En esta página se muestra cómo usar la API para obtener resúmenes de búsqueda con tus resultados de búsqueda. También se explican las opciones disponibles con los resúmenes de búsqueda. Solo para datos no estructurados y de sitios web.
Para obtener información sobre cómo obtener respuestas de IA generativa a tus consultas de datos sanitarios, consulta el artículo Buscar con consultas en lenguaje natural y respuestas de IA generativa.
Antes de empezar
En función del tipo de aplicación que tengas, cumple los siguientes requisitos:
En el caso de una aplicación de búsqueda no estructurada, activa las funciones avanzadas de LLM.
En el caso de una aplicación de búsqueda de sitios web, activa las siguientes funciones:
Indexación avanzada de sitios web Requiere verificación del dominio.
Obtener un resumen de la búsqueda
Un resumen de búsqueda es una breve recapitulación de los principales resultados de búsqueda devueltos en una respuesta de búsqueda. El resumen se extrae de las respuestas extractivas devueltas en la respuesta. Por lo tanto, para obtener un resumen, también debes obtener respuestas extractivas con los resultados de búsqueda. Para obtener más información, consulta Obtener respuestas extractivas (vista previa).
En la siguiente imagen se muestra el resumen cuando se consultan PDFs de un almacén de datos con summaryResultCount definido como 5. El contenido del resumen puede variar en función de las configuraciones de la aplicación.
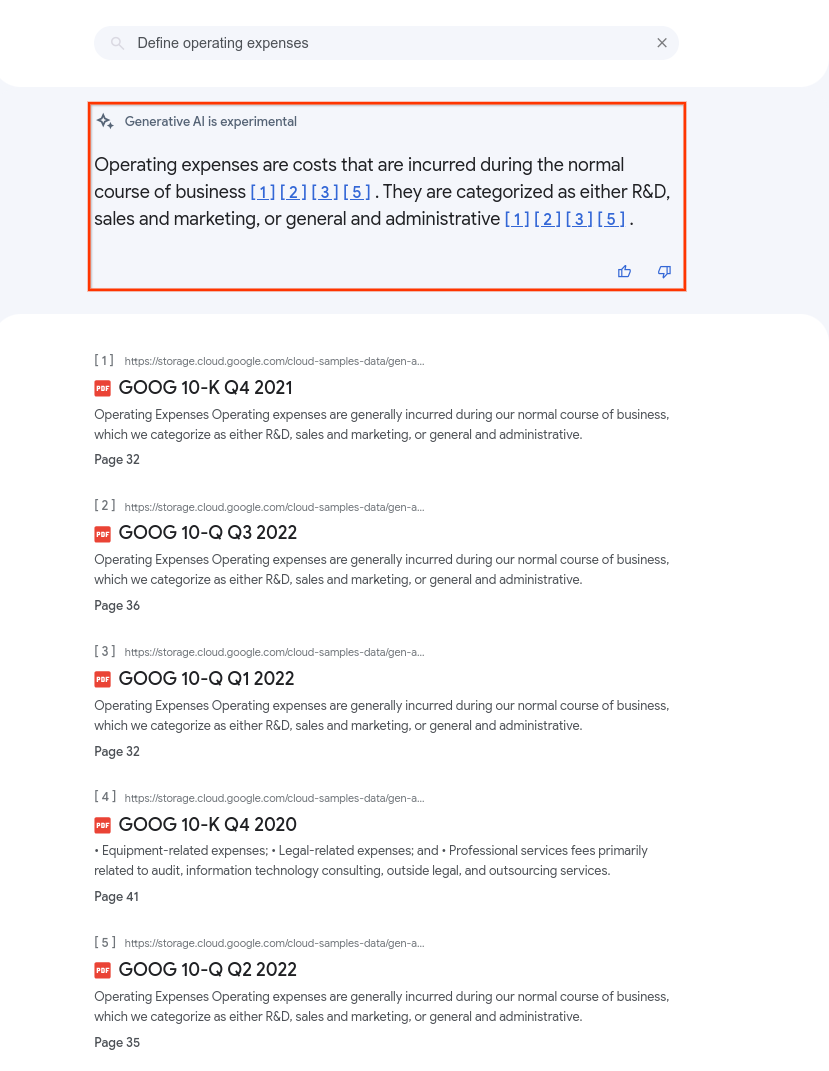
Los resúmenes de búsqueda pueden incluir texto con formato Markdown y etiquetas HTML sencillas que suelen entender los analizadores de Markdown. Por este motivo, te recomendamos que utilices un analizador de Markdown en tu aplicación para renderizar texto de Markdown.
