预计完成时间:4 天
可操作组件所有者:硬件
技能配置文件:部署工程师
完成以下任务,以重置在 Google Distributed Cloud (GDC) 气隙环境中运行的设备和系统。
6.1. 目录
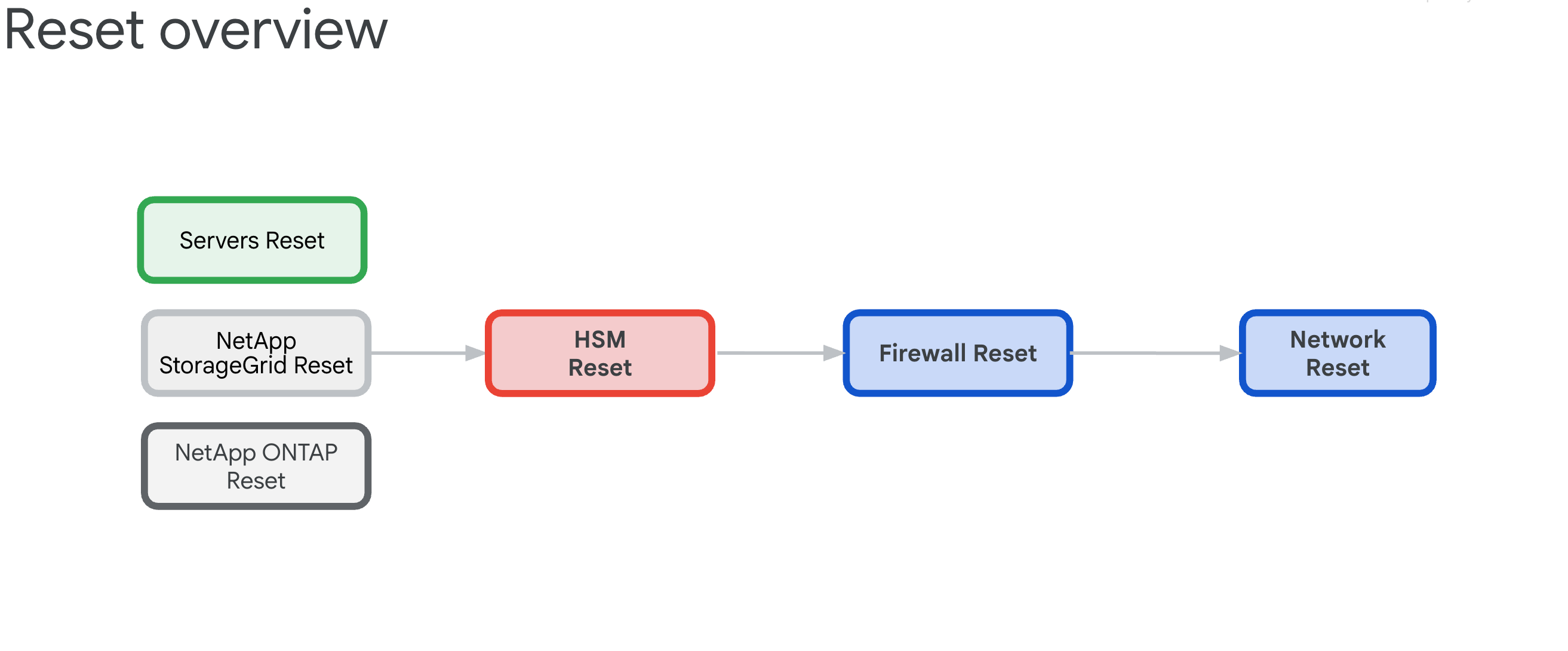
- 重置流程概览
- HPE 服务器重置
- NetApp StorageGRID 重置
- NetApp ONTAP 重置
- Thales HSM 重置
- Palo Alto 防火墙重置
- Cisco 交换机重置
- 其他资源
6.2. 前提条件和安全
6.2.1. 所需访问权限
- 物理访问权限:可访问配备了 crashcart 设备的 DC 机房
- 网络访问:管理界面连接或控制台访问
- 凭据:对所有系统的管理员访问权限
- 备份:所有密钥和配置数据的完整备份
6.2.2. 安全核查清单
- [ ] 对基础设施的物理访问权限
- [ ] 紧急情况下的密钥已离线安全存储
- [ ] 基础架构的备份(如有需要)
6.3. 重置程序概览
现有 GDC 单元区域的重置过程旨在使所有硬件设备摆脱任何依赖关系,然后将其恢复到其 Fabric 状态。
6.3.1. 基础架构依赖项
这些组件具有以下相互依赖关系,决定了重置顺序:
- 服务器、NetApp ONTAP 和 NetApp StorageGrid 依赖于 Thales HSM 设备,因为这些设备可为 ILO、磁盘、租户和存储分区提供加密密钥。
- Thales HSM 设备依赖于 IDP/边界防火墙和 Cisco 交换机连接。
- IDP/边界防火墙依赖于 Cisco 交换机网络基础设施。
- Cisco 交换机需要作为最后一种资源进行重置,因为在重置后连接会中断。
6.3.2. 重置订单(严重)
请按以下顺序操作,以免系统锁定:
- HPE 服务器 - 先移除 HSM 依赖项
- NetApp StorageGRID - 清除加密并重置节点
- NetApp ONTAP - 停用 HSM 并重置集群
- Thales HSM - 恢复出厂设置并清除信任根
- 防火墙 - 恢复出厂设置以将配置重置为默认配置
- Cisco 交换机 - 最后重置(会中断连接)
6.4. Hewlett Packard Enterprise 安全擦除
有三种类型的重置操作可用,每种操作都是清理 iLO Key Manager 配置的替代方法。主要目标是移除对硬件安全模块 (HSM) 的依赖。
通常,ILO 恢复出厂设置足以清理 KMS 配置,然后在下次引导时,服务器引导过程将初始化服务器设置 BIOS 参数、擦除磁盘并重新初始化服务器。
本部分介绍了如何执行以下三种类型的擦除:
这些数据清除脚本使用名为 example.csv 的示例 CSV 文件。在继续操作之前,请准备好以下 CSV 文件:
root@example-bootstrapper:/home/ubuntu/md# cat example.csv
ip,passd
10.251.248.62,XXXXXXXX
10.251.248.64,XXXXXXXX
10.251.248.66,XXXXXXXX
10.251.248.68,XXXXXXXX
10.251.248.70,XXXXXXXX
10.251.248.72,XXXXXXXX
10.251.248.74,XXXXXXXX
10.251.248.76,XXXXXXXX
6.4.1. iLO 恢复出厂设置
完成常规 iLO 恢复出厂设置:
创建一个名为
serversreset.py的文件,并添加以下 Python 脚本:import csv import argparse import requests import urllib3 import json urllib3.disable_warnings() PARSER = argparse.ArgumentParser(prog='serversreset.py', \ description='reset ilo to factory settings') PARSER.add_argument('-csv', '--file', help='choose the csv file', type=str) ARGS = vars(PARSER.parse_args()) headers = {'content-type': 'application/json'} payload = {'ResetType': 'Default'} url = '/redfish/v1/Managers/1/Actions/Oem/Hpe/HpeiLO.ResetToFactoryDefaults/' with open(ARGS['file'], encoding="utf8", mode='r') as csv_file: CSV_READER = csv.DictReader(csv_file) for row in CSV_READER: try: system = requests.post('https://'+row['ip']+url,data=json.dumps(payload),headers=headers,verify=False,auth=('administrator',row['passd'])) systemData = system.json() print(systemData) except Exception as err: print(err)运行以下命令,并将
example.csv替换为您的 CSV 文件:python3 serversreset.py -csv example.csv输出必须类似于以下内容:
{'error': {'code': 'iLO.0.10.ExtendedInfo', 'message': 'See @Message.ExtendedInfo for more information.', '@Message.ExtendedInfo': [{'MessageId': 'iLO.2.15.ResetInProgress'}]}} {'error': {'code': 'iLO.0.10.ExtendedInfo', 'message': 'See @Message.ExtendedInfo for more information.', '@Message.ExtendedInfo': [{'MessageId': 'iLO.2.15.ResetInProgress'}]}} {'error': {'code': 'iLO.0.10.ExtendedInfo', 'message': 'See @Message.ExtendedInfo for more information.', '@Message.ExtendedInfo': [{'MessageId': 'iLO.2.15.ResetInProgress'}]}}
