Compreenda as leituras e as escritas em grande escala
Leia este documento para tomar decisões informadas sobre a arquitetura das suas aplicações para um elevado desempenho e fiabilidade. Este documento inclui tópicos avançados do Firestore. Se está a começar a usar o Firestore, consulte o guia de início rápido.
O Firestore é uma base de dados flexível e escalável para o desenvolvimento de dispositivos móveis, Web e servidores a partir do Firebase e Google Cloud. É muito fácil começar a usar o Firestore e escrever aplicações avançadas e poderosas.
Para garantir que as suas aplicações continuam a ter um bom desempenho à medida que o tamanho da base de dados e o tráfego aumentam, é útil compreender a mecânica das leituras e escritas no back-end do Firestore. Também tem de compreender a interação das suas leituras e escritas com a camada de armazenamento e as restrições subjacentes que podem afetar o desempenho.
Consulte as secções seguintes para conhecer as práticas recomendadas antes de criar a arquitetura da sua aplicação.
Compreenda os componentes de alto nível
O diagrama seguinte mostra os componentes de alto nível envolvidos num pedido da API Firestore.
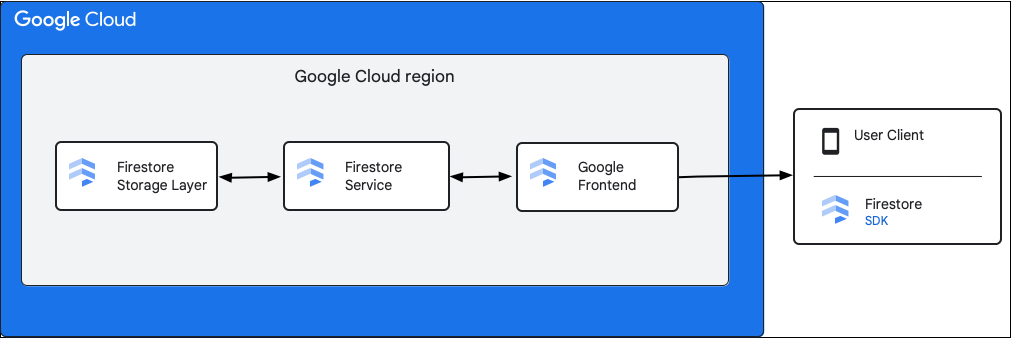
SDK e bibliotecas cliente do Firestore
O Firestore suporta SDKs e bibliotecas cliente para diferentes plataformas. Embora uma app possa fazer chamadas HTTP e RPC diretas para a API Firestore, as bibliotecas cliente fornecem uma camada de abstração para simplificar a utilização da API e implementar práticas recomendadas. Também podem oferecer funcionalidades adicionais, como acesso offline, caches, etc.
Google Front End (GFE)
Este é um serviço de infraestrutura comum a todos os serviços de nuvem Google. O GFE aceita pedidos recebidos e encaminha-os para o serviço Google relevante (serviço Firestore neste contexto). Também oferece outras funcionalidades importantes, incluindo proteção contra ataques de negação de serviço.
Serviço do Firestore
O serviço Firestore realiza verificações no pedido da API, que incluem autenticação, autorização, verificações de quotas e regras de segurança, e também gere transações. Este serviço do Firestore inclui um cliente de armazenamento que interage com a camada de armazenamento para as leituras e escritas de dados.
Camada de armazenamento do Firestore
A camada de armazenamento do Firestore é responsável pelo armazenamento dos dados e metadados, bem como pelas funcionalidades da base de dados associadas fornecidas pelo Firestore. As secções seguintes descrevem como os dados são organizados na camada de armazenamento do Firestore e como o sistema é dimensionado. Saber como os dados estão organizados pode ajudar a criar um modelo de dados escalável e a compreender melhor as práticas recomendadas no Firestore.
