Entenda leituras e gravações em escala
Leia este documento para tomar decisões bem embasadas sobre a arquitetura dos seus aplicativos para alto desempenho e confiabilidade. Este documento inclui tópicos avançados do Firestore. Se você está começando a usar o Firestore, consulte o guia de início rápido.
É importante entender a mecânica das leituras e gravações no back-end do Firestore para garantir que seus aplicativos continuem apresentando bom desempenho à medida que o tamanho do banco de dados cresce e o tráfego aumenta. É preciso entender também a interação de suas leituras e gravações com a camada de armazenamento e as restrições subjacentes que podem afetar o desempenho.
Consulte as seções a seguir para conhecer as práticas recomendadas antes de criar a arquitetura do seu aplicativo.
Entenda os componentes de alto nível
O diagrama a seguir mostra os componentes de alto nível envolvidos em uma solicitação da API Firestore.
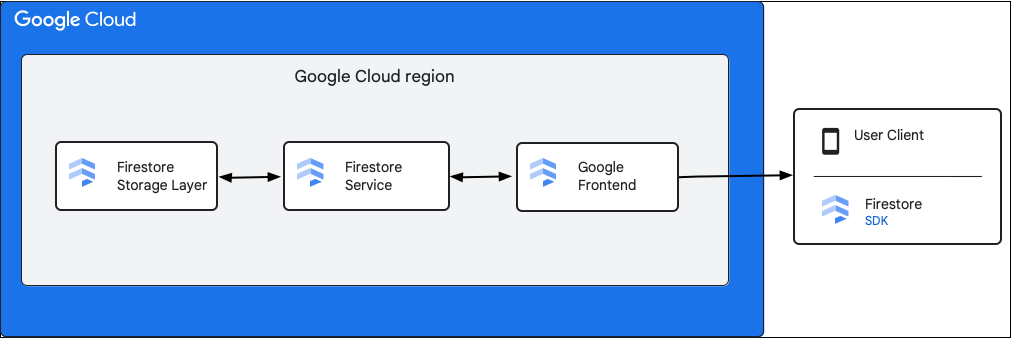
SDKs, bibliotecas de cliente e drivers
O Firestore oferece suporte a SDKs, bibliotecas de cliente e drivers para diferentes plataformas.
Google Front End (GFE)
Esse é um serviço de infraestrutura comum a todos os serviços do Google Cloud . O GFE aceita solicitações de entrada e as encaminha para o serviço do Google relevante (serviço Firestore neste contexto).
Serviço do Firestore
O serviço do Firestore realiza verificações na solicitação da API, o que inclui autenticação, autorização, verificações de cota e também gerencia transações. Esse serviço do Firestore inclui um cliente de armazenamento que interage com a camada de armazenamento para as leituras e gravações dos dados.
Camada de armazenamento do Firestore
A camada de armazenamento do Firestore é responsável por armazenar dados e metadados, além dos recursos de banco de dados associados fornecidos pelo Firestore. As seções a seguir descrevem como os dados são organizados na camada de armazenamento do Firestore e como o sistema é escalonado. Saber como os dados são organizados pode ajudar você a projetar um modelo de dados escalonável e entender melhor as práticas recomendadas no Firestore.
Intervalos de chave e divisões
O Firestore é um banco de dados NoSQL orientado a documentos. Os dados são armazenados em documentos, que são organizados em coleções. O nome da coleção e o ID do documento formam uma chave exclusiva para um documento. Os documentos na mesma coleção são armazenados juntos no keyspace. Nesse keyspace, o ID do documento é hash. O termo intervalo de chaves se refere a um intervalo contíguo de chaves no armazenamento.
O Firestore particiona automaticamente os dados em coleções em vários servidores de armazenamento. Essas partições são chamadas de divisões.
Os documentos podem gerar entradas de índice ordenadas lexicograficamente e participar do mesmo tipo de divisão e posicionamento dos dados do documento.
Replicação síncrona
Cada gravação é replicada de forma síncrona para a maioria das réplicas usando o Paxos. Uma réplica por divisão é considerada um líder e coordena o processo de replicação. Em caso de falha do líder, um novo líder é eleito. As réplicas estão localizadas em diferentes zonas para serem resilientes a possíveis falhas de zona. O resultado geral é um sistema escalonável e altamente disponível que fornece latências baixas para leituras e gravações, independentemente de cargas de trabalho pesadas e em grande escala.
