Halaman ini menunjukkan cara menggunakan API untuk mendapatkan ringkasan penelusuran dengan hasil penelusuran Anda. Bagian ini juga menjelaskan opsi yang tersedia dengan ringkasan penelusuran. Hanya untuk data tidak terstruktur dan situs.
Untuk mengetahui informasi tentang cara mendapatkan jawaban AI generatif untuk kueri data layanan kesehatan Anda, lihat Menelusuri menggunakan kueri bahasa alami dengan jawaban AI generatif.
Sebelum memulai
Bergantung pada jenis aplikasi yang Anda miliki, selesaikan persyaratan berikut:
Untuk aplikasi penelusuran tidak terstruktur: Aktifkan Fitur LLM lanjutan.
Untuk aplikasi penelusuran situs: Aktifkan fitur berikut:
Pengindeksan situs lanjutan. Memerlukan verifikasi domain.
Mendapatkan ringkasan penelusuran
Ringkasan penelusuran adalah ringkasan singkat dari satu atau beberapa hasil penelusuran teratas yang ditampilkan dalam respons penelusuran. Ringkasan itu sendiri diambil dari jawaban ekstraktif yang ditampilkan dalam respons. Oleh karena itu, untuk mendapatkan ringkasan, Anda juga harus mendapatkan jawaban ekstraktif dengan hasil penelusuran Anda. Untuk mengetahui informasi selengkapnya, lihat Mendapatkan jawaban ekstraktif (Pratinjau).
Gambar berikut menunjukkan ringkasan saat PDF di penyimpanan data dikueri dengan
summaryResultCount disetel ke 5. Konten ringkasan dapat bervariasi bergantung pada
konfigurasi aplikasi.
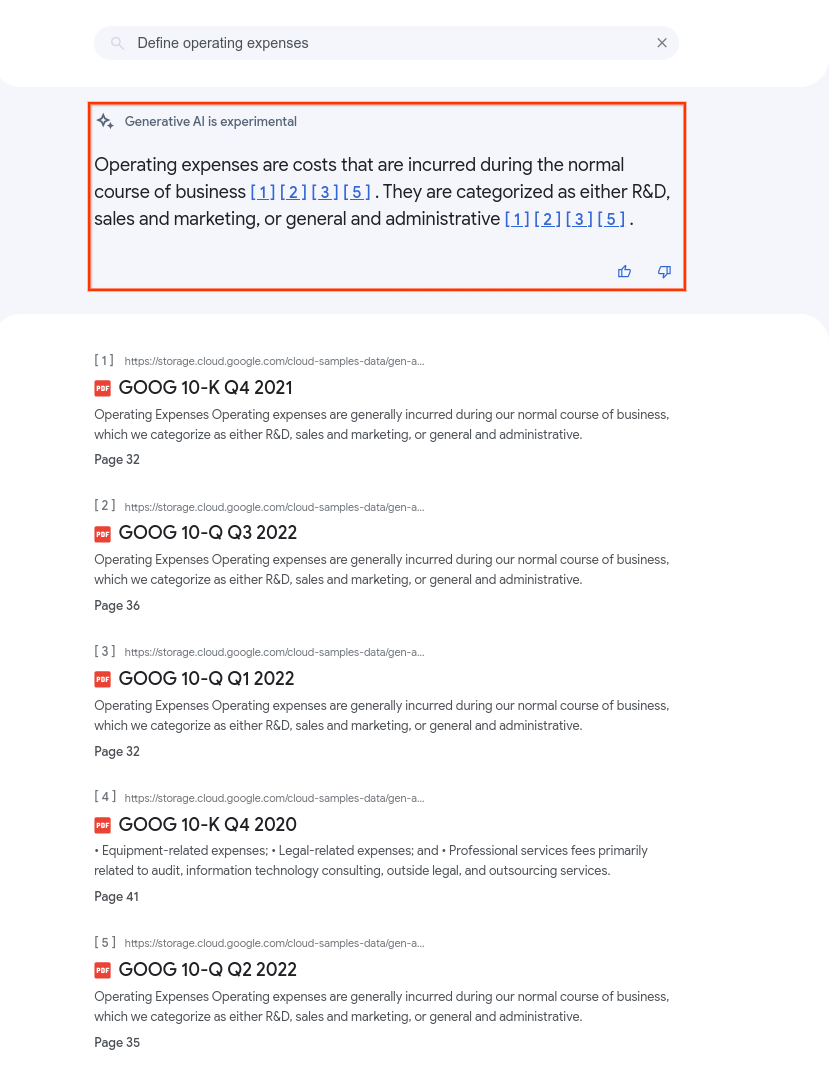
Ringkasan penelusuran dapat menyertakan teks berformat Markdown dan tag HTML sederhana yang umumnya dipahami oleh parser Markdown. Oleh karena itu, pertimbangkan untuk menggunakan parser Markdown di aplikasi Anda untuk merender teks Markdown.