Intervalos de chaves e divisões
O Firestore é uma base de dados NoSQL orientada para documentos. Armazena dados em documentos, que estão organizados em hierarquias de coleções. A hierarquia de recolha e o ID do documento são traduzidos numa única chave para cada documento. Os documentos são armazenados logicamente e ordenados lexicograficamente por esta única chave. Usamos o termo intervalo de chaves para nos referirmos a um intervalo de chaves lexicograficamente contíguo.
Uma base de dados do Firestore típica é demasiado grande para caber numa única máquina física. Também existem cenários em que a carga de trabalho nos dados é demasiado pesada para uma única máquina processar. Para processar grandes cargas de trabalho, o Firestore divide os dados em partes separadas que podem ser armazenadas e apresentadas a partir de várias máquinas ou servidores de armazenamento. Estas partições são feitas nas tabelas da base de dados em blocos de intervalos de chaves denominados divisões.
Replicação síncrona
É importante ter em atenção que a base de dados está sempre a ser replicada de forma automática e síncrona. As divisões de dados têm réplicas em diferentes zonas para as manter disponíveis, mesmo quando uma zona se torna inacessível. A replicação consistente nas diferentes cópias da divisão é gerida pelo algoritmo Paxos para consenso. Uma réplica de cada divisão é eleita para atuar como líder do Paxos, que é responsável pelo processamento das escritas nessa divisão. A replicação síncrona permite-lhe ler sempre a versão mais recente dos dados do Firestore.
O resultado geral é um sistema escalável e altamente disponível que oferece baixas latências para leituras e gravações, independentemente das cargas de trabalho pesadas e em grande escala.
Esquema de dados
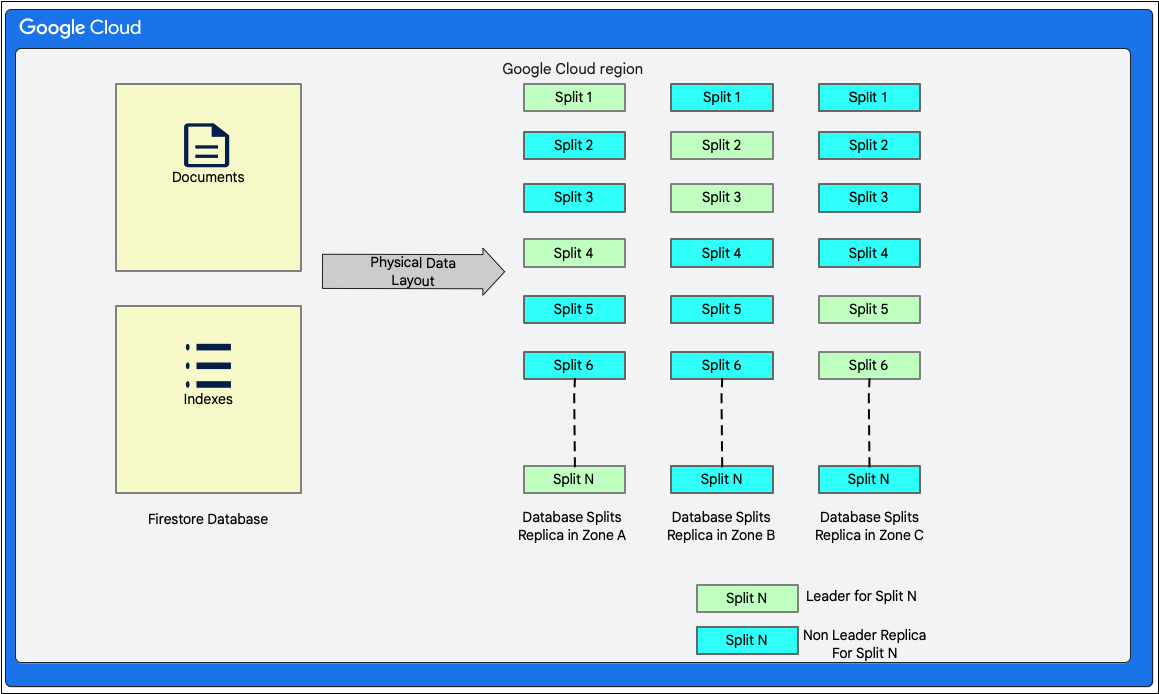
O Firestore é uma base de dados de documentos sem esquema. No entanto, internamente, organiza os dados principalmente em duas tabelas de estilo de base de dados relacional na respetiva camada de armazenamento da seguinte forma:
- Tabela Documents: os documentos são armazenados nesta tabela.
