了解 Firestore 中的性能监控
Cloud Monitoring 会从 Google Cloud 产品中收集指标、事件和元数据。您还可以通过 Cloud Monitoring 访问“使用情况”信息中心和安全规则使用情况中报告的数据,以便进行更详细的分析。 借助 Cloud Monitoring,您还可以设置自定义信息中心和用量提醒。
本文档将引导您了解如何使用指标、自定义指标信息中心以及设置提醒。
受监控的资源
Cloud Monitoring 中受监控的资源表示虚拟机、数据库或应用等逻辑实体或物理实体。受监控的资源包含一组独特的指标,可通过信息中心进行探索、报告或用于创建提醒。此外,每个资源还具有一组资源标签,这些标签是键值对,包含有关资源的其他信息。资源标签适用于与资源关联的所有指标。
使用 Cloud Monitoring API,可通过以下资源监控 Firestore 性能:
| 资源 | 说明 | 支持的数据库模式 |
firestore.googleapis.com/Database(推荐) | 提供 project、location* 和 database_id 细分的受监控的资源类型。对于未指定名称而创建的数据库,database_id 标签将为 (default)。 |
适用于两种模式。 |
firestore_instance | 适用于 Firestore 项目的受监控资源类型,不提供数据库细分数据。 | 适用于 Firestore 原生模式 |
datastore_request | Datastore 项目的受监控资源类型,不提供数据库细分数据。 | 适用于两种模式。 |
指标
Firestore 有两种不同的模式:原生模式 Firestore 和 Datastore 模式 Firestore。如需查看这两种模式之间的功能比较,请参阅选择数据库模式。
如需查看这两种模式的完整指标列表,请参阅以下链接:
服务运行时指标
serviceruntime指标可让您大致了解项目的流量。这些指标适用于大多数 Google Cloud API。consumed_api 受监控的资源类型包含以下常见指标。这些指标每 30 分钟采样一次,因此数据会变得平滑。
