Memahami pembacaan dan penulisan dalam skala besar
Baca dokumen ini untuk membuat keputusan yang tepat dalam merancang aplikasi Anda demi menghasilkan performa dan keandalan yang tinggi. Dokumen ini berisi topik Firestore lanjutan. Jika Anda baru mulai menggunakan Firestore, lihat panduan memulai.
Firestore adalah database yang fleksibel dan skalabel untuk pengembangan perangkat seluler, web, dan server dari Firebase dan Google Cloud. Memulai penggunaan Firestore dan menulis aplikasi yang lengkap dan andal sangatlah mudah.
Agar aplikasi Anda terus menghadirkan performa yang baik seiring bertambahnya ukuran database dan traffic, sebaiknya pahami mekanisme pembacaan dan penulisan di backend Firestore. Anda juga harus memahami interaksi operasi baca dan tulis dengan lapisan penyimpanan dan batasan pokok yang dapat memengaruhi performa.
Lihat bagian berikut untuk mengetahui praktik terbaik sebelum merancang aplikasi.
Memahami komponen tingkat tinggi
Diagram berikut menunjukkan komponen tingkat tinggi yang terlibat dalam permintaan Firestore API.
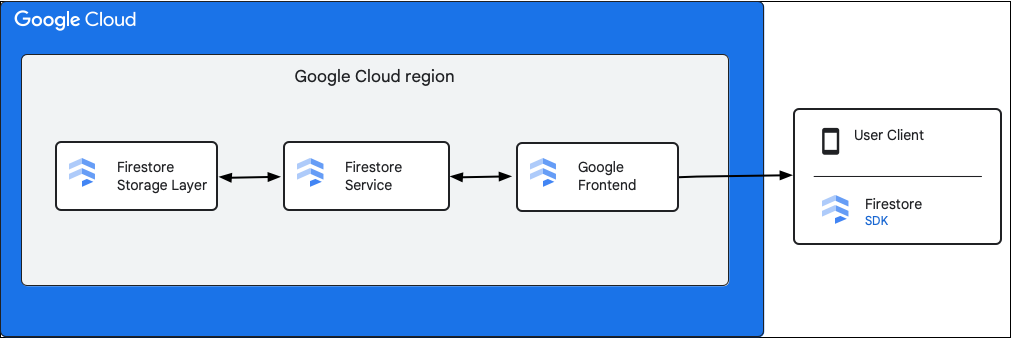
SDK dan library klien Firestore
Firestore mendukung SDK dan library klien untuk berbagai platform. Meskipun aplikasi dapat melakukan panggilan HTTP dan RPC langsung ke Firestore API, library klien menyediakan lapisan abstraksi untuk menyederhanakan penggunaan API dan menerapkan praktik terbaik. Elemen ini juga menyediakan fitur tambahan seperti akses offline, cache, dan sebagainya.
Google Front End (GFE)
Ini adalah layanan infrastruktur yang biasa digunakan oleh semua layanan Google cloud. GFE menerima permintaan masuk dan meneruskannya ke layanan Google yang relevan (layanan Firestore dalam konteks ini). Layanan ini juga menyediakan fungsionalitas penting lainnya, termasuk perlindungan terhadap serangan Denial of Service.
Layanan Firestore
Layanan Firestore melakukan pemeriksaan terhadap permintaan API yang mencakup autentikasi, otorisasi, pemeriksaan kuota, dan aturan keamanan. Layanan Firestore juga mengelola transaksi. Layanan Firestore ini mencakup klien penyimpanan yang berinteraksi dengan lapisan penyimpanan untuk pembacaan dan penulisan data.
Lapisan penyimpanan Firestore
Lapisan penyimpanan Firestore bertanggung jawab untuk menyimpan data dan metadata, serta fitur database terkait yang disediakan oleh Firestore. Bagian berikut menjelaskan cara penyusunan data di lapisan penyimpanan Firestore dan cara sistem dalam melakukan penskalaan. Mempelajari cara penyusunan data dapat membantu Anda mendesain model data yang skalabel dan lebih memahami praktik terbaik di Firestore.
