Tiempo estimado para completarse: 5 días
Propietario del componente operable: OLT
Perfil de habilidades: ingeniero de implementaciones
A partir de la versión 1.14, la finalización de la implementación se verifica en los paneles de control de Observabilidad y monitorización.
Verificar el panel de control de incidentes de ServiceNow
- Comprueba si hay incidentes nuevos o sin resolver relacionados con la implementación.
Verificar el panel de control de Alertmanager de Grafana
- Busca alertas activas.
Clasificar nuevos incidentes y alertas En el caso de los nuevos incidentes de ServiceNow o las alertas activadas de Grafana, sigue estos pasos:
- Compara el problema con el documento de problemas conocidos.
- Si el problema no aparece en la lista de problemas conocidos, deriva el caso al equipo de Ingeniería para que evalúe cómo proceder. Para resolver el problema, es posible que tengas que hacer lo siguiente:
- Resuelve el problema subyacente.
- Documenta la alerta como un nuevo problema conocido, por ejemplo, si se trata de un falso positivo.
37.1. Verificar el estado del sistema
Después de la implementación, el indicador principal del estado del sistema es la ausencia de incidentes y alertas nuevos e inesperados en el panel de control de incidentes de ServiceNow (SNOW) y en el panel de control de AlertManager de Grafana.
37.1.1. Panel de control de incidentes de ServiceNow
El panel de control de ServiceNow ofrece una vista general de los problemas significativos que el sistema ha registrado automáticamente. Después de una implementación, este panel de control no debería mostrar ningún incidente crítico nuevo.
Tu objetivo es confirmar que no se han activado incidentes nuevos sin documentar. Cualquier incidencia que aparezca debe figurar en la sección de problemas conocidos.
37.1.2. Panel de control de AlertManager de Grafana
El panel de control de AlertManager ofrece una vista más inmediata y en tiempo real del estado del sistema, ya que muestra las alertas que se activan. Los problemas suelen aparecer aquí antes de que se cree un incidente de ServiceNow.
Un sistema en buen estado no mostrará nuevas alertas de activación. Todas las alertas activas deben verificarse en la página de problemas conocidos para confirmar que se trata de un comportamiento esperado.
37.1.3. Interpretar los resultados
Si ninguno de los dos paneles muestra problemas nuevos ni sin documentar, es una confirmación sólida de que la implementación se ha realizado correctamente y de que el sistema es estable.
Si detecta algún incidente o alerta que no aparece en la página de problemas conocidos, siga los pasos de triaje y derivación que se indican en la lista de comprobación mencionada anteriormente. Los nuevos falsos positivos deben comunicarse al equipo de ingeniería para que se puedan abordar y documentar correctamente.
37.2. Ejemplo de flujo de trabajo de triaje
Cuando una alerta nueva requiere una investigación, el proceso general de triaje en Grafana AlertManager implica los siguientes pasos:
Agrupar por prioridad: primero, agrupa las alertas para centrarte en los problemas más críticos.