对于 serviceruntime 指标,一个重要的资源标签是 method。此标签表示所调用的底层 RPC 方法。您调用的 SDK 方法可能不一定与底层 RPC 方法同名。原因是 SDK 提供高级 API 抽象。不过,在尝试了解应用如何与 Firestore 互动时,务必要了解基于 RPC 方法名称的指标。
如果您需要了解给定 SDK 方法的底层 RPC 方法,请参阅 API 文档。
您可以使用以下服务运行时指标来监控数据库。
api/request_count
此指标提供已完成请求的计数,按协议(请求协议,例如 HTTP、gRPC 等)、响应代码(HTTP 响应代码)、response_code_class(响应代码类,例如 2xx、4xx 等)和 grpc_status_code(数字 gRPC 响应代码)进行细分。使用此指标可观察总体 API 请求并计算错误率。
在图 1 中,您可以看到按服务和方法分组的返回 2xx 代码的请求。2xx 代码是 HTTP 状态代码,表示请求成功。
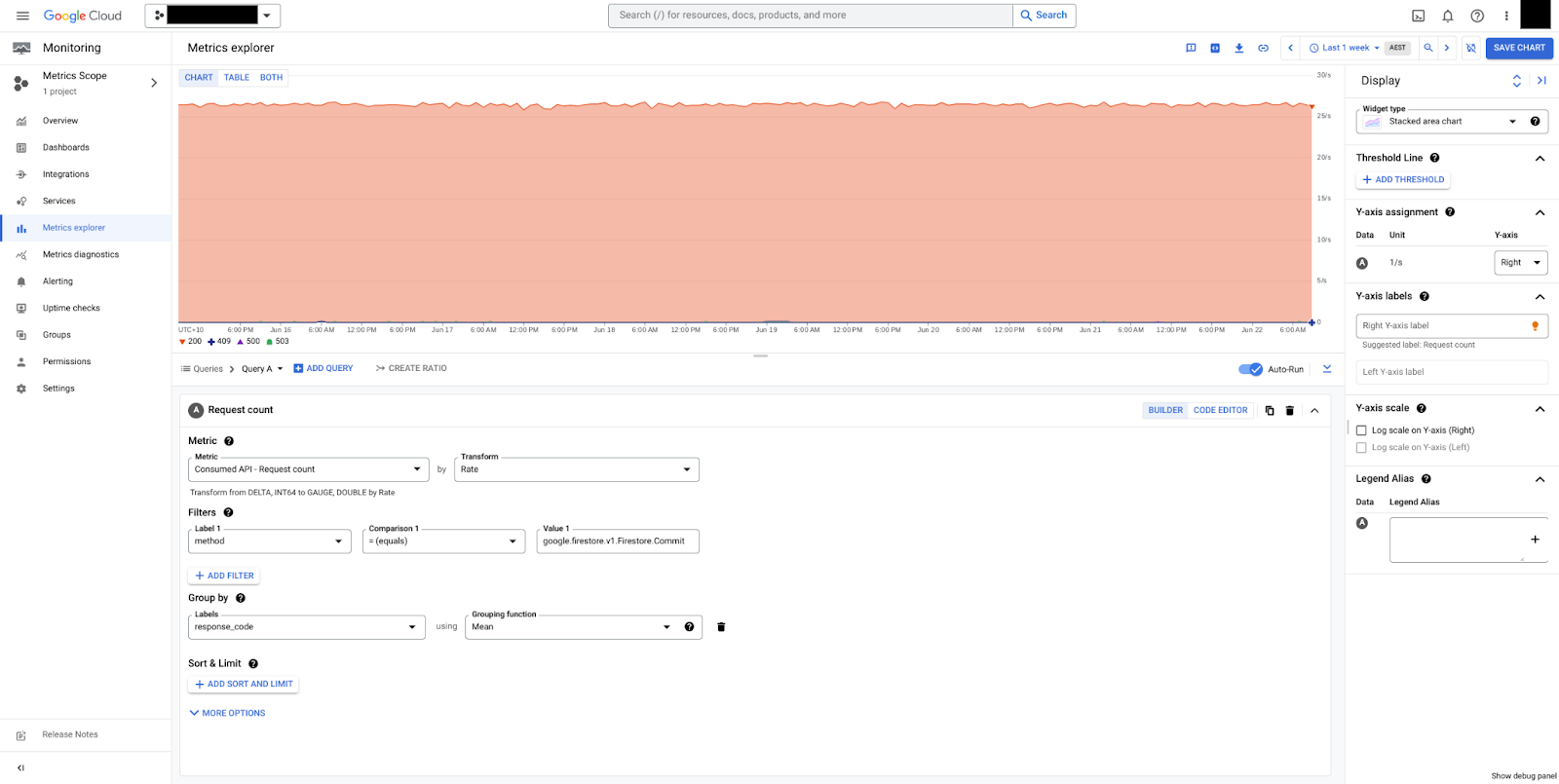