Bagian dan Rentang Kunci
Firestore adalah database NoSQL berorientasi dokumen. Anda menyimpan data di dokumen, yang disusun dalam hierarki koleksi. Hierarki koleksi dan ID dokumen diterjemahkan menjadi satu kunci untuk setiap dokumen. Dokumen disimpan secara logis dan diurutkan secara leksikografis oleh satu kunci ini. Kami menggunakan istilah rentang kunci untuk merujuk pada rentang kunci yang berdekatan secara leksikografis.
Database Firestore biasa terlalu besar untuk dimuat di satu mesin fisik. Ada juga keadaan ketika workload pada data terlalu berat untuk ditangani oleh satu mesin. Untuk menangani workload yang besar, Firestore mempartisi data menjadi beberapa bagian terpisah yang dapat disimpan dan disalurkan dari beberapa mesin atau server penyimpanan. Partisi ini dibuat pada tabel database dalam blok rentang kunci yang disebut bagian.
Replikasi Sinkron
Penting untuk diperhatikan bahwa database selalu direplikasi secara otomatis dan sinkron. Bagian data memiliki replika di berbagai zona, sehingga data tetap tersedia meskipun suatu zona tidak dapat diakses. Replikasi yang konsisten ke berbagai salinan bagian dikelola oleh algoritma Paxos untuk konsensus. Satu replika dari setiap bagian dipilih untuk bertindak sebagai pemimpin Paxos yang bertanggung jawab untuk menangani penulisan ke bagian tersebut. Replikasi sinkron memberi Anda kemampuan untuk selalu dapat membaca data versi terbaru dari Firestore.
Proses replikasi ini bermuara pada sistem yang skalabel dan sangat tersedia, yang memberikan latensi rendah untuk operasi baca dan tulis, terlepas dari workload yang berat dan pada skala yang sangat besar.
Tata letak data
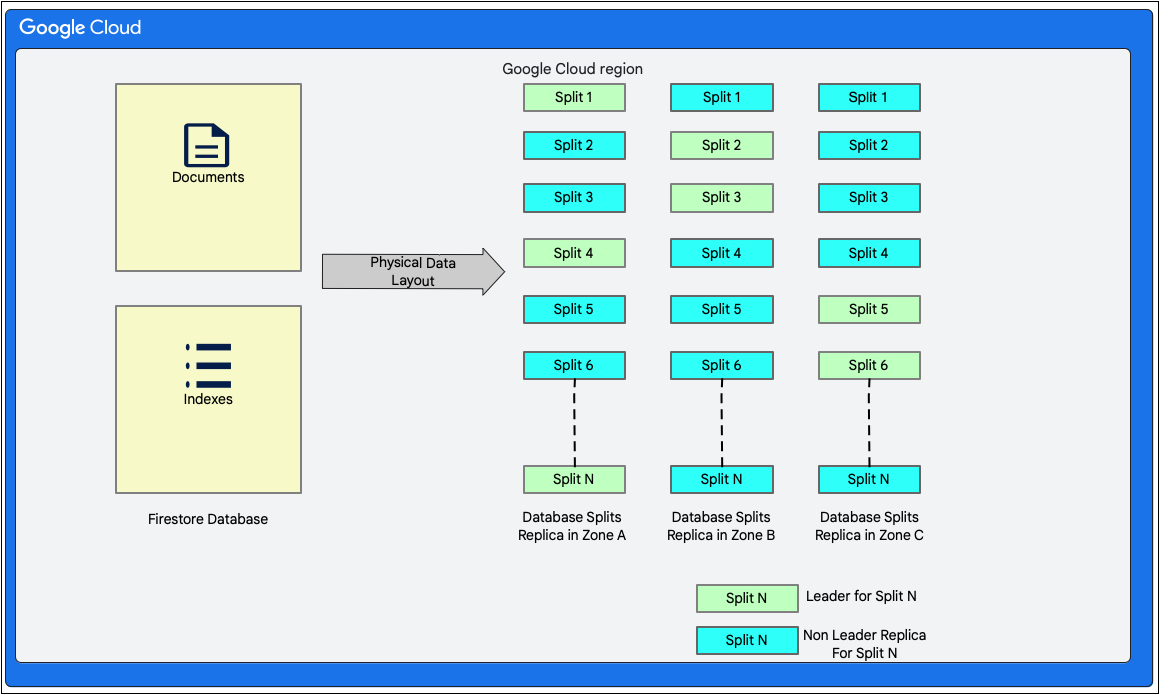
Firestore adalah database dokumen tanpa skema. Namun, Cloud Firestore secara internal menampilkan data dalam dua tabel bergaya database relasional di lapisan penyimpanannya sebagai berikut:
- Tabel Documents: Dokumen disimpan dalam tabel ini.
