Tempo stimato per il completamento: 4 giorni
Proprietario del componente utilizzabile: HW
Profilo delle competenze: ingegnere del deployment
Completa le seguenti attività per ripristinare i dispositivi e i sistemi in esecuzione nell'ambiente air-gap di Google Distributed Cloud (GDC).
6.1. Sommario
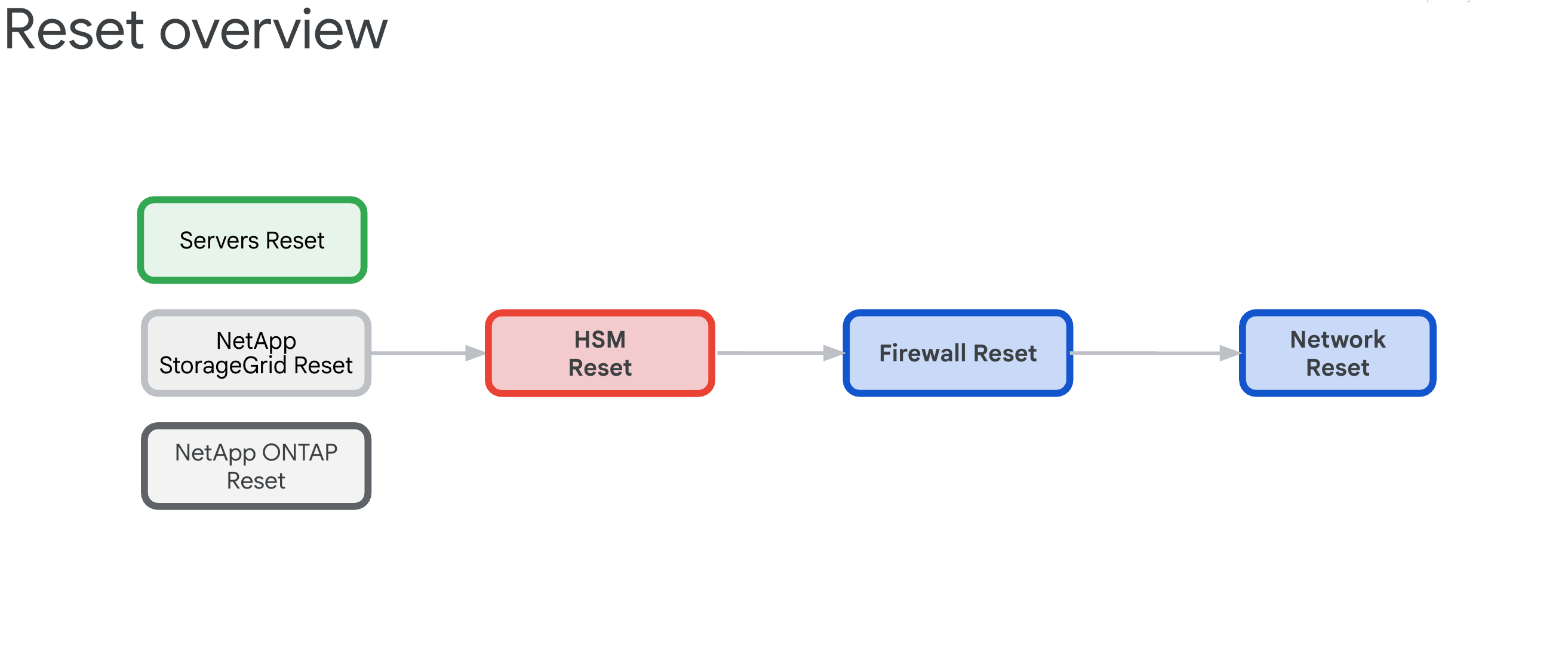
- Panoramica della procedura di ripristino
- HPE Server Reset
- NetApp StorageGRID Reset
- Ripristino di NetApp ONTAP
- Reimpostazione HSM Thales
- Reimpostazione dei firewall Palo Alto
- Cisco Switches Reset
- Risorse aggiuntive
6.2. Prerequisiti e sicurezza
6.2.1. Accesso richiesto
- Accesso fisico: accesso alla sala DC con attrezzatura per carrello di emergenza
- Accesso alla rete: connettività dell'interfaccia di gestione o accesso alla console
- Credenziali: accesso amministratore a tutti i sistemi
- Backup: backup completo di tutti i secret e dei dati di configurazione
6.2.2. Elenco di controllo per la sicurezza
- [ ] Accesso fisico all'infrastruttura
- [ ] I segreti di emergenza sono stati protetti offline
- [ ] Backup dell'infrastruttura (se necessario)
6.3. Panoramica della procedura di reimpostazione
La procedura di ripristino di una zona cella GDC esistente ha lo scopo di liberare tutti gli apparecchi HW da qualsiasi dipendenza e quindi ripristinarne lo stato di fabbrica.
6.3.1. Dipendenze dell'infrastruttura
I componenti hanno le seguenti interdipendenze che determinano l'ordine di ripristino:
- Server, NetApp ONTAP e NetApp StorageGrid si basano sugli appliance HSM Thales, che forniscono le chiavi di crittografia per ILO, dischi, tenant e bucket.
- Gli appliance HSM Thales si basano sulla connettività dei firewall IDP/perimetrali e degli switch Cisco.
- I firewall IDP/perimetrali si basano sull'infrastruttura di rete degli switch Cisco.