在图 2 中,您可以看到按 response_code 分组的提交。在此示例中,我们只看到 HTTP 200 响应,这意味着数据库运行状况良好。
api/request_latencies
api/request_latencies 指标提供所有已完成请求的延迟时间分布。
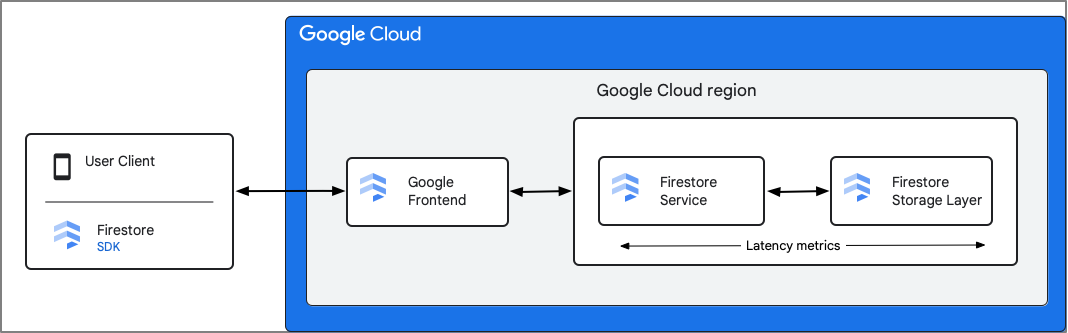
Firestore 会记录来自 Firestore 服务组件的指标。延迟时间指标包括从 Firestore 收到请求到 Firestore 完成发送响应的时间,包括与存储层的互动。因此,这些指标不包括客户端与 Firestore 服务之间的往返延迟时间 (rtt)。
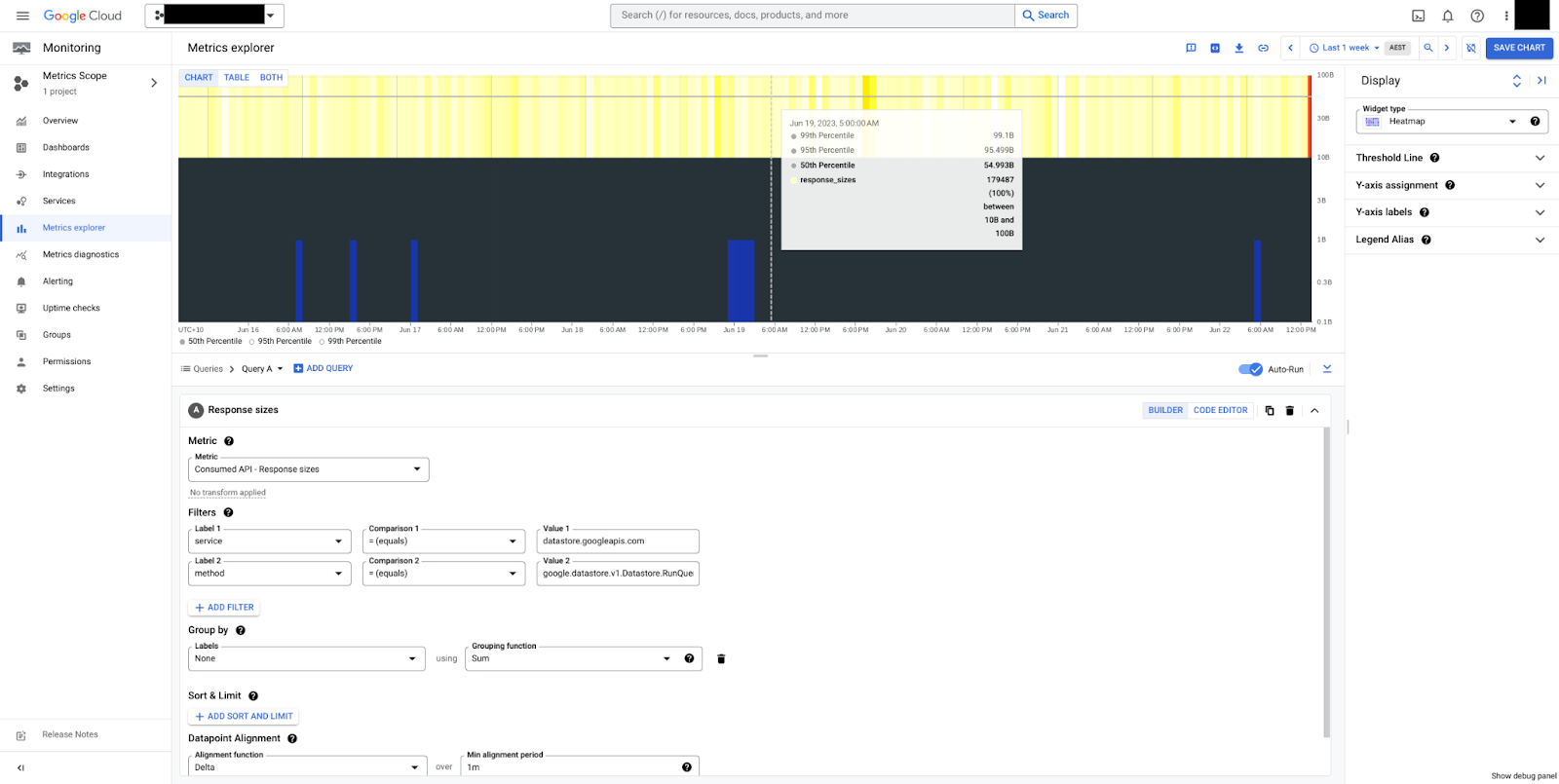
api/request_sizes 和 api/response_sizes
api/request_sizes 和 api/response_sizes 指标分别提供有关载荷大小(以字节为单位)的分析洞见。这些指标有助于了解发送大量数据的写入工作负载或范围过广且返回大型载荷的查询。