- Tabel Indexes: Entri indeks yang diurutkan berdasarkan nilai indeks disimpan dalam tabel ini. Dengan entri indeks, hasil dapat diperoleh secara efisien.
Diagram berikut menunjukkan tampilan tabel database Firestore dengan pembagian. Bagian direplikasi dalam tiga zona berbeda dan setiap bagian memiliki pemimpin Paxos yang sudah ditetapkan.
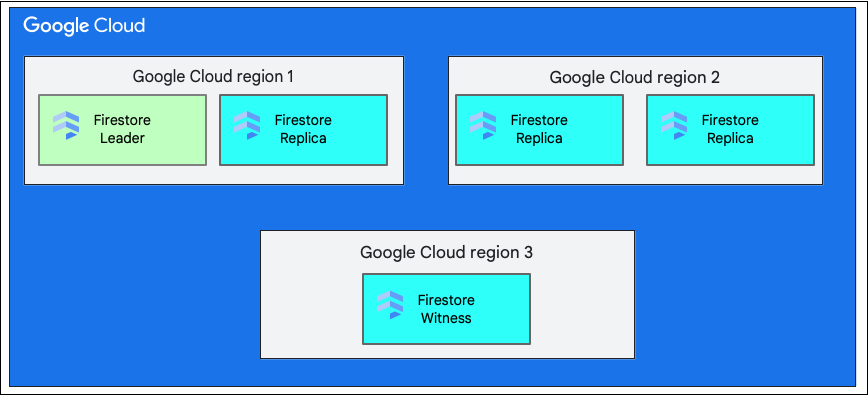
Region Tunggal versus Multi-Region
Saat membuat database, Anda harus memilih region atau multi-region.
Lokasi regional tunggal merupakan lokasi geografis tertentu, seperti us-west1. Bagian data dari database Firestore memiliki replika di berbagai zona dalam region yang dipilih, seperti yang dijelaskan sebelumnya.
Lokasi multi-region terdiri dari kumpulan region yang sudah ditentukan, tempat replika database disimpan. Dalam deployment Firestore multi-region, dua region memiliki replika lengkap dari seluruh data dalam database. Region ketiga memiliki replika saksi yang tidak mempertahankan kumpulan data lengkap, tetapi berpartisipasi dalam replikasi. Dengan mereplikasi data antara beberapa region, data akan tersedia untuk ditulis dan dibaca bahkan jika seluruh region hilang.
Untuk mengetahui informasi selengkapnya tentang lokasi region, lihat Lokasi Firestore.
Memahami masa berlaku penulisan di Firestore
Klien Firestore dapat menulis data dengan membuat, memperbarui, atau menghapus satu dokumen. Penulisan ke satu dokumen memerlukan pembaruan dokumen dan entri indeks terkait secara atomik di lapisan penyimpanan. Firestore juga mendukung operasi atomik yang terdiri dari beberapa pembacaan dan/atau penulisan pada satu atau beberapa dokumen.
