이 페이지에서는 민감한 데이터 검색 서비스를 설명합니다. 이 서비스를 사용하면 조직에서 민감하고 위험성이 높은 데이터가 어디에 있는지 확인할 수 있습니다.
개요
검색 서비스를 사용하면 민감하고 위험성이 높은 데이터가 어디에 있는지 확인하여 조직 전체의 데이터를 보호할 수 있습니다. 검색 스캔 구성을 만들 때 Sensitive Data Protection은 리소스를 스캔하여 프로파일링 범위 내의 데이터를 식별합니다. 그런 다음 데이터 프로필을 생성합니다. 검색 구성이 활성화 상태이면 Sensitive Data Protection은 추가 및 수정하는 데이터를 자동으로 프로파일링합니다. 전체 조직, 개별 폴더, 개별 프로젝트에서 데이터 프로필을 생성할 수 있습니다.
각 데이터 프로필은 검색 서비스가 지원되는 리소스를 스캔하여 수집하는 통계 및 메타데이터 집합입니다. 통계에는 예측된 infoTypes과 데이터의 계산된 데이터 위험 및 민감도 수준이 포함됩니다. 이러한 통계를 사용하여 데이터의 보호, 공유, 사용 방식에 대해 정보에 입각한 결정을 내릴 수 있습니다.
데이터 프로필은 다양한 세부 수준에서 생성됩니다. 예를 들어 BigQuery 데이터를 프로파일링하면 프로젝트, 테이블, 열 수준에서 프로필이 생성됩니다.
다음 이미지는 열 수준 데이터 프로필 목록을 보여줍니다. 이미지를 클릭하여 확대합니다.

각 데이터 프로필에 포함된 통계 및 메타데이터 목록은 측정항목 참조를 확인하세요.
Google Cloud 리소스 계층 구조에 대한 자세한 내용은 리소스 계층 구조를 참고하세요.
데이터 프로필 생성
데이터 프로필을 생성하려면 검색 스캔 구성(데이터 프로필 구성이라고도 함)을 만듭니다. 이 스캔 구성에서는 탐색 작업의 범위와 프로파일링할 데이터 유형을 설정합니다. 스캔 구성에서 프로파일링하거나 건너뛸 데이터의 하위 집합을 지정하는 필터를 설정할 수 있습니다. 프로파일링 일정을 설정할 수도 있습니다.
스캔 구성을 만들 때 사용할 검사 템플릿도 설정합니다. 검사 템플릿에서는 Sensitive Data Protection에서 스캔해야 하는 민감한 정보 유형(infoType이라고도 함)을 지정합니다.
Sensitive Data Protection은 데이터 프로필을 만들 때 스캔 구성 및 검사 템플릿을 기반으로 데이터를 분석합니다.
Sensitive Data Protection은 데이터 프로필 생성 빈도에 설명된 대로 데이터를 다시 프로파일링합니다. 일정을 만들어 스캔 구성에서 프로파일링 빈도를 맞춤설정할 수 있습니다. 디스커버리 서비스에서 데이터를 다시 프로파일링하도록 강제하려면 다시 프로파일링 작업 강제 실행을 참고하세요.
검색 유형
이 섹션에서는 실행할 수 있는 검색 작업 유형과 지원되는 데이터 리소스를 설명합니다.
BigQuery 및 BigLake 검색
BigQuery 데이터를 프로파일링하면 프로젝트, 테이블, 열 수준에서 데이터 프로필이 생성됩니다. BigQuery 테이블을 프로파일링한 후 심층 검사를 수행하여 결과를 추가로 조사할 수 있습니다.
민감한 정보 보호는 다음을 포함하여 BigQuery Storage Read API에서 지원하는 테이블을 프로파일링합니다.
- 표준 BigQuery 테이블
- 테이블 스냅샷
- Cloud Storage에 저장된 BigLake 테이블
다음은 지원되지 않습니다.
- BigQuery Omni 테이블
- 개별 행의 직렬화된 데이터 크기가 BigQuery Storage Read API에서 지원하는 최대 직렬화된 데이터 크기인 128MB를 초과하는 테이블입니다.
- BigLake가 아닌 외부 테이블(예: Google Sheets)
BigQuery 데이터 프로파일링 방법에 대한 자세한 내용은 다음을 참고하세요.
BigQuery에 대한 자세한 내용은 BigQuery 문서를 참고하세요.
Cloud SQL 탐색
Cloud SQL 데이터를 프로파일링하면 프로젝트, 테이블, 열 수준에서 데이터 프로필이 생성됩니다. 검색을 시작하려면 프로파일링할 각 Cloud SQL 인스턴스의 연결 세부정보를 제공해야 합니다.
Cloud SQL 데이터 프로파일링 방법에 관한 자세한 내용은 다음을 참고하세요.
Cloud SQL에 대한 자세한 내용은 Cloud SQL 문서를 참고하세요.