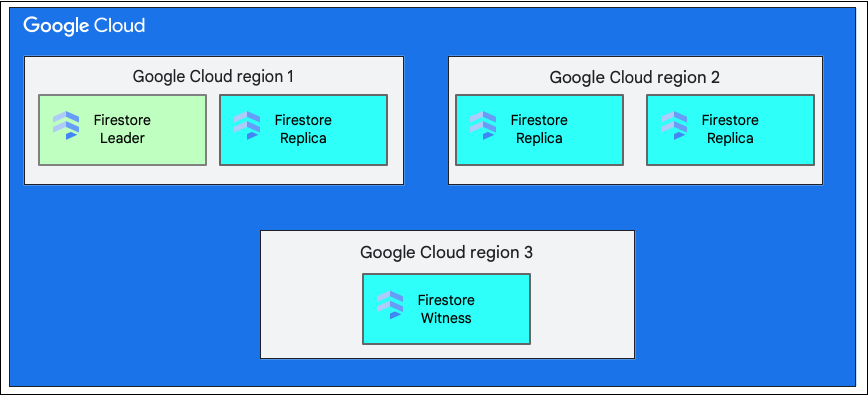
Região única versus multirregião
Ao criar um banco de dados, você precisa selecionar um local regional único ou um local multirregional.
Um único local regional é uma localização geográfica específica, como us-west1. As divisões de dados de um banco de dados do Firestore têm réplicas em diferentes zonas dentro da região selecionada, conforme explicado anteriormente.
Um local multirregional consiste em um conjunto definido de regiões em que o Firestore armazena réplicas do banco de dados. Em uma implantação multirregional do Firestore, duas regiões têm réplicas completas de todos os dados no banco de dados. Uma terceira região tem uma réplica testemunha que não mantém um conjunto completo de dados, mas participa da replicação. Os dados ficam disponíveis para gravação e leitura mesmo com a perda de uma região inteira, porque o Firestore replica os dados entre várias regiões.
Para mais informações sobre os locais de uma região, consulte Locais do Firestore.
Entenda a vida útil de uma gravação
Um driver pode gravar dados criando, atualizando ou excluindo um único documento. Uma gravação em um único documento requer a atualização atômica do documento e de suas entradas de índice associadas na camada de armazenamento. O Firestore também é compatível com operações atômicas que consistem em várias leituras e gravações em um ou mais documentos.
Para todos os tipos de gravação, o Firestore fornece as propriedades ACID (atomicidade, consistência, isolamento e durabilidade) de bancos de dados relacionais. O Firestore também oferece capacidade de serialização, o que significa que todas as transações aparecem como se tivessem sido executadas em uma ordem serial.
Etapas avançadas em uma transação de gravação
Quando o driver emite uma gravação ou confirma uma transação usando qualquer um dos métodos mencionados anteriormente, isso é executado internamente como uma transação de leitura e gravação de banco de dados na camada de armazenamento. A transação permite que o Firestore forneça as propriedades ACID mencionadas anteriormente.
Como primeira etapa de uma transação, o Firestore lê o documento existente e determina as mutações feitas nos dados dele.
Isso também inclui fazer atualizações em todos os índices relevantes:
- Os campos indexados que estão sendo adicionados aos documentos precisam de inserções correspondentes nos índices.
- Os campos indexados que estão sendo removidos dos documentos precisam de exclusões correspondentes nos índices.
- Os campos indexados que estão sendo modificados nos documentos precisam de exclusões (para valores antigos) e inserções (para novos valores) nos índices.
Para calcular as mutações mencionadas anteriormente, o Firestore lê a configuração de indexação do projeto. A configuração de indexação armazena informações sobre os índices de um projeto.
Depois que as mutações são calculadas, o Firestore as coleta dentro de uma transação e, em seguida, as confirma.