Untuk semua jenis penulisan, Firestore menyediakan properti ACID (atomicity, konsistensi, isolasi, dan ketahanan) database relasional. Firestore juga menyediakan serialisasi, yang berarti semua transaksi muncul seolah-olah dijalankan dalam urutan serial.
Langkah-langkah tingkat tinggi dalam transaksi tulis
Saat klien Firestore menerbitkan operasi tulis atau meng-commit transaksi menggunakan salah satu metode yang disebutkan sebelumnya, hal ini dijalankan secara internal sebagai transaksi baca-tulis database di lapisan penyimpanan. Karena transaksi tersebut, Firestore dapat menyediakan properti ACID yang disebutkan sebelumnya.
Sebagai langkah pertama dalam transaksi, Firestore membaca dokumen yang sudah ada dan menentukan mutasi yang akan dilakukan pada data di tabel Documents.
Hal ini juga mencakup pembaruan yang diperlukan pada tabel Indexes sebagai berikut:
- Kolom yang ditambahkan ke dokumen memerlukan penyisipan yang sesuai di tabel Indexes.
- Kolom yang dihapus dari dokumen memerlukan penghapusan yang sesuai di tabel Indexes.
- Kolom yang diubah dalam dokumen memerlukan penghapusan (untuk nilai lama) dan penyisipan (untuk nilai baru) pada tabel Indexes.
Untuk menghitung mutasi yang disebutkan sebelumnya, Firestore membaca konfigurasi pengindeksan untuk project tersebut. Konfigurasi pengindeksan menyimpan informasi tentang indeks untuk sebuah project. Firestore menggunakan dua jenis indeks, yaitu kolom tunggal dan komposit. Untuk mendapatkan pemahaman yang mendetail tentang indeks yang dibuat di Firestore, lihat Jenis indeks di Firestore.
Setelah mutasi dihitung, Firestore mengumpulkannya di dalam transaksi, lalu melakukan commit terhadap mutasi tersebut.
Memahami transaksi tulis di lapisan penyimpanan
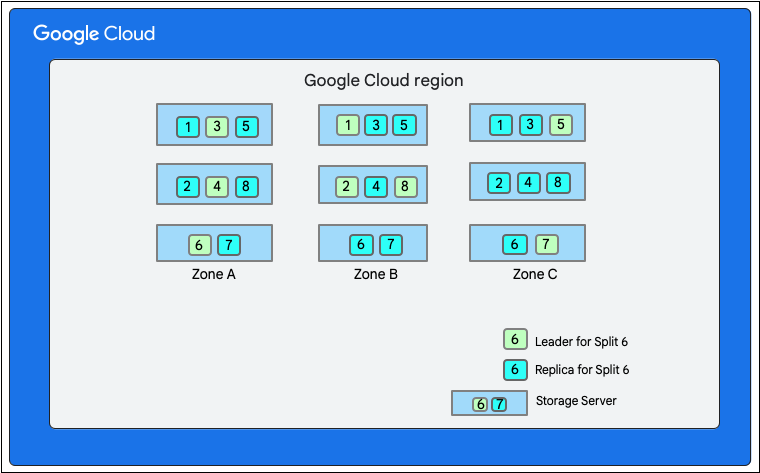
Seperti yang telah dibahas sebelumnya, operasi tulis di Firestore melibatkan transaksi baca-tulis di lapisan penyimpanan. Tergantung pada tata letak data, operasi tulis mungkin melibatkan satu atau beberapa bagian seperti yang terlihat di tata letak data.
Dalam diagram berikut, database Firestore memiliki delapan bagian (ditandai 1-8) yang dihosting di tiga server penyimpanan berbeda dalam satu zona, dan setiap bagian direplikasi di 3 zona(atau lebih) yang berbeda. Setiap bagian memiliki pimpinan Paxos, yang mungkin berada di zona berbeda untuk bagian yang berbeda pula.