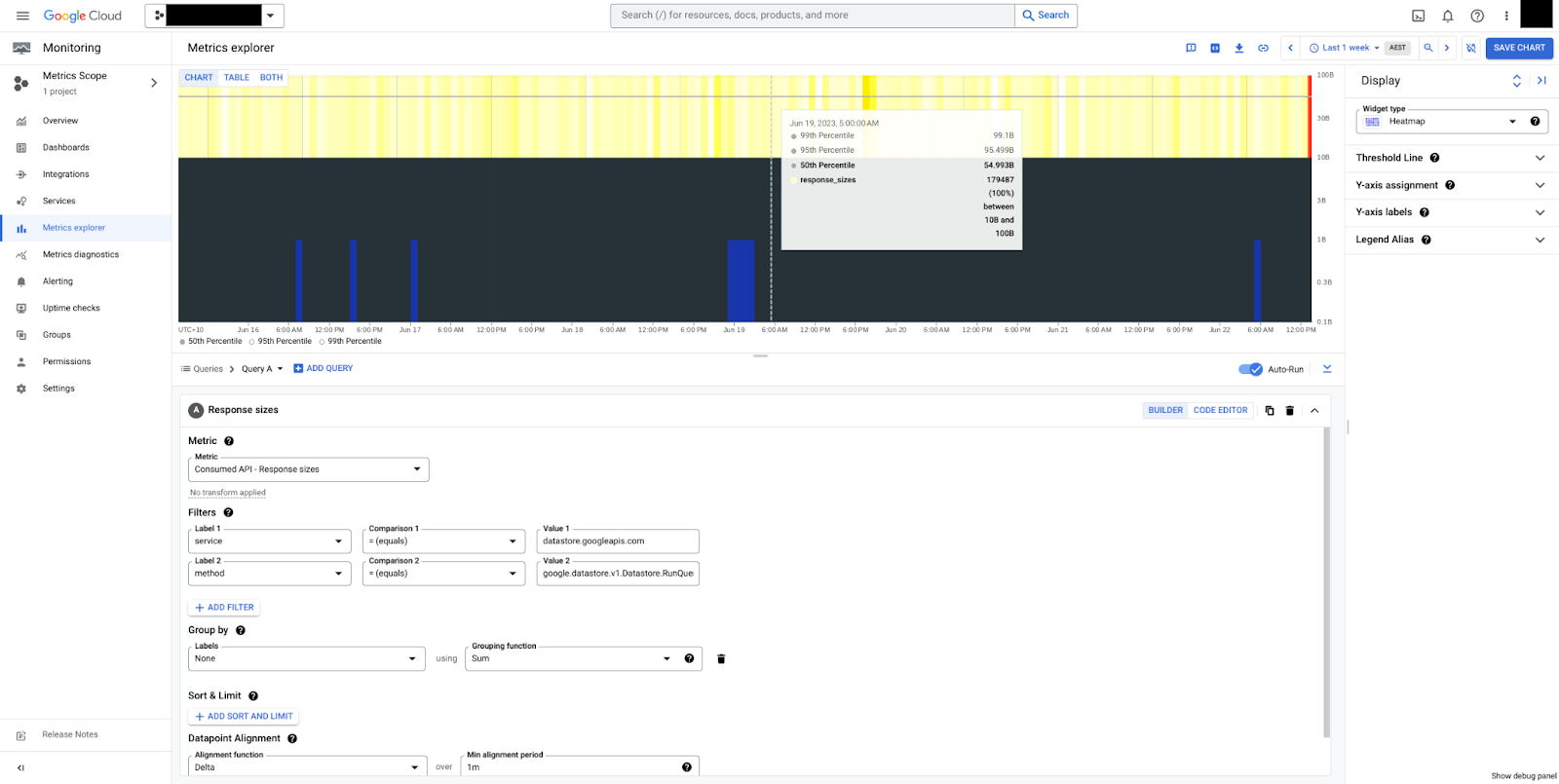
在图 5 中,您可以看到 RunQuery 方法的响应大小的热图。我们可以看到,大小稳定,中位数为 50 字节,总体介于 10 字节和 100 字节之间。请注意,载荷大小始终以未压缩的字节数来衡量,不包括传输控制开销。
文档操作指标
Firestore 会提供读取、写入和删除次数。写入指标可细分“CREATE”和“UPDATE”操作。这些指标与 CRUD 操作相对应。
您可以使用以下指标来了解数据库是读取密集型还是写入密集型,以及新文档与已删除文档的比率。
document/delete_ops_count:成功删除文档的次数。document/read_ops_count:通过查询或查找成功读取的文档数量。document/write_ops_count:成功写入文档的次数。
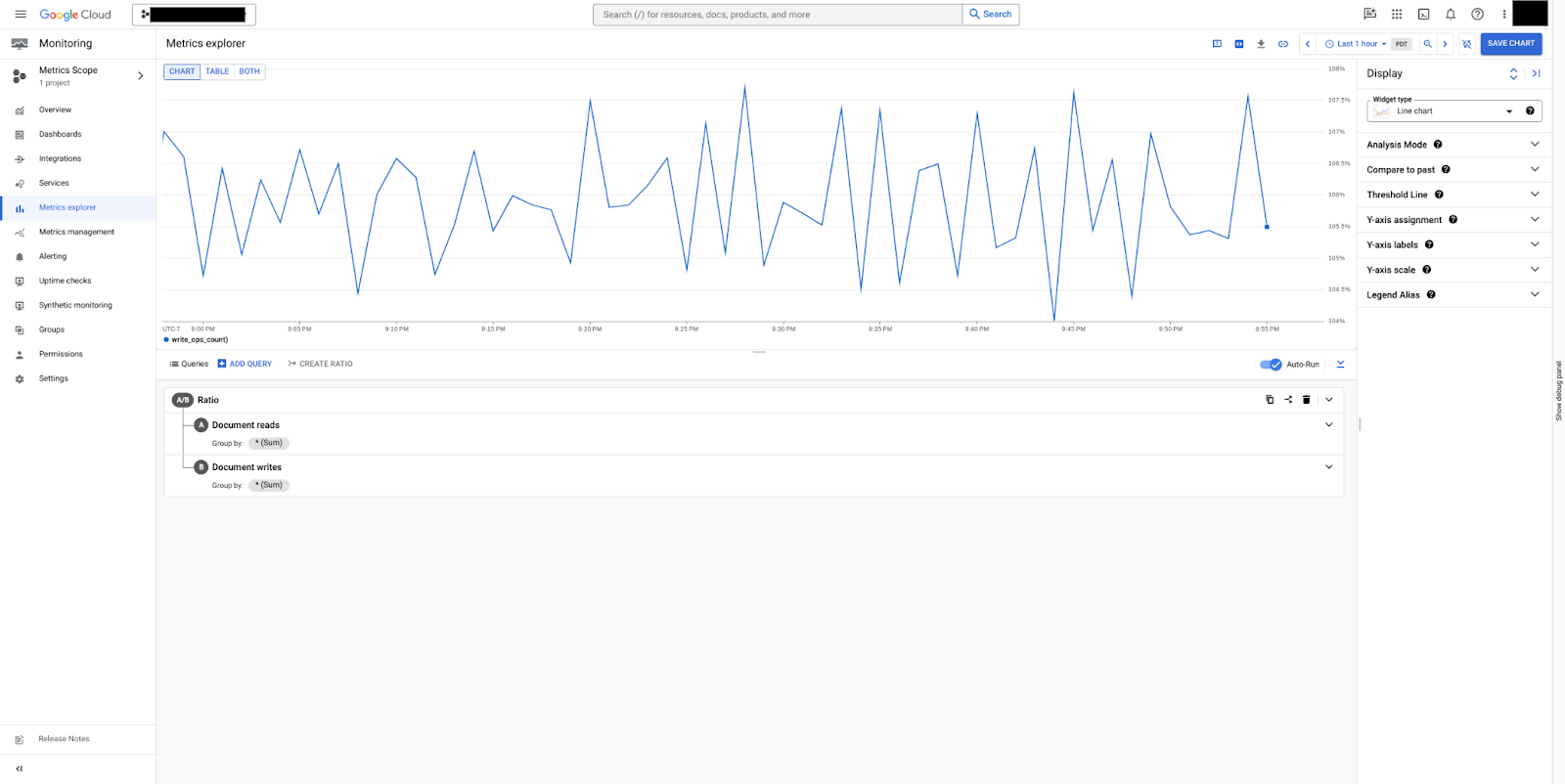