- Gli switch Cisco devono essere ripristinati come ultima risorsa, poiché la connettività verrà interrotta dopo il ripristino.
6.3.2. Reset Order (Critical)
Segui questo ordine esatto per evitare blocchi del sistema:
- Server HPE: rimuovi prima le dipendenze HSM
- NetApp StorageGRID: cancella la crittografia e reimposta i nodi
- NetApp ONTAP: disattiva HSM e reimposta il cluster
- Thales HSM - Ripristino dei dati di fabbrica e cancellazione della radice di attendibilità
- Firewall: ripristino dei dati di fabbrica per la configurazione predefinita
- Switch Cisco: ripristina l'ultimo (interromperà la connettività)
6.4. Cancellazione sicura Hewlett Packard Enterprise
Sono disponibili tre tipi di operazioni di ripristino, ognuna delle quali funge da metodo alternativo per la pulizia della configurazione di iLO Key Manager. L'obiettivo principale è rimuovere la dipendenza dal modulo di sicurezza hardware (HSM).
In genere, il ripristino dei dati di fabbrica di ILO è sufficiente per pulire la configurazione KMS. Al successivo bootstrap, il processo di bootstrap del server inizializzerà i parametri del BIOS di impostazione del server, cancellerà i dischi e inizializzerà nuovamente il server.
Questa sezione spiega come eseguire tre tipi di cancellazione:
Questi script di cancellazione utilizzano un file CSV di esempio denominato example.csv.
Prima di continuare, prepara il seguente file CSV:
root@example-bootstrapper:/home/ubuntu/md# cat example.csv
ip,passd
10.251.248.62,XXXXXXXX
10.251.248.64,XXXXXXXX
10.251.248.66,XXXXXXXX
10.251.248.68,XXXXXXXX
10.251.248.70,XXXXXXXX
10.251.248.72,XXXXXXXX
10.251.248.74,XXXXXXXX
10.251.248.76,XXXXXXXX
6.4.1. Ripristino dei dati di fabbrica di iLO
Completa un normale ripristino dei dati di fabbrica di iLO:
Crea un file denominato
serversreset.pye aggiungi il seguente script Python:import csv import argparse import requests import urllib3 import json urllib3.disable_warnings() PARSER = argparse.ArgumentParser(prog='serversreset.py', \ description='reset ilo to factory settings') PARSER.add_argument('-csv', '--file', help='choose the csv file', type=str) ARGS = vars(PARSER.parse_args()) headers = {'content-type': 'application/json'} payload = {'ResetType': 'Default'} url = '/redfish/v1/Managers/1/Actions/Oem/Hpe/HpeiLO.ResetToFactoryDefaults/' with open(ARGS['file'], encoding="utf8", mode='r') as csv_file: CSV_READER = csv.DictReader(csv_file) for row in CSV_READER: try: system = requests.post('https://'+row['ip']+url,data=json.dumps(payload),headers=headers,verify=False,auth=('administrator',row['passd'])) systemData = system.json() print(systemData) except Exception as err: print(err)Esegui il comando seguente e sostituisci
example.csvcon il tuo file CSV:python3 serversreset.py -csv example.csvL'output deve essere simile al seguente:
{'error': {'code': 'iLO.0.10.ExtendedInfo', 'message': 'See @Message.ExtendedInfo for more information.', '@Message.ExtendedInfo': [{'MessageId': 'iLO.2.15.ResetInProgress'}]}} {'error': {'code': 'iLO.0.10.ExtendedInfo', 'message': 'See @Message.ExtendedInfo for more information.', '@Message.ExtendedInfo': [{'MessageId': 'iLO.2.15.ResetInProgress'}]}} {'error': {'code': 'iLO.0.10.ExtendedInfo', 'message': 'See @Message.ExtendedInfo for more information.', '@Message.ExtendedInfo': [{'MessageId': 'iLO.2.15.ResetInProgress'}]}}
6.4.2. Passaggi manuali aggiuntivi di iLO
Esegui un ripristino manuale di iLO utilizzando l'interfaccia utente iLO:
Seleziona iLO > Amministrazione > Key Manager > Elimina impostazioni.
Nella console BIOS, seleziona System Utilities > System Configuration > Embedded Raid > Administration > Reset To Default.
Imposta le interfacce su netboot solo per LOM1. Tutti i nodi GPU NON hanno schede LOM1, ma schede Intel.
Imposta la rete iLO su DHCP.
