Durée estimée : quatre jours
Propriétaire du composant exploitable : matériel
Profil de compétences : ingénieur de déploiement
Effectuez les tâches suivantes pour réinitialiser les appareils et les systèmes exécutés dans l'environnement isolé Google Distributed Cloud (GDC).
6.1. Sommaire
- Présentation de la procédure de réinitialisation
- Réinitialisation du serveur HPE
- Réinitialisation de NetApp StorageGRID
- Réinitialisation de NetApp ONTAP
- Réinitialisation de Thales HSM
- Réinitialisation des pare-feu Palo Alto
- Réinitialisation des commutateurs Cisco
- Autres ressources
6.2. Conditions préalables et sécurité
6.2.1. Accès requis
- Accès physique : accès à la salle du centre de données avec un chariot d'urgence
- Accès au réseau : connectivité de l'interface de gestion ou accès à la console
- Identifiants : accès administrateur à tous les systèmes
- Sauvegardes : sauvegarde complète de tous les secrets et données de configuration
6.2.2. Checklist de sécurité
- [ ] Accès physique à l'infrastructure
- [ ] Les secrets de secours ont été sécurisés hors connexion
- [ ] Sauvegarde de l'infrastructure (si nécessaire)
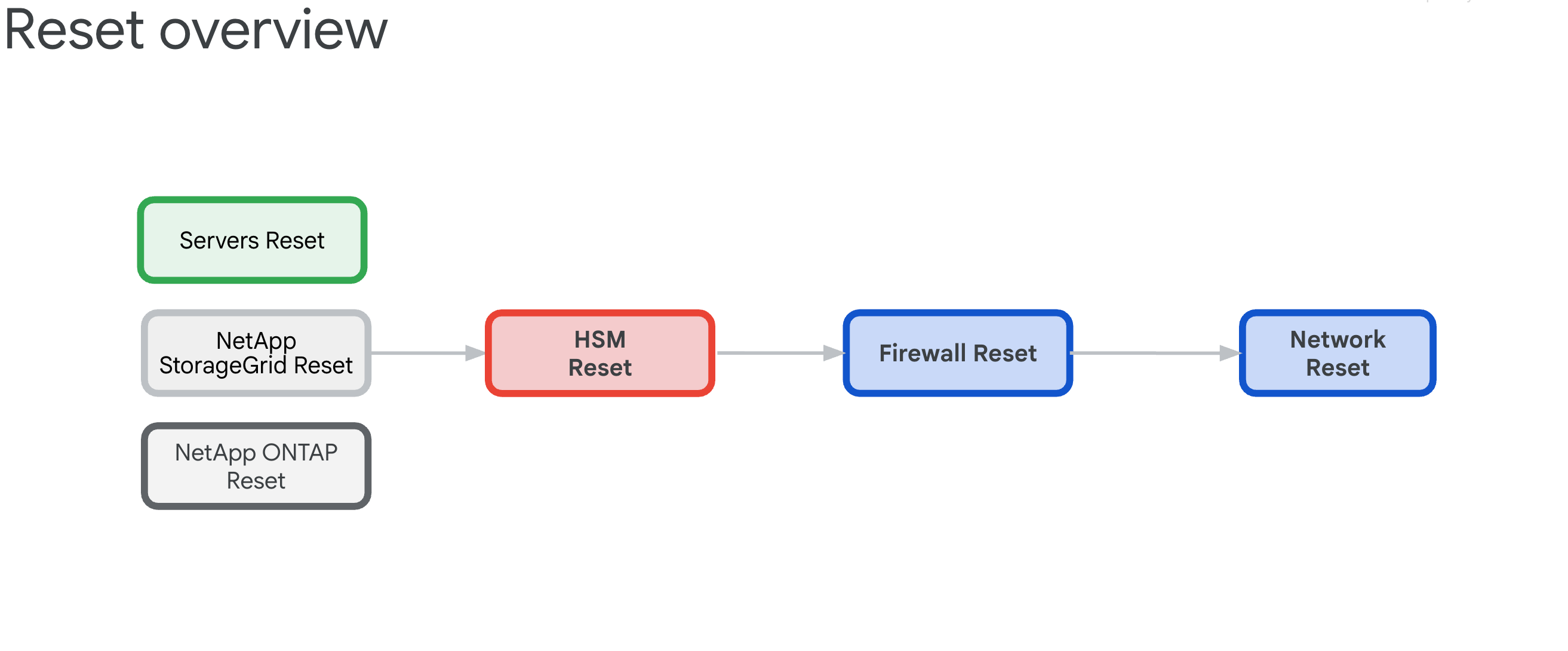
6.3. Présentation de la procédure de réinitialisation
La procédure de réinitialisation d'une zone de cellule GDC existante vise à libérer tous les appliances matériels de toute dépendance, puis à les rétablir dans leur état de structure.