Untuk mendapatkan ringkasan penelusuran, ikuti langkah-langkah berikut:
Kirimkan permintaan penelusuran yang menyertakan
contentSearchSpec.summarySpecdan menentukan nilai untuksummaryResultCountdanmaxExtractiveAnswerCount. Untuk mengetahui informasi selengkapnya tentang cara mengirimkan permintaan penelusuran, lihat Mendapatkan hasil penelusuran.Dalam contoh berikut,
summarySpecmenunjukkan bahwa Anda menginginkan ringkasan penelusuran dan ringkasan tersebut harus dibuat dari tiga hasil penelusuran teratas."contentSearchSpec": { "summarySpec": { "summaryResultCount": 3 }, "extractiveContentSpec": { "maxExtractiveAnswerCount" : 1} }summaryResultCount: Jumlah hasil teratas untuk membuat ringkasan penelusuran. Jika jumlah hasil yang ditampilkan kurang darisummaryResultCount, ringkasan dibuat dari semua hasil.maxExtractiveAnswerCount: Jumlah jawaban ekstraktif yang akan ditampilkan untuk setiap hasil penelusuran. Nilai defaultnya adalah 0 dan nilai maksimumnya adalah 1.
Dapatkan ringkasan dari respons penelusuran. Satu properti
summaryditampilkan dalam setiap respons.Berikut adalah contoh ringkasan yang ditampilkan di akhir respons penelusuran:
"summary": { "summaryText": "BigQuery is Google Cloud's fully managed and completely serverless enterprise data warehouse. BigQuery supports all data types, works across clouds, and has built-in machine learning and business intelligence, all within a unified platform." }
Membuat ringkasan dari potongan semantik
Anda dapat mengaktifkan use_semantic_chunks untuk membuat ringkasan dari bagian dokumen yang paling relevan. Penggunaan potongan semantik untuk pembuatan ringkasan meningkatkan
ingatan dan pengambilan dibandingkan dengan perilaku default penggunaan jawaban ekstraktif.
Jika chunking semantik diaktifkan untuk ringkasan, respons akan menampilkan ringkasan dan konten setiap chunk yang digunakan ringkasan.
Untuk menggunakan potongan semantik dalam pembuatan ringkasan, ikuti langkah-langkah berikut:
Kirim permintaan penelusuran yang menyertakan
contentSearchSpec.summarySpecdan menentukan"use_semantic_chunks": true. Untuk mengetahui informasi selengkapnya tentang cara mengirimkan permintaan penelusuran, lihat Mendapatkan hasil penelusuran.Contoh
summarySpecberikut menunjukkan bahwa Anda menginginkan ringkasan penelusuran yang menggunakan potongan semantik, jumlah hasil yang akan disertakan, dan apakah akan menyertakan kutipan."contentSearchSpec": { "summarySpec": { "useSemanticChunks": SEMANTIC_CHUNK_BOOLEAN, "summaryResultCount": SUMMARY_RESULT_COUNT, "includeCitations": CITATIONS_BOOLEAN, } }SEMANTIC_CHUNK_BOOLEAN: Boolean yang menentukan apakah akan menggunakan potongan semantik untuk membuat ringkasan penelusuran. Jika disetel ketrue, potongan semantik akan digunakan.SUMMARY_RESULT_COUNT: Jumlah hasil teratas untuk membuat ringkasan penelusuran. Nilai maksimumnya adalah10.CITATIONS_BOOLEAN: Boolean yang menentukan apakah kutipan ditampilkan. Jika Anda mengaktifkan mode potongan saat membuat penyimpanan data, kutipan akan merujuk ke potongan. Jika tidak, kutipan merujuk pada dokumen sumber. Untuk mengetahui informasi selengkapnya tentang mode potongan, lihat Mengurai dan membagi dokumen.
Dapatkan ringkasan dari respons penelusuran.