6.4.3. Reimpostazione del BIOS
Segui questi passaggi per eseguire un ripristino del BIOS:
Crea un file denominato
biosreset.pye aggiungi il seguente script Python:import csv import argparse import requests import urllib3 import json urllib3.disable_warnings() PARSER = argparse.ArgumentParser(prog='biosreset.py', \ description='reset BIOS to factory settings') PARSER.add_argument('-csv', '--file', help='choose the csv file', type=str) ARGS = vars(PARSER.parse_args()) headers = {'content-type': 'application/json'} payload = {} with open(ARGS['file'], encoding="utf8", mode='r') as csv_file: CSV_READER = csv.DictReader(csv_file) for row in CSV_READER: try: system = requests.post('https://'+row['ip']+'/redfish/v1/systems/1/bios/Actions/Bios.ResetBios/',data=json.dumps(payload),headers=headers,verify=False,auth=('administrator',row['passd'])) systemData = system.json() print(systemData) except Exception as err: print(err)Esegui il comando seguente e sostituisci
example.csvcon il tuo file CSV:python3 biosreset.py -csv example.csvL'output deve essere simile al seguente:
{'error': {'code': 'iLO.0.10.ExtendedInfo', 'message': 'See @Message.ExtendedInfo for more information.', '@Message.ExtendedInfo': [{'MessageId': 'iLO.2.15.SystemResetRequired'}]}}Dopo aver eseguito il comando, i server sono in stato di accensione. Devi eseguire il seguente script per spegnere tutti i server:
import csv import argparse import requests import urllib3 import json urllib3.disable_warnings() PARSER = argparse.ArgumentParser(prog='power-ilo.py', \ description='power off server') PARSER.add_argument('-csv', '--file', help='choose the csv file', type=str) ARGS = vars(PARSER.parse_args()) headers = {'content-type': 'application/json'} payload = {'ResetType': 'PushPowerButton'} with open(ARGS['file'], encoding="utf8", mode='r') as csv_file: CSV_READER = csv.DictReader(csv_file) for row in CSV_READER: try: system = requests.post( 'https://' + row['ip'] + '/redfish/v1/systems/1/Actions/ComputerSystem.Reset/', data=json.dumps(payload), headers=headers, verify=False, auth=('administrator', row['passd'])) systemData = system.json() if 'Success' in systemData['error']['@Message.ExtendedInfo'][0][ 'MessageId']: print(f"ilo with ip {row['ip']} succeeded") #print(systemData) else: print(f"ilo with ip {row['ip']} failed") print(systemData) except Exception as err: print(err)Spegni manualmente i server:
python3 power-ilo.py -csv ~/servers.csv- (Facoltativo) Per controllare lo stato, utilizza il seguente script:
import csv import argparse import requests import urllib3 import json urllib3.disable_warnings() PARSER = argparse.ArgumentParser(prog='ilostatus.py', \ description='check power status of server') PARSER.add_argument('-csv', '--file', help='choose the csv file', type=str) ARGS = vars(PARSER.parse_args()) headers = {'content-type': 'application/json'} with open(ARGS['file'], encoding="utf8", mode='r') as csv_file: CSV_READER = csv.DictReader(csv_file) for row in CSV_READER: try: system = requests.get('https://'+row['ip']+'/redfish/v1/Systems/1',headers=headers,verify=False,auth=('administrator',row['passd'])) systemData = system.json() print(f"ilo with ip {row['ip']} has power status of {systemData['PowerState']}") if 'Success' in systemData['error']['@Message.ExtendedInfo'][0]['MessageId']: print(f"ilo with ip {row['ip']} succeeded") print(systemData) else: print(f"ilo with ip {row['ip']} failed") print(systemData) except Exception as err: passEsegui questo comando:
python3 ilostatus.py -csv ~/servers.csvL'output deve essere simile al seguente:
ilo with ip 172.22.112.96 has power status of Off ilo with ip 172.22.112.97 has power status of Off ilo with ip 172.22.112.98 has power status of Off ilo with ip 172.22.112.100 has power status of Off ilo with ip 172.22.112.101 has power status of Off ilo with ip 172.22.112.102 has power status of Off6.4.4. Cancellazione sicura
Premi F10 nella schermata POST del server. Viene avviato Intelligent Provisioning.
Dopo l'avvio di Intelligent Provisioning, fai clic sulla freccia giù accanto a Procedura guidata di configurazione iniziale per saltare la procedura guidata.
Salta la richiesta della procedura guidata e fai clic su Sì.
Fai clic su Esegui manutenzione.
Fai clic su One Button Secure Erase.
Un messaggio indica che non disponi di privilegi sufficienti. Fai clic su Accedi e inserisci le credenziali amministratore.
Fai clic su Fine.
Fai clic su Invia.
Conferma di voler eseguire la cancellazione sicura, quindi digita ERASE.
Fai clic su CANCELLA.
Fai clic su Yes (Sì) per confermare.
Fai clic su Avvia ora nella sezione Coda dei job.
In circa 2 minuti o meno, segui il prompt per fare clic su Ok.
La macchina si riavvia, non toccare nulla per circa 10-15 minuti.
Al termine della cancellazione sicura, torna al BIOS facendo clic su F9 durante l'avvio del POST.
Vai a Embedded Applications (Applicazioni incorporate) > Integrated Management Log (IML) (Log di gestione integrato) > View IML (Visualizza IML) > OK. Viene visualizzato il messaggio Cancellazione sicura con un solo pulsante completata:

Crea un file denominato
serversreset.pye aggiungi il seguente script Python:import csv import argparse import requests import urllib3 import json urllib3.disable_warnings() PARSER = argparse.ArgumentParser(prog='secureerase.py', \ description='reset ilo to factory settings') PARSER.add_argument('-csv', '--file', help='choose the csv file', type=str) ARGS = vars(PARSER.parse_args()) headers = {'content-type': 'application/json'} payload = {'SystemROMAndiLOErase': True , 'UserDataErase': True} with open(ARGS['file'], encoding="utf8", mode='r') as csv_file: CSV_READER = csv.DictReader(csv_file) for row in CSV_READER: try: system = requests.post('https://'+row['ip']+'/redfish/v1/Systems/1/Actions/Oem/Hpe/HpeComputerSystemExt.SecureSystemErase/',data=json.dumps(payload),headers=headers,verify=False,auth=('administrator',row['passd'])) systemData = system.json() print(systemData) except Exception as err: print(err)Esegui il comando seguente e sostituisci
example.csvcon il tuo file CSV:python serversreset.py -csv example.csvDopo aver eseguito il comando, i server sono in stato di spegnimento. Devi accendere manualmente il server.