6.4.2. 其他手动 iLO 步骤
使用 iLO 界面执行手动 iLO 重置:
依次选择 iLO > 管理 > 密钥管理器 > 删除设置。
在 BIOS 控制台中,依次选择系统实用程序 > 系统配置 > 嵌入式 RAID > 管理 > 重置为默认值。
将接口设置为仅针对 LOM1 进行网络启动。所有 GPU 节点都没有 LOM1 卡,而是配备了 Intel 卡。
将 iLO 网络设置为 DHCP。
6.4.3. BIOS 重置
请按以下步骤操作,以执行 BIOS 重置:
创建一个名为
biosreset.py的文件,并添加以下 Python 脚本:import csv import argparse import requests import urllib3 import json urllib3.disable_warnings() PARSER = argparse.ArgumentParser(prog='biosreset.py', \ description='reset BIOS to factory settings') PARSER.add_argument('-csv', '--file', help='choose the csv file', type=str) ARGS = vars(PARSER.parse_args()) headers = {'content-type': 'application/json'} payload = {} with open(ARGS['file'], encoding="utf8", mode='r') as csv_file: CSV_READER = csv.DictReader(csv_file) for row in CSV_READER: try: system = requests.post('https://'+row['ip']+'/redfish/v1/systems/1/bios/Actions/Bios.ResetBios/',data=json.dumps(payload),headers=headers,verify=False,auth=('administrator',row['passd'])) systemData = system.json() print(systemData) except Exception as err: print(err)运行以下命令,并将
example.csv替换为您的 CSV 文件:python3 biosreset.py -csv example.csv输出必须类似于以下内容:
{'error': {'code': 'iLO.0.10.ExtendedInfo', 'message': 'See @Message.ExtendedInfo for more information.', '@Message.ExtendedInfo': [{'MessageId': 'iLO.2.15.SystemResetRequired'}]}}运行该命令后,服务器处于开机状态。您必须运行以下脚本才能关闭所有服务器:
import csv import argparse import requests import urllib3 import json urllib3.disable_warnings() PARSER = argparse.ArgumentParser(prog='power-ilo.py', \ description='power off server') PARSER.add_argument('-csv', '--file', help='choose the csv file', type=str) ARGS = vars(PARSER.parse_args()) headers = {'content-type': 'application/json'} payload = {'ResetType': 'PushPowerButton'} with open(ARGS['file'], encoding="utf8", mode='r') as csv_file: CSV_READER = csv.DictReader(csv_file) for row in CSV_READER: try: system = requests.post( 'https://' + row['ip'] + '/redfish/v1/systems/1/Actions/ComputerSystem.Reset/', data=json.dumps(payload), headers=headers, verify=False, auth=('administrator', row['passd'])) systemData = system.json() if 'Success' in systemData['error']['@Message.ExtendedInfo'][0][ 'MessageId']: print(f"ilo with ip {row['ip']} succeeded") #print(systemData) else: print(f"ilo with ip {row['ip']} failed") print(systemData) except Exception as err: print(err)手动关闭服务器电源:
python3 power-ilo.py -csv ~/servers.csv- (可选)如需检查状态,请使用以下脚本:
import csv import argparse import requests import urllib3 import json urllib3.disable_warnings() PARSER = argparse.ArgumentParser(prog='ilostatus.py', \ description='check power status of server') PARSER.add_argument('-csv', '--file', help='choose the csv file', type=str) ARGS = vars(PARSER.parse_args()) headers = {'content-type': 'application/json'} with open(ARGS['file'], encoding="utf8", mode='r') as csv_file: CSV_READER = csv.DictReader(csv_file) for row in CSV_READER: try: system = requests.get('https://'+row['ip']+'/redfish/v1/Systems/1',headers=headers,verify=False,auth=('administrator',row['passd'])) systemData = system.json() print(f"ilo with ip {row['ip']} has power status of {systemData['PowerState']}") if 'Success' in systemData['error']['@Message.ExtendedInfo'][0]['MessageId']: print(f"ilo with ip {row['ip']} succeeded") print(systemData) else: print(f"ilo with ip {row['ip']} failed") print(systemData) except Exception as err: pass运行以下命令:
python3 ilostatus.py -csv ~/servers.csv输出必须类似于以下内容:
ilo with ip 172.22.112.96 has power status of Off ilo with ip 172.22.112.97 has power status of Off ilo with ip 172.22.112.98 has power status of Off ilo with ip 172.22.112.100 has power status of Off ilo with ip 172.22.112.101 has power status of Off ilo with ip 172.22.112.102 has power status of Off6.4.4. 安全擦除
在服务器 POST 界面中按 F10。这将启动智能配置。
启动智能配置后,点击首次设置向导后面的向下箭头以跳过向导。
跳过向导提示,点击是。
点击 Perform Maintenance。
点击一键安全清空。
系统会显示一条消息,指出您没有足够的权限。点击登录,然后输入管理员凭据。
点击完成。
点击提交。
确认您要执行安全擦除,然后输入 ERASE。
点击清除。
点击是进行确认。
在“作业队列”部分中,点击立即启动。
在 2 分钟内(或更短时间内),按照提示点击确定。
机器会重新启动,请在 10 到 15 分钟内不要触碰任何东西。
安全擦除完成后,在 POST 启动期间点击 F9,重新进入 BIOS。
依次前往嵌入式应用 > 集成管理日志 (IML) > 查看 IML > 确定。 系统会显示“一键安全清除完成”消息:

创建一个名为
serversreset.py的文件,并添加以下 Python 脚本:import csv import argparse import requests import urllib3 import json urllib3.disable_warnings() PARSER = argparse.ArgumentParser(prog='secureerase.py', \ description='reset ilo to factory settings') PARSER.add_argument('-csv', '--file', help='choose the csv file', type=str) ARGS = vars(PARSER.parse_args()) headers = {'content-type': 'application/json'} payload = {'SystemROMAndiLOErase': True , 'UserDataErase': True} with open(ARGS['file'], encoding="utf8", mode='r') as csv_file: CSV_READER = csv.DictReader(csv_file) for row in CSV_READER: try: system = requests.post('https://'+row['ip']+'/redfish/v1/Systems/1/Actions/Oem/Hpe/HpeComputerSystemExt.SecureSystemErase/',data=json.dumps(payload),headers=headers,verify=False,auth=('administrator',row['passd'])) systemData = system.json() print(systemData) except Exception as err: print(err)运行以下命令,并将
example.csv替换为您的 CSV 文件:python serversreset.py -csv example.csv运行该命令后,服务器处于关机状态。您必须手动开启服务器电源。
6.5. 重置 NetApp StorageGRID 设备
6.5.1. 前提条件
在重置 NetApp StorageGRID 设备之前,请务必仔细阅读以下内容: - 如果系统已启用节点加密和/或驱动器加密,您必须执行停用 HSM 站点加密中所述的步骤。 否则,请继续重置 StorageGRID 系统。
6.5.2. 在存储控制器节点上停用 StorageGRID HSM 站点加密
如需获取存储控制器节点的 IP(每个存储节点有两个 IP),请执行以下操作:
$ kubectl get objectstoragestoragenodes -n gpc-system -o custom-columns="NAME:metadata.name,COMPUTE_NODEA_IP:.spec.network.controllerAManagementIP,COMPUTE_NODEB_IP:.spec.network.controllerBManagementIP"
NAME COMPUTE_NODEA_IP COMPUTE_NODEB_IP
ak-ac-objs01 172.22.210.166/24 172.22.210.167/24
ak-ac-objs02 172.22.210.170/24 172.22.210.171/24