Berikut adalah contoh respons penelusuran yang menyertakan ringkasan yang dibuat dari potongan dan menyertakan kutipan. Bagian
referencesdari respons berisi konten potongan yang digunakan untuk membuat ringkasan.Respons
{ "results": [ { "id": "123xyz", "document": { "name": "projects/exampleproject/locations/global/collections/default_collection/dataStores/exampledatastore/branches/0/documents/123xyz", "id": "123xyz", "derivedStructData": { "link": "gs://examplebucket/alphabet-investor-pdfs/2004_google_annual_report.pdf" } } } ], "totalSize": 8375, "attributionToken": "abcdefg", "nextPageToken": "hijklmnop", "guidedSearchResult": {}, "summary": { "summaryText": "Google's search technology uses a combination of techniques to determine the importance of a web page independent of a particular search query and to determine the relevance of that page to a particular search query. [1]", "summaryWithMetadata": { "summary": "Google's search technology uses a combination of techniques to determine the importance of a web page independent of a particular search query and to determine the relevance of that page to a particular search query.", "citationMetadata": { "citations": [ { "endIndex": "216", "sources": [ {} ] } ] }, "references": [ { "document": "projects/exampleproject/locations/global/collections/default_collection/dataStores/exampledatastore/branches/0/documents/123xyz", "chunkContents": [ { "content": "Groups contains more than 1 billion messages from Usenet Internet discussion groups dating back to 1981.The\ndiscussions in these groups cover a broad range of discourse and provide a comprehensive look at evolving\nviewpoints, debate and advice on many subjects.The new Google Groups adds in the ability to create your own\ngroups for you and your friends and an improved user interface.Google Mobile.Google Mobile offers people the ability to search and view both the "mobile web,"\nconsisting of pages created specifically for wireless devices, and the entire Google index of more than 8 billion\nweb pages.Google Mobile works on devices that support WAP, WAP 2.0, i-mode or j-sky mobile Internet\nprotocols.In addition, users can access a variety of information using Google SMS by typing a query to the\nGoogle shortcode.Google Mobile is available through many wireless and mobile phone services worldwide.", "pageIdentifier": "17" }, { "content": "Google Labs is our playground for our engineers and for adventurous Google users.On Google\nLabs, we post product prototypes and solicit feedback on how the technology could be used or improved.Current Google Labs examples include:Google Personalized Search—provides customized search results based on an individual user's interests.Froogle Wireless—gives people the ability to search for product information from their mobile phones\nand other wireless devices.Google Maps—enables users to see maps, get directions, and find local businesses and services quickly\nand easily.Google Maps has several unique features, including draggable maps, integrated local search\nfrom Google Local, and keyboard shortcuts.Google Scholar—enables users to search specifically for scholarly literature, including peer-reviewed\npapers, theses, books, preprints, abstracts and technical reports from all broad areas of research.Google\nScholar can be used to find articles from a wide variety of academic publishers, professional societies,\npreprint repositories and universities, as well as scholarly articles available across the web.Google Suggest—guesses what you're typing and offers suggestions in real time.This is similar to\nGoogle's "Did you mean?"feature that offers alternative spellings for your query after you search, except\nthat it works in real time.", "pageIdentifier": "17" }, { "content": "Groups contains more than 1 billion messages from Usenet Internet discussion groups dating back to 1981.The\ndiscussions in these groups cover a broad range of discourse and provide a comprehensive look at evolving\nviewpoints, debate and advice on many subjects.The new Google Groups adds in the ability to create your own\ngroups for you and your friends and an improved user interface.Google Mobile.Google Mobile offers people the ability to search and view both the "mobile web,"\nconsisting of pages created specifically for wireless devices, and the entire Google index of more than 8 billion\nweb pages.Google Mobile works on devices that support WAP, WAP 2.0, i-mode or j-sky mobile Internet\nprotocols.In addition, users can access a variety of information using Google SMS by typing a query to the\nGoogle shortcode.Google Mobile is available through many wireless and mobile phone services worldwide.\n\nGoogle Local.Google Local enables users to find relevant local businesses near a city, postal code, or specific\naddress.This service combines Yellow Page listings with information found on web pages, and plots their\nlocations on interactive maps.Google Print.Google Print brings information online that had previously not been available to web\nsearchers.Under this program, we enable a number of publishers to host their content and show their\npublications at the top of our search results.", "pageIdentifier": "17" }, { "content": "Votes cast by important web pages with high PageRank weigh more heavily and are\nmore influential in deciding the PageRank of pages on the web.Text-Matching Techniques.Our technology employs text-matching techniques that compare search queries\nwith the content of web pages to help determine relevance.Our text-based scoring techniques do far more than\ncount the number of times a search term appears on a web page.For example, our technology determines the\nproximity of individual search terms to each other on a given web page, and prioritizes results that have the\nsearch terms near each other.Many other aspects of a page's content are factored into the equation, as is the\ncontent of pages that link to the page in question.By combining query independent measures such as PageRank\nwith our text-matching techniques, we are able to deliver search results that are relevant to what people are\ntrying to find.\n\nAdvertising Technology\nOur advertising program serves millions of relevant, targeted ads each day based on search terms people\n\nenter or content they view on the web.The key elements of our advertising technology include:\n\nGoogle AdWords Auction System.We use the Google AdWords auction system to enable advertisers to\nautomatically deliver relevant, targeted advertising.", "pageIdentifier": "21" }, { "content": "Votes cast by important web pages with high PageRank weigh more heavily and are\nmore influential in deciding the PageRank of pages on the web.Text-Matching Techniques.Our technology employs text-matching techniques that compare search queries\nwith the content of web pages to help determine relevance.Our text-based scoring techniques do far more than\ncount the number of times a search term appears on a web page.For example, our technology determines the\nproximity of individual search terms to each other on a given web page, and prioritizes results that have the\nsearch terms near each other.Many other aspects of a page's content are factored into the equation, as is the\ncontent of pages that link to the page in question.By combining query independent measures such as PageRank\nwith our text-matching techniques, we are able to deliver search results that are relevant to what people are\ntrying to find.