Entenda uma transação de gravação na camada de armazenamento
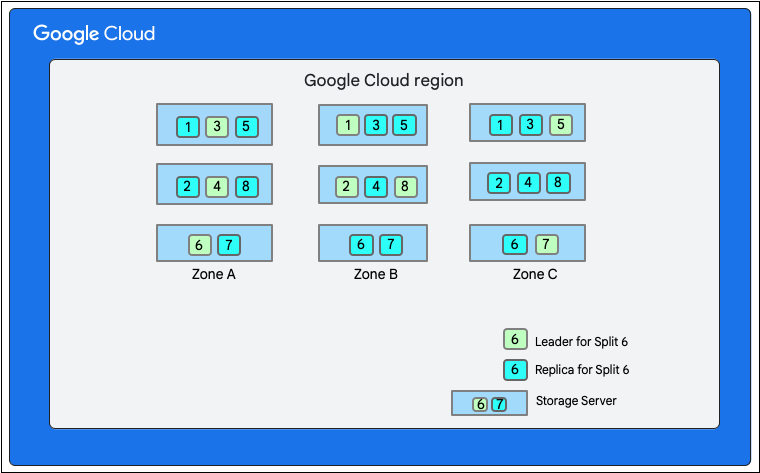
Como discutido anteriormente, uma gravação no Firestore envolve uma transação de leitura/gravação na camada de armazenamento. Dependendo do layout dos dados, uma gravação pode envolver uma ou mais divisões.
No diagrama a seguir, o banco de dados do Firestore tem oito divisões (marcadas de 1 a 8) hospedadas em três servidores de armazenamento diferentes em uma única zona, e cada divisão é replicada em três ou mais zonas diferentes. Cada divisão tem um líder do Paxos, que pode estar em uma zona diferente no caso de divisões diferentes.
Considere um banco de dados do Firestore que tenha a coleção Restaurants da seguinte maneira:
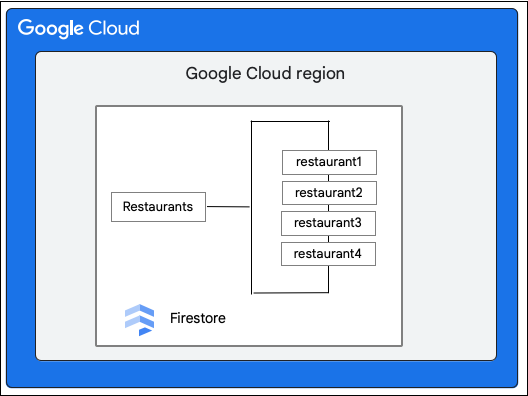
O motorista solicita a seguinte mudança em um documento na coleção Restaurant atualizando o valor do campo priceCategory.
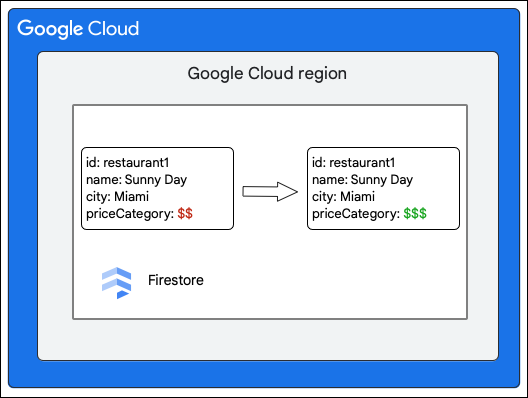
As etapas avançadas a seguir descrevem o que acontece como parte da gravação:
- Crie uma transação de leitura/gravação.
- Leia o documento
restaurant1na coleçãoRestaurants. - Leia os índices do documento.
- Calcule as mutações a serem feitas nos dados. Nesse caso, há cinco mutações:
- M1: atualize a linha de
restaurant1para refletir a mudança no valor do campopriceCategory. - M2 e M3: exclua as entradas de índice antigas de
priceCategory. - M4 e M5: adicione novas entradas de índice para
priceCategory.
- M1: atualize a linha de
- Confirme essas mutações.