6.5. Reimposta il dispositivo NetApp StorageGRID
6.5.1. Prerequisiti
Prima di resettare il dispositivo NetApp StorageGRID, assicurati di leggere quanto segue: - Se il sistema è stato abilitato con la crittografia dei nodi e/o delle unità, devi eseguire i passaggi descritti in Disattivare la crittografia del sito HSM. In caso contrario, vai a reimpostare il sistema StorageGRID.
6.5.2. Disattiva la crittografia del sito HSM StorageGRID sui nodi del controller di archiviazione
Per ottenere gli IP dei nodi del controller di archiviazione (due IP per ogni nodo di archiviazione):
$ kubectl get objectstoragestoragenodes -n gpc-system -o custom-columns="NAME:metadata.name,COMPUTE_NODEA_IP:.spec.network.controllerAManagementIP,COMPUTE_NODEB_IP:.spec.network.controllerBManagementIP"
NAME COMPUTE_NODEA_IP COMPUTE_NODEB_IP
ak-ac-objs01 172.22.210.166/24 172.22.210.167/24
ak-ac-objs02 172.22.210.170/24 172.22.210.171/24
ak-ac-objs03 172.22.210.174/24 172.22.210.175/24
Se il sistema StorageGRID è stato precedentemente abilitato con HSM, la crittografia deve essere rimossa prima di procedere al ripristino dei dati di fabbrica. Esegui questi passaggi per ogni nodo di archiviazione prima di ripristinare il dispositivo. In caso contrario, i dischi e il sistema potrebbero bloccarsi.
Accedi al sito di Object Storage e vai all'elenco dei nodi nella barra laterale.
Fai clic sul nome del nodo di archiviazione.
Vai alla scheda SANtricity System Manager.
Vai a Impostazioni > Sistema > Gestione delle chiavi di sicurezza.

Seleziona Disattiva gestione delle chiavi esterna e digita la passphrase per scaricare la token di backup.
6.5.3. Ripristino dei dati di fabbrica del nodo di amministrazione StorageGRID e del nodo di calcolo di archiviazione
Per ottenere gli IP dei nodi di amministrazione:
$ kubectl get objectstorageadminnodes -n gpc-system
NAME SITE NAME MANAGEMENT IP READY AGE
ak-ac-objsadm01 ak-obj-site-1 172.22.210.160/24 True 12d
ak-ac-objsadm02 ak-obj-site-1 172.22.210.162/24 True 12d
Per ottenere gli IP dei nodi di computing di archiviazione:
$ kubectl get objectstoragestoragenodes -n gpc-system
NAME SITE NAME MANAGEMENT IP READY AGE
ak-ac-objs01 ak-obj-site-1 172.22.210.164/24 True 12d
ak-ac-objs02 ak-obj-site-1 172.22.210.168/24 True 12d
ak-ac-objs03 ak-obj-site-1 172.22.210.172/24 True 12d
Per ripristinare i dati di fabbrica del dispositivo StorageGRID, devi completare i seguenti passaggi per ogni nodo (sia di archiviazione che di amministrazione) del sito:
Recupera gli IP di gestione per ogni nodo. Può essere ottenuto da cell.yaml, cercando
ObjectStorageStorageNodeeObjectStorageAdminNode. Questi possono essere trovati anche nelle risorse dei nodi nel cluster di amministrazione principale.Recupera la password e connettiti al nodo utilizzando SSH:
Se sul nodo non è installato StorageGRID, utilizza
admin/bycastoroot/netapp1!come nome utente e password, rispettivamente. Se SSH non funziona, utilizza la porta SSH 8022.Se sul nodo è installato StorageGRID, ma non è stata configurata alcuna sede, utilizza
admin/bycastoroot/bycastcome nome utente e password, rispettivamente.Se il sito è configurato e il nodo fa parte del sito:
Recupera la passphrase di provisioning. Queste informazioni vengono memorizzate in un secret denominato
grid-secret, che si trova nel file cell.yaml. (Facoltativo) puoi eseguire il seguente comando. Assicurati di decodificare in Base64 la password:echo $(kubectl get secret -n gpc-system grid-secret -ojsonpath="{.data.grid-management-provisioning-password}" | base64 -d)Nell'interfaccia utente del sito di Object Storage, vai a Maintenance > System > Recovery package per scaricare il pacchetto di ripristino dopo aver inserito la passphrase di provisioning.

Dopo il download, estrai il file tar. Questo conterrà un altro tarball:
GIDXXXXX_REV1_SAID.zip. Estrai il tarball per trovare il filePasswords.txt. UtilizzaPasswordsia per l'accesso SSH che per l'accesso root e ignoraSSH Access Password.File di esempio:
Password Data for Grid ID: 546285, Revision: 1 Revision Prepared on: 2022-06-13 20:49:56 +0000 Server "root" and "admin" Account Passwords Server Name Password SSH Access Password ____________________________________________________________ alatl14-gpcstgeadm01 <removed> <removed> alatl14-gpcstgeadm02 <removed> <removed> alatl14-gpcstgecn01 <removed> n/a alatl14-gpcstgecn02 <removed> n/a alatl14-gpcstgecn03 <removed> n/a
Apri una console seriale per il nodo o connettiti al nodo utilizzando SSH:
ssh -o ProxyCommand=None -o StrictHostKeyChecking=no \ -o UserKnownHostsFile=/dev/null admin@<node-management-ip>Inserisci le credenziali per accedere. Per ottenere i privilegi sudo, digita
su -e inserisci la password root ottenuta dal secondo passaggio.Inserisci il comando
sgareinstalle premiyper continuare a ripristinare il dispositivo.Se la crittografia è stata attivata sul dispositivo, al termine del ripristino segui questi passaggi per eliminare i pool di dischi e la cache SSD.