6.3.1. Dépendances de l'infrastructure
Les composants ont les interdépendances suivantes qui déterminent l'ordre de réinitialisation :
- Les serveurs, NetApp ONTAP et NetApp StorageGrid s'appuient sur les appliances Thales HSM, car elles fournissent les clés de chiffrement pour les ILO, les disques, les locataires et les buckets.
- Les appliances HSM Thales reposent sur la connectivité des pare-feu IDP/de périmètre et des commutateurs Cisco.
- Les pare-feu IDP/de périmètre s'appuient sur l'infrastructure réseau des commutateurs Cisco.
- Les commutateurs Cisco doivent être réinitialisés en dernier recours, car la connectivité sera interrompue après leur réinitialisation.
6.3.2. Réinitialiser l'ordre (critique)
Suivez cet ordre exact pour éviter le blocage du système :
- Serveurs HPE : supprimez d'abord les dépendances HSM
- NetApp StorageGRID : effacer le chiffrement et réinitialiser les nœuds
- NetApp ONTAP : désactiver le HSM et réinitialiser le cluster
- HSM Thales : rétablir la configuration d'usine et effacer la racine de confiance
- Pare-feu : rétablir la configuration d'usine
- Routeurs Cisco : réinitialiser la dernière connexion (interrompt la connectivité)
6.4. Effacement sécurisé Hewlett Packard Enterprise
Trois types d'opérations de réinitialisation sont disponibles. Chacun d'eux constitue une méthode alternative pour nettoyer la configuration du Gestionnaire de clés iLO. L'objectif principal est de supprimer la dépendance au module de sécurité matériel (HSM).
En règle générale, la réinitialisation d'ILO aux paramètres d'usine suffit à nettoyer la configuration KMS. Ensuite, lors du prochain bootstrap, le processus de bootstrap du serveur initialisera les paramètres BIOS du serveur, effacera les disques et réinitialisera le serveur.
Cette section explique comment effectuer trois types d'effacements :
Ces scripts d'effacement utilisent un exemple de fichier CSV appelé example.csv.
Avant de continuer, préparez le fichier CSV suivant :
root@example-bootstrapper:/home/ubuntu/md# cat example.csv
ip,passd
10.251.248.62,XXXXXXXX
10.251.248.64,XXXXXXXX
10.251.248.66,XXXXXXXX
10.251.248.68,XXXXXXXX
10.251.248.70,XXXXXXXX
10.251.248.72,XXXXXXXX
10.251.248.74,XXXXXXXX
10.251.248.76,XXXXXXXX
6.4.1. Rétablir la configuration d'usine iLO
Rétablissez la configuration d'usine d'iLO :
Créez un fichier nommé
serversreset.pyet ajoutez-y le script Python suivant :import csv import argparse import requests import urllib3 import json urllib3.disable_warnings() PARSER = argparse.ArgumentParser(prog='serversreset.py', \ description='reset ilo to factory settings') PARSER.add_argument('-csv', '--file', help='choose the csv file', type=str) ARGS = vars(PARSER.parse_args()) headers = {'content-type': 'application/json'} payload = {'ResetType': 'Default'} url = '/redfish/v1/Managers/1/Actions/Oem/Hpe/HpeiLO.ResetToFactoryDefaults/' with open(ARGS['file'], encoding="utf8", mode='r') as csv_file: CSV_READER = csv.DictReader(csv_file) for row in CSV_READER: try: system = requests.post('https://'+row['ip']+url,data=json.dumps(payload),headers=headers,verify=False,auth=('administrator',row['passd'])) systemData = system.json() print(systemData) except Exception as err: print(err)Exécutez la commande suivante et remplacez
example.csvpar votre fichier CSV :python3 serversreset.py -csv example.csvLe résultat doit ressembler à ce qui suit :
{'error': {'code': 'iLO.0.10.ExtendedInfo', 'message': 'See @Message.ExtendedInfo for more information.', '@Message.ExtendedInfo': [{'MessageId': 'iLO.2.15.ResetInProgress'}]}} {'error': {'code': 'iLO.0.10.ExtendedInfo', 'message': 'See @Message.ExtendedInfo for more information.', '@Message.ExtendedInfo': [{'MessageId': 'iLO.2.15.ResetInProgress'}]}} {'error': {'code': 'iLO.0.10.ExtendedInfo', 'message': 'See @Message.ExtendedInfo for more information.', '@Message.ExtendedInfo': [{'MessageId': 'iLO.2.15.ResetInProgress'}]}}
6.4.2. Étapes manuelles supplémentaires pour iLO
Effectuez une réinitialisation manuelle d'iLO à l'aide de l'interface utilisateur iLO :
Sélectionnez iLO > Administration > Gestionnaire de clés > Supprimer les paramètres.