.Para obtener un resumen de la búsqueda, sigue estos pasos:
Envía una solicitud de búsqueda que incluya
contentSearchSpec.summarySpecy especifica valores parasummaryResultCountymaxExtractiveAnswerCount. Para obtener más información sobre cómo enviar una solicitud de búsqueda, consulta el artículo Obtener resultados de búsqueda.En el siguiente ejemplo,
summarySpecindica que quieres un resumen de la búsqueda y que este se genere a partir de los tres primeros resultados de búsqueda."contentSearchSpec": { "summarySpec": { "summaryResultCount": 3 }, "extractiveContentSpec": { "maxExtractiveAnswerCount" : 1} }summaryResultCount: número de resultados principales a partir de los que se generará el resumen de búsqueda. Si el número de resultados devueltos es inferior asummaryResultCount, el resumen se genera a partir de todos los resultados.maxExtractiveAnswerCount: número de respuestas extractivas que se devuelven por cada resultado de búsqueda. El valor predeterminado es 0 y el máximo es 1.
Obtén el resumen de la respuesta de búsqueda. En cada respuesta se devuelve una propiedad
summary.A continuación se muestra un ejemplo de resumen devuelto al final de una respuesta de búsqueda:
"summary": { "summaryText": "BigQuery is Google Cloud's fully managed and completely serverless enterprise data warehouse. BigQuery supports all data types, works across clouds, and has built-in machine learning and business intelligence, all within a unified platform." }
Generar resúmenes a partir de fragmentos semánticos
Puedes activar use_semantic_chunks para generar resúmenes a partir de los fragmentos de documento más relevantes. Si se usan fragmentos semánticos para generar resúmenes, se mejora la
recuperación y la evocación en comparación con el comportamiento predeterminado de usar respuestas extractivas.
Cuando la segmentación semántica está activada en los resúmenes, la respuesta devuelve el resumen y el contenido de cada fragmento que se ha usado en el resumen.
Para usar los fragmentos semánticos en la generación de resúmenes, sigue estos pasos:
Envía una solicitud de búsqueda que incluya
contentSearchSpec.summarySpecy especifique"use_semantic_chunks": true. Para obtener más información sobre cómo enviar una solicitud de búsqueda, consulta el artículo Obtener resultados de búsqueda.En el siguiente ejemplo de
summarySpecse indica que quieres un resumen de búsqueda que use fragmentos semánticos, cuántos resultados quieres incluir y si quieres incluir citas."contentSearchSpec": { "summarySpec": { "useSemanticChunks": SEMANTIC_CHUNK_BOOLEAN, "summaryResultCount": SUMMARY_RESULT_COUNT, "includeCitations": CITATIONS_BOOLEAN, } }SEMANTIC_CHUNK_BOOLEAN: valor booleano que especifica si se deben usar fragmentos semánticos para generar el resumen de búsqueda. Si se le asigna el valortrue, se utilizan fragmentos semánticos.SUMMARY_RESULT_COUNT: número de resultados principales a partir de los que se generará el resumen de búsqueda. El valor máximo es10.CITATIONS_BOOLEAN: valor booleano que especifica si se devuelven las citas. Si activaste el modo de fragmentación al crear tu almacén de datos, las citas harán referencia a fragmentos. De lo contrario, las citas hacen referencia a documentos de origen. Para obtener más información sobre el modo de fragmentación, consulta Analizar y fragmentar documentos.
Obtén el resumen de la respuesta de búsqueda.