6.5.4. Elimina i pool di dischi e la cache SSD sui nodi del controller di archiviazione
Per ottenere gli IP dei nodi del controller di archiviazione (due IP per ogni nodo di archiviazione):
$ kubectl get objectstoragestoragenodes -n gpc-system -o custom-columns="NAME:metadata.name,COMPUTE_NODEA_IP:.spec.network.controllerAManagementIP,COMPUTE_NODEB_IP:.spec.network.controllerBManagementIP"
NAME COMPUTE_NODEA_IP COMPUTE_NODEB_IP
ak-ac-objs01 172.22.210.166/24 172.22.210.167/24
ak-ac-objs02 172.22.210.170/24 172.22.210.171/24
ak-ac-objs03 172.22.210.174/24 172.22.210.175/24
Se la crittografia è stata attivata sul dispositivo e i nodi sono stati reimpostati dopo aver seguito l'ultima sezione, i pool di dischi devono essere eliminati insieme all'eliminazione delle unità. Questa operazione deve essere eseguita prima del riavvio del sito in modo che possa creare nuovi pool di dischi. Segui questi passaggi per ogni nodo di archiviazione (controller di archiviazione e2860) nel sito (noto anche come controllerAManagementIP):
Apri un browser web per visitare
https://<storage-node-controller-ip>:8443e inserisci le credenziali. Se non hai accesso alle credenziali SANtricity, segui questi passaggi.Vai a Storage > Pool e gruppi di volumi.
Elimina cache SSD:
Seleziona la cache SSD per evidenziarla.
Seleziona il menu a discesa Attività insolite e fai clic su Elimina.

Elimina il pool di dischi:
Seleziona il pool di dischi per evidenziarlo.
Seleziona il menu a discesa Attività insolite e fai clic su Elimina.

Prova a creare un nuovo pool di dischi. Viene visualizzata una finestra di dialogo che blocca la creazione e chiede di cancellare le unità.

Poiché le unità abilitate alla sicurezza non assegnate non possono essere utilizzate per la creazione di pool, devi prima eliminarle. Fai clic sul pulsante di opzione Sì, voglio selezionare le unità da cancellare per l'operazione, quindi seleziona tutte le unità da cancellare. Conferma l'operazione di cancellazione e fai clic su Ok. Non procedere con la creazione di un nuovo pool.
Segui i passaggi descritti nella sezione relativa alla rimozione della crittografia dei nodi.
6.5.5. Rimuovere la crittografia dei nodi sui nodi di amministrazione StorageGRID e sui nodi di calcolo di archiviazione
Per ottenere gli IP dei nodi di amministrazione:
$ kubectl get objectstorageadminnodes -n gpc-system
NAME SITE NAME MANAGEMENT IP READY AGE
ak-ac-objsadm01 ak-obj-site-1 172.22.210.160/24 True 12d
ak-ac-objsadm02 ak-obj-site-1 172.22.210.162/24 True 12d
Per ottenere gli IP dei nodi di computing di archiviazione:
$ kr get objectstoragestoragenodes -n gpc-system
NAME SITE NAME MANAGEMENT IP READY AGE
ak-ac-objs01 ak-obj-site-1 172.22.210.164/24 True 12d
ak-ac-objs02 ak-obj-site-1 172.22.210.168/24 True 12d
ak-ac-objs03 ak-obj-site-1 172.22.210.172/24 True 12d
Se la crittografia è stata attivata sul dispositivo e i nodi sono stati reimpostati dopo aver seguito questa procedura e i pool di dischi e la cache SSD sono stati eliminati con questa procedura, esegui i seguenti passaggi su ogni nodo per rimuovere la crittografia del nodo:
Vai all'interfaccia utente di StorageGRID Appliance Installer.
Vai a Configura hardware > Crittografia dei nodi.
Fai clic su Cancella chiave KMS ed elimina dati.

Una volta attivata la cancellazione, il controller verrà riavviato e l'operazione può richiedere circa 15 minuti.
6.5.6. Reinstalla StorageGRID
Riavvia manualmente ogni nodo.
Apri una console seriale per il nodo, visualizza il menu del bootloader GRUB e seleziona StorageGRID Appliance: Force StorageGRID reinstall.

6.5.7. Ottenere le credenziali SANtricity
Apri una console seriale per uno qualsiasi dei controller SANtricity.
Utilizza le seguenti credenziali per accedere:
- nome utente:
spri - password:
SPRIentry
- nome utente:
Una volta effettuato l'accesso, vedrai un menu come questo:
Service Interface Main Menu ============================== 1)Display IP Configuration 2)Change IP Configuration 3)Reset Storage Array Administrator Password 4)Display 7-segment LED codes 5)Disable SAML 6)Unlock remote admin account Q)Quit Menu Enter Selection: 3 Are you sure that you want to reset the Storage Array Password ? (Y/N): Y Storage Array Password reset successfulAccedi ai controller SANtricity e il ripristino della password sarà disponibile.