\n\nAdvertising Technology\nOur advertising program serves millions of relevant, targeted ads each day based on search terms people\n\nenter or content they view on the web.The key elements of our advertising technology include:", "pageIdentifier": "21" }, { "content": "Google Maps—enables users to see maps, get directions, and find local businesses and services quickly\nand easily.Google Maps has several unique features, including draggable maps, integrated local search\nfrom Google Local, and keyboard shortcuts.Google Scholar—enables users to search specifically for scholarly literature, including peer-reviewed\npapers, theses, books, preprints, abstracts and technical reports from all broad areas of research.Google\nScholar can be used to find articles from a wide variety of academic publishers, professional societies,\npreprint repositories and universities, as well as scholarly articles available across the web.Google Suggest—guesses what you're typing and offers suggestions in real time.This is similar to\nGoogle's "Did you mean?"feature that offers alternative spellings for your query after you search, except\nthat it works in real time.Google Video—includes thousands of programs that play on our TVs every day.Google Video enables\nyou to search a growing archive of televised content—everything from sports to dinosaur\ndocumentaries to news shows.\n\n6", "pageIdentifier": "17" }, { "content": "Every search query we process involves the automated\nexecution of an auction, resulting in our advertising system often processing hundreds of millions of auctions per\nday.To determine whether an ad is relevant to a particular query, this system weighs an advertiser's willingness\nto pay for prominence in the ad listings (the CPC) and interest from users in the ad as measured by the click\nthrough rate and other factors.If an ad does not attract user clicks, it moves to a less prominent position on the\npage, even if the advertiser offers to pay a high amount.This prevents advertisers with irrelevant ads from\n"squatting" in top positions to gain exposure.Conversely, more relevant, well-targeted ads that are clicked on\nfrequently move up in ranking, with no need for advertisers to increase their bids.Because we are paid only\nwhen users click on ads, the AdWords ranking system aligns our interests equally with those of our advertisers\nand our users.The more relevant and useful the ad, the better for our users, for our advertisers and for us.\n\nThe AdWords auction system also incorporates our AdWords discounter, which automatically lowers the\namount advertisers actually pay to the minimum needed to maintain their ad position.", "pageIdentifier": "21" }, { "content": "Web Search Technology\nOur web search technology uses a combination of techniques to determine the importance of a web page\nindependent of a particular search query and to determine the relevance of that page to a particular search\nquery.We do not explain how we do ranking in great detail because some people try to manipulate our search\nresults for their own gain, rather than in an attempt to provide high-quality information to users.\n\nRanking Technology.One element of our technology for ranking web pages is called PageRank.While we\ndeveloped much of our ranking technology after Google was formed, PageRank was developed at Stanford\nUniversity with the involvement of our founders, and was therefore published as research.Most of our current\nranking technology is protected as trade-secret.PageRank is a query-independent technique for determining the\nimportance of web pages by looking at the link structure of the web.PageRank treats a link from web page A to\nweb page B as a "vote" by page A in favor of page B.The PageRank of a page is the sum of the PageRank of the\npages that link to it.The PageRank of a web page also depends on the importance (or PageRank) of the other\nweb pages casting the votes.", "pageIdentifier": "21" }, { "content": "The Company recognizes as revenue the fees charged advertisers each time a user clicks on one of the text\nbased ads that are displayed next to the search results on Google web sites.Effective January 1, 2004, the\nCompany offered a single pricing structure to all of its advertisers based on the AdWords cost per click model.\n\nGoogle AdSense is the program through which the Company distributes its advertisers' text-based ads for\ndisplay on the web sites of the Google Network members.In accordance with Emerging Issues Task Force\n("EITF") Issue No. 99 19, Reporting Revenue Gross as a Principal Versus Net as an Agent, the Company recognizes\nas revenues the fees it receives from its advertisers.This revenue is reported gross primarily because the\nCompany is the primary obligor to its advertisers.\n\nThe Company generates fees from search services through a variety of contractual arrangements, which\ninclude per-query search fees and search service hosting fees.Revenues from set up and support fees and search\nservice hosting fees are recognized on a straight-line basis over the term of the contract, which is the expected\nperiod during which these services will be provided.The Company's policy is to recognize revenues from per\nquery search fees in the period queries are made and results are delivered.\n\nThe Company provides search services pursuant to certain AdSense agreements.", "pageIdentifier": "85" }, { "content": "On Google Print pages, we provide links to book sellers that may\noffer the full versions of these publications for sale, and we show content-targeted ads that are served through\nthe Google AdSense program.Google Desktop Search.Google Desktop Search enables our users to perform a full text search on the\ncontents of their own computer, including email, files, instant messenger chats and web browser history.Users\ncan use this service to view web pages they have visited even when they are not online.Google Alerts.Google Alerts are email updates of the latest relevant Google results (web, news, etc.) based\non the user's choice of query or topic.Typical uses include monitoring a developing news story, keeping current\non a competitor or industry, getting the latest on a celebrity or event, or keeping tabs on a favorite sports team.Google Labs.Google Labs is our playground for our engineers and for adventurous Google users.On Google\nLabs, we post product prototypes and solicit feedback on how the technology could be used or improved.Current Google Labs examples include:Google Personalized Search—provides customized search results based on an individual user's interests.Froogle Wireless—gives people the ability to search for product information from their mobile phones\nand other wireless devices.", "pageIdentifier": "17" } ] } ] } } }
Mendapatkan kutipan
Kutipan, jika ditentukan, adalah angka yang ditempatkan sebaris dalam ringkasan penelusuran. Angka-angka ini menunjukkan dari hasil penelusuran mana kalimat tertentu dalam ringkasan diambil.