A continuación, se muestra un ejemplo de una respuesta de búsqueda que incluye un resumen generado a partir de fragmentos y que contiene citas. La parte
referencesde la respuesta contiene el contenido de los fragmentos a partir de los que se genera el resumen.Respuesta
{ "results": [ { "id": "123xyz", "document": { "name": "projects/exampleproject/locations/global/collections/default_collection/dataStores/exampledatastore/branches/0/documents/123xyz", "id": "123xyz", "derivedStructData": { "link": "gs://examplebucket/alphabet-investor-pdfs/2004_google_annual_report.pdf" } } } ], "totalSize": 8375, "attributionToken": "abcdefg", "nextPageToken": "hijklmnop", "guidedSearchResult": {}, "summary": { "summaryText": "Google's search technology uses a combination of techniques to determine the importance of a web page independent of a particular search query and to determine the relevance of that page to a particular search query. [1]", "summaryWithMetadata": { "summary": "Google's search technology uses a combination of techniques to determine the importance of a web page independent of a particular search query and to determine the relevance of that page to a particular search query.", "citationMetadata": { "citations": [ { "endIndex": "216", "sources": [ {} ] } ] }, "references": [ { "document": "projects/exampleproject/locations/global/collections/default_collection/dataStores/exampledatastore/branches/0/documents/123xyz", "chunkContents": [ { "content": "Groups contains more than 1 billion messages from Usenet Internet discussion groups dating back to 1981.The\ndiscussions in these groups cover a broad range of discourse and provide a comprehensive look at evolving\nviewpoints, debate and advice on many subjects.The new Google Groups adds in the ability to create your own\ngroups for you and your friends and an improved user interface.Google Mobile.Google Mobile offers people the ability to search and view both the "mobile web,"\nconsisting of pages created specifically for wireless devices, and the entire Google index of more than 8 billion\nweb pages.Google Mobile works on devices that support WAP, WAP 2.0, i-mode or j-sky mobile Internet\nprotocols.In addition, users can access a variety of information using Google SMS by typing a query to the\nGoogle shortcode.Google Mobile is available through many wireless and mobile phone services worldwide.", "pageIdentifier": "17" }, { "content": "Google Labs is our playground for our engineers and for adventurous Google users.On Google\nLabs, we post product prototypes and solicit feedback on how the technology could be used or improved.Current Google Labs examples include:Google Personalized Search—provides customized search results based on an individual user's interests.Froogle Wireless—gives people the ability to search for product information from their mobile phones\nand other wireless devices.Google Maps—enables users to see maps, get directions, and find local businesses and services quickly\nand easily.Google Maps has several unique features, including draggable maps, integrated local search\nfrom Google Local, and keyboard shortcuts.Google Scholar—enables users to search specifically for scholarly literature, including peer-reviewed\npapers, theses, books, preprints, abstracts and technical reports from all broad areas of research.Google\nScholar can be used to find articles from a wide variety of academic publishers, professional societies,\npreprint repositories and universities, as well as scholarly articles available across the web.Google Suggest—guesses what you're typing and offers suggestions in real time.This is similar to\nGoogle's "Did you mean?"feature that offers alternative spellings for your query after you search, except\nthat it works in real time.", "pageIdentifier": "17" }, { "content": "Groups contains more than 1 billion messages from Usenet Internet discussion groups dating back to 1981.The\ndiscussions in these groups cover a broad range of discourse and provide a comprehensive look at evolving\nviewpoints, debate and advice on many subjects.The new Google Groups adds in the ability to create your own\ngroups for you and your friends and an improved user interface.Google Mobile.Google Mobile offers people the ability to search and view both the "mobile web,"\nconsisting of pages created specifically for wireless devices, and the entire Google index of more than 8 billion\nweb pages.Google Mobile works on devices that support WAP, WAP 2.0, i-mode or j-sky mobile Internet\nprotocols.In addition, users can access a variety of information using Google SMS by typing a query to the\nGoogle shortcode.Google Mobile is available through many wireless and mobile phone services worldwide.\n\nGoogle Local.Google Local enables users to find relevant local businesses near a city, postal code, or specific\naddress.This service combines Yellow Page listings with information found on web pages, and plots their\nlocations on interactive maps.Google Print.Google Print brings information online that had previously not been available to web\nsearchers.Under this program, we enable a number of publishers to host their content and show their\npublications at the top of our search results.", "pageIdentifier": "17" }, { "content": "Votes cast by important web pages with high PageRank weigh more heavily and are\nmore influential in deciding the PageRank of pages on the web.Text-Matching Techniques.Our technology employs text-matching techniques that compare search queries\nwith the content of web pages to help determine relevance.Our text-based scoring techniques do far more than\ncount the number of times a search term appears on a web page.For example, our technology determines the\nproximity of individual search terms to each other on a given web page, and prioritizes results that have the\nsearch terms near each other.Many other aspects of a page's content are factored into the equation, as is the\ncontent of pages that link to the page in question.By combining query independent measures such as PageRank\nwith our text-matching techniques, we are able to deliver search results that are relevant to what people are\ntrying to find.\n\nAdvertising Technology\nOur advertising program serves millions of relevant, targeted ads each day based on search terms people\n\nenter or content they view on the web.The key elements of our advertising technology include:\n\nGoogle AdWords Auction System.We use the Google AdWords auction system to enable advertisers to\nautomatically deliver relevant, targeted advertising.", "pageIdentifier": "21" }, { "content": "Votes cast by important web pages with high PageRank weigh more heavily and are\nmore influential in deciding the PageRank of pages on the web.Text-Matching Techniques.Our technology employs text-matching techniques that compare search queries\nwith the content of web pages to help determine relevance.Our text-based scoring techniques do far more than\ncount the number of times a search term appears on a web page.For example, our technology determines the\nproximity of individual search terms to each other on a given web page, and prioritizes results that have the\nsearch terms near each other.Many other aspects of a page's content are factored into the equation, as is the\ncontent of pages that link to the page in question.By combining query independent measures such as PageRank\nwith our text-matching techniques, we are able to deliver search results that are relevant to what people are\ntrying to find.