6.6. Reimpostare il dispositivo NetApp ONTAP
6.6.1. Prerequisiti
Prima di ripristinare il dispositivo NetApp ONTAP, assicurati di leggere quanto segue:
Se il sistema è stato precedentemente abilitato con un modulo di sicurezza hardware (HSM), devi eseguire i passaggi descritti in Disattivare il modulo di sicurezza hardware prima di reimpostare i sistemi ONTAP.
Si tratta di un'operazione distruttiva che cancella tutti i dati di CipherTrust Manager, inclusi, a titolo esemplificativo, chiavi, backup, chiavi di backup e log di sistema.
Assicurati di avere un backup valido di CipherTrust Manager di tutti i dati e delle chiavi di backup.
Se è disponibile un HSM incorporato, non viene reimpostato nell'ambito di questa operazione.
(Facoltativo) La reinizializzazione di un HSM incorporato è vivamente consigliata dopo questa operazione per configurarlo come radice di attendibilità.
Se è stato utilizzato un dispositivo di inserimento del PIN (PED) remoto, questo deve essere ricollegato al termine dell'operazione.
Questa operazione potrebbe richiedere fino a 15 minuti. Assicurati di avere un sistema di alimentazione di backup.
6.6.2. Disattivare il modulo di sicurezza hardware
Se il sistema è stato attivato in precedenza utilizzando un HSM, esegui questi passaggi prima di reimpostare i sistemi ONTAP. In caso contrario, i dischi e il sistema potrebbero bloccarsi. Esegui questi comandi sul cluster ONTAP:
Imposta il livello di privilegio su avanzato:
set -privilege advancedElenca la chiave dei dati del disco e le chiavi di autenticazione Federal Information Processing Standards (FIPS) che utilizza:
storage encryption disk showPer ogni disco del sistema, imposta l'ID chiave di autenticazione dei dati e FIPS per il nodo sul valore predefinito MSID 0x0:
storage encryption disk modify -disk * -fips-key-id 0x0 storage encryption disk modify -disk * -data-key-id 0x0Conferma che l'operazione sia riuscita con quanto segue:
storage encryption disk show-statusRipeti il comando
show-statusfinché non riceviDisks Begun == Disks Done. Questo output indica che l'operazione è stata completata.cluster1:: storage encryption disk show-status FIPS Latest Start Execution Disks Disks Disks Node Support Request Timestamp Time (sec) Begun Done Successful ------- ------- -------- ------------------ ---------- ------ ------ ---------- cluster1 true modify 1/18/2022 15:29:38 3 14 5 5 1 entry was displayed.Rimuovi la configurazione del gestore di chiavi esterno:
Se la connessione HSM è attiva, vai direttamente al passaggio f. Se la connessione HSM non funziona, vai al passaggio b.
cluster1::> security key-manager external show-statusPassa alla modalità
diageseguendoset -priv diag.Esegui questo comando per mostrare tutte le chiavi di crittografia del volume.
debug smdb table kmip_external_key_cache_mdb_v2 show.Raccogli la proprietà
vserver-id.Esegui questo comando per tutti i server delle chiavi per eliminare le chiavi:
debug smdb table kmip_external_key_cache_mdb_v2 delete -vserver-id <vserver-id> -key-id * -key-server <key-server endpoint>.Elimina tutti i volumi utilizzando l'interfaccia utente (UI) di ONTAP o elimina manualmente i volumi dalla console.
Se elimini i volumi dalla console, devi ignorare i volumi root per i nodi. Di solito hanno il nome
vol0e uno dei nodi èvserver. In genere, non è consentito eliminare i volumi con un nodo comevservere non devono essere eliminati.Se non è possibile eliminare altri volumi diversi da
vol0, dal passaggio precedente, dall'interfaccia utente, prova a utilizzare la CLI:cluster1::> vol offline -volume volume_to_be_deleted -vserver vserve-id cluster1::> vol delete -volume volume_to_be_deleted -vserver vserver-idPer accedere a un cluster di archiviazione dalla UI, recupera il nome utente e la password dal secret con i seguenti comandi, sostituendo CELL_ID con l'ID univoco della cella che stai installando:
kubectl get secret -n gpc-system ontap-CELL_ID-stge-clus-01-credential -o jsonpath='{.data.netapp_username}' | base64 --decode kubectl get secret -n gpc-system ontap-CELL_ID-stge-clus-01-credential -o jsonpath='{.data.netapp_password}' | base64 --decodePoi vai a Volumi, seleziona tutti i volumi e fai clic su Elimina. Devi ripetere l'operazione più volte per ogni pagina. Nota: puoi ignorare in sicurezza un errore relativo all'eliminazione di un volume. Per maggiori dettagli, consulta la knowledge base di NetApp.