- Tabela de índices: as entradas de índice que permitem obter resultados de forma eficiente e ordenados por valor de índice são armazenadas nesta tabela.
O diagrama seguinte mostra o aspeto das tabelas de uma base de dados do Firestore com as divisões. As divisões são replicadas em três zonas diferentes e cada divisão tem um líder do Paxos atribuído.
Região única versus multirregião
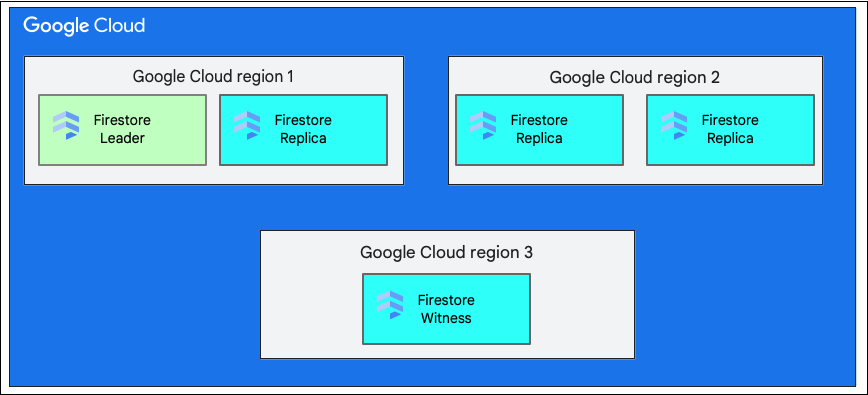
Quando cria uma base de dados, tem de selecionar uma região ou uma multirregião.
Uma única localização regional é uma localização geográfica específica, como us-west1. As divisões de dados de uma base de dados do Firestore têm réplicas em diferentes zonas na região selecionada, conforme explicado anteriormente.
Uma localização multirregional consiste num conjunto definido de regiões onde são armazenadas réplicas da base de dados. Numa implementação multirregional do Firestore, duas das regiões têm réplicas completas de todos os dados na base de dados. Uma terceira região tem uma réplica de testemunho que não mantém um conjunto completo de dados, mas participa na replicação. Ao replicar os dados entre várias regiões, os dados estão disponíveis para serem escritos e lidos, mesmo com a perda de uma região inteira.
Para mais informações sobre as localizações de uma região, consulte o artigo Localizações do Firestore.
Compreenda o ciclo de vida de uma escrita no Firestore
Um cliente do Firestore pode escrever dados criando, atualizando ou eliminando um único documento. Uma gravação num único documento requer a atualização atómica do documento e das respetivas entradas de índice na camada de armazenamento. O Firestore também suporta operações atómicas que consistem em várias leituras e/ou escritas num ou mais documentos.
Para todos os tipos de escritas, o Firestore oferece as propriedades ACID (atomicidade, consistência, isolamento e durabilidade) das bases de dados relacionais. O Firestore também oferece serializability, o que significa que todas as transações aparecem como se fossem executadas numa ordem de série.
Passos de alto nível numa transação de escrita
Quando o cliente do Firestore emite uma gravação ou confirma uma transação, através de qualquer um dos métodos mencionados anteriormente, isto é executado internamente como uma transação de leitura/gravação da base de dados na camada de armazenamento. A transação permite que o Firestore forneça as propriedades ACID mencionadas anteriormente.
Como primeiro passo de uma transação, o Firestore lê o documento existente e determina as mutações a fazer aos dados na tabela Documents.
Isto também inclui fazer as atualizações necessárias à tabela Indexes da seguinte forma:
- Os campos que estão a ser adicionados aos documentos precisam de inserções correspondentes na tabela Indexes.