Cloud Storage 탐색
Cloud Storage 데이터를 프로파일링하면 버킷 수준에서 데이터 프로필이 생성됩니다. 민감한 정보 보호는 감지된 파일을 파일 클러스터로 그룹화하고 각 클러스터의 요약을 제공합니다.
Cloud Storage 데이터를 프로파일링하는 방법에 대한 자세한 내용은 다음을 참고하세요.
Cloud Storage에 대한 자세한 내용은 Cloud Storage 문서를 참고하세요.
Vertex AI용 Discovery
Vertex AI 데이터 세트를 프로파일링하면 학습 데이터가 저장된 위치(Cloud Storage 또는 BigQuery)에 따라 Sensitive Data Protection에서 파일 스토어 데이터 프로필 또는 테이블 데이터 프로필을 생성합니다.
자세한 내용은 다음을 참조하세요.
Vertex AI에 대한 자세한 내용은 Vertex AI 문서를 참고하세요.
기타 클라우드 제공업체 검색
S3 데이터를 프로파일링하면 버킷 수준에서 데이터 프로필이 생성됩니다. Azure Blob Storage 데이터를 프로파일링하면 컨테이너 수준에서 데이터 프로필이 생성됩니다.
두 경우 모두 민감한 정보 보호는 감지된 파일을 파일 클러스터로 그룹화하고 각 클러스터의 요약을 제공합니다.
자세한 내용은 다음을 참조하세요.
Cloud Run 환경 변수
탐색 서비스는 Cloud Run 함수 및 Cloud Run 서비스 버전 환경 변수에서 보안 비밀의 존재를 감지하고 발견 항목을 Security Command Center로 보낼 수 있습니다. 데이터 프로필은 생성되지 않습니다.
자세한 내용은 Security Command Center에 환경 변수의 보안 비밀 보고를 참고하세요.
데이터 프로필 구성 및 보기에 필요한 역할
다음 섹션에는 용도에 따라 분류된 필수 사용자 역할이 열거되어 있습니다. 조직이 설정된 방법에 따라 각 사용자가 서로 다른 태스크를 수행하도록 결정할 수 있습니다. 예를 들어 데이터 프로필을 구성하는 사람은 일반적으로 이를 모니터링하는 사람과 다를 수 있습니다.
조직 또는 폴더 수준에서 데이터 프로필을 작업하는 데 필요한 역할
이러한 역할은 조직 또는 폴더 수준에서 데이터 프로필을 구성 및 확인할 수 있게 해줍니다.
이러한 역할이 조직 수준에서 적절한 사용자에게 부여되었는지 확인합니다. 또는 Google Cloud 관리자가 관련 권한만 있는 커스텀 역할을 만들 수 있습니다.
| 목적 | 사전 정의된 역할 | 관련 권한 |
|---|---|---|
| 검색 스캔 구성 만들기 및 데이터 프로필 보기 | DLP 관리자(roles/dlp.admin)
|
|
| 서비스 에이전트 컨테이너로 사용할 프로젝트 만들기1 | 프로젝트 생성자(roles/resourcemanager.projectCreator) |
|
| 검색 액세스 권한 부여2 | 다음 중 하나:
|
|
| 데이터 프로필 보기(읽기 전용) | DLP 데이터 프로필 리더(roles/dlp.dataProfilesReader) |
|
DLP 리더(roles/dlp.reader) |
|
1프로젝트 생성자(roles/resourcemanager.projectCreator) 역할이 없어도 스캔 구성을 만들 수 있지만 사용하는 서비스 에이전트 컨테이너가 기존 프로젝트여야 합니다.
2조직 관리자(roles/resourcemanager.organizationAdmin) 또는 보안 관리자(roles/iam.securityAdmin) 역할이 없어도 스캔 구성을 만들 수 있습니다. 스캔 구성을 만든 후 조직에서 이러한 역할 중 하나를 가진 사용자가 서비스 에이전트에 검색 액세스 권한을 부여해야 합니다.
프로젝트 수준에서 데이터 프로필을 작업하는 데 필요한 역할
이러한 역할은 프로젝트 수준에서 데이터 프로필을 구성 및 확인할 수 있게 해줍니다.
이러한 역할이 프로젝트 수준에서 적절한 사용자에게 부여되었는지 확인합니다. 또는 Google Cloud 관리자가 관련 권한만 있는 커스텀 역할을 만들 수 있습니다.
| 목적 | 사전 정의된 역할 | 관련 권한 |
|---|---|---|
| 데이터 프로필 구성 및 보기 | DLP 관리자(roles/dlp.admin)
|
|
| 데이터 프로필 보기(읽기 전용) | DLP 데이터 프로필 리더(roles/dlp.dataProfilesReader) |
|
DLP 리더(roles/dlp.reader) |
|
탐색 스캔 구성
검색 스캔 구성 (검색 구성 또는 스캔 구성이라고도 함)은 Sensitive Data Protection이 데이터를 프로파일링하는 방법을 지정합니다. 다음과 같은 설정이 포함됩니다.