Untuk mendapatkan kutipan, ikuti langkah-langkah berikut:
Kirim permintaan penelusuran yang menyertakan
contentSearchSpec.summarySpecdan menentukan"includeCitations": true. Untuk mengetahui informasi selengkapnya tentang mengirimkan permintaan penelusuran, lihat Mendapatkan hasil penelusuran.Dalam contoh berikut,
summarySpecmenunjukkan bahwa Anda menginginkan ringkasan penelusuran, bahwa ringkasan harus dibuat dari tiga hasil penelusuran teratas, dan bahwa kutipan harus disertakan dalam ringkasan."contentSearchSpec": { "summarySpec": { "summaryResultCount": 3, "includeCitations": true }, "extractiveContentSpec": { "maxExtractiveAnswerCount" : 1} }summaryResultCount: Jumlah hasil teratas untuk membuat ringkasan penelusuran. Jika jumlah hasil yang ditampilkan kurang darisummaryResultCount, ringkasan dibuat dari semua hasil. Nilai maksimumnya adalah5.includeCitations: Boolean yang menentukan apakah kutipan ditampilkan.maxExtractiveAnswerCount: Jumlah jawaban ekstraktif yang akan ditampilkan untuk setiap hasil penelusuran. Nilai defaultnya adalah 0 dan nilai maksimumnya adalah 1.
Dapatkan ringkasan, dengan kutipan, dari respons penelusuran. Satu properti
summaryditampilkan di setiap respons.Berikut adalah contoh ringkasan, dengan kutipan dan metadata kutipan, yang ditampilkan di akhir respons penelusuran:
"summary": { "summaryText": "BigQuery is Google Cloud's fully managed and completely serverless enterprise data warehouse [1]. BigQuery supports all data types, works across clouds, and has built-in machine learning and business intelligence, all within a unified platform [2, 3].", "summaryWithMetadata": { "summary": "BigQuery is Google Cloud's fully managed and completely serverless enterprise data warehouse. BigQuery supports all data types, works across clouds, and has built-in machine learning and business intelligence, all within a unified platform.", "citationMetadata": { "citations": [ { "startIndex": "0", "endIndex": "101", "sources": [ { "uri": "gs://example-dataset/html/6344007140738632642.html", "title": "About BigQuery", "id": "b6344007140738632642", "referenceIndex": "0" }, { "uri": "gs://example-dataset/html/1365490014946172719.html", "title": "Google Cloud article", "id": "b1365490014946172719", "referenceIndex": "1" }, { "uri": "gs://example-dataset/html/2687910668117268120.html", "title": "BigQuery document", "id": "a2687910668117268120", "referenceIndex": "2" } ] }, { "startIndex": "103", "endIndex": "230", "sources": [ { "referenceIndex": "0" }, { "referenceIndex": "1" }, { "referenceIndex": "2", } ] } ] }, "references": [ { "title": "Sports in the United States", "docName": "projects/123/locations/global/collections/default_collection/dataStores/ds-123/branches/0/documents/b6344007140738632642", "uri": "https://example.com/bigqueryA" }, { "title": "Sports in the United States", "docName": "projects/123/locations/global/collections/default_collection/dataStores/ds-123/branches/0/documents/b1365490014946172719", "uri": "https://example.com/bigqueryB" }, { "title": "Sports in the United States", "docName": "projects/123/locations/global/collections/default_collection/dataStores/ds-123/branches/0/documents/a268791066811726812", "uri": "https://example.com/bigqueryC" } ] } }summaryText: Ringkasan penelusuran, dengan nomor kutipan. Nomor kutipan mengacu pada hasil penelusuran yang ditampilkan dan diindeks 1. Misalnya,[1]berarti kalimat tersebut diatribusikan ke hasil penelusuran pertama.[2, 3]berarti kalimat tersebut diatribusikan ke hasil penelusuran kedua dan ketiga.citations: Untuk setiap kalimat dalam ringkasan yang memiliki kutipan, mencantumkan metadata untuk kutipan tersebut.startIndex: Menunjukkan awal kalimat, diukur dalam byte unicode.endIndex: Menunjukkan akhir kalimat, diukur dalam byte unicode.sources: MencantumkanreferenceIndexuntuk setiap sumber yang disertakan dalam kutipan kalimat.referenceIndexadalah nomor indeks yang ditetapkan ke sumber.referenceIndexsumber pertama tidak selalu ditampilkan secara eksplisit dalam respons. KarenareferenceIndexdiindeks 0, sumber pertama selalu memilikireferenceIndex0.references: Mencantumkan metadata untuk setiap referensi yang dikutip dalam ringkasan. Metadata mencakuptitle,docName, danuri.