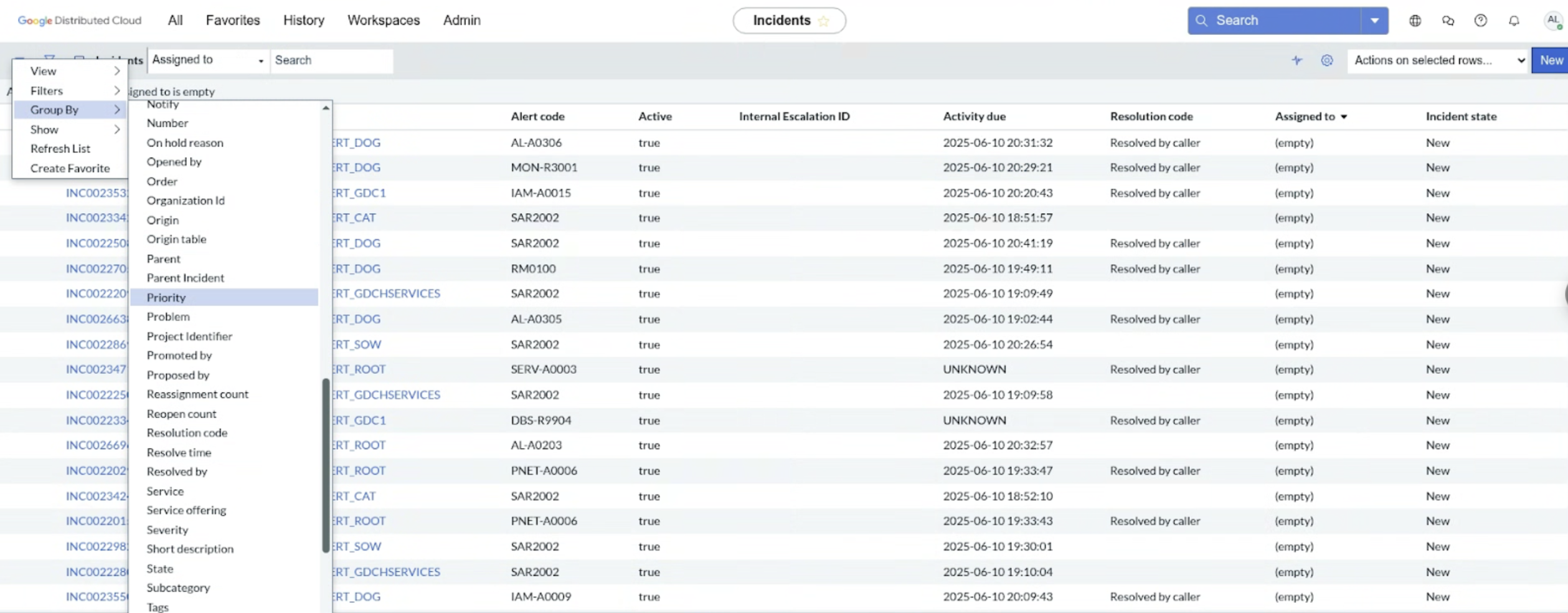
Asigna un ticket: para asegurar la propiedad y el seguimiento, asigna un ticket a la alerta.
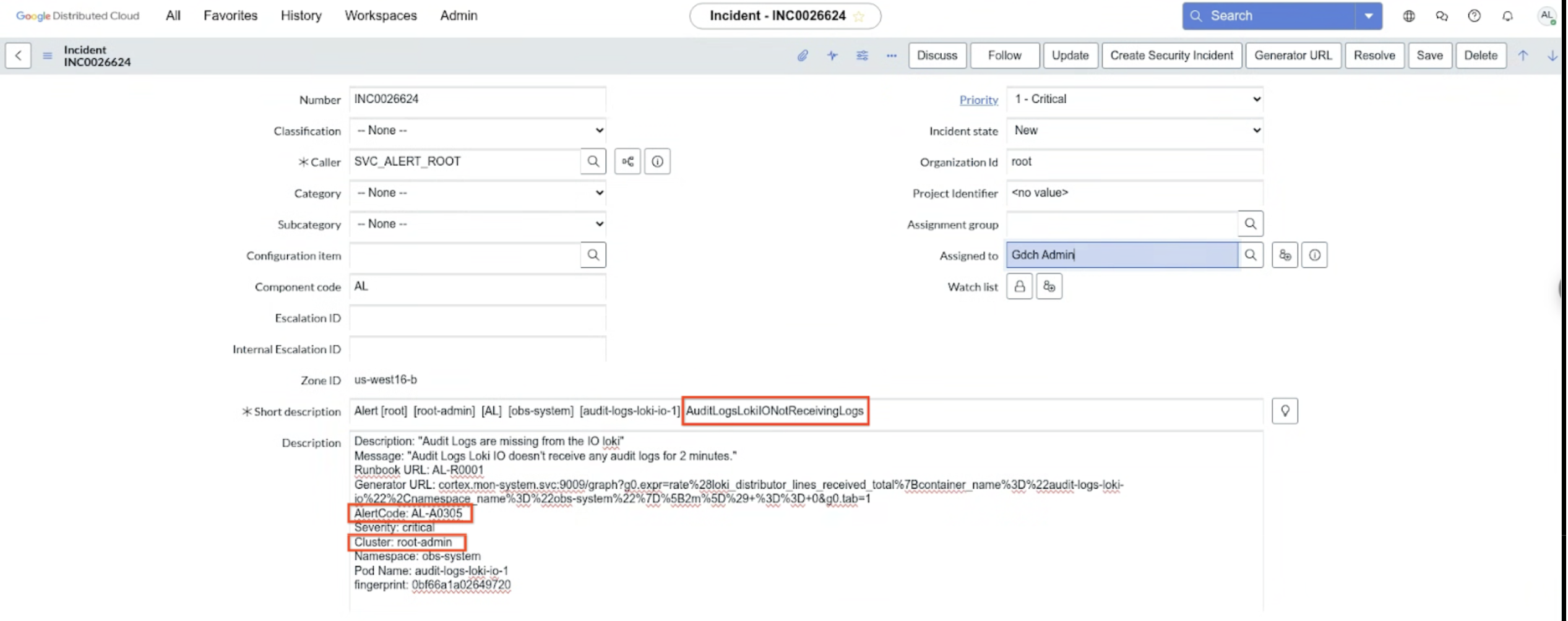
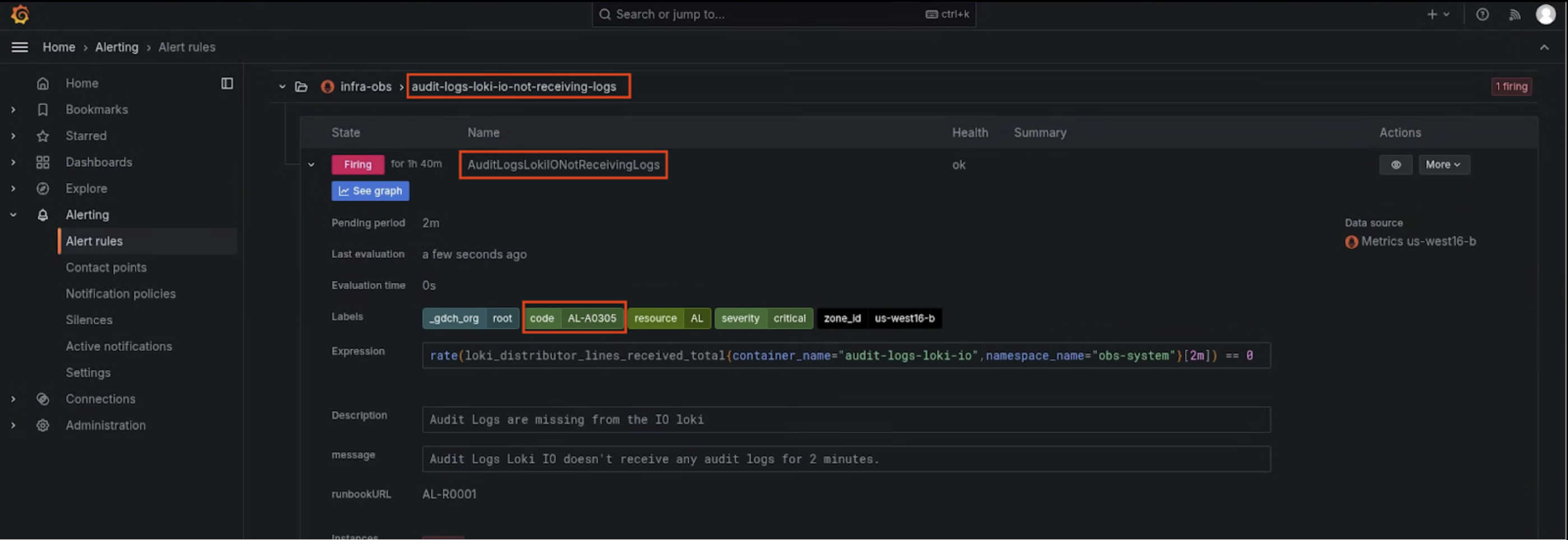
Revisa las reglas de alertas: investiga la regla de alertas específica que se ha activado para comprender sus condiciones y su finalidad.
Comprobar el estado de activación: consulta los detalles y el estado de la alerta de activación en el panel de control.
Verifica la alerta: por último, confirma que la alerta se activa y representa un problema válido antes de continuar con el proceso de derivación.