Dans la console BIOS, sélectionnez System Utilities > System Configuration > Embedded Raid > Administration > Reset To Default (Utilitaires système > Configuration système > RAID intégré > Administration > Rétablir les paramètres par défaut).
Définissez les interfaces sur "netboot only" (démarrage réseau uniquement) pour LOM1. Tous les nœuds GPU ne disposent PAS de cartes LOM1, mais de cartes Intel.
Définissez le réseau iLO sur DHCP.
6.4.3. Réinitialisation du BIOS
Suivez les étapes ci-dessous pour réinitialiser le BIOS :
Créez un fichier nommé
biosreset.pyet ajoutez-y le script Python suivant :import csv import argparse import requests import urllib3 import json urllib3.disable_warnings() PARSER = argparse.ArgumentParser(prog='biosreset.py', \ description='reset BIOS to factory settings') PARSER.add_argument('-csv', '--file', help='choose the csv file', type=str) ARGS = vars(PARSER.parse_args()) headers = {'content-type': 'application/json'} payload = {} with open(ARGS['file'], encoding="utf8", mode='r') as csv_file: CSV_READER = csv.DictReader(csv_file) for row in CSV_READER: try: system = requests.post('https://'+row['ip']+'/redfish/v1/systems/1/bios/Actions/Bios.ResetBios/',data=json.dumps(payload),headers=headers,verify=False,auth=('administrator',row['passd'])) systemData = system.json() print(systemData) except Exception as err: print(err)Exécutez la commande suivante et remplacez
example.csvpar votre fichier CSV :python3 biosreset.py -csv example.csvLe résultat doit ressembler à ce qui suit :
{'error': {'code': 'iLO.0.10.ExtendedInfo', 'message': 'See @Message.ExtendedInfo for more information.', '@Message.ExtendedInfo': [{'MessageId': 'iLO.2.15.SystemResetRequired'}]}}Une fois la commande exécutée, les serveurs sont en état d'activation. Vous devez exécuter le script suivant pour éteindre tous les serveurs :
import csv import argparse import requests import urllib3 import json urllib3.disable_warnings() PARSER = argparse.ArgumentParser(prog='power-ilo.py', \ description='power off server') PARSER.add_argument('-csv', '--file', help='choose the csv file', type=str) ARGS = vars(PARSER.parse_args()) headers = {'content-type': 'application/json'} payload = {'ResetType': 'PushPowerButton'} with open(ARGS['file'], encoding="utf8", mode='r') as csv_file: CSV_READER = csv.DictReader(csv_file) for row in CSV_READER: try: system = requests.post( 'https://' + row['ip'] + '/redfish/v1/systems/1/Actions/ComputerSystem.Reset/', data=json.dumps(payload), headers=headers, verify=False, auth=('administrator', row['passd'])) systemData = system.json() if 'Success' in systemData['error']['@Message.ExtendedInfo'][0][ 'MessageId']: print(f"ilo with ip {row['ip']} succeeded") #print(systemData) else: print(f"ilo with ip {row['ip']} failed") print(systemData) except Exception as err: print(err)Éteignez manuellement les serveurs :
python3 power-ilo.py -csv ~/servers.csv- (Facultatif) Pour vérifier l'état, utilisez le script suivant :
import csv import argparse import requests import urllib3 import json urllib3.disable_warnings() PARSER = argparse.ArgumentParser(prog='ilostatus.py', \ description='check power status of server') PARSER.add_argument('-csv', '--file', help='choose the csv file', type=str) ARGS = vars(PARSER.parse_args()) headers = {'content-type': 'application/json'} with open(ARGS['file'], encoding="utf8", mode='r') as csv_file: CSV_READER = csv.DictReader(csv_file) for row in CSV_READER: try: system = requests.get('https://'+row['ip']+'/redfish/v1/Systems/1',headers=headers,verify=False,auth=('administrator',row['passd'])) systemData = system.json() print(f"ilo with ip {row['ip']} has power status of {systemData['PowerState']}") if 'Success' in systemData['error']['@Message.ExtendedInfo'][0]['MessageId']: print(f"ilo with ip {row['ip']} succeeded") print(systemData) else: print(f"ilo with ip {row['ip']} failed") print(systemData) except Exception as err: passExécutez la commande suivante :
python3 ilostatus.py -csv ~/servers.csvLe résultat doit ressembler à ce qui suit :
ilo with ip 172.22.112.96 has power status of Off ilo with ip 172.22.112.97 has power status of Off ilo with ip 172.22.112.98 has power status of Off ilo with ip 172.22.112.100 has power status of Off ilo with ip 172.22.112.101 has power status of Off ilo with ip 172.22.112.102 has power status of Off6.4.4. Effacement sécurisé
Appuyez sur F10 sur l'écran POST du serveur. Intelligent Provisioning se lance.