\n\nAdvertising Technology\nOur advertising program serves millions of relevant, targeted ads each day based on search terms people\n\nenter or content they view on the web.The key elements of our advertising technology include:", "pageIdentifier": "21" }, { "content": "Google Maps—enables users to see maps, get directions, and find local businesses and services quickly\nand easily.Google Maps has several unique features, including draggable maps, integrated local search\nfrom Google Local, and keyboard shortcuts.Google Scholar—enables users to search specifically for scholarly literature, including peer-reviewed\npapers, theses, books, preprints, abstracts and technical reports from all broad areas of research.Google\nScholar can be used to find articles from a wide variety of academic publishers, professional societies,\npreprint repositories and universities, as well as scholarly articles available across the web.Google Suggest—guesses what you're typing and offers suggestions in real time.This is similar to\nGoogle's "Did you mean?"feature that offers alternative spellings for your query after you search, except\nthat it works in real time.Google Video—includes thousands of programs that play on our TVs every day.Google Video enables\nyou to search a growing archive of televised content—everything from sports to dinosaur\ndocumentaries to news shows.\n\n6", "pageIdentifier": "17" }, { "content": "Every search query we process involves the automated\nexecution of an auction, resulting in our advertising system often processing hundreds of millions of auctions per\nday.To determine whether an ad is relevant to a particular query, this system weighs an advertiser's willingness\nto pay for prominence in the ad listings (the CPC) and interest from users in the ad as measured by the click\nthrough rate and other factors.If an ad does not attract user clicks, it moves to a less prominent position on the\npage, even if the advertiser offers to pay a high amount.This prevents advertisers with irrelevant ads from\n"squatting" in top positions to gain exposure.Conversely, more relevant, well-targeted ads that are clicked on\nfrequently move up in ranking, with no need for advertisers to increase their bids.Because we are paid only\nwhen users click on ads, the AdWords ranking system aligns our interests equally with those of our advertisers\nand our users.The more relevant and useful the ad, the better for our users, for our advertisers and for us.\n\nThe AdWords auction system also incorporates our AdWords discounter, which automatically lowers the\namount advertisers actually pay to the minimum needed to maintain their ad position.", "pageIdentifier": "21" }, { "content": "Web Search Technology\nOur web search technology uses a combination of techniques to determine the importance of a web page\nindependent of a particular search query and to determine the relevance of that page to a particular search\nquery.We do not explain how we do ranking in great detail because some people try to manipulate our search\nresults for their own gain, rather than in an attempt to provide high-quality information to users.\n\nRanking Technology.One element of our technology for ranking web pages is called PageRank.While we\ndeveloped much of our ranking technology after Google was formed, PageRank was developed at Stanford\nUniversity with the involvement of our founders, and was therefore published as research.Most of our current\nranking technology is protected as trade-secret.PageRank is a query-independent technique for determining the\nimportance of web pages by looking at the link structure of the web.PageRank treats a link from web page A to\nweb page B as a "vote" by page A in favor of page B.The PageRank of a page is the sum of the PageRank of the\npages that link to it.The PageRank of a web page also depends on the importance (or PageRank) of the other\nweb pages casting the votes.", "pageIdentifier": "21" }, { "content": "The Company recognizes as revenue the fees charged advertisers each time a user clicks on one of the text\nbased ads that are displayed next to the search results on Google web sites.Effective January 1, 2004, the\nCompany offered a single pricing structure to all of its advertisers based on the AdWords cost per click model.\n\nGoogle AdSense is the program through which the Company distributes its advertisers' text-based ads for\ndisplay on the web sites of the Google Network members.In accordance with Emerging Issues Task Force\n("EITF") Issue No. 99 19, Reporting Revenue Gross as a Principal Versus Net as an Agent, the Company recognizes\nas revenues the fees it receives from its advertisers.This revenue is reported gross primarily because the\nCompany is the primary obligor to its advertisers.\n\nThe Company generates fees from search services through a variety of contractual arrangements, which\ninclude per-query search fees and search service hosting fees.Revenues from set up and support fees and search\nservice hosting fees are recognized on a straight-line basis over the term of the contract, which is the expected\nperiod during which these services will be provided.The Company's policy is to recognize revenues from per\nquery search fees in the period queries are made and results are delivered.\n\nThe Company provides search services pursuant to certain AdSense agreements.", "pageIdentifier": "85" }, { "content": "On Google Print pages, we provide links to book sellers that may\noffer the full versions of these publications for sale, and we show content-targeted ads that are served through\nthe Google AdSense program.Google Desktop Search.Google Desktop Search enables our users to perform a full text search on the\ncontents of their own computer, including email, files, instant messenger chats and web browser history.Users\ncan use this service to view web pages they have visited even when they are not online.Google Alerts.Google Alerts are email updates of the latest relevant Google results (web, news, etc.) based\non the user's choice of query or topic.Typical uses include monitoring a developing news story, keeping current\non a competitor or industry, getting the latest on a celebrity or event, or keeping tabs on a favorite sports team.Google Labs.Google Labs is our playground for our engineers and for adventurous Google users.On Google\nLabs, we post product prototypes and solicit feedback on how the technology could be used or improved.Current Google Labs examples include:Google Personalized Search—provides customized search results based on an individual user's interests.Froogle Wireless—gives people the ability to search for product information from their mobile phones\nand other wireless devices.", "pageIdentifier": "17" } ] } ] } } }
Obtener citas
Las citas, cuando se especifican, son números que se colocan en línea en un resumen de búsqueda. Estos números indican de qué resultados de búsqueda se han extraído frases concretas del resumen.