- Os campos que estão a ser removidos dos documentos precisam de eliminações correspondentes na tabela Indexes.
- Os campos que estão a ser modificados nos documentos precisam de eliminações (para valores antigos) e inserções (para novos valores) na tabela Indexes.
Para calcular as mutações mencionadas anteriormente, o Firestore lê a configuração de indexação do projeto. A configuração de indexação armazena informações sobre os índices de um projeto. O Firestore usa dois tipos de índices: de campo único e compostos. Para uma compreensão detalhada dos índices criados no Firestore, consulte o artigo Tipos de índices no Firestore.
Assim que as mutações são calculadas, o Firestore recolhe-as numa transação e, em seguida, confirma-a.
Compreenda uma transação de escrita na camada de armazenamento
Conforme referido anteriormente, uma escrita no Firestore envolve uma transação de leitura/escrita na camada de armazenamento. Consoante a disposição dos dados, uma gravação pode envolver uma ou mais divisões, conforme apresentado no esquema de dados.
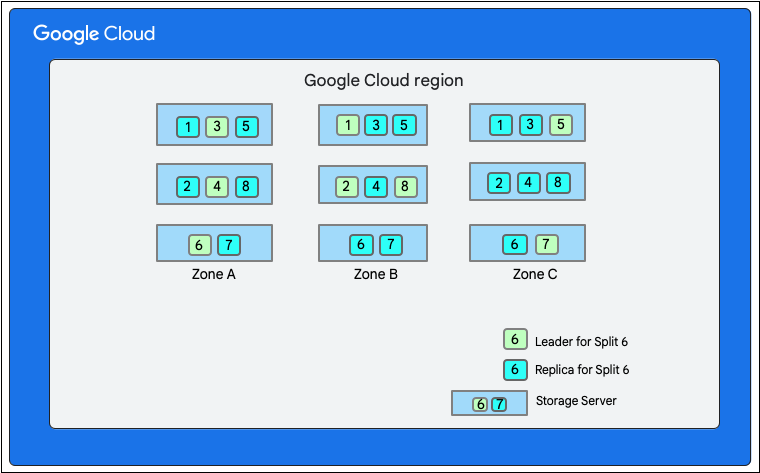
No diagrama seguinte, a base de dados do Firestore tem oito divisões (marcadas de 1 a 8) alojadas em três servidores de armazenamento diferentes numa única zona, e cada divisão é replicada em 3(ou mais) zonas diferentes. Cada divisão tem um líder do Paxos, que pode estar numa zona diferente para diferentes divisões.
Considere uma base de dados do Firestore que tenha a coleção Restaurants da seguinte forma:
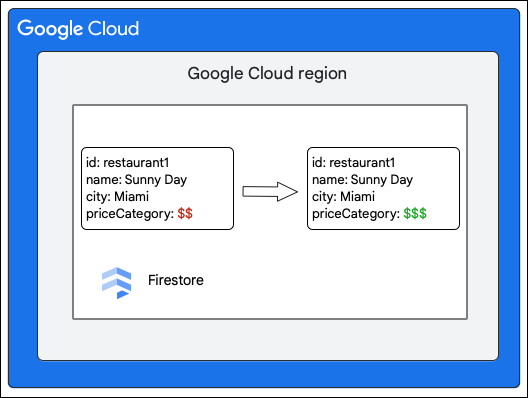
O cliente do Firestore pede a seguinte alteração a um documento na coleção Restaurant atualizando o valor do campo priceCategory.
Os seguintes passos de alto nível descrevem o que acontece como parte da gravação:
- Crie uma transação de leitura/escrita.
- Leia o documento
restaurant1na coleçãoRestaurantsda tabela Documents da camada de armazenamento. - Leia os índices do documento a partir da tabela Índices.