Mengabaikan kueri yang bertentangan
Kueri yang bersifat melawan mencakup komentar negatif atau dirancang untuk menghasilkan output yang tidak aman dan melanggar kebijakan. Anda dapat menentukan bahwa tidak ada ringkasan penelusuran yang akan ditampilkan untuk kueri yang bersifat merugikan. Jika kueri yang merugikan diabaikan, properti summaryText berisi teks boilerplate yang menunjukkan bahwa tidak ada ringkasan penelusuran yang ditampilkan. Dokumen penelusuran ditampilkan untuk kueri yang bertentangan meskipun ringkasan penelusuran tidak ditampilkan.
Untuk menentukan bahwa tidak ada ringkasan penelusuran yang harus ditampilkan untuk kueri yang bertentangan, ikuti langkah-langkah berikut:
Kirim permintaan penelusuran yang menyertakan
contentSearchSpec.summarySpecdan menentukan"ignoreAdversarialQuery": true. Untuk mengetahui informasi selengkapnya tentang mengirimkan permintaan penelusuran, lihat Mendapatkan hasil penelusuran.Dalam contoh berikut,
summarySpecmenunjukkan bahwa Anda menginginkan ringkasan penelusuran, bahwa ringkasan harus dibuat dari tiga hasil penelusuran teratas, tetapi tidak ada ringkasan yang harus ditampilkan untuk kueri yang bertentangan."contentSearchSpec": { "summarySpec": { "summaryResultCount": 3, "ignoreAdversarialQuery": true }, "extractiveContentSpec": { "maxExtractiveAnswerCount" : 1} }summaryResultCount: Jumlah hasil teratas untuk membuat ringkasan penelusuran. Jika jumlah hasil yang ditampilkan kurang darisummaryResultCount, ringkasan dibuat dari semua hasil. Nilai maksimumnya adalah5.ignoreAdversarialQuery: Boolean yang menentukan bahwa tidak ada ringkasan penelusuran yang boleh ditampilkan untuk kueri yang bersifat merugikan.maxExtractiveAnswerCount: Jumlah jawaban ekstraktif yang akan ditampilkan untuk setiap hasil penelusuran. Nilai defaultnya adalah 0 dan nilai maksimumnya adalah 1.
Lihat properti
summaryyang ditampilkan untuk permintaan penelusuran yang bertentangan.Berikut ini contohnya:
"summary": { "summaryText": "We do not have a summary for your query. Here are some search results.", "summarySkippedReasons": [ "ADVERSARIAL_QUERY_IGNORED" ] }summaryText: Teks standar yang menunjukkan bahwa tidak ada ringkasan penelusuran yang ditampilkan.summarySkippedReasons: Enumerasi dengan nilai untuk alasan ringkasan dilewati.
Mengabaikan kueri yang tidak mencari ringkasan
Kueri yang tidak mencari ringkasan akan menampilkan hasil yang tidak sesuai untuk diringkas. Misalnya, "mengapa langit berwarna biru" dan "Siapa pemain sepak bola terbaik di dunia?" adalah kueri yang mencari ringkasan, tetapi "bandara SFO" dan "piala dunia 2026" bukan. Kueri tersebut kemungkinan besar adalah kueri navigasi. Anda dapat menentukan bahwa tidak ada ringkasan penelusuran yang harus ditampilkan untuk kueri yang tidak mencari ringkasan. Dokumen penelusuran ditampilkan untuk kueri yang tidak mencari ringkasan meskipun ringkasan penelusuran tidak ditampilkan.
Untuk menentukan bahwa tidak ada ringkasan penelusuran yang harus ditampilkan untuk kueri yang tidak mencari ringkasan, ikuti langkah-langkah berikut:
Kirim permintaan penelusuran yang menyertakan
contentSearchSpec.summarySpecdan menentukan"ignoreNonSummarySeekingQuery": true. Untuk mengetahui informasi selengkapnya tentang cara mengirimkan permintaan penelusuran, lihat Mendapatkan hasil penelusuran.Dalam contoh berikut,
summarySpecmenunjukkan bahwa Anda menginginkan ringkasan penelusuran, ringkasan harus dibuat dari tiga hasil penelusuran teratas, tetapi tidak ada ringkasan yang harus ditampilkan untuk kueri yang tidak mencari ringkasan."contentSearchSpec": { "summarySpec": { "summaryResultCount": 3, "ignoreNonSummarySeekingQuery": true }, "extractiveContentSpec": { "maxExtractiveAnswerCount" : 1} }summaryResultCount: Jumlah hasil teratas untuk membuat ringkasan penelusuran. Jika jumlah hasil yang ditampilkan kurang darisummaryResultCount, ringkasan dibuat dari semua hasil. Nilai maksimumnya adalah5.ignoreNonSummarySeekingQuery: Boolean yang menentukan bahwa tidak ada ringkasan penelusuran yang akan ditampilkan untuk kueri yang tidak mencari ringkasan.maxExtractiveAnswerCount: Jumlah jawaban ekstraktif yang akan ditampilkan untuk setiap hasil penelusuran. Nilai defaultnya adalah 0 dan nilai maksimumnya adalah 1.