Para obtener citas, sigue estos pasos:
Envía una solicitud de búsqueda que incluya
contentSearchSpec.summarySpecy especifique"includeCitations": true. Para obtener más información sobre cómo enviar una solicitud de búsqueda, consulta el artículo Obtener resultados de búsqueda.En el siguiente ejemplo,
summarySpecindica que quieres un resumen de la búsqueda, que el resumen se genere a partir de los tres primeros resultados de búsqueda y que se incluyan citas en el resumen."contentSearchSpec": { "summarySpec": { "summaryResultCount": 3, "includeCitations": true }, "extractiveContentSpec": { "maxExtractiveAnswerCount" : 1} }summaryResultCount: número de resultados principales a partir de los que se generará el resumen de búsqueda. Si el número de resultados devueltos es inferior asummaryResultCount, el resumen se genera a partir de todos los resultados. El valor máximo es5.includeCitations: valor booleano que especifica si se devuelven las citas.maxExtractiveAnswerCount: número de respuestas extractivas que se devuelven por cada resultado de búsqueda. El valor predeterminado es 0 y el máximo es 1.
Obtén el resumen, con citas, de la respuesta de búsqueda. En cada respuesta se devuelve una propiedad
summary.A continuación se muestra un ejemplo de resumen, con citas y metadatos de citas, que se devuelve al final de una respuesta de búsqueda:
"summary": { "summaryText": "BigQuery is Google Cloud's fully managed and completely serverless enterprise data warehouse [1]. BigQuery supports all data types, works across clouds, and has built-in machine learning and business intelligence, all within a unified platform [2, 3].", "summaryWithMetadata": { "summary": "BigQuery is Google Cloud's fully managed and completely serverless enterprise data warehouse. BigQuery supports all data types, works across clouds, and has built-in machine learning and business intelligence, all within a unified platform.", "citationMetadata": { "citations": [ { "startIndex": "0", "endIndex": "101", "sources": [ { "uri": "gs://example-dataset/html/6344007140738632642.html", "title": "About BigQuery", "id": "b6344007140738632642", "referenceIndex": "0" }, { "uri": "gs://example-dataset/html/1365490014946172719.html", "title": "Google Cloud article", "id": "b1365490014946172719", "referenceIndex": "1" }, { "uri": "gs://example-dataset/html/2687910668117268120.html", "title": "BigQuery document", "id": "a2687910668117268120", "referenceIndex": "2" } ] }, { "startIndex": "103", "endIndex": "230", "sources": [ { "referenceIndex": "0" }, { "referenceIndex": "1" }, { "referenceIndex": "2", } ] } ] }, "references": [ { "title": "Sports in the United States", "docName": "projects/123/locations/global/collections/default_collection/dataStores/ds-123/branches/0/documents/b6344007140738632642", "uri": "https://example.com/bigqueryA" }, { "title": "Sports in the United States", "docName": "projects/123/locations/global/collections/default_collection/dataStores/ds-123/branches/0/documents/b1365490014946172719", "uri": "https://example.com/bigqueryB" }, { "title": "Sports in the United States", "docName": "projects/123/locations/global/collections/default_collection/dataStores/ds-123/branches/0/documents/a268791066811726812", "uri": "https://example.com/bigqueryC" } ] } }summaryText: el resumen de la búsqueda, con los números de cita. Los números de cita hacen referencia a los resultados de búsqueda devueltos y están indexados a partir del 1. Por ejemplo,[1]significa que la frase se atribuye al primer resultado de búsqueda.[2, 3]significa que la frase se atribuye tanto al segundo como al tercer resultado de búsqueda.citations: por cada frase del resumen que tenga una cita, se muestra los metadatos de esa cita.startIndex: indica el inicio de la frase, medido en bytes Unicode.endIndex: indica el final de la frase, medido en bytes Unicode.sources: muestra lareferenceIndexde cada fuente que se ha incluido en la cita de la frase.referenceIndexes el número de índice asignado a una fuente. ElreferenceIndexde la primera fuente no siempre se devuelve explícitamente en la respuesta. ComoreferenceIndexse basa en el índice 0, la primera fuente siempre tiene unreferenceIndexde 0.references: muestra los metadatos de cada referencia que se ha citado en el resumen. Los metadatos incluyentitle,docNameyuri.