ag-stge-clus-01::*> vol show Vserver Volume Aggregate State Type Size Available Used% --------- ------------ ------------ ---------- ---- ---------- ---------- ----- ag-ad-stge01-01 vol0 aggr0_ag_ad_stge01_01 online RW 151.3GB 84.97GB 40% ag-ad-stge01-02 vol0 aggr0_ag_ad_stge01_02 online RW 151.3GB 86.69GB 39% ag-ad-stge02-01 vol0 aggr0_ag_ad_stge02_01 online RW 151.3GB 83.62GB 41% ag-ad-stge02-02 vol0 aggr0_ag_ad_stge02_02 online RW 151.3GB 85.97GB 40% ag-ad-stge03-01 vol0 aggr0_ag_ad_stge03_01 online RW 151.3GB 89.19GB 37% ag-ad-stge03-02 vol0 aggr0_ag_ad_stge03_02 online RW 151.3GB 88.74GB 38%
Dopo aver eliminato tutti i volumi, esegui questo comando per eliminare la coda di ripristino:
recovery-queue purge-all -vserver <vserver>.Esegui questo comando per eliminare il gestore delle chiavi esterno:
clusterl::> security key-manager external remove-servers -vserver <CLUSTER_NAME> -key-servers <IP1:PORT,IP2:PORT,...>. Dopo questo passaggio, potresti ricevere il seguente errore:Error: command failed: The key server at "172.22.112.192" contains authentication keys that are currently in use and not available from any other configured key server.Questo errore indica la presenza di chiavi rimanenti. Per eliminare le chiavi rimanenti:
Per elencare le chiavi rimanenti, esegui il comando seguente:
security key-manager key queryL'output è simile al seguente:
Node: ag-ad-stge01-01 Vserver: ag-stge-clus-01 Key Manager: 172.22.112.192:5696 Key Manager Type: KMIP Key Manager Policy: - Key Tag Key Type Encryption Restored ------------------------------------ -------- ------------ -------- ag-ad-stge01-01 NSE-AK AES-256 true Key ID: 00000000000000000200000000000100454007f1854b3e3f5c90756bc5cfa6cc0000000000000000Prendi nota del valore ID chiave dell'output precedente. Utilizza il comando
security key-manager key delete -key-id+ il valore ID chiave per eliminare le chiavi rimanenti:security key-manager key delete -key-id 00000000000000000200000000000100454007f1854b3e3f5c90756bc5cfa6cc0000000000000000Ripeti i passaggi i e j per eliminare le chiavi rimanenti. Al termine, l'output è simile al seguente esempio:
ag-stge-clus-01::*> security key-manager key query No matching keys found.6.6.3. Reimposta i nodi ONTAP
Per reimpostare i nodi ONTAP:
Riavvia il nodo per accedere al menu di avvio utilizzando il comando
system node rebootal prompt del sistema. Nota: puoi ignorare tranquillamente gli avvisi di riavvio del sistema.Esempi:
ag-stge-clus-01::> system reboot -node ag-ad-stge03-02 Warning: Are you sure you want to reboot node "ag-ad-stge03-02"? {y|n}: y Error: Could not migrate LIFs away from node: Failed to migrate one or more LIFs away from node "ag-ad-stge03-02". Use the "network interface show -curr-node ag-ad-stge03-02" command to identify LIFs that could not be migrated off that node. Use the "network interface migrate" command to manually migrate the LIFs off the node. Reissue the command with "-skip-lif-migration-before-reboot" to skip the migration and continue with takeover. ag-stge-clus-01::> system reboot -node ag-ad-stge03-02 -skip-lif-migration-before-reboot Warning: Are you sure you want to reboot node "ag-ad-stge03-02"? {y|n}: y Connection to 172.22.115.134 closed.ag-stge-clus-01::> system reboot -node ag-ad-stge02-02 Error: command failed: Taking node "ag-ad-stge02-02" out of service might result in a data service failure and client disruption for the entire cluster. If possible, bring an additional node online to improve the resiliency of the cluster and to ensure continuity of service. Verify the health of the node using the "cluster show" command, then try the command again, or provide "-ignore-quorum-warnings" to bypass this check. ag-stge-clus-01::> system reboot -node ag-ad-stge02-02 -ignore-quorum-warnings Warning: Are you sure you want to reboot node "ag-ad-stge02-02"? {y|n}: y Error: Could not migrate LIFs away from node: Failed to migrate one or more LIFs away from node "ag-ad-stge02-02". Use the "network interface show -curr-node ag-ad-stge02-02" command to identify LIFs that could not be migrated off that node. Use the "network interface migrate" command to manually migrate the LIFs off the node. Reissue the command with "-skip-lif-migration-before-reboot" to skip the migration and continue with takeover. ag-stge-clus-01::> system reboot -node ag-ad-stge02-02 -ignore-quorum-warnings -skip-lif-migration-before-reboot Warning: Are you sure you want to reboot node "ag-ad-stge02-02"? {y|n}: y Connection to 172.22.115.132 closed.Se ti trovi nel menu
LOADER, inserisciboot_ontapper procedere con il riavvio. Durante la procedura di riavvio, premiCtrl-Cper visualizzare il menu di avvio quando ti viene richiesto. Il nodo mostra le seguenti opzioni per il menu di avvio:(1) Normal Boot. (2) Boot without /etc/rc. (3) Change password. (4) Clean configuration and initialize all disks. (5) Maintenance mode boot. (6) Update flash from backup config. (7) Install new software first. (8) Reboot node. (9) Configure Advanced Drive Partitioning Selection (1-9)?Seleziona l'opzione
(9) Configure Advanced Drive Partitioning. Il nodo mostra le seguenti opzioni:* Advanced Drive Partitioning Boot Menu Options * ************************************************* (9a) Destroy aggregates, unpartition all disks and remove their ownership information. (9b) Clean configuration and initialize node with partitioned disks. (9c) Clean configuration and initialize node with whole disks. (9d) Reboot the node. (9e) Return to main boot menu. (9f) Remove disk ownership.Seleziona l'opzione
9ae inseriscinoquando ti viene chiesto di terminare. Il nodo mostra di nuovo l'opzione seguente dopo9a:(9a) Unpartition all disks and remove their ownership information. (9b) Clean configuration and initialize node with partitioned disks. (9c) Clean configuration and initialize node with whole disks. (9d) Reboot the node. (9e) Return to main boot menu. ```Esegui l'operazione
9aper tutti i nodi di archiviazione esistenti nel cluster prima di procedere.Per ogni nodo, esegui l'opzione
9be inserisciyesper confermare.(9a) Unpartition all disks and remove their ownership information. (9b) Clean configuration and initialize node with partitioned disks. (9c) Clean configuration and initialize node with whole disks. (9d) Reboot the node. (9e) Return to main boot menu.Se esiste una coppia HA, viene visualizzato il seguente messaggio. Assicurati che tutti i nodi del cluster abbiano completato il passaggio 9a prima di eseguire il passaggio 9b.
