-quality information to users.\n\nRanking Technology.One element of our technology for ranking web pages is called PageRank.While we\ndeveloped much of our ranking technology after Google was formed, PageRank was developed at Stanford\nUniversity with the involvement of our founders, and was therefore published as research.Most of our current\nranking technology is protected as trade-secret.PageRank is a query-independent technique for determining the\nimportance of web pages by looking at the link structure of the web.PageRank treats a link from web page A to\nweb page B as a "vote" by page A in favor of page B.The PageRank of a page is the sum of the PageRank of the\npages that link to it.The PageRank of a web page also depends on the importance (or PageRank) of the other\nweb pages casting the votes.", "pageIdentifier": "21" }, { "content": "The Company recognizes as revenue the fees charged advertisers each time a user clicks on one of the text\nbased ads that are displayed next to the search results on Google web sites.Effective January 1, 2004, the\nCompany offered a single pricing structure to all of its advertisers based on the AdWords cost per click model.\n\nGoogle AdSense is the program through which the Company distributes its advertisers' text-based ads for\ndisplay on the web sites of the Google Network members.In accordance with Emerging Issues Task Force\n("EITF") Issue No. 99 19, Reporting Revenue Gross as a Principal Versus Net as an Agent, the Company recognizes\nas revenues the fees it receives from its advertisers.This revenue is reported gross primarily because the\nCompany is the primary obligor to its advertisers.\n\nThe Company generates fees from search services through a variety of contractual arrangements, which\ninclude per-query search fees and search service hosting fees.Revenues from set up and support fees and search\nservice hosting fees are recognized on a straight-line basis over the term of the contract, which is the expected\nperiod during which these services will be provided.The Company's policy is to recognize revenues from per\nquery search fees in the period queries are made and results are delivered.\n\nThe Company provides search services pursuant to certain AdSense agreements.", "pageIdentifier": "85" }, { "content": "On Google Print pages, we provide links to book sellers that may\noffer the full versions of these publications for sale, and we show content-targeted ads that are served through\nthe Google AdSense program.Google Desktop Search.Google Desktop Search enables our users to perform a full text search on the\ncontents of their own computer, including email, files, instant messenger chats and web browser history.Users\ncan use this service to view web pages they have visited even when they are not online.Google Alerts.Google Alerts are email updates of the latest relevant Google results (web, news, etc.) based\non the user's choice of query or topic.Typical uses include monitoring a developing news story, keeping current\non a competitor or industry, getting the latest on a celebrity or event, or keeping tabs on a favorite sports team.Google Labs.Google Labs is our playground for our engineers and for adventurous Google users.On Google\nLabs, we post product prototypes and solicit feedback on how the technology could be used or improved.Current Google Labs examples include:Google Personalized Search—provides customized search results based on an individual user's interests.Froogle Wireless—gives people the ability to search for product information from their mobile phones\nand other wireless devices.", "pageIdentifier": "17" } ] } ] } } }