Ignorar consultas adversarias
Las consultas adversarias incluyen comentarios negativos o están diseñadas para generar resultados no seguros que infringen las políticas. Puede especificar que no se devuelvan resúmenes de búsqueda para consultas engañosas. Cuando se ignora una consulta adversarial, la propiedad summaryText contiene texto predefinido que indica que no se devuelve ningún resumen de búsqueda. Los documentos de búsqueda se devuelven para consultas adversarias, aunque los resúmenes de búsqueda no.
Para especificar que no se devuelvan resúmenes de búsqueda para consultas adversarias, sigue estos pasos:
Envía una solicitud de búsqueda que incluya
contentSearchSpec.summarySpecy especifique"ignoreAdversarialQuery": true. Para obtener más información sobre cómo enviar una solicitud de búsqueda, consulta el artículo Obtener resultados de búsqueda.En el siguiente ejemplo,
summarySpecindica que quieres un resumen de la búsqueda, que el resumen se debe generar a partir de los tres primeros resultados de búsqueda, pero que no se debe devolver ningún resumen para las consultas adversarias."contentSearchSpec": { "summarySpec": { "summaryResultCount": 3, "ignoreAdversarialQuery": true }, "extractiveContentSpec": { "maxExtractiveAnswerCount" : 1} }summaryResultCount: número de resultados principales a partir de los que se generará el resumen de búsqueda. Si el número de resultados devueltos es inferior asummaryResultCount, el resumen se genera a partir de todos los resultados. El valor máximo es5.ignoreAdversarialQuery: valor booleano que especifica que no se deben devolver resúmenes de búsqueda para las consultas adversarias.maxExtractiveAnswerCount: número de respuestas extractivas que se devuelven por cada resultado de búsqueda. El valor predeterminado es 0 y el máximo es 1.
Consulta la propiedad
summaryque se devuelve en una solicitud de búsqueda adversarial.A continuación se muestra un ejemplo:
"summary": { "summaryText": "We do not have a summary for your query. Here are some search results.", "summarySkippedReasons": [ "ADVERSARIAL_QUERY_IGNORED" ] }summaryText: texto genérico que indica que no se ha devuelto ningún resumen de búsqueda.summarySkippedReasons: una enumeración con valores para los motivos por los que se ha omitido el resumen.
Ignorar las consultas que no buscan resúmenes
Las consultas que no buscan resúmenes devuelven resultados que no son adecuados para resumir. Por ejemplo, "¿Por qué el cielo es azul?" y "¿Quién es el mejor futbolista del mundo?" son consultas que buscan un resumen, pero "Aeropuerto de San Francisco" y "Mundial 2026" no lo son. Lo más probable es que se trate de consultas de navegación. Puedes especificar que no se devuelvan resúmenes de búsqueda para las consultas que no busquen resúmenes. Los documentos de búsqueda se devuelven en consultas que no buscan resúmenes, aunque los resúmenes de búsqueda no se devuelvan.
Para especificar que no se devuelvan resúmenes de búsqueda en las consultas que no busquen resúmenes, siga estos pasos:
Envía una solicitud de búsqueda que incluya
contentSearchSpec.summarySpecy especifique"ignoreNonSummarySeekingQuery": true. Para obtener más información sobre cómo enviar una solicitud de búsqueda, consulta el artículo Obtener resultados de búsqueda.En el siguiente ejemplo,
summarySpecindica que quieres un resumen de la búsqueda, que se debe generar a partir de los tres primeros resultados de búsqueda, pero que no se debe devolver ningún resumen para las consultas que no busquen un resumen."contentSearchSpec": { "summarySpec": { "summaryResultCount": 3, "ignoreNonSummarySeekingQuery": true }, "extractiveContentSpec": { "maxExtractiveAnswerCount" : 1} }summaryResultCount: número de resultados principales a partir de los que se generará el resumen de búsqueda. Si el número de resultados devueltos es inferior asummaryResultCount, el resumen se genera a partir de todos los resultados. El valor máximo es5.ignoreNonSummarySeekingQuery: valor booleano que especifica que no se deben devolver resúmenes de búsqueda para las consultas que no busquen resúmenes.maxExtractiveAnswerCount: número de respuestas extractivas que se devuelven por cada resultado de búsqueda. El valor predeterminado es 0 y el máximo es 1.