Une fois Intelligent Provisioning lancé, cliquez sur la flèche vers le bas à côté de Assistant de configuration initiale pour ignorer l'assistant.
Ignorer l'invite de l'assistant, cliquez sur Oui.
Cliquez sur Perform Maintenance (Effectuer la maintenance).
Cliquez sur Effacement sécurisé en un clic.
Un message indique que vous ne disposez pas des droits suffisants. Cliquez sur Login (Se connecter), puis saisissez les identifiants de l'administrateur.
Cliquez sur OK.
Cliquez sur Envoyer.
Confirmez que vous souhaitez effectuer l'effacement sécurisé, puis saisissez ERASE.
Cliquez sur EFFACER.
Cliquez sur Oui pour confirmer la suppression.
Cliquez sur Lancer maintenant dans la section "File d'attente des tâches".
En deux minutes maximum, suivez l'invite pour cliquer sur OK.
La machine redémarre. Ne touchez rien pendant environ 10 à 15 minutes.
Une fois l'effacement sécurisé terminé, retournez dans le BIOS en cliquant sur F9 pendant le POST Boot.
Accédez à Embedded Applications > Integrated Management Log (IML) > View IML > OK (Applications intégrées > Journal de gestion intégré (IML) > Afficher le journal IML > OK). Le message Effacement sécurisé en un clic terminé s'affiche :

Créez un fichier nommé
serversreset.pyet ajoutez-y le script Python suivant :import csv import argparse import requests import urllib3 import json urllib3.disable_warnings() PARSER = argparse.ArgumentParser(prog='secureerase.py', \ description='reset ilo to factory settings') PARSER.add_argument('-csv', '--file', help='choose the csv file', type=str) ARGS = vars(PARSER.parse_args()) headers = {'content-type': 'application/json'} payload = {'SystemROMAndiLOErase': True , 'UserDataErase': True} with open(ARGS['file'], encoding="utf8", mode='r') as csv_file: CSV_READER = csv.DictReader(csv_file) for row in CSV_READER: try: system = requests.post('https://'+row['ip']+'/redfish/v1/Systems/1/Actions/Oem/Hpe/HpeComputerSystemExt.SecureSystemErase/',data=json.dumps(payload),headers=headers,verify=False,auth=('administrator',row['passd'])) systemData = system.json() print(systemData) except Exception as err: print(err)Exécutez la commande suivante et remplacez
example.csvpar votre fichier CSV :python serversreset.py -csv example.csvUne fois la commande exécutée, les serveurs sont à l'état "Éteint". Vous devez mettre le serveur sous tension manuellement.
6.5. Réinitialiser l'appareil NetApp StorageGRID
6.5.1. Prérequis
Avant de réinitialiser votre appareil NetApp StorageGRID, assurez-vous de lire les informations suivantes : - Si le système a été activé avec le chiffrement des nœuds et/ou des lecteurs, vous devez suivre les étapes décrites dans Désactiver le chiffrement du site HSM. Sinon, passez à la section Réinitialiser le système StorageGRID.
6.5.2. Désactiver le chiffrement du site HSM StorageGRID sur les nœuds du contrôleur de stockage
Pour obtenir les adresses IP des nœuds du contrôleur de stockage (deux adresses IP pour chaque nœud de stockage) :
$ kubectl get objectstoragestoragenodes -n gpc-system -o custom-columns="NAME:metadata.name,COMPUTE_NODEA_IP:.spec.network.controllerAManagementIP,COMPUTE_NODEB_IP:.spec.network.controllerBManagementIP"
NAME COMPUTE_NODEA_IP COMPUTE_NODEB_IP
ak-ac-objs01 172.22.210.166/24 172.22.210.167/24
ak-ac-objs02 172.22.210.170/24 172.22.210.171/24
ak-ac-objs03 172.22.210.174/24 172.22.210.175/24
Si le système StorageGRID était précédemment activé avec HSM, le chiffrement doit être supprimé avant de rétablir la configuration d'usine. Effectuez ces étapes pour chaque nœud de stockage avant de réinitialiser l'appareil. Si vous ne le faites pas, les disques et le système risquent d'être verrouillés.
Connectez-vous au site Object Storage et accédez à la liste des nœuds dans la barre latérale.
Cliquez sur le nom du nœud de stockage.