- 검색 작업의 범위(조직, 폴더 또는 프로젝트)
- 프로파일링할 리소스 유형
- 사용할 검사 템플릿
- 스캔 빈도
- 검색에 포함하거나 검색에서 제외해야 하는 데이터의 특정 하위 집합
- 검색 후 Sensitive Data Protection이 수행할 작업(예: 프로필을 게시할 Google Cloud 서비스)
- 검색 작업에 사용할 서비스 에이전트
검색 스캔 구성을 만드는 방법에 대한 자세한 내용은 다음 페이지를 참고하세요.
BigQuery 데이터 검색
Cloud SQL 데이터 검색
Cloud Storage 데이터 탐색
Vertex AI 데이터 검색
Cloud Run 환경 변수의 보안 비밀을 Security Command Center에 보고 (생성된 프로필 없음)
스캔 구성 범위
다음 수준에서 스캔 구성을 만들 수 있습니다.
- 조직
- 폴더
- 프로젝트
- 단일 데이터 리소스
조직 및 폴더 수준에서 2개 이상의 활성 스캔 구성의 범위에 동일한 프로젝트가 있으면 Sensitive Data Protection에서 해당 프로젝트의 프로필을 생성할 수 있는 스캔 구성을 결정합니다. 자세한 내용은 이 페이지의 스캔 구성 재정의를 참조하세요.
프로젝트 수준 스캔 구성은 항상 대상 프로젝트를 프로파일링할 수 있으며 상위 폴더 또는 조직 수준의 다른 구성과 경쟁하지 않습니다.
단일 리소스 스캔 구성을 사용하면 단일 데이터 리소스에서 프로파일링을 탐색하고 테스트할 수 있습니다.
스캔 구성 위치
스캔 구성을 처음 만들 때는 민감한 정보 보호를 저장할 위치를 지정합니다. 이후에 만드는 모든 스캔 구성은 동일한 리전에 저장됩니다.
예를 들어 폴더 A에 대한 스캔 구성을 만들고 us-west1 리전에 저장하면 나중에 다른 리소스에 대해 만든 모든 스캔 구성도 이 리전에 저장됩니다.
프로파일링할 데이터에 대한 메타데이터가 스캔 구성과 동일한 리전에 복사되지만 데이터 자체는 이동되거나 복사되지 않습니다. 자세한 내용은 데이터 상주 고려사항을 참조하세요.
검사 템플릿
검사 템플릿은 민감한 정보 보호에서 데이터를 스캔하는 동안 찾는 정보 유형(또는 infoType)을 지정합니다. 여기에서는 기본 제공 infoType 및 선택적 커스텀 infoType의 조합을 제공합니다.
민감한 정보 보호가 일치하는 것으로 간주하는 범위를 좁힐 수 있는 가능성 수준도 제공할 수 있습니다. 규칙 세트를 추가하여 원치 않는 발견 항목을 제외하거나 추가 발견 항목을 포함할 수 있습니다.
기본적으로 스캔 구성에 사용되는 검사 템플릿을 변경하면 해당 변경사항이 이후 스캔에만 적용됩니다. 이 작업으로 데이터에 대한 다시 프로파일링 작업이 수행되는 것은 아닙니다.
검사 템플릿이 변경될 때 영향을 받는 데이터에 대해 다시 프로파일링하는 작업을 트리거하려면 스캔 구성에서 일정을 추가하거나 업데이트하고 검사 템플릿이 변경될 때 데이터를 다시 프로파일링하는 옵션을 사용 설정합니다. 자세한 내용은 데이터 프로필 생성 빈도를 참고하세요.
프로파일링할 데이터가 있는 리전마다 검사 템플릿이 있어야 합니다. 여러 리전에 단일 템플릿을 사용하려면 global 리전에 저장된 템플릿을 사용하면 됩니다. 조직 정책으로 인해 global 리전에서 검사 템플릿을 만들 수 없는 경우 각 리전에 전용 검사 템플릿을 설정해야 합니다. 자세한 내용은 데이터 상주 고려사항을 참조하세요.
검사 템플릿은 민감한 정보 보호 플랫폼의 핵심 구성요소입니다. 데이터 프로필은 모든 민감한 정보 보호 서비스에서 사용할 수 있는 동일한 검사 템플릿을 사용합니다. 검사 템플릿에 대한 자세한 내용은 템플릿을 참조하세요.
서비스 에이전트 컨테이너 및 서비스 에이전트
조직 또는 폴더의 스캔 구성을 만들 때 민감한 정보 보호 기능을 사용하려면 서비스 에이전트 컨테이너를 제공해야 합니다. 서비스 에이전트 컨테이너는 민감한 정보 보호에서 조직 및 폴더 수준 프로파일링 작업과 관련해 청구된 요금을 추적하는 데 사용하는 Google Cloud 프로젝트입니다.