Selection (9a-9f)?: 9b 9b Option (9a) MUST BE COMPLETED on BOTH nodes in an HA pair (and DR/DR-AUX partner nodes if applicable) prior to starting option (9b). Has option (9a) been completed on all the nodes (yes/no)? yes yes
Quando viene visualizzato il messaggio
Welcome to the cluster setup wizard, la reimpostazione è completata.
6.7. Reimpostare Thales k570
Per ripristinare Thales k570, inizia con il ripristino dei dati di fabbrica di Ciphertrust Manager e prosegui con il ripristino dell'HSM Luna.
6.7.1. Ripristino dei dati di fabbrica del sistema
Crea una directory di lavoro temporanea per le credenziali HSM:
TMPPWDDIR=/run/user/$(id --user)/hsm mkdir -p $TMPPWDDIR chmod 700 $TMPPWDDIRStabilisci una connessione SSH all'HSM:
export ADMIN_SSH_SECRET_NAME=`kubectl get secrets -n hsm-system -o json | jq .items[].metadata.name | tr -d '"' | grep "ssh"` kubectl get secret $ADMIN_SSH_SECRET_NAME \ --namespace=hsm-system \ --output jsonpath='{.data.ssh-privatekey}' \ | base64 --decode > $TMPPWDDIR/hsm-ssh-privatekey chmod 0600 $TMPPWDDIR/hsm-ssh-privatekey ssh -i $TMPPWDDIR/hsm-ssh-privatekey ksadmin@$HSM_MGMT_IPSe non è possibile, connettiti utilizzando un cavo seriale dal computer alla porta della console. Esegui questo comando in un'altra scheda per ottenere la password di
ksadmin.export KSADMIN_SECRET_NAME=`kubectl get secrets -n hsm-system -o json | jq .items[]metadata.name | tr -d '"' | grep "ksadmin"` kubectl get secret $KSADMIN_SECRET_NAME \ --namespace=hsm-system \ --output jsonpath='{.data.password}' \ | base64 --decodeUna volta eseguito l'accesso alla porta seriale, viene visualizzato un prompt di accesso. Inserisci il nome utente come
ksadmine incolla la password del comando precedente.Prima di eseguire il comando
factory-reset:Evita di riavviare il sistema durante questo periodo, poiché la riconnessione comporta il riavvio multiplo del sistema e non può essere annullata.
Assicurati di avere un gruppo di continuità.
Esegui questo comando per eseguire il ripristino dei dati di fabbrica:
sudo /opt/keysecure/ks_reset_to_factory.shIl completamento della procedura di ripristino richiede circa 10 minuti.
6.7.2. Reimpostazione di Luna HSM
Il ripristino dei dati di fabbrica del sistema non cancella la radice di attendibilità dagli HSM. Esegui i seguenti comandi per reimpostare Luna HSM:
Dall'interno dell'host CipherTrust Manager, tramite SSH o la console seriale, esegui il seguente comando:
/usr/safenet/lunaclient/bin/lunacmlunacm:> hsm factoryResetElimina la directory di lavoro temporanea dal bootstrapper:
rm $TMPPWDDIR
6.8. Reimposta firewall
Per istruzioni su come ripristinare le impostazioni di fabbrica dei firewall, vedi Ripristino dei dati di fabbrica del firewall.
6.9. Reimposta gli switch Cisco
Segui questi passaggi per eseguire il ripristino degli switch Cisco. Tieni presente che queste istruzioni si applicano anche ai cambi di spazio di archiviazione come stgesw.
- Accedi agli interruttori.
Scrivi, cancella e ricarica gli interruttori:
write erase reloadSe i sensori sono stati configurati in precedenza e hai a disposizione una directory
cellcfg, puoi seguire la procedura di pulizia pre-volo.Verifica che gli switch siano in Power On Auto Provisioning (POAP).
Se lo switch viene ripristinato correttamente, quando ti connetti utilizzando il server della console dovrebbe essere visualizzato il seguente prompt:
Abort Power On Auto Provisioning [yes - continue with normal setup, skip - bypass password and basic configuration, no - continue with Power On Auto Provisioning] (yes/skip/no)[no]:
6.10. Risorse aggiuntive sulla procedura di ripristino
Per saperne di più sulla procedura di ripristino, consulta le seguenti risorse:
https://docs.netapp.com/us-en/ontap/system-admin/manage-node-boot-menu-task.htmlhttps://docs.netapp.com/us-en/ontap/encryption-at-rest/return-seds-unprotected-mode-task.html