Accédez à l'onglet SANtricity System Manager.
Accédez à Paramètres > Système > Gestion des clés de sécurité.

Sélectionnez Désactiver la gestion des clés externes, puis saisissez la phrase secrète pour télécharger la clé de sauvegarde.
6.5.3. Rétablir la configuration d'usine du nœud d'administration et du nœud de calcul StorageGRID
Pour obtenir les adresses IP des nœuds d'administration :
$ kubectl get objectstorageadminnodes -n gpc-system
NAME SITE NAME MANAGEMENT IP READY AGE
ak-ac-objsadm01 ak-obj-site-1 172.22.210.160/24 True 12d
ak-ac-objsadm02 ak-obj-site-1 172.22.210.162/24 True 12d
Pour obtenir les adresses IP des nœuds de calcul Storage :
$ kubectl get objectstoragestoragenodes -n gpc-system
NAME SITE NAME MANAGEMENT IP READY AGE
ak-ac-objs01 ak-obj-site-1 172.22.210.164/24 True 12d
ak-ac-objs02 ak-obj-site-1 172.22.210.168/24 True 12d
ak-ac-objs03 ak-obj-site-1 172.22.210.172/24 True 12d
Pour rétablir la configuration d'usine de l'appareil StorageGRID, vous devez suivre les étapes ci-dessous pour chaque nœud (nœuds de stockage et d'administration) du site :
Récupérez les adresses IP de gestion pour chaque nœud. Vous pouvez l'obtenir à partir du fichier cell.yaml, en recherchant
ObjectStorageStorageNodeetObjectStorageAdminNode. Vous pouvez également les trouver dans les ressources de nœud du cluster d'administrateur racine.Récupérez le mot de passe et connectez-vous au nœud à l'aide de SSH :
Si StorageGRID n'est pas installé sur le nœud, utilisez
admin/bycastouroot/netapp1!comme nom d'utilisateur et mot de passe, respectivement. Utilisez le port SSH 8022 si le protocole SSH ne fonctionne pas.Si StorageGRID est installé sur le nœud, mais qu'aucun site n'est configuré, utilisez
admin/bycastouroot/bycastcomme nom d'utilisateur et mot de passe, respectivement.Si le site est configuré et que le nœud en fait partie :
Récupérez la phrase secrète de provisionnement. Il est stocké dans un secret nommé
grid-secret, que vous trouverez dans le fichier cell.yaml. Vous pouvez éventuellement exécuter la commande suivante. Veillez à décoder le mot de passe en base64 :echo $(kubectl get secret -n gpc-system grid-secret -ojsonpath="{.data.grid-management-provisioning-password}" | base64 -d)Dans l'interface utilisateur du site Object Storage, accédez à Maintenance > Système > Package de récupération pour télécharger le package de récupération après avoir saisi la phrase secrète de provisionnement.

Après le téléchargement, extrayez le fichier tar. Il contiendra une autre archive tar :
GIDXXXXX_REV1_SAID.zip. Extrayez cette archive tar pour trouver le fichierPasswords.txt. UtilisezPasswordpour l'accès SSH et racine, et ignorezSSH Access Password.Exemple de fichier :
Password Data for Grid ID: 546285, Revision: 1 Revision Prepared on: 2022-06-13 20:49:56 +0000 Server "root" and "admin" Account Passwords Server Name Password SSH Access Password ____________________________________________________________ alatl14-gpcstgeadm01 <removed> <removed> alatl14-gpcstgeadm02 <removed> <removed> alatl14-gpcstgecn01 <removed> n/a alatl14-gpcstgecn02 <removed> n/a alatl14-gpcstgecn03 <removed> n/a
Ouvrez une console série sur le nœud ou connectez-vous au nœud à l'aide de SSH :
ssh -o ProxyCommand=None -o StrictHostKeyChecking=no \ -o UserKnownHostsFile=/dev/null admin@<node-management-ip>Saisissez les identifiants pour vous connecter. Pour obtenir les droits sudo, saisissez
su -, puis saisissez le mot de passe racine obtenu à la deuxième étape.Saisissez la commande
sgareinstallet appuyez surypour continuer à réinitialiser l'appareil.Si le chiffrement était activé sur l'appareil, une fois la réinitialisation terminée, suivez ces étapes pour supprimer les pools de disques et le cache SSD.