在图 6 中,您可以看到如何创建显示读取的文档与写入的文档之比的比率。在本例中,读取的文档数量比写入的文档数量多约 6%。
文档操作指标
这些指标以字节为单位提供对 Firestore 数据库的读取(查找和查询)和写入操作的载荷大小分布。这些值表示载荷的总大小。例如,查询返回的任何结果。
这些指标与 api/request_sizes 和 api/response_sizes 指标类似,主要区别在于文档操作指标可提供更精细的抽样,但细分程度较低。
例如,文档操作指标使用 datastore_request 受监控的资源,因此没有服务或方法细分。
entity/read_sizes:读取的文档的大小分布。entity/write_sizes:已撰写文档的大小分布。
指数指标
可以将索引写入速率与 document/write_ops_count 指标进行对比,以了解 索引扇出比。
index/write_count:索引写入次数。
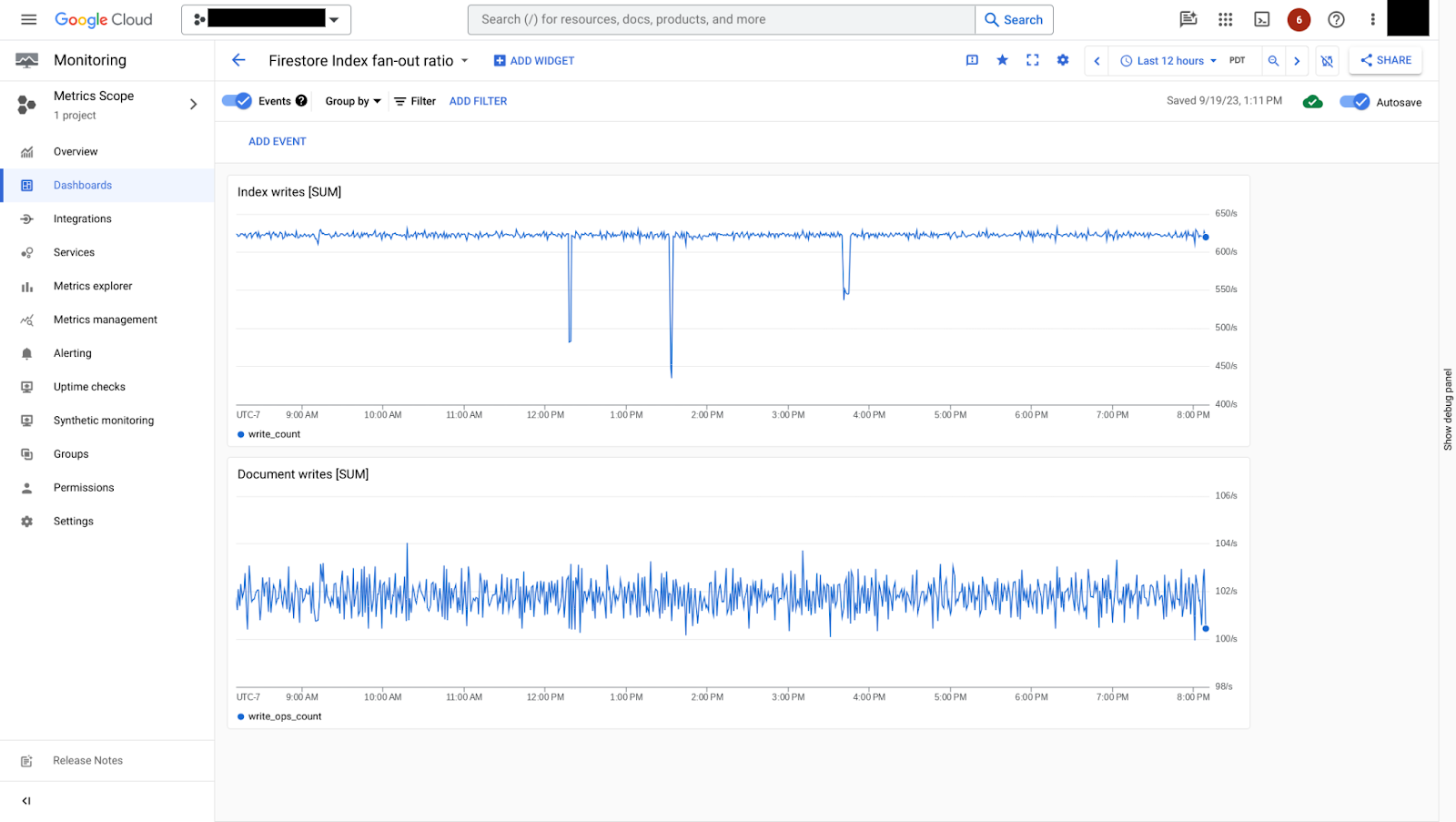