서비스 에이전트 컨테이너에는 민감한 정보 보호에서 사용자를 대신하여 데이터를 프로파일링하는 데 사용하는 서비스 에이전트가 포함되어 있습니다. 민감한 정보 보호 및 기타 API에 인증하려면 서비스 에이전트가 필요합니다. 서비스 에이전트에는 데이터에 액세스하고 프로파일링하는 데 필요한 모든 권한이 있어야 합니다. 서비스 에이전트 ID의 형식은 다음과 같습니다.
service-PROJECT_NUMBER@dlp-api.iam.gserviceaccount.com
여기에서 PROJECT_NUMBER는 서비스 에이전트 컨테이너의 숫자 식별자입니다.
서비스 에이전트 컨테이너를 설정할 때 기존 프로젝트를 선택할 수 있습니다. 선택한 프로젝트에 서비스 에이전트가 포함된 경우 민감한 정보 보호는 해당 서비스 에이전트에 필요한 IAM 권한을 부여합니다. 프로젝트에 서비스 에이전트가 없으면 민감한 정보 보호에서 서비스 에이전트를 만들고 여기에 데이터 프로파일링 권한을 자동으로 부여합니다.
또는 민감한 정보 보호에서 서비스 에이전트 컨테이너와 서비스 에이전트를 자동으로 만들도록 선택할 수 있습니다. 민감한 정보 보호는 서비스 프로파일링에 데이터 프로파일링 권한을 자동으로 부여합니다.
두 경우 모두 민감한 정보 보호가 서비스 에이전트에 데이터 프로파일링 액세스 권한을 부여하지 않으면 스캔 구성 세부정보를 볼 때 오류가 표시됩니다.
프로젝트 수준 스캔 구성의 경우 서비스 에이전트 컨테이너가 필요하지 않습니다. 프로파일링하는 프로젝트는 서비스 에이전트 컨테이너의 역할을 합니다. 민감한 정보 보호는 프로파일링 작업을 실행하는 데 해당 프로젝트의 자체 서비스 에이전트를 사용합니다.
조직 또는 폴더 수준에서 데이터 프로파일링 액세스
조직 또는 폴더 수준에서 프로파일링을 구성하면 민감한 정보 보호는 서비스 에이전트에 데이터 프로파일링 액세스 권한을 자동으로 부여하려고 시도합니다. 하지만 IAM 역할을 부여할 수 있는 권한이 없으면 민감한 정보 보호에서 이 작업을 자동으로 수행할 수 없습니다. Google Cloud 관리자와 같이 조직 내에서 해당 권한이 있는 사람이 서비스 에이전트에 데이터 프로파일링 액세스 권한을 부여해야 합니다.
데이터 프로필 생성 빈도
특정 리소스의 검색 스캔 구성을 만든 후 Sensitive Data Protection은 초기 스캔을 수행하여 스캔 구성 범위의 데이터를 프로파일링합니다.
초기 스캔 후 Sensitive Data Protection은 프로파일링된 리소스를 지속적으로 모니터링합니다. 리소스에 추가된 데이터는 추가된 직후 자동으로 프로파일링됩니다.
기본 리프로파일링 빈도
기본 리프로파일링 빈도는 스캔 구성의 검색 유형에 따라 다릅니다.
- BigQuery 프로파일링: 각 테이블의 경우 30일 동안 기다린 후 스키마, 테이블 행 또는 검사 템플릿이 변경된 경우 테이블을 다시 프로파일링합니다.
- Cloud SQL 프로파일링: 각 테이블에 대해 30일 동안 기다린 후 스키마 또는 검사 템플릿이 변경된 경우 테이블을 다시 프로파일링합니다.
- Vertex AI 프로파일링: 각 데이터 세트의 경우 30일 동안 기다린 후 검사 템플릿이 변경된 경우 데이터 세트를 다시 프로파일링합니다.
파일 저장소 프로파일링: Google Cloud 또는 기타 클라우드의 각 파일 저장소에 대해 30일 동안 기다린 후 검사 템플릿이 변경된 경우 파일 저장소를 다시 프로파일링합니다.
민감한 정보 보호에서는 파일 스토리지 버킷 또는 컨테이너를 나타내기 위해 파일 스토어라는 용어를 사용합니다.
리프로파일링 빈도 맞춤설정
스캔 구성에서 데이터의 하위 집합마다 하나 이상의 일정을 만들어 리프로파일링 빈도를 맞춤설정할 수 있습니다.
다음과 같은 다시 프로파일링 빈도를 사용할 수 있습니다.
- 다시 프로파일링하지 않음: 초기 프로필이 생성된 후에는 다시 프로파일링하지 않습니다.
- 매일 다시 프로파일링: 24시간 후에 다시 프로파일링합니다.
- 매주 다시 프로파일링: 7일 후에 다시 프로파일링합니다.
- 매월 다시 프로파일링: 30일 후에 다시 프로파일링합니다.
일정에 따른 리프로파일링
스캔 구성에서 데이터가 변경되었는지 여부와 관계없이 데이터의 하위 집합을 정기적으로 다시 프로파일링할지 여부를 지정할 수 있습니다. 설정한 빈도는 프로파일링 작업 사이에 경과해야 하는 시간을 지정합니다. 예를 들어 빈도를 주별로 설정하면 Sensitive Data Protection은 마지막으로 프로파일링된 후 7일이 지나면 데이터 리소스를 프로파일링합니다.