Pertimbangkan database Firestore yang memiliki koleksi Restaurants sebagai berikut:
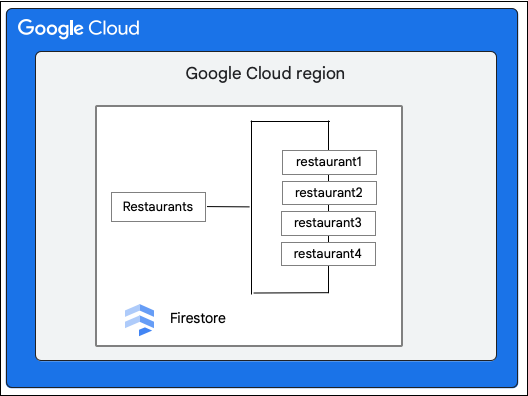
Klien Firestore meminta perubahan berikut pada dokumen dalam koleksi Restaurant dengan memperbarui nilai kolom priceCategory.
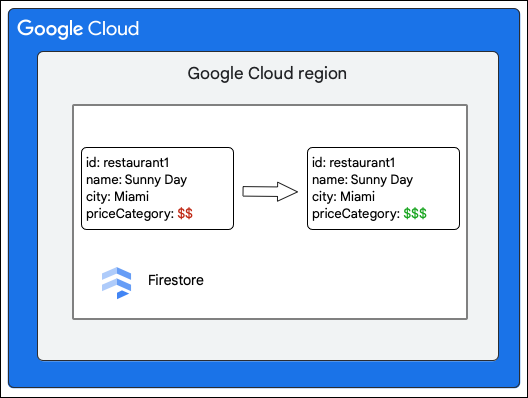
Sebagai bagian dari penulisan, langkah-langkah tingkat tinggi berikut menjelaskan hal yang terjadi:
- Membuat transaksi baca-tulis.
- Baca dokumen
restaurant1di koleksiRestaurantsdari tabel Documents dari lapisan penyimpanan. - Baca indeks untuk dokumen dari tabel Indexes.
- Hitung mutasi yang akan dibuat pada data. Dalam hal ini, ada lima mutasi:
- M1: Perbarui baris untuk
restaurant1di tabel Documents agar sesuai dengan perubahan nilai kolompriceCategory. - M2 dan M3: Hapus baris untuk nilai lama
priceCategorydi tabel Indexes untuk indeks menurun dan menaik. - M4 dan M5: Menyisipkan baris untuk nilai baru
priceCategorydi tabel Indexes untuk indeks menurun dan menaik.
- M1: Perbarui baris untuk
- Lakukan mutasi ini.
Klien penyimpanan di layanan Firestore mencari bagian yang memiliki kunci baris yang akan diubah. Mari kita perhatikan kasus saat Bagian 3 menyalurkan M1, dan Bagian 6 menyalurkan M2-M5. Ada transaksi terdistribusi yang melibatkan semua bagian ini sebagai peserta. Bagian peserta juga dapat menyertakan bagian lain dari data yang dibaca sebelumnya sebagai bagian dari transaksi baca-tulis.