Lihat properti
summaryyang ditampilkan untuk permintaan penelusuran yang tidak mencari ringkasan.Berikut ini contohnya:
"summary": { "summaryText": "We do not have a summary for your query. Here are some search results.", "summarySkippedReasons": [ "NON_SUMMARY_SEEKING_QUERY_IGNORED" ] }summaryText: Teks standar yang menunjukkan bahwa tidak ada ringkasan penelusuran yang ditampilkan.summarySkippedReasons: Enumerasi dengan nilai untuk alasan ringkasan dilewati.
Mendapatkan ringkasan yang disesuaikan
Anda bisa mendapatkan ringkasan yang disesuaikan dengan memberikan petunjuk bahasa natural.
Fitur ini tersedia untuk widget penelusuran dengan menggunakan konsol, dan untuk
API dengan memasukkan petunjuk di kolom modelPromptSpec.preamble.
Anda dapat meminta penyesuaian seperti panjang, tingkat detail, gaya output (seperti "sederhana"), bahasa output, fokus jawaban, dan format (seperti tabel, poin-poin, dan XML).
Misalnya, untuk kueri What are the benefits of bigquery?, Anda dapat memasukkan petunjuk penyesuaian seperti dalam contoh berikut:
Contoh petunjuk:
please show the answer format in an ordered listContoh jawaban:
The benefits of BigQuery are: 1. Increased business productivity 2. IT staff productivity 3. Reduced infrastructure costs 4. Loading and exporting data are freeContoh petunjuk:
give a very detailed answerContoh jawaban:
BigQuery is a serverless, highly scalable, and cost-effective cloud data warehouse that enables businesses to analyze all their data very quickly. It is a fully managed service that takes care of provisioning, scaling, and managing the underlying infrastructure, so you can focus on analyzing your data. BigQuery is also integrated with other Google Cloud services, such as Google Kubernetes Engine, Cloud Data Fusion, and Cloud Dataproc, making it easy to build and deploy data pipelines. Here are some of the benefits of using BigQuery: * **Fast and scalable:** BigQuery can process petabytes of data very quickly, and it can scale to handle even the most demanding workloads. * **Cost-effective:** BigQuery is a very cost-effective way to store and analyze data. You only pay for the data that you use, and there are no upfront costs or commitments. * **Secure:** BigQuery is a secure platform that meets the needs of even the most security-conscious organizations. * **Easy to use:** BigQuery is easy to use, even for non-technical users. It has a simple and intuitive user interface, and it supports a variety of data sources. * **Integrated with other Google Cloud services:** BigQuery is integrated with other Google Cloud services, making it easy to build and deploy data pipelines. If you are looking for a fast, scalable, and cost-effective way to analyze your data, then BigQuery is a great option.
Praktik terbaik untuk ringkasan yang disesuaikan
Jika Anda berencana menggunakan fitur ini, lakukan hal berikut:
- Minta hanya satu penyesuaian dalam satu waktu. Jangan menggabungkan penyesuaian—misalnya, meminta tabel HTML dalam bahasa Prancis.
- Google merekomendasikan agar Anda membatasi penyesuaian yang dapat diminta oleh pengguna akhir Anda—misalnya, dengan menawarkan pemilih dengan serangkaian penyesuaian yang telah ditentukan sebelumnya.
Menyesuaikan ringkasan
Anda bisa mendapatkan ringkasan yang disesuaikan hanya untuk widget penelusuran menggunakan konsol atau, untuk permintaan penelusuran apa pun, menggunakan API.
Untuk mendapatkan ringkasan yang disesuaikan, ikuti langkah-langkah berikut:
Konsol
Di konsol Google Cloud , buka halaman AI Applications.
Klik nama aplikasi yang ingin Anda edit.
Buka Configurations > UI.
Pastikan Jenis penelusuran widget penelusuran Anda disetel ke Penelusuran dengan jawaban atau Penelusuran dengan tindak lanjut. Fitur ini tidak tersedia jika Penelusuran dipilih.
Aktifkan Aktifkan penyesuaian ringkasan.
Untuk memasukkan petunjuk ringkasan, lakukan salah satu hal berikut:
- Masukkan petunjuk bentuk bebas: Masukkan petunjuk bahasa alami Anda sendiri di kolom Preamble.
- Petunjuk penggunaan template: Klik Ganti dengan template dan pilih salah satu petunjuk template yang telah ditentukan sebelumnya. Template standar akan muncul di kolom Preamble setelah Anda memilihnya.
Uji pembuatan ringkasan yang disesuaikan untuk aplikasi Anda dengan menelusuri di panel Pratinjau.
Untuk mereset ke set instruksi yang terakhir disimpan, klik Reset preamble.
Untuk menyimpan setelan ke widget, klik Simpan dan publikasikan.