업데이트 시 리프로파일링
스캔 구성에서 다시 프로파일링 작업을 트리거할 수 있는 이벤트를 지정할 수 있습니다. 이러한 이벤트의 예시로는 검사 템플릿 업데이트가 있습니다.
이러한 이벤트를 선택하면 설정한 일정에 따라 Sensitive Data Protection이 데이터를 다시 프로파일링하기 전에 업데이트 누적을 기다리는 가장 긴 시간이 지정됩니다. 지정된 기간 내에 스키마 변경 또는 검사 템플릿 변경과 같이 적용 가능한 변경사항이 없으면 데이터가 다시 프로파일링되지 않습니다. 다음에 적용 가능한 변경이 발생하면 영향을 받는 데이터는 다음 기회에 다시 프로파일링되며, 이는 다양한 요소 (예: 사용 가능한 머신 용량 또는 구매한 구독 단위)에 따라 결정됩니다. 그런 다음 Sensitive Data Protection은 설정된 일정에 따라 업데이트가 다시 누적될 때까지 기다립니다.
예를 들어 스캔 구성이 스키마 변경에 대해 매월 다시 프로파일링하도록 설정되어 있다고 가정해 보겠습니다. 데이터 프로필은 0일 차에 처음 만들어졌습니다. 30일 차까지 스키마가 변경되지 않았습니다. 그러므로 데이터가 다시 프로파일링되지 않습니다. 35일 차에 첫 번째 스키마가 변경됩니다. Sensitive Data Protection은 다음 기회에 업데이트된 데이터를 다시 프로파일링합니다. 그런 다음 시스템은 스키마 업데이트가 누적될 때까지 30일 더 기다린 후에 업데이트된 데이터를 다시 프로파일링합니다.
다시 프로파일링이 시작된 후 작업이 완료되려면 최대 24시간까지 걸릴 수 있습니다. 지연이 24시간 이상 지속되고 구독 가격 모드를 사용하는 경우 해당 월에 용량이 남아 있는지 확인합니다.
예시 시나리오로 데이터 프로파일링 가격 책정 예시를 참조하세요.
디스커버리 서비스에서 데이터를 다시 프로파일링하도록 강제하려면 다시 프로파일링 작업 강제 실행을 참고하세요.
프로파일링 성능
데이터를 프로파일링하는 데 걸리는 시간은 다음을 포함하되 이에 국한되지 않은 여러 요소에 따라 달라집니다.
- 프로파일링할 데이터 리소스 수
- 데이터 리소스 크기
- 표의 경우 열 수
- 표의 경우 열의 데이터 유형
따라서 과거 검사나 프로파일링 태스크에서 경험한 민감한 정보 보호 성능이 이후의 프로파일링 태스크에서 수행할 성능을 의미하지는 않습니다.
데이터 프로필 보관
민감한 정보 보호는 데이터 프로필의 최신 버전을 13개월 동안 보관합니다. Sensitive Data Protection이 데이터 리소스를 다시 프로파일링하면 시스템에서 해당 데이터 리소스의 기존 프로필을 새 프로필로 바꿉니다.
다음 예시 시나리오에서는 BigQuery의 기본 프로파일링 빈도가 적용된다고 가정합니다.
1월 1일에 민감한 정보 보호에서 테이블 A를 프로파일링합니다. 테이블 A는 1년 동안 변경되지 않으므로 다시 프로파일링되지 않습니다. 이 경우 민감한 정보 보호는 테이블 A의 데이터 프로필을 13개월 동안 보관한 후 삭제합니다.
1월 1일에 민감한 정보 보호에서 테이블 A를 프로파일링합니다. 1월 내에 조직 내 누군가가 해당 테이블의 스키마를 업데이트합니다. 이 변경으로 인해 다음 달 민감한 정보 보호에서 테이블 A를 자동으로 다시 프로파일링합니다. 새로 생성된 데이터 프로필은 1월에 생성된 프로필을 덮어씁니다.
데이터 프로파일링에 민감한 정보 보호에서 비용을 청구하는 방식에 대한 자세한 내용은 탐색 가격 책정을 참고하세요.
데이터 프로필을 무기한 보존하거나 발생한 변경사항의 레코드를 보관하려면 프로파일링을 구성할 때 데이터 프로필을 BigQuery에 저장하는 것이 좋습니다. 프로필을 저장할 BigQuery 데이터 세트를 선택하고 이 데이터 세트의 테이블 만료 정책을 제어합니다.
스캔 구성 재정의
각 범위 및 검색 유형 조합에 대해 스캔 구성을 하나만 만들 수 있습니다. 예를 들어 BigQuery 데이터 프로파일링에 대해 조직 수준 스캔 구성을 하나만 만들고 보안 비밀 검색에 대해 조직 수준 스캔 구성을 하나만 만들 수 있습니다. 마찬가지로 BigQuery 데이터 프로파일링에 대해 프로젝트 수준의 스캔 구성을 하나만 만들고 보안 비밀 검색에 대해 프로젝트 수준의 스캔 구성을 하나만 만들 수 있습니다.