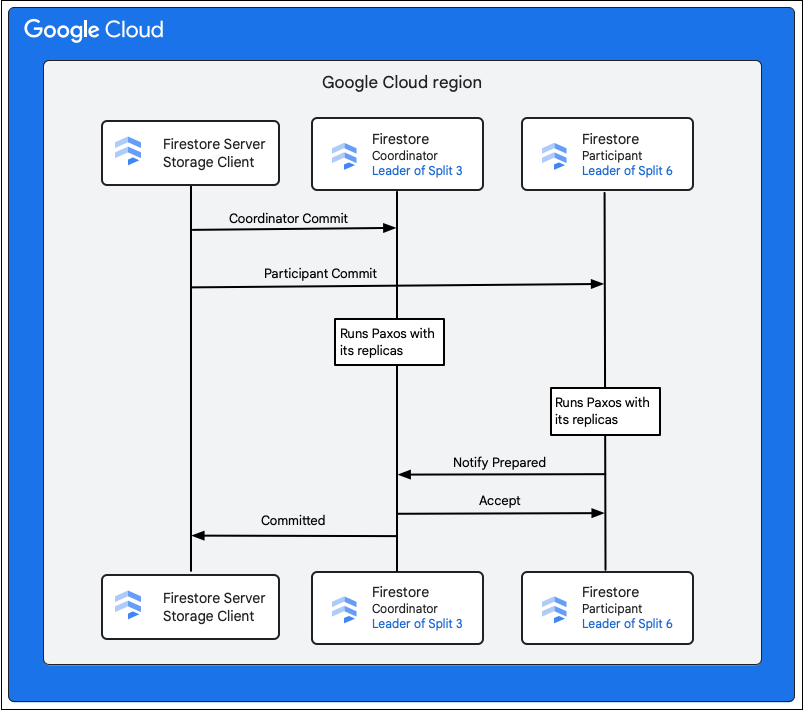
Sebagai bagian dari commit, langkah-langkah berikut menjelaskan hal yang terjadi:
- Klien penyimpanan menerbitkan commit. Commit berisi mutasi M1-M5.
- Bagian 3 dan 6 adalah peserta dalam transaksi ini. Salah satu peserta dipilih sebagai koordinator, seperti Bagian 3. Tugas koordinator adalah memastikan transaksi di-commit atau dibatalkan secara atomik pada semua peserta.
- Replika pemimpin dari bagian ini bertanggung jawab atas pekerjaan yang dilakukan oleh peserta dan koordinator.
- Setiap peserta dan koordinator menjalankan algoritma Paxos dengan replika masing-masing.
- Pemimpin tersebut menjalankan algoritma Paxos dengan replika. Kuorum dicapai jika sebagian besar replika membalas pemimpin dengan respons
ok to commit. - Setiap peserta kemudian akan memberi tahu koordinator saat mereka siap (fase pertama dari commit dengan dua fase). Jika setiap peserta tidak dapat meng-commit transaksi, maka seluruh transaksi
aborts.
- Pemimpin tersebut menjalankan algoritma Paxos dengan replika. Kuorum dicapai jika sebagian besar replika membalas pemimpin dengan respons
- Setelah koordinator mengetahui semua peserta sudah siap, termasuk dirinya sendiri, mereka akan mengomunikasikan hasil transaksi
acceptkepada semua peserta (fase kedua dari commit dengan dua fase). Pada fase ini, setiap peserta mencatat keputusan commit ke penyimpanan yang stabil dan transaksi di-commit. - Koordinator merespons klien penyimpanan di Firestore bahwa transaksi telah di-commit. Secara paralel, koordinator dan semua peserta menerapkan mutasi ke data.
Jika database Firestore berukuran kecil, satu bagian dapat memiliki semua kunci dalam mutasi M1-M5. Dalam kasus seperti itu, hanya ada satu peserta dalam transaksi. Selain itu, commit dengan dua fase yang disebutkan sebelumnya tidak diperlukan, sehingga penulisan menjadi lebih cepat.
Penulisan di multi-region
Dalam deployment multi-region, penyebaran replika di seluruh region meningkatkan ketersediaan, tetapi berdampak pada performa. Komunikasi antara replika di berbagai region memerlukan waktu round-trip yang lebih lama. Oleh karena itu, latensi dasar untuk operasi Firestore sedikit lebih banyak dibandingkan dengan deployment region tunggal.
Kami mengonfigurasi replika sedemikian rupa agar pemimpin bagian selalu berada di region utama. Region utama adalah region tempat traffic masuk ke server Firestore. Keputusan kepemimpinan ini mengurangi penundaan dua arah dalam komunikasi antara klien penyimpanan di Firestore dan pemimpin replika (atau koordinator untuk transaksi multi-bagian).