Consulta la propiedad
summaryque se devuelve en una solicitud de búsqueda que no busca un resumen.A continuación se muestra un ejemplo:
"summary": { "summaryText": "We do not have a summary for your query. Here are some search results.", "summarySkippedReasons": [ "NON_SUMMARY_SEEKING_QUERY_IGNORED" ] }summaryText: texto genérico que indica que no se ha devuelto ningún resumen de búsqueda.summarySkippedReasons: una enumeración con valores para los motivos por los que se ha omitido el resumen.
Obtener resúmenes personalizados
Puedes obtener resúmenes personalizados proporcionando instrucciones en lenguaje natural.
Esta función está disponible para el widget de búsqueda mediante la consola y para la API introduciendo instrucciones en el campo modelPromptSpec.preamble.
Puedes solicitar personalizaciones como la longitud, el nivel de detalle, el estilo de la respuesta (por ejemplo, "simple"), el idioma de la respuesta, el enfoque de la respuesta y el formato (por ejemplo, tablas, viñetas y XML).
Por ejemplo, para la consulta What are the benefits of bigquery?, puedes introducir instrucciones de personalización como las de los siguientes ejemplos:
Ejemplo de instrucción:
please show the answer format in an ordered listRespuesta de ejemplo:
The benefits of BigQuery are: 1. Increased business productivity 2. IT staff productivity 3. Reduced infrastructure costs 4. Loading and exporting data are freeEjemplo de instrucción:
give a very detailed answerRespuesta de ejemplo:
BigQuery is a serverless, highly scalable, and cost-effective cloud data warehouse that enables businesses to analyze all their data very quickly. It is a fully managed service that takes care of provisioning, scaling, and managing the underlying infrastructure, so you can focus on analyzing your data. BigQuery is also integrated with other Google Cloud services, such as Google Kubernetes Engine, Cloud Data Fusion, and Cloud Dataproc, making it easy to build and deploy data pipelines. Here are some of the benefits of using BigQuery: * **Fast and scalable:** BigQuery can process petabytes of data very quickly, and it can scale to handle even the most demanding workloads. * **Cost-effective:** BigQuery is a very cost-effective way to store and analyze data. You only pay for the data that you use, and there are no upfront costs or commitments. * **Secure:** BigQuery is a secure platform that meets the needs of even the most security-conscious organizations. * **Easy to use:** BigQuery is easy to use, even for non-technical users. It has a simple and intuitive user interface, and it supports a variety of data sources. * **Integrated with other Google Cloud services:** BigQuery is integrated with other Google Cloud services, making it easy to build and deploy data pipelines. If you are looking for a fast, scalable, and cost-effective way to analyze your data, then BigQuery is a great option.
Prácticas recomendadas para los resúmenes personalizados
Si tiene previsto usar esta función, siga estos pasos:
- Solicita solo una personalización a la vez. No combine personalizaciones. Por ejemplo, no solicite una tabla HTML en francés.
- Google recomienda que imponga límites en las personalizaciones que pueden solicitar sus usuarios finales. Por ejemplo, puede ofrecer un selector con un conjunto de personalizaciones predefinidas.
Personalizar resúmenes
Puedes obtener resúmenes personalizados solo para el widget de búsqueda mediante la consola o, para cualquier solicitud de búsqueda, mediante la API.
Para obtener un resumen personalizado, sigue estos pasos:
Consola
En la Google Cloud consola, ve a la página Aplicaciones de IA.
Haz clic en el nombre de la aplicación que quieras editar.
Ve a Configuraciones > Interfaz de usuario.
Comprueba que el Tipo de búsqueda de tu widget de búsqueda esté configurado como Buscar con una respuesta o Buscar con seguimiento. Esta función no está disponible si se selecciona Buscar.
Activa Habilitar personalización del resumen.
Para introducir instrucciones de resumen, haz una de las siguientes acciones:
- Introduce instrucciones de formato libre: escribe tus propias instrucciones en lenguaje natural en el campo Preamble.
- Usar instrucciones de plantilla: haz clic en Sustituir por una plantilla y selecciona una de las instrucciones de plantilla predefinidas. La plantilla predefinida aparece en el campo Preamble después de seleccionarla.
Prueba la generación de resúmenes personalizados de tu aplicación buscando en el panel Vista previa.
Para volver al último conjunto de instrucciones guardado, haz clic en Restablecer preámbulo.
Para guardar los ajustes en el widget, haz clic en Guardar y publicar.