REST
Kirimkan permintaan penelusuran yang menyertakan
contentSearchSpec.summarySpecdan tentukan petunjuk penyesuaian dimodelPromptSpec.preamble. Untuk mengetahui informasi selengkapnya tentang cara mengirimkan permintaan penelusuran, lihat Mendapatkan hasil penelusuran.Dalam contoh berikut,
summarySpecmenunjukkan bahwa Anda menginginkan ringkasan penelusuran, ringkasan harus dibuat dari tiga hasil penelusuran teratas, dan ringkasan harus disesuaikan seolah-olah sedang dijelaskan kepada anak berusia 10 tahun."contentSearchSpec": { "summarySpec": { "summaryResultCount": 3, "modelPromptSpec": { "preamble": "explain like you would to a ten year old" } } }summaryResultCount: Jumlah hasil teratas untuk membuat ringkasan penelusuran. Jika jumlah hasil yang ditampilkan kurang darisummaryResultCount, ringkasan dibuat dari semua hasil. Nilai maksimumnya adalah5.preamble: Petunjuk untuk penyesuaian.
Dapatkan ringkasan yang disesuaikan dari respons penelusuran.
Berikut adalah contoh ringkasan yang disesuaikan yang ditampilkan:
"summary": { "summaryText": "BigQuery is a serverless data warehouse that helps you analyze all your data very quickly. It's very easy to use and you don't need to worry about managing servers or infrastructure. BigQuery is also very scalable, so you can analyze large datasets without any problems." }summaryText: Ringkasan penelusuran yang disesuaikan.
Menentukan model ringkasan
Anda dapat menentukan model yang ingin digunakan untuk membuat ringkasan.
Anda dapat menentukan stable, preview, atau versi model tertentu menurut nama.
Untuk mengetahui versi model yang tersedia, lihat Versi dan siklus proses model
pembuatan jawaban.
Untuk mengubah versi model:
Kirimkan permintaan penelusuran yang menyertakan
ContentSearchSpec.SummarySpec.ModelSpecuntuk menentukan versi model."contentSearchSpec": { "summarySpec": { "modelSpec": { "version": "MODEL_VERSION" } } }MODEL_VERSION: Menentukan model yang akan digunakan untuk membuat ringkasan. Nilai yang didukung adalah:
stable: string. Spesifikasi default jika tidak ada nilai yang ditentukan.stablemengarah ke versi model GA yang telah di-fine-tune untuk pembuatan jawaban. Model yang ditunjuk olehstableakan berubah saat versi model GA baru dirilis dan versi model sebelumnya dihentikan. Untuk mengetahui versi terbaru yang ditunjuk olehstable, lihat Versi dan siklus proses model pembuatan jawaban.preview: string.previewmengarah ke model Gemini terbaru untuk tanya jawab. Untuk mengetahui informasi selengkapnya tentang Gemini, lihat Ringkasan model.- Untuk menentukan versi model tertentu, masukkan nama versi, seperti
gemini-1.5-flash-002/answer_gen/v1. Untuk mengetahui versi yang didukung, lihat Versi dan siklus proses model pembuatan jawaban.
Misalnya, permintaan penelusuran berikut menentukan preview sebagai versi
model:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
"https://discoveryengine.googleapis.com/v1/projects/exampleproject/locations/global/collections/default_collection/dataStores/exampledatastore/servingConfigs/default_search:search" \
-d '{
"query": "what is bigquery",
"contentSearchSpec": {
"summarySpec": {
"modelSpec": {
"version": "preview"
}
}
}
}'
Batasan ringkasan penelusuran
Anda mungkin mengalami batasan berikut saat menggunakan ringkasan penelusuran:
Karena LLM digunakan untuk membuat ringkasan dan kutipan penelusuran, batasan LLM juga berlaku untuk ringkasan Vertex AI Search.
Untuk mengetahui informasi umum tentang batasan LLM ini, lihat Batasan PaLM API dalam dokumentasi Vertex AI.
Kueri penelusuran yang memerlukan penalaran atau analisis logis yang kompleks atau pemahaman tentang dunia dapat menghasilkan ringkasan penelusuran yang berisi informasi yang salah (halusinasi) atau informasi yang tidak ada dalam data tidak terstruktur atau data situs.
Beberapa pernyataan dalam ringkasan penelusuran mungkin tidak berisi kutipan:
Jika sistem menentukan bahwa pernyataan tidak memerlukan perujukan, pernyataan tersebut tidak akan menyertakan kutipan. Kalimat seperti "Berikut yang saya temukan" atau "Ada banyak metode yang dapat Anda ikuti" tidak memiliki kutipan.
Kutipan yang tidak ada juga dapat menunjukkan bahwa referensi yang valid tidak ditemukan. Fakta tanpa kutipan mungkin tidak dapat diandalkan.
Dalam kasus yang jarang terjadi, kutipan mungkin salah diatribusikan ke pernyataan.
Dokumen yang kompleks mungkin salah diurai oleh LLM. Dalam hal ini, ringkasan mungkin tidak lengkap atau salah.
Karena petunjuk penyesuaian menggunakan bahasa alami, kepatuhan terhadap petunjuk tidak dapat dijamin untuk semua permintaan.