Setiap penulisan di Firestore juga melibatkan beberapa interaksi dengan mesin real-time di Firestore. Untuk mengetahui informasi selengkapnya tentang kueri real-time, lihat bagian Memahami kueri real-time dalam skala besar.
Memahami masa berlaku pembacaan di Firestore
Bagian ini berfokus pada pembacaan non-realtime dan mandiri di Firestore. Secara internal, server Firestore menangani sebagian besar kueri ini dalam dua tahap utama:
- Pemindaian rentang tunggal pada tabel Indexes
- Pencarian titik di tabel Documents berdasarkan hasil pemindaian sebelumnya
Pembacaan data dari lapisan penyimpanan dilakukan secara internal dengan menggunakan transaksi database untuk memastikan pembacaan yang konsisten. Namun, tidak seperti transaksi yang digunakan untuk penulisan, transaksi ini tidak dikunci. Sebagai gantinya, opsi tersebut bekerja dengan memilih stempel waktu, lalu menjalankan semua operasi baca pada stempel waktu tersebut. Karena tidak memperoleh kunci, transaksi tersebut tidak memblokir transaksi baca-tulis serentak. Untuk menjalankan transaksi ini, klien penyimpanan di Firestore menentukan batas stempel waktu, yang memberi tahu lapisan penyimpanan cara memilih stempel waktu pembacaan. Jenis stempel waktu yang dipilih oleh klien penyimpanan di Firestore ditentukan oleh opsi baca untuk permintaan Read.
Memahami transaksi baca di lapisan penyimpanan
Bagian ini menjelaskan jenis pembacaan dan cara pemrosesannya di lapisan penyimpanan di Firestore.
Pembacaan andal
Secara default, pembacaan Firestore sangat konsisten. Konsistensi kuat ini berarti bahwa pembacaan Firestore menampilkan versi terbaru data yang mencerminkan semua penulisan yang telah di-commit hingga awal pembacaan.
Pembacaan Bagian Tunggal
Klien penyimpanan di Firestore mencari bagian yang memiliki kunci baris yang akan dibaca. Anggaplah Anda perlu membaca dari Bagian 3 dari bagian sebelumnya. Klien mengirimkan permintaan baca ke replika terdekat untuk mengurangi latensi dua arah.
Pada tahap ini, kasus berikut mungkin terjadi bergantung pada replika yang dipilih:
- Permintaan baca ditujukan ke replika pemimpin (Zona A).
- Karena pemimpin selalu diperbarui, pembacaan dapat langsung dilanjutkan.
- Permintaan baca ditujukan ke replika non-pemimpin (seperti Zona B)
- Bagian 3 mungkin tahu dari status internalnya bahwa variabel tersebut memiliki informasi yang cukup untuk menyajikan operasi baca, dan bagian tersebut pun melakukannya.
- Bagian 3 tidak yakin apakah sudah melihat data terbaru atau belum. Fungsi ini mengirim pesan ke pemimpin untuk meminta stempel waktu transaksi terakhir yang perlu diterapkan untuk melayani pembacaan. Setelah transaksi tersebut diterapkan, pembacaan dapat dilanjutkan.
Firestore kemudian menampilkan respons ke kliennya.
Pembacaan multi-bagian
Jika operasi baca harus dilakukan dari beberapa bagian, mekanisme yang sama akan diterapkan pada semua bagian. Setelah data ditampilkan dari semua bagian, klien penyimpanan di Firestore akan menggabungkan hasilnya. Firestore kemudian merespons kliennya dengan data ini.
Pembacaan yang sudah tidak berlaku
Operasi baca yang andal adalah mode default di Firestore. Namun, hal ini mungkin memiliki potensi latensi yang lebih tinggi karena komunikasi yang mungkin diperlukan dengan pemimpin. Sering kali aplikasi Firestore Anda tidak perlu membaca data versi terbaru dan fungsinya bekerja dengan baik dengan data yang mungkin baru beberapa detik tidak berlaku.