取得引用內容
如果指定引用內容,則為搜尋摘要中內嵌的數字。這些數字代表摘要中的特定句子是從哪個搜尋結果擷取而來。
如要取得引用次數,請按照下列步驟操作:
提交包含
contentSearchSpec.summarySpec的搜尋要求,並指定"includeCitations": true。如要進一步瞭解如何提交搜尋要求,請參閱「取得搜尋結果」。在下列範例中,
summarySpec表示您需要搜尋摘要,且摘要應根據前三項搜尋結果生成,並附上引文。"contentSearchSpec": { "summarySpec": { "summaryResultCount": 3, "includeCitations": true }, "extractiveContentSpec": { "maxExtractiveAnswerCount" : 1} }summaryResultCount:用來生成搜尋摘要的頂端結果數量。如果傳回的結果數少於summaryResultCount,系統會根據所有結果生成摘要。最大值為5。includeCitations:布林值,指定是否傳回引文。maxExtractiveAnswerCount:每個搜尋結果要傳回的擷取答案數量。預設值為 0,最大值為 1。
從搜尋回應中取得附有引文的摘要。每個回應都會傳回一項
summary屬性。以下是摘要範例,其中包含引文和引文的後設資料, 會顯示在搜尋回覆的結尾:
"summary": { "summaryText": "BigQuery is Google Cloud's fully managed and completely serverless enterprise data warehouse [1]. BigQuery supports all data types, works across clouds, and has built-in machine learning and business intelligence, all within a unified platform [2, 3].", "summaryWithMetadata": { "summary": "BigQuery is Google Cloud's fully managed and completely serverless enterprise data warehouse. BigQuery supports all data types, works across clouds, and has built-in machine learning and business intelligence, all within a unified platform.", "citationMetadata": { "citations": [ { "startIndex": "0", "endIndex": "101", "sources": [ { "uri": "gs://example-dataset/html/6344007140738632642.html", "title": "About BigQuery", "id": "b6344007140738632642", "referenceIndex": "0" }, { "uri": "gs://example-dataset/html/1365490014946172719.html", "title": "Google Cloud article", "id": "b1365490014946172719", "referenceIndex": "1" }, { "uri": "gs://example-dataset/html/2687910668117268120.html", "title": "BigQuery document", "id": "a2687910668117268120", "referenceIndex": "2" } ] }, { "startIndex": "103", "endIndex": "230", "sources": [ { "referenceIndex": "0" }, { "referenceIndex": "1" }, { "referenceIndex": "2", } ] } ] }, "references": [ { "title": "Sports in the United States", "docName": "projects/123/locations/global/collections/default_collection/dataStores/ds-123/branches/0/documents/b6344007140738632642", "uri": "https://example.com/bigqueryA" }, { "title": "Sports in the United States", "docName": "projects/123/locations/global/collections/default_collection/dataStores/ds-123/branches/0/documents/b1365490014946172719", "uri": "https://example.com/bigqueryB" }, { "title": "Sports in the United States", "docName": "projects/123/locations/global/collections/default_collection/dataStores/ds-123/branches/0/documents/a268791066811726812", "uri": "https://example.com/bigqueryC" } ] } }summaryText:搜尋摘要,附上引用資料編號。引文編號是指傳回的搜尋結果,並以 1 為索引。舉例來說,[1]代表該句子歸因於第一個搜尋結果。[2, 3]表示該句子歸因於第二和第三個搜尋結果。citations:針對摘要中含有引文的每個句子,列出該引文的中繼資料。startIndex:表示句子的開頭,以 Unicode 位元組為單位。endIndex:表示句尾,以 Unicode 位元組為單位。sources:列出句子引用內容中包含的每個來源。referenceIndexreferenceIndex是指派給來源的索引編號。回應中不一定會明確傳回第一個來源的referenceIndex。由於referenceIndex是以 0 為索引,因此第一個來源的referenceIndex一律為 0。references:列出摘要中引用的每個參考資料的中繼資料。中繼資料包括title、docName和uri。
忽略對抗查詢
這類查詢包括負面留言,或旨在生成不安全/違反政策的輸出內容。您可以指定不針對對抗性查詢傳回任何搜尋摘要。如果系統忽略惡意查詢,summaryText 屬性會包含公式化文字,指出系統未傳回任何搜尋摘要。即使搜尋摘要未傳回,搜尋文件仍會針對對抗性查詢傳回。
如要指定不應針對對抗性查詢傳回搜尋摘要,請按照下列步驟操作:
提交包含
contentSearchSpec.summarySpec的搜尋要求,並指定"ignoreAdversarialQuery": true。如要進一步瞭解如何提交搜尋要求,請參閱「取得搜尋結果」。在下列範例中,