在图 7 中,您可以看到索引写入速率与文档写入速率的对比情况。在此示例中,每次写入文档时,大约会写入 6 个索引,这是一个相对较小的索引扇出率。
使用 Firebase SDK 直接连接到数据库的客户端
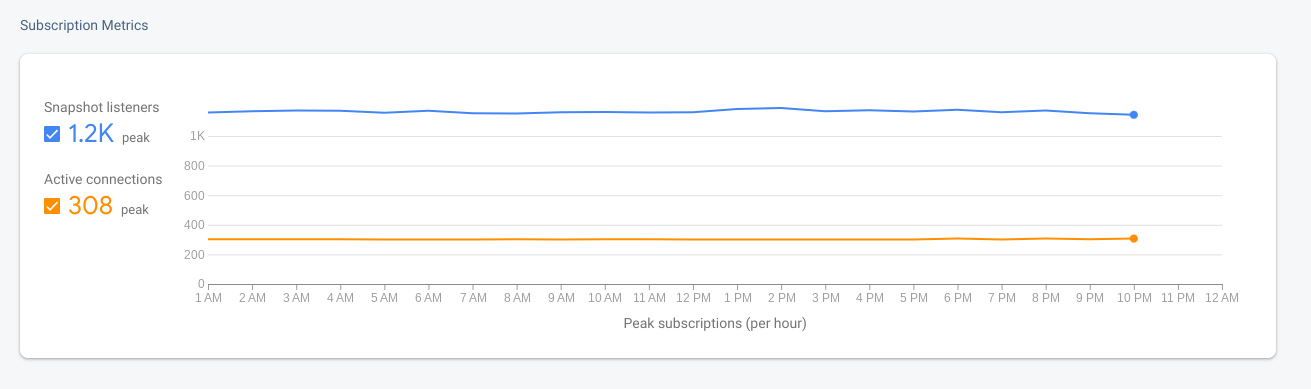
您可以使用两个指标来跟踪通过移动 SDK、Web SDK 或两者直接连接到 Firestore 数据库的客户端的活动。这些指标包含与实时快照监听器相关的功能,其中数据库中的相关更改会立即流式传输回客户端。
network/active_connections:相应时间点的活跃连接数。每个 Web 或移动客户端都有一个连接。network/snapshot_listeners:当前在所有已连接的客户端中注册的快照监听器数量。每个客户端可能有多个连接。
您可以在 Firebase 控制台中 Firestore 数据库的 Usage 标签页中查看这些指标。
TTL 指标
TTL 指标适用于 Firestore 原生数据库和 Datastore 模式的 Firestore 数据库。您可以使用这些指标来监控强制执行的 TTL 政策的效果。