- Calcular as mutações a fazer nos dados. Neste caso, existem cinco mutações:
- M1: atualize a linha de
restaurant1na tabela Documents para refletir a alteração no valor do campopriceCategory. - M2 e M3: elimine as linhas do valor antigo de
priceCategoryna tabela Índices para índices descendentes e ascendentes. - M4 e M5: insira as linhas para o novo valor de
priceCategoryna tabela Índices para índices descendentes e ascendentes.
- M1: atualize a linha de
- Confirme estas mutações.
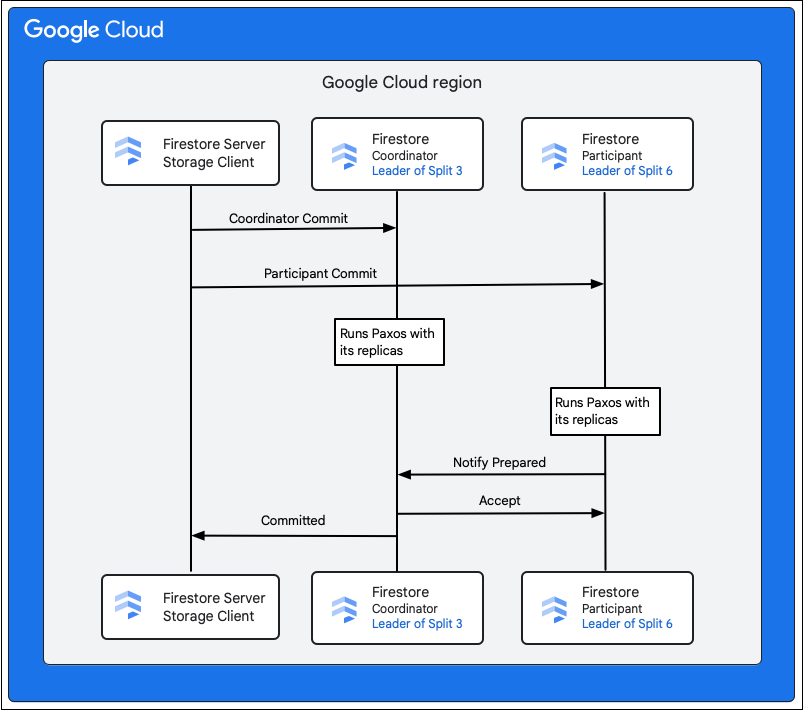
O cliente de armazenamento no serviço Firestore procura as divisões que detêm as chaves das linhas a alterar. Vamos considerar um caso em que a divisão 3 publica M1 e a divisão 6 publica M2 a M5. Existe uma transação distribuída que envolve todas estas divisões como participantes. As divisões de participantes também podem incluir qualquer outra divisão a partir da qual os dados foram lidos anteriormente como parte da transação de leitura/escrita.
Os passos seguintes descrevem o que acontece como parte da confirmação:
- O cliente de armazenamento emite uma confirmação. A confirmação contém as mutações M1 a M5.
- As divisões 3 e 6 são os participantes nesta transação. Um dos participantes é escolhido como coordenador, como a divisão 3. A tarefa do coordenador é garantir que a transação é confirmada ou anulada atomicamente em todos os participantes.
- As réplicas principais destas divisões são responsáveis pelo trabalho realizado pelos participantes e coordenadores.
- Cada participante e coordenador executa um algoritmo Paxos com as respetivas réplicas.
- O líder executa um algoritmo Paxos com as réplicas. O quórum é alcançado se a maioria das réplicas responder com uma resposta
ok to commitao líder. - Em seguida, cada participante notifica o coordenador quando está preparado (primeira fase da confirmação de duas fases). Se qualquer participante não conseguir confirmar a transação, toda a transação
aborts.
- O líder executa um algoritmo Paxos com as réplicas. O quórum é alcançado se a maioria das réplicas responder com uma resposta
- Assim que o coordenador souber que todos os participantes, incluindo ele próprio, estão preparados, comunica o resultado da transação
accepta todos os participantes (segunda fase da confirmação de duas fases). Nesta fase, cada participante regista a decisão de confirmação no armazenamento estável e a transação é confirmada. - O coordenador responde ao cliente de armazenamento no Firestore que a transação foi confirmada. Em paralelo, o coordenador e todos os participantes aplicam as mutações aos dados.