6.5.4. Supprimer les pools de disques et le cache SSD sur les nœuds du contrôleur de stockage
Pour obtenir les adresses IP des nœuds du contrôleur de stockage (deux adresses IP pour chaque nœud de stockage) :
$ kubectl get objectstoragestoragenodes -n gpc-system -o custom-columns="NAME:metadata.name,COMPUTE_NODEA_IP:.spec.network.controllerAManagementIP,COMPUTE_NODEB_IP:.spec.network.controllerBManagementIP"
NAME COMPUTE_NODEA_IP COMPUTE_NODEB_IP
ak-ac-objs01 172.22.210.166/24 172.22.210.167/24
ak-ac-objs02 172.22.210.170/24 172.22.210.171/24
ak-ac-objs03 172.22.210.174/24 172.22.210.175/24
Si le chiffrement était activé sur l'appareil et que les nœuds ont été réinitialisés après avoir suivi la dernière section, les pools de disques doivent être supprimés en même temps que les lecteurs sont effacés. Cette opération doit être effectuée avant le réamorçage du site afin qu'il puisse créer des pools de disques. Procédez comme suit pour chaque nœud de stockage (contrôleur de stockage e2860) du site (également appelé "controllerAManagementIP") :
Ouvrez un navigateur Web pour accéder à
https://<storage-node-controller-ip>:8443et saisissez les identifiants. Si vous n'avez pas accès aux identifiants SANtricity, suivez ces étapes.Accédez à Stockage > Pools et groupes de volumes.
Supprimer le cache SSD :
Sélectionnez le cache SSD pour le mettre en surbrillance.
Sélectionnez le menu déroulant Tâches inhabituelles, puis cliquez sur Supprimer.

Supprimez le pool de disques :
Sélectionnez le pool de disques pour le mettre en surbrillance.
Sélectionnez le menu déroulant Tâches inhabituelles, puis cliquez sur Supprimer.

Essayez de créer un pool de disques. Une boîte de dialogue s'affiche, bloquant la création et demandant d'effacer les lecteurs.

Étant donné que les lecteurs sécurisés non attribués ne peuvent pas être utilisés pour créer un pool, vous devez d'abord les supprimer. Cliquez sur le bouton radio Oui, je souhaite sélectionner les lecteurs à effacer pour l'opération, puis sélectionnez tous les lecteurs à effacer. Confirmez l'opération d'effacement, puis cliquez sur OK. Ne créez pas de pool.
Suivez les étapes décrites dans la section Supprimer le chiffrement des nœuds.
6.5.5. Supprimer le chiffrement des nœuds sur les nœuds d'administration et de calcul StorageGRID
Pour obtenir les adresses IP des nœuds d'administration :
$ kubectl get objectstorageadminnodes -n gpc-system
NAME SITE NAME MANAGEMENT IP READY AGE
ak-ac-objsadm01 ak-obj-site-1 172.22.210.160/24 True 12d
ak-ac-objsadm02 ak-obj-site-1 172.22.210.162/24 True 12d
Pour obtenir les adresses IP des nœuds de calcul Storage :
$ kr get objectstoragestoragenodes -n gpc-system
NAME SITE NAME MANAGEMENT IP READY AGE
ak-ac-objs01 ak-obj-site-1 172.22.210.164/24 True 12d
ak-ac-objs02 ak-obj-site-1 172.22.210.168/24 True 12d
ak-ac-objs03 ak-obj-site-1 172.22.210.172/24 True 12d
Si le chiffrement était activé sur l'appareil et que les nœuds ont été réinitialisés après avoir suivi ces étapes, et que les pools de disques et le cache SSD ont été supprimés en suivant ces étapes, procédez comme suit sur chaque nœud pour supprimer le chiffrement des nœuds :
Accédez à l'interface utilisateur de StorageGRID Appliance Installer.
Accédez à Configure Hardware (Configurer le matériel) > Node Encryption (Chiffrement des nœuds).
Cliquez sur Effacer la clé KMS et supprimer les données.

Une fois l'effacement déclenché, la télécommande redémarre. Cette opération peut prendre environ 15 minutes.
6.5.6. Réinstaller StorageGRID
Redémarrez manuellement chaque nœud.
Ouvrez une console série sur le nœud, accédez au menu du bootloader GRUB, puis sélectionnez StorageGRID Appliance: Force StorageGRID reinstall (Appliance StorageGRID : forcer la réinstallation de StorageGRID).

6.5.7. Obtenir les identifiants SANtricity
Ouvrez une console série sur l'un des contrôleurs SANtricity.
Connectez-vous à l'aide des identifiants suivants :
- Nom d'utilisateur :
spri - Mot de passe :
SPRIentry
- Nom d'utilisateur :
Une fois connecté, un menu semblable à celui-ci s'affiche :
Service Interface Main Menu ============================== 1)Display IP Configuration 2)Change IP Configuration 3)Reset Storage Array Administrator Password 4)Display 7-segment LED codes 5)Disable SAML 6)Unlock remote admin account Q)Quit Menu Enter Selection: 3 Are you sure that you want to reset the Storage Array Password ? (Y/N): Y Storage Array Password reset successfulConnectez-vous aux contrôleurs SANtricity. La réinitialisation du mot de passe sera alors disponible.