summarySpec表示您需要搜尋摘要,摘要應根據前三項搜尋結果產生,但對抗性查詢不應傳回摘要。"contentSearchSpec": { "summarySpec": { "summaryResultCount": 3, "ignoreAdversarialQuery": true }, "extractiveContentSpec": { "maxExtractiveAnswerCount" : 1} }summaryResultCount:用來生成搜尋摘要的頂端結果數量。如果傳回的結果數少於summaryResultCount,系統會根據所有結果生成摘要。最大值為5。ignoreAdversarialQuery:布林值,指定不應針對對抗性查詢傳回搜尋摘要。maxExtractiveAnswerCount:每個搜尋結果要傳回的擷取答案數量。預設值為 0,最大值為 1。
請參閱針對對抗性搜尋要求傳回的
summary屬性。範例如下:
"summary": { "summaryText": "We do not have a summary for your query. Here are some search results.", "summarySkippedReasons": [ "ADVERSARIAL_QUERY_IGNORED" ] }summaryText:樣板文字,表示系統未傳回任何搜尋摘要。summarySkippedReasons:列舉,包含摘要略過原因的值。
忽略非摘要查詢
如果查詢並非尋找摘要,系統會傳回不適合用於摘要的結果。舉例來說,「為什麼天空是藍的」和「誰是世界上最厲害的足球員?」是尋求摘要的查詢,但「舊金山國際機場」和「2026 年世界盃」則不是。這類查詢最有可能屬於導覽查詢。您可以指定不為非摘要搜尋查詢傳回搜尋摘要。即使搜尋摘要未傳回,系統仍會針對非摘要查詢傳回搜尋文件。
如要指定系統不應針對非摘要查詢傳回搜尋摘要,請按照下列步驟操作:
提交包含
contentSearchSpec.summarySpec的搜尋要求,並指定"ignoreNonSummarySeekingQuery": true。如要進一步瞭解如何提交搜尋要求,請參閱「取得搜尋結果」。在下列範例中,
summarySpec表示您需要搜尋摘要,摘要應根據前三項搜尋結果產生,但對於非摘要搜尋查詢,則不應傳回摘要。"contentSearchSpec": { "summarySpec": { "summaryResultCount": 3, "ignoreNonSummarySeekingQuery": true }, "extractiveContentSpec": { "maxExtractiveAnswerCount" : 1} }summaryResultCount:用來生成搜尋摘要的頂端結果數量。如果傳回的結果數少於summaryResultCount,系統會根據所有結果生成摘要。最大值為5。ignoreNonSummarySeekingQuery:布林值,指定不應為非摘要搜尋查詢傳回搜尋摘要。maxExtractiveAnswerCount:每個搜尋結果要傳回的擷取答案數量。預設值為 0,最大值為 1。
查看為非摘要搜尋要求傳回的
summary屬性。範例如下:
"summary": { "summaryText": "We do not have a summary for your query. Here are some search results.", "summarySkippedReasons": [ "NON_SUMMARY_SEEKING_QUERY_IGNORED" ] }summaryText:樣板文字,表示系統未傳回任何搜尋摘要。summarySkippedReasons:列舉,包含摘要略過原因的值。
取得自訂摘要
您可以提供自然語言指令,取得自訂摘要。
如要使用這項功能,請透過控制台操作搜尋小工具,或在 modelPromptSpec.preamble 欄位中輸入指令,透過 API 操作。
你可以要求自訂長度、詳細程度、輸出內容的風格 (例如「簡單」)、輸出內容的語言、答案的重點和格式 (例如表格、項目符號和 XML)。
舉例來說,如果查詢是 What are the benefits of bigquery?,您可以輸入自訂指令,例如:
範例指令:
please show the answer format in an ordered list回答範例:
The benefits of BigQuery are: 1. Increased business productivity 2. IT staff productivity 3. Reduced infrastructure costs 4. Loading and exporting data are free範例指令:
give a very detailed answer回答範例:
BigQuery is a serverless, highly scalable, and cost-effective cloud data warehouse that enables businesses to analyze all their data very quickly. It is a fully managed service that takes care of provisioning, scaling, and managing the underlying infrastructure, so you can focus on analyzing your data. BigQuery is also integrated with other Google Cloud services, such as Google Kubernetes Engine, Cloud Data Fusion, and Cloud Dataproc, making it easy to build and deploy data pipelines. Here are some of the benefits of using BigQuery: * **Fast and scalable:** BigQuery can process petabytes of data very quickly, and it can scale to handle even the most demanding workloads. * **Cost-effective:** BigQuery is a very cost-effective way to store and analyze data. You only pay for the data that you use, and there are no upfront costs or commitments. * **Secure:** BigQuery is a secure platform that meets the needs of even the most security-conscious organizations. * **Easy to use:** BigQuery is easy to use, even for non-technical users. It has a simple and intuitive user interface, and it supports a variety of data sources. * **Integrated with other Google Cloud services:** BigQuery is integrated with other Google Cloud services, making it easy to build and deploy data pipelines. If you are looking for a fast, scalable, and cost-effective way to analyze your data, then BigQuery is a great option.