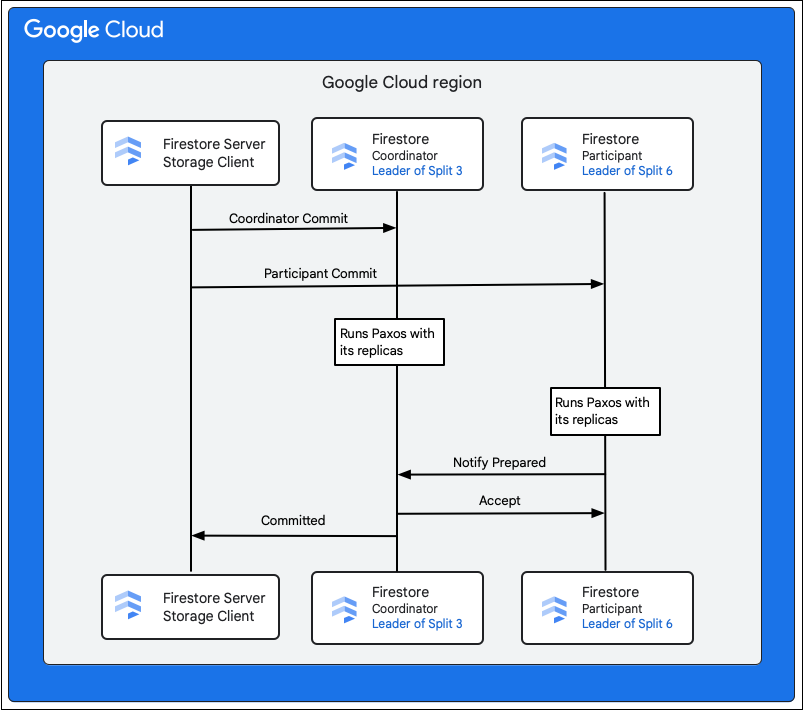
O cliente de armazenamento no serviço do Firestore pesquisa as divisões que têm as chaves das linhas a serem alteradas. Considere um caso em que a Divisão 3 atende M1 e a Divisão 6 atende M2-M5. Há uma transação distribuída, envolvendo todas essas divisões como participantes. As divisões do participante também podem incluir qualquer outra divisão da qual os dados foram lidos anteriormente como parte da transação de leitura/gravação.
As etapas a seguir descrevem o que acontece como parte da confirmação:
- O cliente de armazenamento emite uma confirmação. A confirmação contém as mutações M1-M5.
- As divisões 3 e 6 são os participantes dessa transação. Um dos participantes é escolhido como o coordenador, como a Divisão 3, por exemplo. O trabalho dele é garantir que a transação seja confirmada ou cancelada atomicamente em todos os participantes.
- As réplicas líderes dessas divisões são responsáveis pelo trabalho realizado pelos participantes e coordenadores.
- Cada participante e coordenador executa um algoritmo Paxos com as respectivas réplicas.
- O líder executa um algoritmo Paxos com as réplicas. O quórum é alcançado se a maioria das réplicas responder com uma resposta
ok to commitao líder. - Em seguida, cada participante notifica o coordenador quando está preparado (primeira fase da confirmação de duas fases). Se algum participante não puder confirmar a transação, toda a transação
aborts.
- O líder executa um algoritmo Paxos com as réplicas. O quórum é alcançado se a maioria das réplicas responder com uma resposta
- Depois que o coordenador sabe que todos os participantes, incluindo ele mesmo, estão preparados, comunica o resultado da transação do
accepta todos os participantes (segunda fase da confirmação de duas fases). Nesta fase, cada participante registra a decisão de confirmação no armazenamento estável e a transação é confirmada. - O coordenador responde ao cliente de armazenamento no Firestore que a transação foi confirmada. Paralelamente, o coordenador e todos os participantes aplicam as mutações aos dados.
Quando o banco de dados do Firestore é pequeno, pode acontecer de uma única divisão ter todas as chaves nas mutações M1-M5. Nesse caso, há apenas um participante na transação e a confirmação de duas fases mencionada anteriormente não é necessária, tornando as gravações mais rápidas.
Gravações em multirregiões
Em uma implantação multirregional, a distribuição de réplicas entre regiões aumenta a disponibilidade, mas tem um custo de desempenho. A comunicação entre as réplicas em diferentes regiões aumenta o tempo de retorno. Portanto, a latência do valor de referência para as operações do Firestore é um pouco maior em comparação com as implantações de região única.
Configuramos as réplicas de modo que a liderança para divisões sempre permaneça na região principal. A região principal é aquela que recebe o tráfego para o servidor do Firestore. Essa decisão da liderança reduz o atraso do tempo de retorno na comunicação entre o cliente de armazenamento no Firestore e o líder da réplica (ou coordenador de transações com várias divisões).
Entenda a vida útil de uma leitura
Esta seção analisa detalhadamente as leituras no Firestore. As consultas, em particular, consistem em uma combinação de leituras de documentos e de entradas de índice.