2개 이상의 활성 스캔 구성의 해당 범위에 동일한 프로젝트 및 검색 유형이 포함되어 있으면 다음 규칙이 적용됩니다.
- 조직 수준 및 폴더 수준 스캔 구성에서는 프로젝트에 가장 가까운 항목이 해당 프로젝트에 대해 검색을 실행할 수 있습니다. 이 규칙은 동일한 검색 유형의 프로젝트 수준 스캔 구성이 있더라도 적용됩니다.
- 민감한 정보 보호는 조직 수준 및 폴더 수준 구성과 별개로 프로젝트 수준 스캔 구성을 처리합니다. 프로젝트 수준에서 만드는 스캔 구성은 상위 폴더 또는 조직용으로 만드는 구성을 재정의할 수 없습니다.
세 가지 활성 스캔 구성이 있는 예시를 가정해 보겠습니다. 이러한 모든 스캔 구성이 BigQuery 데이터 프로파일링을 위한 것이라고 가정해 보세요.
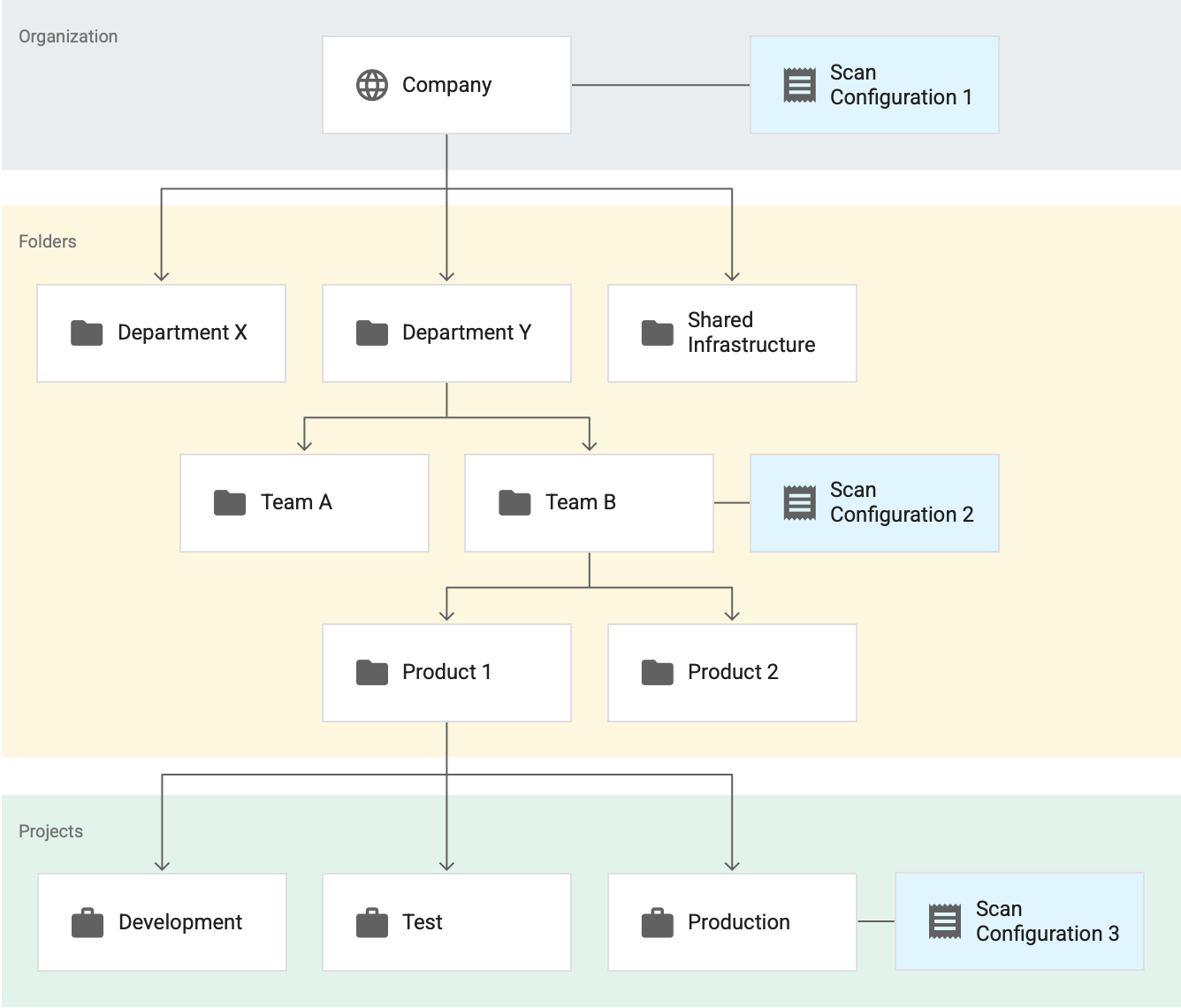
여기에서 스캔 구성 1은 전체 조직에 적용되고 스캔 구성 2는 팀 B 폴더에 적용되며 스캔 구성 3은 프로덕션 프로젝트에 적용됩니다. 이 예에서는 다음과 같이 정의됩니다.