自訂摘要的最佳做法
如要使用這項功能,請按照下列步驟操作:
- 一次只能要求一項自訂項目。請勿合併自訂項目,例如要求以法文顯示 HTML 表格。
- Google 建議您限制使用者可要求的自訂項目,例如提供一組預先定義的自訂項目供使用者選擇。
自訂摘要
如要取得搜尋小工具的自訂摘要,請使用控制台;如要取得任何搜尋要求的自訂摘要,請使用 API。
如要取得自訂摘要,請按照下列步驟操作:
主控台
前往 Google Cloud 控制台的「AI Applications」頁面。
按一下要編輯的應用程式名稱。
依序前往「Configurations」>「UI」。
確認搜尋小工具的「搜尋類型」已設為「搜尋並取得答案」或「搜尋並追問」。如果選取「搜尋」,則無法使用這項功能。
開啟「啟用摘要自訂功能」。
如要輸入摘要說明,請執行下列任一操作:
- 輸入任意格式的指令:在「前言」欄位中輸入自己的自然語言指令。
- 使用範本指令:按一下「替換為範本」,然後選取其中一個預先定義的範本指令。選取預先定義的範本後,該範本會顯示在「前言」欄位中。
在「預覽」窗格中搜尋,測試應用程式的自訂摘要生成功能。
如要重設為上次儲存的指令集,請按一下「重設前言」。
如要將設定儲存至小工具,請按一下「儲存並發布」。
REST
提交搜尋要求,其中包含
contentSearchSpec.summarySpec,並在modelPromptSpec.preamble中指定自訂指令。如要進一步瞭解如何提交搜尋要求,請參閱「取得搜尋結果」。在下列範例中,
summarySpec表示您想要搜尋摘要,摘要應根據前三項搜尋結果生成,且摘要應經過自訂,就像是向 10 歲兒童說明一樣。"contentSearchSpec": { "summarySpec": { "summaryResultCount": 3, "modelPromptSpec": { "preamble": "explain like you would to a ten year old" } } }summaryResultCount:用來生成搜尋摘要的頂端結果數量。如果傳回的結果數少於summaryResultCount,系統會根據所有結果生成摘要。最大值為5。preamble:自訂的指令。
從搜尋回應取得自訂摘要。
以下是傳回的自訂摘要範例:
"summary": { "summaryText": "BigQuery is a serverless data warehouse that helps you analyze all your data very quickly. It's very easy to use and you don't need to worry about managing servers or infrastructure. BigQuery is also very scalable, so you can analyze large datasets without any problems." }summaryText:自訂搜尋摘要。
指定摘要模型
您可以指定要用來生成摘要的模型。
您可以指定 stable、preview 或特定模型版本 (依名稱)。
如要瞭解可用的模型版本,請參閱「答案生成模型版本和生命週期」。
如要變更模型版本,請按照下列步驟操作:
提交搜尋要求,並加入
ContentSearchSpec.SummarySpec.ModelSpec來指定模型版本。"contentSearchSpec": { "summarySpec": { "modelSpec": { "version": "MODEL_VERSION" } } }MODEL_VERSION:指定用於生成摘要的模型。支援的值如下:
stable:字串。未指定值時的預設規格。stable指向經過微調的正式版模型,可生成答案。隨著新的正式版模型發布,以及舊版模型停止使用,stable指向的模型也會隨之變更。如要瞭解stable指向的最新版本,請參閱答案生成模型版本和生命週期。preview:字串。preview指向最新的 Gemini 模型,用於問答。如要進一步瞭解 Gemini,請參閱「模型總覽」。- 如要指定特定模型版本,請輸入版本名稱,例如
gemini-1.5-flash-002/answer_gen/v1。如要瞭解支援的版本,請參閱「答案生成模型版本和生命週期」。
舉例來說,下列搜尋要求會將 preview 指定為模型版本:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
"https://discoveryengine.googleapis.com/v1/projects/exampleproject/locations/global/collections/default_collection/dataStores/exampledatastore/servingConfigs/default_search:search" \
-d '{
"query": "what is bigquery",
"contentSearchSpec": {
"summarySpec": {
"modelSpec": {
"version": "preview"
}
}
}
}'
搜尋摘要的限制
使用搜尋摘要時,可能會遇到下列限制:
由於 LLM 用於生成搜尋摘要和引用出處,因此 LLM 的限制也適用於 Vertex AI Search 摘要。
如要瞭解這些大型語言模型的限制,請參閱 Vertex AI 說明文件中的 PaLM API 限制。
如果搜尋查詢需要複雜的邏輯或分析推理,或是對世界有深入瞭解,搜尋摘要可能會包含不正確的資訊 (幻覺),或是非結構化或網站資料中沒有的資訊。
搜尋摘要中的部分陳述內容可能沒有引文:
如果系統判定陳述內容不需要根據事實,就不會附上引文。「以下是我找到的資訊」或「你可以按照許多方法操作」等句子缺少引文。
如果沒有引文,也可能表示系統找不到有效的參考資料。 沒有引文的事實可能不可靠。
在極少數情況下,引文可能會錯誤歸給陳述內容。
大型語言模型可能會誤解複雜的文件。在這種情況下,摘要可能不完整或不正確。
由於自訂指示是以自然語言提供,因此無法保證所有要求都會遵守指示。