6.6. Réinitialiser l'appareil NetApp ONTAP
6.6.1. Prérequis
Avant de réinitialiser votre appareil NetApp ONTAP, assurez-vous de lire les informations suivantes :
Si le système était précédemment activé avec un module de sécurité matérielle (HSM), vous devez suivre la procédure décrite dans Désactiver le module de sécurité matérielle avant de réinitialiser les systèmes ONTAP.
Il s'agit d'une opération destructrice qui efface toutes les données CipherTrust Manager, y compris, sans s'y limiter, les clés, les sauvegardes, les clés de sauvegarde et les journaux système.
Assurez-vous de disposer d'une sauvegarde CipherTrust Manager valide de toutes les données et clés de sauvegarde.
Si un HSM intégré est disponible, il n'est pas réinitialisé dans le cadre de cette opération.
Facultatif : Il est fortement recommandé de réinitialiser un HSM intégré après cette opération pour le configurer comme racine de confiance.
Si un terminal de saisie du code à distance a été utilisé, il doit être reconnecté une fois l'opération terminée.
Cette opération peut prendre jusqu'à 15 minutes. Assurez-vous de disposer d'une alimentation de secours.
6.6.2. Désactiver le module de sécurité matérielle
Si le système a déjà été activé à l'aide d'un HSM, suivez ces étapes avant de réinitialiser les systèmes ONTAP. Si vous ne le faites pas, les disques et le système risquent d'être verrouillés. Exécutez les commandes suivantes sur le cluster ONTAP :
Définissez le niveau de privilège sur "Avancé" :
set -privilege advancedAffichez la clé de données du disque et les clés d'authentification FIPS (Federal Information Processing Standards) qu'il utilise :
storage encryption disk showPour chaque disque du système, définissez l'ID de clé d'authentification FIPS et de données du nœud sur l'ID MSID par défaut 0x0 :
storage encryption disk modify -disk * -fips-key-id 0x0 storage encryption disk modify -disk * -data-key-id 0x0Vérifiez que l'opération a réussi en procédant comme suit :
storage encryption disk show-statusRépétez la commande
show-statusjusqu'à ce que vous receviezDisks Begun == Disks Done. Ce résultat signifie que l'opération est terminée.cluster1:: storage encryption disk show-status FIPS Latest Start Execution Disks Disks Disks Node Support Request Timestamp Time (sec) Begun Done Successful ------- ------- -------- ------------------ ---------- ------ ------ ---------- cluster1 true modify 1/18/2022 15:29:38 3 14 5 5 1 entry was displayed.Supprimez la configuration du gestionnaire de clés externe :
Si la connexion HSM est établie, passez directement à l'étape f. Si la connexion HSM est interrompue, passez à l'étape b.
cluster1::> security key-manager external show-statusPassez en mode
diagen exécutantset -priv diag.Exécutez la commande suivante pour afficher toutes les clés de chiffrement de volume.
debug smdb table kmip_external_key_cache_mdb_v2 show.Collectez la propriété
vserver-id.Exécutez la commande suivante pour tous les serveurs de clés afin de supprimer les clés :
debug smdb table kmip_external_key_cache_mdb_v2 delete -vserver-id <vserver-id> -key-id * -key-server <key-server endpoint>.Supprimez tous les volumes à l'aide de l'interface utilisateur (UI) ONTAP ou supprimez-les manuellement depuis la console.
Si vous supprimez des volumes à partir de la console, vous devez ignorer les volumes racine des nœuds. Ils portent généralement le nom
vol0et l'un des nœuds est défini commevserver. En règle générale, tout volume dont un nœud est levserverne peut pas être supprimé et ne doit pas l'être.Si d'autres volumes que
vol0, de l'étape précédente, ne peuvent pas être supprimés de l'interface utilisateur, essayez d'utiliser la CLI :cluster1::> vol offline -volume volume_to_be_deleted -vserver vserve-id cluster1::> vol delete -volume volume_to_be_deleted -vserver vserver-idPour vous connecter à un cluster de stockage depuis l'interface utilisateur, obtenez le nom d'utilisateur et le mot de passe à partir du secret à l'aide des commandes suivantes, en remplaçant CELL_ID par l'ID unique de la cellule que vous installez :
kubectl get secret -n gpc-system ontap-CELL_ID-stge-clus-01-credential -o jsonpath='{.data.netapp_username}' | base64 --decode kubectl get secret -n gpc-system ontap-CELL_ID-stge-clus-01-credential -o jsonpath='{.data.netapp_password}' | base64 --decodeAccédez ensuite à Volumes, sélectionnez tout, puis cliquez sur Supprimer. Vous devez répéter cette opération plusieurs fois pour chaque page. Remarque : Vous pouvez ignorer sans risque l'erreur indiquant qu'un volume n'a pas pu être supprimé. Pour en savoir plus, consultez la base de connaissances NetApp.