As leituras de dados da camada de armazenamento são feitas internamente usando uma transação de banco de dados para garantir leituras consistentes. No entanto, ao contrário das transações usadas para gravações, essas transações não têm bloqueios. Em vez disso, elas escolhem um carimbo de data/hora e executam todas as leituras com esse carimbo. Como elas não adquirem bloqueios, elas não bloqueiam transações simultâneas de leitura/gravação. Para executar essa transação, o cliente de armazenamento no Firestore especifica um limite de carimbo de data/hora, que informa à camada de armazenamento como escolher um carimbo de data/hora de leitura. O tipo de limite de carimbo de data/hora escolhido pelo cliente de armazenamento no Firestore é determinado pelas opções de leitura para a solicitação de leitura.
Entenda uma transação de leitura na camada de armazenamento
Esta seção descreve os tipos de leituras e como elas são processadas na camada de armazenamento no Firestore.
Leituras fortes
Por padrão, as leituras do Firestore são altamente consistentes. Essa consistência forte significa que uma leitura do Firestore retorna a versão mais recente dos dados que refletem todas as gravações que foram confirmadas até o início da leitura.
Leitura de divisão única
O cliente de armazenamento no Firestore procura as divisões que têm as chaves das linhas a serem lidas. Vamos supor que ele precise fazer uma leitura da Divisão 3 a partir da seção anterior. O cliente envia a solicitação de leitura para a réplica mais próxima para reduzir a latência de ida e volta.
Neste ponto, os seguintes casos podem acontecer, dependendo da réplica escolhida:
- A solicitação de leitura vai para uma réplica líder (Zona A).
- Como o líder está sempre atualizado, a leitura pode prosseguir diretamente.
- A solicitação de leitura vai para uma réplica não líder (como a Zona B)
- A Divisão 3 pode saber, pelo estado interno, que tem informações suficientes para atender à leitura, e a divisão faz isso.
- A Divisão 3 não tem certeza se teve acesso aos dados mais recentes. Ela envia uma mensagem ao líder para solicitar o carimbo de data/hora da última transação que precisa ser aplicado para exibir a leitura. Depois que essa transação é aplicada, a leitura pode prosseguir.
O Firestore retorna a resposta para o cliente.
Leitura de várias divisões
Na situação em que as leituras precisam ser feitas de várias divisões, o mesmo mecanismo acontece em todas as divisões. Depois que os dados forem retornados de todas as divisões, o cliente de armazenamento no Firestore vai combinar os resultados. O Firestore responde ao cliente com esses dados.
Evite pontos de acesso
As divisões no Firestore são automaticamente divididas em partes menores para distribuir o trabalho de veiculação de tráfego a mais servidores de armazenamento quando necessário ou quando o espaço da chave é expandido. As divisões criadas para lidar com o excesso de tráfego são retidas por cerca de 24 horas, mesmo que o tráfego desapareça. Portanto, se houver picos de tráfego recorrentes, as divisões serão mantidas e mais divisões serão introduzidas sempre que necessário. Esses mecanismos ajudam o escalonamento automático dos bancos de dados do Firestore para aumentar a carga do tráfego ou o tamanho do banco de dados. No entanto, há algumas limitações que devem ser consideradas.
A divisão do armazenamento e da carga demora, e o aumento rápido do tráfego pode causar erros de alta latência ou de prazo excedido, geralmente chamados de pontos de acesso, enquanto o serviço é ajustado. A prática recomendada é distribuir operações no intervalo de chaves, enquanto se intensifica o tráfego gradualmente em uma coleção em um banco de dados.
Embora as divisões sejam criadas automaticamente com carga crescente, o Firestore só pode dividir um intervalo de chaves até exibir um único documento usando um conjunto dedicado de servidores de armazenamento replicados. Como resultado, grandes volumes de operações simultâneas em um único documento podem levar a um ponto de acesso nesse documento. Se você encontrar altas latências sustentadas em um único documento, modifique seu modelo de dados para dividir ou replicar os dados em vários documentos.
Os erros de contenção ocorrem quando várias operações tentam ler e gravar o mesmo documento simultaneamente.
Seguindo as práticas descritas nesta página, o Firestore pode ser escalonado para atender cargas de trabalho arbitrariamente grandes sem a necessidade de ajustar qualquer configuração.