document/ttl_deletion_count:由 TTL 服务删除的文档总数。
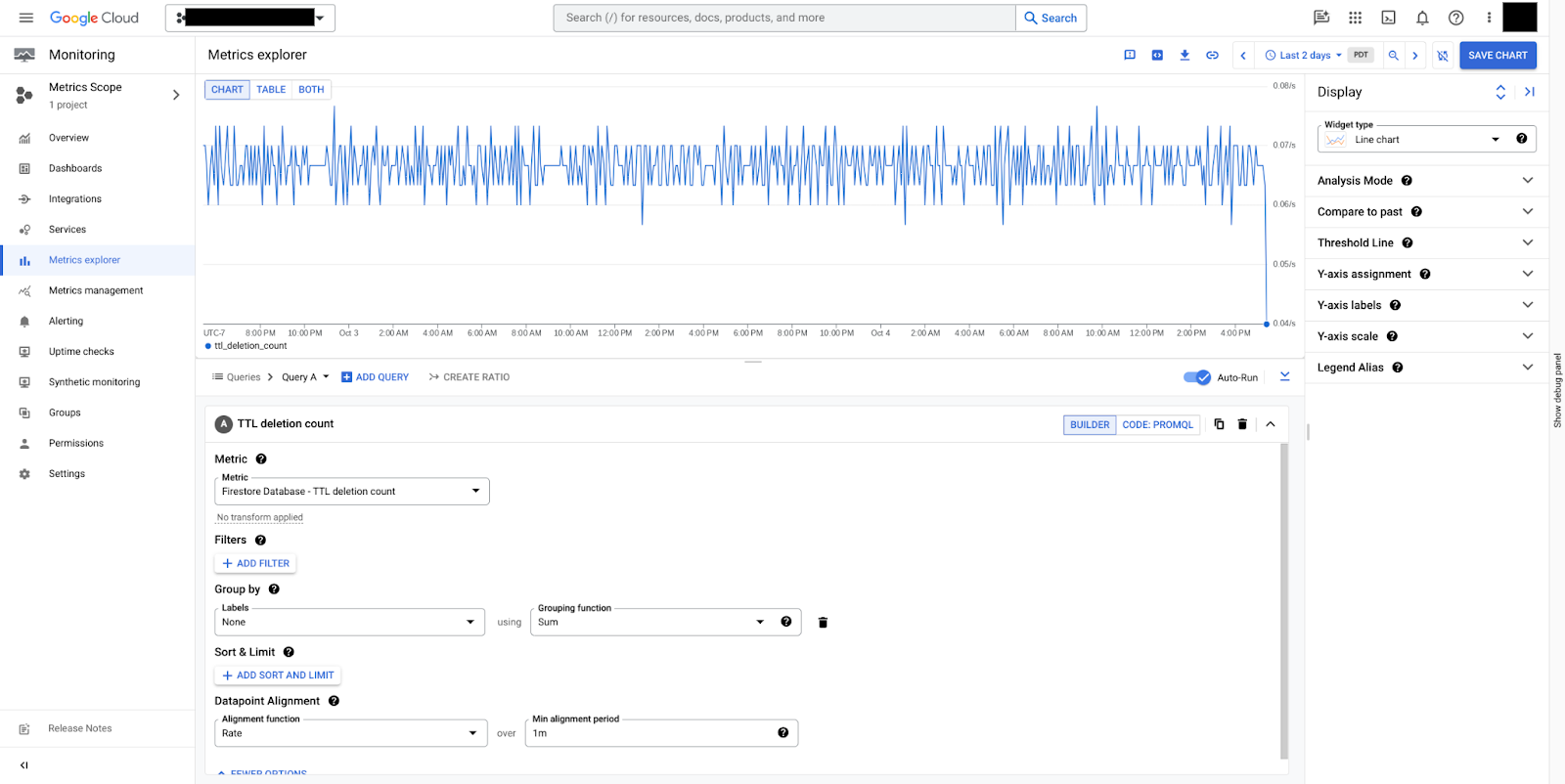
在图 9 中,您可以看到在一段时间内每分钟删除的文档数量。
document/ttl_expiration_to_deletion_delays:具有 TTL 的文档从到期到实际删除之间的间隔时间。
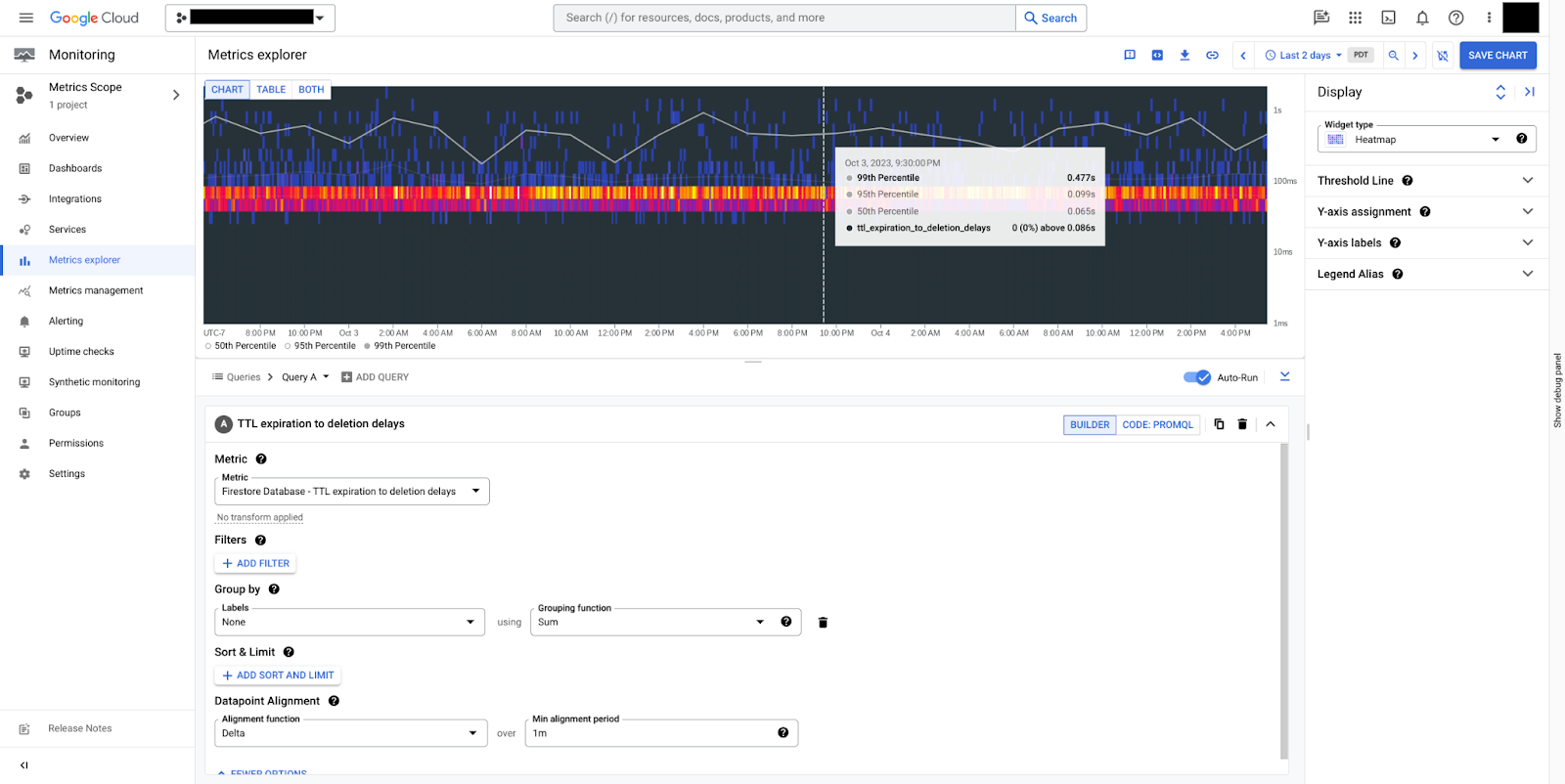
在图 10 中,您可以看到此指标提供了 Firestore 删除具有 TTL 政策的文档所用时间的分布情况(以秒为单位)。在第 99 百分位,删除 TTL 过期文档所需的时间不到 0.5 秒。这表示系统运行正常。Firestore 通常会在 24 小时内删除过期文档,但不能保证一定会删除。 如果发现处理时间超过 24 小时,请与支持团队联系。
后续步骤
- 了解如何使用 Cloud Monitoring 信息中心查看指标。
- 监控用量,以了解一段时间内的文档读取、写入和删除情况。