Dalam kasus semacam itu, klien dapat memilih untuk menerima pembacaan yang sudah tidak berlaku dengan menggunakan opsi baca read_time. Dalam hal ini, pembacaan dilakukan karena data berada di read_time, dan replika terdekat kemungkinan besar telah memverifikasi bahwa data tersebut memiliki data di read_time yang ditentukan.
Untuk performa yang jauh lebih baik, 15 detik adalah nilai tidak berlaku yang wajar. Bahkan untuk pembacaan yang sudah tidak berlaku, baris yang dihasilkan bersifat konsisten satu sama lain.
Menghindari hotspot
Bagian di Firestore secara otomatis dipecah menjadi bagian-bagian yang lebih kecil untuk mendistribusikan tugas penayangan traffic ke lebih banyak server penyimpanan saat diperlukan atau ketika ruang kunci diperluas. Bagian yang dibuat untuk menangani kelebihan traffic akan dipertahankan selama sekitar ~24 jam meskipun traffic hilang. Jadi, jika ada lonjakan traffic berulang, bagian tersebut akan dipertahankan, sementara bagian lainnya akan dilakukan setiap kali diperlukan. Mekanisme ini membantu database Firestore melakukan penskalaan otomatis pada peningkatan beban traffic atau ukuran database. Namun, ada beberapa batasan yang perlu diketahui, seperti dijelaskan di bawah ini.
Membagi penyimpanan dan beban membutuhkan waktu, dan meningkatkan traffic terlalu cepat dapat menyebabkan error yang melebihi batas atau latensi tinggi, biasanya disebut sebagai hotspot, sembari layanan disesuaikan. Praktik terbaiknya adalah mendistribusikan operasi di seluruh rentang kunci, sambil meningkatkan traffic pada koleksi dalam database dengan 500 operasi per detik. Setelah penambahan bertahap ini, tingkatkan traffic hingga 50% setiap lima menit. Proses ini disebut aturan 500/50/5 dan memosisikan database untuk diskalakan secara optimal guna memenuhi beban kerja Anda.
Meskipun bagian dibuat secara otomatis dengan bertambahnya beban, Firestore dapat membagi rentang kunci hanya sampai menyajikan satu dokumen menggunakan kumpulan server penyimpanan replika khusus. Akibatnya, volume operasi serentak yang tinggi dan berkelanjutan pada satu dokumen dapat menyebabkan hotspot pada dokumen tersebut. Jika Anda mendapati latensi tinggi yang berkelanjutan pada satu dokumen, sebaiknya ubah model data untuk membagi atau mereplikasi data di beberapa dokumen.
Error pertentangan terjadi saat beberapa operasi mencoba membaca dan/atau menulis dokumen yang sama secara bersamaan.
Kasus khusus hotspotting lainnya terjadi ketika kunci yang meningkat/turun secara berurutan digunakan sebagai ID dokumen di Firestore, dan ada banyak sekali operasi per detik. Membuat lebih banyak bagian tidak memecahkan masalah karena lonjakan traffic akan langsung berpindah ke bagian yang baru dibuat. Karena Firestore secara otomatis mengindeks semua kolom dalam dokumen secara default, hotspot bergerak tersebut juga dapat dibuat di ruang indeks untuk kolom dokumen yang berisi nilai yang meningkat/turun secara berurutan seperti stempel waktu.
Perhatikan bahwa dengan mengikuti praktik yang diuraikan di atas, Firestore dapat diskalakan untuk melayani beban kerja besar yang berubah-ubah tanpa harus menyesuaikan konfigurasi.
Pemecahan masalah
Firestore menyediakan Key Visualizer sebagai alat diagnostik yang dirancang untuk menganalisis pola penggunaan dan memecahkan masalah hotspotting.
Langkah Berikutnya
- Baca praktik terbaik lainnya
- Pelajari kueri real-time dalam skala besar