ak-ac-objs03 172.22.210.174/24 172.22.210.175/24
如果 StorageGRID 系统之前已启用 HSM,则需要先移除加密,然后再继续执行恢复出厂设置。在重置设备之前,请针对每个存储节点执行以下步骤。否则,可能会锁定磁盘和系统。
登录对象存储空间网站,然后前往边栏中显示的节点列表。
点击存储节点的名称。
前往 SANtricity System Manager 标签页。
依次前往设置 > 系统 > 安全密钥管理。

选择停用外部密钥管理,然后输入口令以下载备份密钥。
6.5.3. StorageGRID 管理员节点和存储计算节点恢复出厂设置
如需获取管理员节点的 IP,请执行以下操作:
$ kubectl get objectstorageadminnodes -n gpc-system
NAME SITE NAME MANAGEMENT IP READY AGE
ak-ac-objsadm01 ak-obj-site-1 172.22.210.160/24 True 12d
ak-ac-objsadm02 ak-obj-site-1 172.22.210.162/24 True 12d
如需获取存储计算节点的 IP,请执行以下操作:
$ kubectl get objectstoragestoragenodes -n gpc-system
NAME SITE NAME MANAGEMENT IP READY AGE
ak-ac-objs01 ak-obj-site-1 172.22.210.164/24 True 12d
ak-ac-objs02 ak-obj-site-1 172.22.210.168/24 True 12d
ak-ac-objs03 ak-obj-site-1 172.22.210.172/24 True 12d
如需将 StorageGRID 设备恢复出厂设置,您必须针对站点中的每个节点(存储节点和管理节点)完成以下步骤:
获取每个节点的管理 IP。这可以通过在 cell.yaml 中查找
ObjectStorageStorageNode和ObjectStorageAdminNode来获取。这些信息也可以从根管理员集群中的节点资源中找到。获取密码并使用 SSH 连接到节点:
如果节点未安装 StorageGRID,请分别使用
admin/bycast或root/netapp1!作为用户名和密码。如果 SSH 无法正常运行,请使用 SSH 端口 8022。如果节点已安装 StorageGRID 但未设置网站,请分别使用
admin/bycast或root/bycast作为用户名和密码。如果已设置站点,并且节点是站点的一部分:
获取配置口令。此值存储在名为
grid-secret的 Secret 中,该 Secret 位于 cell.yaml 文件中。(可选)可以运行以下命令。请务必对密码进行 base64 解码:echo $(kubectl get secret -n gpc-system grid-secret -ojsonpath="{.data.grid-management-provisioning-password}" | base64 -d)在对象存储网站界面上,依次前往维护 > 系统 > 恢复软件包,输入配置口令后即可下载恢复软件包。

下载后,提取 tar 文件。该文件将包含另一个 tarball:
GIDXXXXX_REV1_SAID.zip。解压缩该 tarball 以找到Passwords.txt文件。将Password同时用于 SSH 和 root 访问权限,并忽略SSH Access Password。样本文件:
Password Data for Grid ID: 546285, Revision: 1 Revision Prepared on: 2022-06-13 20:49:56 +0000 Server "root" and "admin" Account Passwords Server Name Password SSH Access Password ____________________________________________________________ alatl14-gpcstgeadm01 <removed> <removed> alatl14-gpcstgeadm02 <removed> <removed> alatl14-gpcstgecn01 <removed> n/a alatl14-gpcstgecn02 <removed> n/a alatl14-gpcstgecn03 <removed> n/a
打开节点的串行控制台,或使用 SSH 连接到节点:
ssh -o ProxyCommand=None -o StrictHostKeyChecking=no \ -o UserKnownHostsFile=/dev/null admin@<node-management-ip>输入凭据以登录。如需获得 sudo 权限,请键入
su -,然后输入从第二步中获得的 root 密码。输入命令
sgareinstall,然后按y继续重置设备。如果设备上启用了加密,则在重置完成后,请按照以下步骤删除磁盘池和 SSD 缓存。
6.5.4. 删除存储控制器节点上的磁盘池和 SSD 缓存
如需获取存储控制器节点的 IP(每个存储节点有两个 IP),请执行以下操作:
$ kubectl get objectstoragestoragenodes -n gpc-system -o custom-columns="NAME:metadata.name,COMPUTE_NODEA_IP:.spec.network.controllerAManagementIP,COMPUTE_NODEB_IP:.spec.network.controllerBManagementIP"
NAME COMPUTE_NODEA_IP COMPUTE_NODEB_IP
ak-ac-objs01 172.22.210.166/24 172.22.210.167/24
ak-ac-objs02 172.22.210.170/24 172.22.210.171/24
ak-ac-objs03 172.22.210.174/24 172.22.210.175/24
如果设备上已启用加密,并且节点已按照上一部分中的说明重置,则需要删除磁盘池并擦除驱动器。必须在重新启动网站之前完成此操作,以便网站可以创建新的磁盘池。请针对网站中的每个存储节点(e2860 存储控制器)(也称为 controllerAManagementIP)执行以下步骤:
打开网络浏览器,访问
https://<storage-node-controller-ip>:8443并输入凭据。如果您无法获取 SANtricity 凭据,请按照这些步骤操作。依次前往存储 > 池和卷组。
删除 SSD 缓存:
选择 SSD 缓存以突出显示。
选择不常见任务下拉菜单,然后点击删除。

删除磁盘池:
选择磁盘池以突出显示。
选择不常见任务下拉菜单,然后点击删除。

尝试创建新的磁盘池。系统会显示一个对话框,阻止创建并要求擦除驱动器。

由于未分配的启用安全功能的硬盘无法用于创建池,因此您必须先将其删除。点击是 - 我要选择要在此操作中清除的驱动器单选按钮,然后选择要清除的所有驱动器。确认清除操作,然后点击确定。请勿继续创建新池。
按照移除节点加密部分中所述的步骤操作。
6.5.5. 移除 StorageGRID 管理节点和存储计算节点上的节点加密
如需获取管理员节点的 IP,请执行以下操作:
$ kubectl get objectstorageadminnodes -n gpc-system
NAME SITE NAME MANAGEMENT IP READY AGE
ak-ac-objsadm01 ak-obj-site-1 172.22.210.160/24 True 12d
ak-ac-objsadm02 ak-obj-site-1 172.22.210.162/24 True 12d
如需获取存储计算节点的 IP,请执行以下操作:
$ kr get objectstoragestoragenodes -n gpc-system
NAME SITE NAME MANAGEMENT IP READY AGE
ak-ac-objs01 ak-obj-site-1 172.22.210.164/24 True 12d
ak-ac-objs02 ak-obj-site-1 172.22.210.168/24 True 12d
ak-ac-objs03 ak-obj-site-1 172.22.210.172/24 True 12d
如果设备上已启用加密,并且在按照这些步骤重置节点后,又按照这些步骤删除了磁盘池和 SSD 缓存,请在每个节点上执行以下步骤来移除节点加密:
前往 StorageGRID 设备安装程序界面。
依次前往配置硬件 > 节点加密。
点击清除 KMS 密钥并删除数据。

触发清除操作后,系统会重新启动控制器,这可能需要大约 15 分钟。
6.5.6. 重新安装 StorageGRID
手动重启每个节点。
打开节点的串行控制台,捕获 GRUB 引导加载程序菜单,然后选择 StorageGRID 设备:强制重新安装 StorageGRID。

6.5.7. 获取 SANtricity 凭据
打开与任一 SANtricity 控制器的串行控制台连接。
使用以下凭据登录:
- 用户名:
spri - 密码:
SPRIentry
- 用户名:
登录后,您会看到如下菜单:
Service Interface Main Menu ============================== 1)Display IP Configuration 2)Change IP Configuration 3)Reset Storage Array Administrator Password 4)Display 7-segment LED codes 5)Disable SAML 6)Unlock remote admin account Q)Quit Menu Enter Selection: 3 Are you sure that you want to reset the Storage Array Password ? (Y/N): Y Storage Array Password reset successful登录 SANtricity 控制器,即可重置密码。
6.6. 重置 NetApp ONTAP 设备
6.6.1. 前提条件
在重置 NetApp ONTAP 设备之前,请务必仔细阅读以下内容:
如果系统之前已启用硬件安全模块 (HSM),则必须先执行停用硬件安全模块中所述的步骤,然后再重置 ONTAP 系统。
这是一项破坏性操作,会清除所有 CipherTrust Manager 数据,包括但不限于密钥、备份、备份密钥和系统日志。
确保您拥有所有数据和备份密钥的有效 CipherTrust Manager 备份。
如果嵌入式 HSM 可用,则不会在此操作中重置。
可选:强烈建议在此操作后重新初始化嵌入式 HSM,以将其配置为信任根。
如果使用了远程 PIN 码输入设备 (PED),则必须在完成后重新连接。
此操作最长可能需要 15 分钟才能完成。确保您已准备好备用电源。
6.6.2. 停用硬件安全模块
如果之前使用 HSM 启用了系统,请在重置 ONTAP 系统之前执行以下步骤。否则,可能会锁定磁盘和系统。 在 ONTAP 集群上执行以下命令:
将权限级别设置为高级:
set -privilege advanced列出磁盘正在使用的数据密钥和联邦信息处理标准 (FIPS) 身份验证密钥:
storage encryption disk show对于系统中的每个磁盘,将节点的数据和 FIPS 身份验证密钥 ID 设置回默认 MSID 0x0:
storage encryption disk modify -disk * -fips-key-id 0x0 storage encryption disk modify -disk * -data-key-id 0x0通过以下方式确认操作是否成功:
storage encryption disk show-status重复
show-status命令,直到收到Disks Begun == Disks Done。此输出表示操作已完成。cluster1:: storage encryption disk show-status FIPS Latest Start Execution Disks Disks Disks Node Support Request Timestamp Time (sec) Begun Done Successful ------- ------- -------- ------------------ ---------- ------ ------ ---------- cluster1 true modify 1/18/2022 15:29:38 3 14 5 5 1 entry was displayed.移除外部密钥管理器配置:
如果 HSM 连接已建立,请直接前往步骤 f。如果 HSM 连接中断,请前往步骤 b。