- 민감한 정보 보호는 스캔 구성 1에 따라 팀 B 폴더에 없는 프로젝트의 모든 테이블을 프로파일링합니다.
- 민감한 정보 보호는 스캔 구성 2에 따라 팀 B 폴더에 있는 프로젝트의 모든 테이블(프로덕션 프로젝트의 테이블 포함)을 프로파일링합니다.
- 민감한 정보 보호는 스캔 구성 3에 따라 프로덕션 프로젝트의 모든 테이블을 프로파일링합니다.
이 예시에서 민감한 정보 보호는 프로덕션 프로젝트의 프로필 세트 2개를 생성합니다. 이 프로필 세트는 다음 각 스캔 구성마다 하나씩 설정됩니다.
- 스캔 구성 2
- 스캔 구성 3
하지만 동일한 프로젝트에 두 개의 프로필 세트가 있어도 대시보드에 모두 함께 표시되지는 않습니다. 보고 있는 리소스(조직, 폴더 또는 프로젝트)와 리전에서 생성된 프로필만 표시됩니다.
Google Cloud의 리소스 계층 구조에 대한 자세한 내용은 리소스 계층 구조를 참고하세요.
데이터 프로필 스냅샷
각 데이터 프로필에는 스캔 구성의 스냅샷과 이를 생성하는 데 사용된 검사 템플릿이 포함됩니다. 이 스냅샷을 사용하여 특정 데이터 프로필을 생성하는 데 사용한 설정을 확인할 수 있습니다.
데이터 보존 고려사항
데이터 상주 고려사항은Google Cloud 데이터를 스캔하는지 아니면 다른 클라우드 제공업체의 데이터를 스캔하는지에 따라 다릅니다.
Google Cloud 데이터의 데이터 상주 고려사항
이 섹션은 Google Cloud리소스의 민감한 데이터 검색에만 적용됩니다. 다른 클라우드 제공업체의 리소스와 관련된 데이터 상주 고려사항은 이 페이지의 다른 클라우드 제공업체의 데이터에 대한 데이터 상주 고려사항을 참고하세요.
민감한 정보 보호는 데이터 상주를 지원하도록 설계되었습니다. 데이터 상주 요구사항을 준수해야 하는 경우 다음 사항을 고려하세요.
지역 검사 템플릿
이 섹션은 Google Cloud리소스의 민감한 데이터 검색에만 적용됩니다. 다른 클라우드 제공업체의 리소스와 관련된 데이터 상주 고려사항은 이 페이지의 다른 클라우드 제공업체의 데이터에 대한 데이터 상주 고려사항을 참고하세요.
Sensitive Data Protection은 데이터가 저장된 리전과 동일한 리전에서 데이터를 처리합니다. 즉, 데이터는 현재 리전을 벗어나지 않습니다.
또한 검사 템플릿은 해당 템플릿과 동일한 리전에 존재하는 데이터를 프로파일링하는 데에만 사용될 수 있습니다. 예를 들어 us-west1 리전에 저장된 검사 템플릿을 사용하도록 검색을 구성하는 경우 민감한 정보 보호에서 해당 리전의 데이터만 프로파일링할 수 있습니다.
데이터가 있는 각 리전에 전용 검사 템플릿을 설정할 수 있습니다.
global 리전에 저장된 검사 템플릿을 제공하면 민감한 정보 보호는 전용 검사 템플릿이 없는 리전의 데이터에 해당 템플릿을 사용합니다.
다음 표에서는 예시 시나리오를 보여줍니다.
| 시나리오 | 지원 |
|---|---|
us 리전에서 검사 템플릿을 사용하여 us 리전의 데이터를 스캔합니다. |
지원됨 |
us 리전에서 검사 템플릿을 사용하여 global 리전의 데이터를 스캔합니다. |
지원되지 않음 |
global 리전에서 검사 템플릿을 사용하여 us 리전의 데이터를 스캔합니다. |
지원됨 |
us-east1 리전에서 검사 템플릿을 사용하여 us 리전의 데이터를 스캔합니다. |
지원되지 않음 |
us 리전에서 검사 템플릿을 사용하여 us-east1 리전의 데이터를 스캔합니다. |
지원되지 않음 |
asia 리전에서 검사 템플릿을 사용하여 us 리전의 데이터를 스캔합니다. |
지원되지 않음 |
데이터 프로필 구성
이 섹션은 Google Cloud리소스의 민감한 데이터 검색에만 적용됩니다. 다른 클라우드 제공업체의 리소스와 관련된 데이터 상주 고려사항은 이 페이지의 다른 클라우드 제공업체의 데이터에 대한 데이터 상주 고려사항을 참고하세요.