Quando a base de dados do Firestore é pequena, pode acontecer que uma única divisão seja proprietária de todas as chaves nas mutações M1-M5. Nesse caso, existe apenas um participante na transação e a confirmação em duas fases mencionada anteriormente não é necessária, o que torna as escritas mais rápidas.
Escrita em várias regiões
Numa implementação em várias regiões, a distribuição de réplicas por várias regiões aumenta a disponibilidade, mas tem um custo de desempenho. A comunicação entre réplicas em diferentes regiões demora mais tempo de ida e volta. Por conseguinte, a latência de base para as operações do Firestore é ligeiramente superior em comparação com as implementações de região única.
Configuramos as réplicas de forma que a liderança das divisões permaneça sempre na região principal. A região principal é aquela a partir da qual o tráfego está a entrar no servidor do Firestore. Esta decisão de liderança reduz o atraso de ida e volta na comunicação entre o cliente de armazenamento no Firestore e o líder da réplica (ou o coordenador para transações com várias divisões).
Cada escrita no Firestore também envolve alguma interação com o motor em tempo real no Firestore. Para mais informações sobre as consultas em tempo real, consulte o artigo Compreenda as consultas em tempo real em grande escala.
Compreenda o ciclo de vida de uma leitura no Firestore
Esta secção aborda as leituras autónomas e não em tempo real no Firestore. Internamente, o servidor do Firestore processa a maioria destas consultas em duas fases principais:
- Uma única análise de intervalo na tabela Índices
- Consultas de pontos na tabela Documentos com base no resultado da digitalização anterior
As leituras de dados da camada de armazenamento são feitas internamente através de uma transação de base de dados para garantir leituras consistentes. No entanto, ao contrário das transações usadas para escritas, estas transações não usam bloqueios. Em alternativa, funcionam escolhendo uma indicação de tempo e, em seguida, executando todas as leituras nessa indicação de tempo. Como não adquirem bloqueios, não bloqueiam transações de leitura/escrita simultâneas. Para executar esta transação, o cliente de armazenamento no Firestore especifica um limite de data/hora, que indica à camada de armazenamento como escolher uma data/hora de leitura. O tipo de data/hora associada escolhido pelo cliente de armazenamento no Firestore é determinado pelas opções de leitura do pedido de leitura.
Compreenda uma transação de leitura na camada de armazenamento
Esta secção descreve os tipos de leituras e como são processadas na camada de armazenamento no Firestore.
Leituras fortes
Por predefinição, as leituras do Firestore são fortemente consistentes. Esta forte consistência significa que uma leitura do Firestore devolve a versão mais recente dos dados que reflete todas as escritas confirmadas até ao início da leitura.
Leitura de divisão única
O cliente de armazenamento no Firestore procura as divisões que detêm as chaves das linhas a serem lidas. Vamos supor que tem de fazer uma leitura a partir da divisão 3 da secção anterior. O cliente envia o pedido de leitura para a réplica mais próxima para reduzir a latência de ida e volta.
Neste momento, podem ocorrer os seguintes casos, consoante a réplica escolhida:
- O pedido de leitura é enviado para uma réplica principal (zona A).
- Como o líder está sempre atualizado, a leitura pode prosseguir diretamente.
- O pedido de leitura é enviado para uma réplica não principal (por exemplo, a zona B)
- A divisão 3 pode saber pelo respetivo estado interno que tem informações suficientes para publicar a leitura e a divisão fá-lo.
- O Split 3 não tem a certeza se viu os dados mais recentes. Envia uma mensagem ao líder para pedir a data/hora da última transação que tem de aplicar para publicar a leitura. Assim que essa transação for aplicada, a leitura pode prosseguir.
Em seguida, o Firestore devolve a resposta ao respetivo cliente.