cluster1::> security key-manager external show-status通过运行
set -priv diag进入diag模式。运行以下命令可显示所有卷加密密钥。
debug smdb table kmip_external_key_cache_mdb_v2 show。收集属性
vserver-id。针对所有密钥服务器运行以下命令以删除密钥:
debug smdb table kmip_external_key_cache_mdb_v2 delete -vserver-id <vserver-id> -key-id * -key-server <key-server endpoint>。使用 ONTAP 界面 (UI) 删除所有卷,或从控制台中手动删除卷。
如果从控制台中删除,您必须忽略节点的根卷。这些通常名为
vol0,并且其中一个节点是vserver。以节点作为vserver的任何卷通常不允许删除,也不应删除。如果无法从界面中删除上一步中的
vol0以外的其他卷,请尝试使用 CLI:cluster1::> vol offline -volume volume_to_be_deleted -vserver vserve-id cluster1::> vol delete -volume volume_to_be_deleted -vserver vserver-id如需从界面登录存储集群,请使用以下命令从 Secret 中获取用户名和密码,并将 CELL_ID 替换为您要安装的 Cell 的唯一 ID:
kubectl get secret -n gpc-system ontap-CELL_ID-stge-clus-01-credential -o jsonpath='{.data.netapp_username}' | base64 --decode kubectl get secret -n gpc-system ontap-CELL_ID-stge-clus-01-credential -o jsonpath='{.data.netapp_password}' | base64 --decode然后前往卷,选择所有卷,然后点击删除。您必须针对每个网页重复多次。 注意:您可以放心地忽略有关卷删除失败的错误,详情请参阅 NetApp 知识库。
ag-stge-clus-01::*> vol show Vserver Volume Aggregate State Type Size Available Used% --------- ------------ ------------ ---------- ---- ---------- ---------- ----- ag-ad-stge01-01 vol0 aggr0_ag_ad_stge01_01 online RW 151.3GB 84.97GB 40% ag-ad-stge01-02 vol0 aggr0_ag_ad_stge01_02 online RW 151.3GB 86.69GB 39% ag-ad-stge02-01 vol0 aggr0_ag_ad_stge02_01 online RW 151.3GB 83.62GB 41% ag-ad-stge02-02 vol0 aggr0_ag_ad_stge02_02 online RW 151.3GB 85.97GB 40% ag-ad-stge03-01 vol0 aggr0_ag_ad_stge03_01 online RW 151.3GB 89.19GB 37% ag-ad-stge03-02 vol0 aggr0_ag_ad_stge03_02 online RW 151.3GB 88.74GB 38%
删除所有卷后,运行以下命令以清除恢复队列:
recovery-queue purge-all -vserver <vserver>。运行以下命令以删除外部密钥管理器:
clusterl::> security key-manager external remove-servers -vserver <CLUSTER_NAME> -key-servers <IP1:PORT,IP2:PORT,...>。 完成此步骤后,您可能会收到以下错误:Error: command failed: The key server at "172.22.112.192" contains authentication keys that are currently in use and not available from any other configured key server.此错误表示存在剩余密钥。如需删除剩余的密钥,请按以下步骤操作:
如需列出剩余的密钥,请运行以下命令:
security key-manager key query输出类似于以下示例:
Node: ag-ad-stge01-01 Vserver: ag-stge-clus-01 Key Manager: 172.22.112.192:5696 Key Manager Type: KMIP Key Manager Policy: - Key Tag Key Type Encryption Restored ------------------------------------ -------- ------------ -------- ag-ad-stge01-01 NSE-AK AES-256 true Key ID: 00000000000000000200000000000100454007f1854b3e3f5c90756bc5cfa6cc0000000000000000记下上一个输出中的密钥 ID 值。使用
security key-manager key delete -key-id命令 + 密钥 ID 值删除剩余的密钥:security key-manager key delete -key-id 00000000000000000200000000000100454007f1854b3e3f5c90756bc5cfa6cc0000000000000000重复步骤 i 和 j,以删除其余密钥。完成后,输出类似于以下示例:
ag-stge-clus-01::*> security key-manager key query No matching keys found.6.6.3. 重置 ONTAP 节点
如需重置 ONTAP 节点,请执行以下操作:
在系统提示符处使用
system node reboot命令重启节点,以访问启动菜单。 注意:您可以放心地忽略系统重启警告。示例:
ag-stge-clus-01::> system reboot -node ag-ad-stge03-02 Warning: Are you sure you want to reboot node "ag-ad-stge03-02"? {y|n}: y Error: Could not migrate LIFs away from node: Failed to migrate one or more LIFs away from node "ag-ad-stge03-02". Use the "network interface show -curr-node ag-ad-stge03-02" command to identify LIFs that could not be migrated off that node. Use the "network interface migrate" command to manually migrate the LIFs off the node. Reissue the command with "-skip-lif-migration-before-reboot" to skip the migration and continue with takeover. ag-stge-clus-01::> system reboot -node ag-ad-stge03-02 -skip-lif-migration-before-reboot Warning: Are you sure you want to reboot node "ag-ad-stge03-02"? {y|n}: y Connection to 172.22.115.134 closed.ag-stge-clus-01::> system reboot -node ag-ad-stge02-02 Error: command failed: Taking node "ag-ad-stge02-02" out of service might result in a data service failure and client disruption for the entire cluster. If possible, bring an additional node online to improve the resiliency of the cluster and to ensure continuity of service. Verify the health of the node using the "cluster show" command, then try the command again, or provide "-ignore-quorum-warnings" to bypass this check. ag-stge-clus-01::> system reboot -node ag-ad-stge02-02 -ignore-quorum-warnings Warning: Are you sure you want to reboot node "ag-ad-stge02-02"? {y|n}: y Error: Could not migrate LIFs away from node: Failed to migrate one or more LIFs away from node "ag-ad-stge02-02". Use the "network interface show -curr-node ag-ad-stge02-02" command to identify LIFs that could not be migrated off that node. Use the "network interface migrate" command to manually migrate the LIFs off the node. Reissue the command with "-skip-lif-migration-before-reboot" to skip the migration and continue with takeover. ag-stge-clus-01::> system reboot -node ag-ad-stge02-02 -ignore-quorum-warnings -skip-lif-migration-before-reboot Warning: Are you sure you want to reboot node "ag-ad-stge02-02"? {y|n}: y Connection to 172.22.115.132 closed.如果您位于
LOADER菜单中,请输入boot_ontap以继续执行重新启动。在重新启动过程中,当系统提示时,按Ctrl-C以显示启动菜单。 节点会显示以下启动菜单选项:(1) Normal Boot. (2) Boot without /etc/rc. (3) Change password. (4) Clean configuration and initialize all disks. (5) Maintenance mode boot. (6) Update flash from backup config. (7) Install new software first. (8) Reboot node. (9) Configure Advanced Drive Partitioning Selection (1-9)?选择选项
(9) Configure Advanced Drive Partitioning。 该节点会显示以下选项:* Advanced Drive Partitioning Boot Menu Options * ************************************************* (9a) Destroy aggregates, unpartition all disks and remove their ownership information. (9b) Clean configuration and initialize node with partitioned disks. (9c) Clean configuration and initialize node with whole disks. (9d) Reboot the node. (9e) Return to main boot menu. (9f) Remove disk ownership.选择选项