민감한 정보 보호에서 데이터 프로필을 만들 때 스캔 구성과 검사 템플릿의 스냅샷을 만들고 이를 각 테이블 데이터 프로필 또는 파일 스토어 데이터 프로필에 저장합니다.
global 리전에서 검사 템플릿을 사용하도록 검색을 구성하면 민감한 정보 보호는 이 템플릿을 프로파일링할 데이터가 있는 리전에 복사합니다. 마찬가지로 스캔 구성을 해당 리전에 복사합니다.
다음 예시: 프로젝트 A에 테이블 1 포함을 고려해보세요. 표 1은 us-west1 리전에 있고, 스캔 구성은 us-west2 리전에 있고, 검사 템플릿은 global 리전에 있습니다.
민감한 정보 보호에서 프로젝트 A를 스캔할 때 테이블 1의 데이터 프로필을 만들고 us-west1 리전에 저장합니다. 테이블 1의 테이블 데이터 프로필에는 프로파일링 작업에 사용되는 스캔 구성 및 검사 템플릿의 복사본이 포함됩니다.
검사 템플릿을 다른 리전에 복사하지 않으려면 민감한 정보 구성에서 해당 리전의 데이터를 스캔하지 않도록 구성합니다.
데이터 프로필의 Regional Storage
이 섹션은 Google Cloud리소스의 민감한 데이터 검색에만 적용됩니다. 다른 클라우드 제공업체의 리소스와 관련된 데이터 상주 고려사항은 이 페이지의 다른 클라우드 제공업체의 데이터에 대한 데이터 상주 고려사항을 참고하세요.
Sensitive Data Protection은 데이터가 있는 리전 또는 멀티 리전에서 데이터를 처리하고 생성된 데이터 프로필을 동일한 리전이나 멀티 리전에 저장합니다.
Google Cloud 콘솔에서 데이터 프로필을 보려면 먼저 데이터 프로필이 있는 리전을 선택해야 합니다. 여러 리전에 데이터가 있는 경우 각 프로필 집합을 보려면 리전을 전환해야 합니다.
지원되지 않는 리전
이 섹션은 Google Cloud리소스의 민감한 데이터 검색에만 적용됩니다. 다른 클라우드 제공업체의 리소스와 관련된 데이터 상주 고려사항은 이 페이지의 다른 클라우드 제공업체의 데이터에 대한 데이터 상주 고려사항을 참고하세요.
데이터가 민감한 정보 보호에서 지원하지 않는 리전에 있는 경우 검색 서비스는 이러한 데이터 리소스를 건너뛰고 데이터 프로필을 볼 때 오류를 표시합니다.
멀티 리전
민감한 정보 보호는 멀티 리전을 리전 모음이 아닌 하나의 리전으로 취급합니다. 예를 들어 us 멀티 리전과 us-west1 리전은 데이터 상주와 관련하여 두 개의 개별 리전으로 취급됩니다.
영역별 리소스
민감한 정보 보호는 리전 및 멀티 리전 서비스이며 영역을 구분하지 않습니다. Cloud SQL 인스턴스와 같은 지원되는 영역 리소스의 경우 데이터는 현재 리전에서 처리되지만 반드시 현재 영역에서 처리되는 것은 아닙니다. 예를 들어 Cloud SQL 인스턴스가 us-central1-a 영역에 저장된 경우 민감한 정보 보호는 us-central1 리전에서 데이터 프로필을 처리하고 저장합니다.
Google Cloud 위치에 관한 일반 정보는 위치 및 리전을 참고하세요.
다른 클라우드 제공업체의 데이터에 대한 데이터 상주 고려사항
다른 클라우드 제공업체의 데이터를 프로파일링하려는 경우 다음을 고려하세요.
- 데이터 프로필은 검색 스캔 구성과 함께 저장됩니다. 반면 Google Cloud 데이터를 프로파일링하면 프로필이 프로파일링할 데이터와 동일한 리전에 저장됩니다.
global리전에 검사 템플릿을 저장하면 검색 스캔 구성을 저장한 리전에서 해당 템플릿의 인메모리 복사본이 읽힙니다.- 데이터는 수정되지 않습니다. 데이터의 인메모리 복사본은 검색 스캔 구성을 저장하는 리전에서 읽습니다. 하지만 민감한 정보 보호는 데이터가 공개 인터넷에 도달한 후 어디를 통과하는지 보장하지 않습니다. 데이터는 SSL로 암호화됩니다.
규정 준수
민감한 정보 보호에서 데이터를 처리하고 규정 준수 요구사항을 충족할 수 있게 하는 방법에 대한 자세한 내용은 데이터 보안을 참조하세요.
다음 단계
Identity & Security 블로그 게시물 민감한 정보 보호를 사용하여 BigQuery용 자동 데이터 위험 관리 읽어보기
데이터 프로파일링 비용 추정 방법 알아보기
Sensitive Data Protection에서 데이터를 프로파일링할 때 데이터 위험 및 민감도 수준을 계산하는 방법을 알아봅니다.
검색 결과 해결 방법 알아보기
데이터 프로파일러 관련 문제 해결 방법 알아보기