Leitura com várias divisões
Na situação em que as leituras têm de ser feitas a partir de várias divisões, o mesmo mecanismo ocorre em todas as divisões. Assim que os dados forem devolvidos de todas as divisões, o cliente de armazenamento no Firestore combina os resultados. Em seguida, o Firestore responde ao respetivo cliente com estes dados.
Leituras desatualizadas
As leituras fortes são o modo predefinido no Firestore. No entanto, tem o custo de uma potencial latência mais elevada devido à comunicação que pode ser necessária com o líder. Muitas vezes, a sua aplicação do Firestore não precisa de ler a versão mais recente dos dados, e a funcionalidade funciona bem com dados que podem estar desatualizados há alguns segundos.
Nesse caso, o cliente pode optar por receber leituras desatualizadas através das opções de leitura read_time. Neste caso, as leituras são feitas como se os dados estivessem em read_time, e é muito provável que a réplica mais próxima já tenha verificado que tem dados no read_time especificado.
Para um desempenho visivelmente melhor, 15 segundos é um valor de desatualização razoável. Mesmo para leituras desatualizadas, as linhas geradas são consistentes entre si.
Evite pontos ativos
As divisões no Firestore são automaticamente divididas em partes mais pequenas para distribuir o trabalho de publicação de tráfego para mais servidores de armazenamento quando necessário ou quando o espaço de chaves se expande. As divisões criadas para processar o excesso de tráfego são mantidas durante cerca de 24 horas, mesmo que o tráfego desapareça. Assim, se existirem picos de tráfego recorrentes, as divisões são mantidas e são introduzidas mais divisões sempre que necessário. Estes mecanismos ajudam as bases de dados do Firestore a serem dimensionadas automaticamente sob uma carga de tráfego ou um tamanho da base de dados cada vez maior. No entanto, existem algumas limitações a ter em atenção, conforme explicado abaixo.
A divisão do armazenamento e do carregamento demora tempo, e o aumento do tráfego demasiado rápido pode causar uma latência elevada ou erros de limite de tempo excedido, normalmente denominados hotspots, enquanto o serviço se ajusta. A prática recomendada é distribuir as operações pelo intervalo de chaves, ao mesmo tempo que aumenta o tráfego numa recolha numa base de dados com 500 operações por segundo. Após este aumento gradual, aumente o tráfego até 50% a cada cinco minutos. Este processo é denominado regra 500/50/5 e posiciona a base de dados para ser dimensionada de forma ideal de modo a satisfazer a sua carga de trabalho.
Embora as divisões sejam criadas automaticamente com o aumento da carga, o Firestore só pode dividir um intervalo de chaves até estar a publicar um único documento através de um conjunto dedicado de servidores de armazenamento replicados. Como resultado, volumes elevados e contínuos de operações simultâneas num único documento podem levar a um ponto crítico nesse documento. Se encontrar latências elevadas persistentes num único documento, deve considerar modificar o seu modelo de dados para dividir ou replicar os dados em vários documentos.
Os erros de contenção ocorrem quando várias operações tentam ler e/ou escrever o mesmo documento em simultâneo.
Outro caso especial de hotspotting ocorre quando é usada uma chave que aumenta/diminui sequencialmente como o ID do documento no Firestore e existe um número consideravelmente elevado de operações por segundo. A criação de mais divisões não ajuda neste caso, uma vez que o aumento do tráfego passa simplesmente para a divisão recém-criada. Uma vez que o Firestore indexa automaticamente todos os campos no documento por predefinição, também podem ser criados pontos críticos móveis no espaço de índice para um campo de documento que contenha um valor que aumenta/diminui sequencialmente, como uma data/hora.
Tenha em atenção que, seguindo as práticas descritas acima, o Firestore pode ser dimensionado para publicar cargas de trabalho arbitrariamente grandes sem ter de ajustar nenhuma configuração.
Resolução de problemas
O Firestore oferece o Key Visualizer como uma ferramenta de diagnóstico concebida para analisar padrões de utilização e resolver problemas de hotspots.
O que se segue
- Leia mais sobre práticas recomendadas
- Saiba mais sobre as consultas em tempo real em grande escala