9a,并在系统要求输入终止符时输入no。 节点在9a后再次显示以下选项:(9a) Unpartition all disks and remove their ownership information. (9b) Clean configuration and initialize node with partitioned disks. (9c) Clean configuration and initialize node with whole disks. (9d) Reboot the node. (9e) Return to main boot menu. ```在继续操作之前,针对集群中存在的所有存储节点运行
9a操作。针对每个节点运行选项
9b,然后输入yes以确认。(9a) Unpartition all disks and remove their ownership information. (9b) Clean configuration and initialize node with partitioned disks. (9c) Clean configuration and initialize node with whole disks. (9d) Reboot the node. (9e) Return to main boot menu.如果存在 HA 对,系统会显示以下消息。确保集群中的所有节点都已完成 9a,然后再在其上运行步骤 9b。
Selection (9a-9f)?: 9b 9b Option (9a) MUST BE COMPLETED on BOTH nodes in an HA pair (and DR/DR-AUX partner nodes if applicable) prior to starting option (9b). Has option (9a) been completed on all the nodes (yes/no)? yes yes
当系统显示
Welcome to the cluster setup wizard消息时,重置即完成。
6.7. 重置 Thales k570
如需重置 Thales k570,请先将 Ciphertrust Manager 恢复出厂设置,然后再重置 Luna HSM 本身。
6.7.1. 系统恢复出厂设置
为 HSM 凭据创建临时工作目录:
TMPPWDDIR=/run/user/$(id --user)/hsm mkdir -p $TMPPWDDIR chmod 700 $TMPPWDDIR建立与 HSM 的 SSH 连接:
export ADMIN_SSH_SECRET_NAME=`kubectl get secrets -n hsm-system -o json | jq .items[].metadata.name | tr -d '"' | grep "ssh"` kubectl get secret $ADMIN_SSH_SECRET_NAME \ --namespace=hsm-system \ --output jsonpath='{.data.ssh-privatekey}' \ | base64 --decode > $TMPPWDDIR/hsm-ssh-privatekey chmod 0600 $TMPPWDDIR/hsm-ssh-privatekey ssh -i $TMPPWDDIR/hsm-ssh-privatekey ksadmin@$HSM_MGMT_IP如果无法实现此操作,请使用串行电缆将电脑连接到控制台端口。在另一个标签页中运行以下命令,以获取
ksadmin密码。export KSADMIN_SECRET_NAME=`kubectl get secrets -n hsm-system -o json | jq .items[]metadata.name | tr -d '"' | grep "ksadmin"` kubectl get secret $KSADMIN_SECRET_NAME \ --namespace=hsm-system \ --output jsonpath='{.data.password}' \ | base64 --decode登录到串行后,您会看到登录提示。输入用户名
ksadmin,然后粘贴上一个命令输出的密码。在运行
factory-reset命令之前:在此期间,请避免重启系统,因为重新连接涉及多次系统重启,且无法撤消。
确保您已准备好备用电源。
运行以下命令以执行恢复出厂设置:
sudo /opt/keysecure/ks_reset_to_factory.sh重置过程大约需要 10 分钟才能完成。
6.7.2. Luna HSM 重置
系统恢复出厂设置不会清除 HSM 中的信任根。运行以下命令以重置 Luna HSM:
在 CipherTrust Manager 主机内,通过 SSH 或串行控制台运行以下命令:
/usr/safenet/lunaclient/bin/lunacmlunacm:> hsm factoryReset从引导加载程序中删除临时工作目录:
rm $TMPPWDDIR
6.8. 重置防火墙
如需了解如何将防火墙恢复出厂设置,请参阅防火墙恢复出厂设置。
6.9. 重置 Cisco 交换机
请按照以下步骤操作,重置 Cisco 交换机。请注意,这些说明也适用于存储空间切换,例如 stgesw。
- 登录到交换机。
写入、擦除和重新加载开关:
write erase reload如果之前已配置开关,并且您有
cellcfg目录可用,则可以改为按照预检清理操作进行。验证交换机是否处于“开机自动配置”(POAP) 状态。
如果交换机已正确重置,则使用控制台服务器连接到交换机时,应会显示以下提示:
Abort Power On Auto Provisioning [yes - continue with normal setup, skip - bypass password and basic configuration, no - continue with Power On Auto Provisioning] (yes/skip/no)[no]:
6.10. 有关重置流程的其他资源
如需详细了解重置流程,请参阅以下资源:
https://docs.netapp.com/us-en/ontap/system-admin/manage-node-boot-menu-task.htmlhttps://docs.netapp.com/us-en/ontap/encryption-at-rest/return-seds-unprotected-mode-task.html