REST
Envía una solicitud de búsqueda que incluya
contentSearchSpec.summarySpecy especifica la instrucción de personalización enmodelPromptSpec.preamble. Para obtener más información sobre cómo enviar una solicitud de búsqueda, consulta el artículo Obtener resultados de búsqueda.En el siguiente ejemplo,
summarySpecindica que quieres un resumen de la búsqueda, que se genere a partir de los tres primeros resultados de búsqueda y que se personalice como si se le explicara a un niño de 10 años."contentSearchSpec": { "summarySpec": { "summaryResultCount": 3, "modelPromptSpec": { "preamble": "explain like you would to a ten year old" } } }summaryResultCount: número de resultados principales a partir de los que se generará el resumen de búsqueda. Si el número de resultados devueltos es inferior asummaryResultCount, el resumen se genera a partir de todos los resultados. El valor máximo es5.preamble: las instrucciones de personalización.
Obtiene el resumen personalizado de la respuesta de búsqueda.
Aquí tienes un ejemplo de resumen personalizado que se devuelve:
"summary": { "summaryText": "BigQuery is a serverless data warehouse that helps you analyze all your data very quickly. It's very easy to use and you don't need to worry about managing servers or infrastructure. BigQuery is also very scalable, so you can analyze large datasets without any problems." }summaryText: el resumen de la búsqueda personalizada.
Especificar el modelo de resumen
Puedes especificar el modelo que quieres usar para generar resúmenes.
Puedes especificar stable, preview o una versión de modelo específica por su nombre.
Para ver las versiones de modelo disponibles, consulta Versiones y ciclo de vida del modelo de generación de respuestas.
Para cambiar la versión del modelo, sigue estos pasos:
Envía una solicitud de búsqueda que incluya
ContentSearchSpec.SummarySpec.ModelSpecpara especificar la versión del modelo."contentSearchSpec": { "summarySpec": { "modelSpec": { "version": "MODEL_VERSION" } } }MODEL_VERSION: especifica el modelo que se va a usar para generar resúmenes. Los valores admitidos son:
stable: cadena. Especificación predeterminada cuando no se especifica ningún valor.stableapunta a una versión del modelo de GA que se ha ajustado para generar respuestas. Qué modelostableapunta a los cambios a medida que se lanzan nuevas versiones del modelo de GA y se dejan de ofrecer las versiones anteriores. Para ver la versión actualizada a la questablehace referencia, consulta Versiones y ciclo de vida del modelo de generación de respuestas.preview: cadena.previewapunta al modelo de Gemini más reciente para responder preguntas. Para obtener más información sobre Gemini, consulta la descripción general de los modelos.- Para especificar una versión del modelo, introduce el nombre de la versión, como
gemini-1.5-flash-002/answer_gen/v1. Para ver las versiones compatibles, consulta Versiones y ciclo de vida del modelo de generación de respuestas.
Por ejemplo, la siguiente solicitud de búsqueda especifica preview como versión del modelo:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
"https://discoveryengine.googleapis.com/v1/projects/exampleproject/locations/global/collections/default_collection/dataStores/exampledatastore/servingConfigs/default_search:search" \
-d '{
"query": "what is bigquery",
"contentSearchSpec": {
"summarySpec": {
"modelSpec": {
"version": "preview"
}
}
}
}'
Limitaciones de los resúmenes de búsqueda
Puede que te encuentres las siguientes limitaciones al usar resúmenes de búsqueda:
Como los LLMs se usan para generar resúmenes y citas de búsqueda, las limitaciones de los LLMs también se aplican a los resúmenes de Vertex AI Search.
Para obtener información general sobre estas limitaciones de los LLMs, consulta las limitaciones de la API PaLM en la documentación de Vertex AI.
Las consultas de búsqueda que requieren un razonamiento lógico o analítico complejo, o bien una comprensión del mundo, pueden dar lugar a resúmenes de búsqueda que contengan información incorrecta (alucinaciones) o información que no esté presente en los datos no estructurados o del sitio web.
Es posible que algunas afirmaciones del resumen de búsqueda no incluyan una cita:
Si el sistema determina que una afirmación no requiere una base, no incluirá una cita. Las frases como "Esto es lo que he encontrado" o "Hay muchos métodos que puedes seguir" no incluyen citas.
La falta de citas también puede indicar que no se ha encontrado una referencia válida. Los datos sin citas pueden no ser fiables.
En contadas ocasiones, las citas pueden atribuirse incorrectamente a una afirmación.
Es posible que la LLM analice documentos complejos de forma incorrecta. En ese caso, el resumen podría estar incompleto o ser incorrecto.
Como las instrucciones de personalización están en lenguaje natural, no se puede garantizar que se cumplan en todas las solicitudes.