ag-stge-clus-01::*> vol show Vserver Volume Aggregate State Type Size Available Used% --------- ------------ ------------ ---------- ---- ---------- ---------- ----- ag-ad-stge01-01 vol0 aggr0_ag_ad_stge01_01 online RW 151.3GB 84.97GB 40% ag-ad-stge01-02 vol0 aggr0_ag_ad_stge01_02 online RW 151.3GB 86.69GB 39% ag-ad-stge02-01 vol0 aggr0_ag_ad_stge02_01 online RW 151.3GB 83.62GB 41% ag-ad-stge02-02 vol0 aggr0_ag_ad_stge02_02 online RW 151.3GB 85.97GB 40% ag-ad-stge03-01 vol0 aggr0_ag_ad_stge03_01 online RW 151.3GB 89.19GB 37% ag-ad-stge03-02 vol0 aggr0_ag_ad_stge03_02 online RW 151.3GB 88.74GB 38%
Après avoir supprimé tous les volumes, exécutez la commande suivante pour vider la file d'attente de récupération :
recovery-queue purge-all -vserver <vserver>.Exécutez la commande suivante pour supprimer le gestionnaire de clés externe :
clusterl::> security key-manager external remove-servers -vserver <CLUSTER_NAME> -key-servers <IP1:PORT,IP2:PORT,...>. Après cette étape, vous pouvez recevoir l'erreur suivante :Error: command failed: The key server at "172.22.112.192" contains authentication keys that are currently in use and not available from any other configured key server.Cette erreur indique qu'il reste des clés. Pour supprimer les clés restantes, procédez comme suit :
Pour lister les clés restantes, exécutez la commande suivante :
security key-manager key queryLe résultat ressemble à celui de l'exemple ci-dessous.
Node: ag-ad-stge01-01 Vserver: ag-stge-clus-01 Key Manager: 172.22.112.192:5696 Key Manager Type: KMIP Key Manager Policy: - Key Tag Key Type Encryption Restored ------------------------------------ -------- ------------ -------- ag-ad-stge01-01 NSE-AK AES-256 true Key ID: 00000000000000000200000000000100454007f1854b3e3f5c90756bc5cfa6cc0000000000000000Notez la valeur ID de clé dans la sortie précédente. Exécutez la commande
security key-manager key delete -key-id+ la valeur ID de clé pour supprimer les clés restantes :security key-manager key delete -key-id 00000000000000000200000000000100454007f1854b3e3f5c90756bc5cfa6cc0000000000000000Répétez les étapes i et j pour supprimer les clés restantes. Une fois l'opération terminée, le résultat ressemble à l'exemple suivant :
ag-stge-clus-01::*> security key-manager key query No matching keys found.6.6.3. Réinitialiser les nœuds ONTAP
Pour réinitialiser les nœuds ONTAP :
Redémarrez le nœud pour accéder au menu de démarrage à l'aide de la commande
system node rebootà l'invite système. Remarque : Vous pouvez ignorer sans risque les avertissements de redémarrage du système.Exemples :
ag-stge-clus-01::> system reboot -node ag-ad-stge03-02 Warning: Are you sure you want to reboot node "ag-ad-stge03-02"? {y|n}: y Error: Could not migrate LIFs away from node: Failed to migrate one or more LIFs away from node "ag-ad-stge03-02". Use the "network interface show -curr-node ag-ad-stge03-02" command to identify LIFs that could not be migrated off that node. Use the "network interface migrate" command to manually migrate the LIFs off the node. Reissue the command with "-skip-lif-migration-before-reboot" to skip the migration and continue with takeover. ag-stge-clus-01::> system reboot -node ag-ad-stge03-02 -skip-lif-migration-before-reboot Warning: Are you sure you want to reboot node "ag-ad-stge03-02"? {y|n}: y Connection to 172.22.115.134 closed.ag-stge-clus-01::> system reboot -node ag-ad-stge02-02 Error: command failed: Taking node "ag-ad-stge02-02" out of service might result in a data service failure and client disruption for the entire cluster. If possible, bring an additional node online to improve the resiliency of the cluster and to ensure continuity of service. Verify the health of the node using the "cluster show" command, then try the command again, or provide "-ignore-quorum-warnings" to bypass this check. ag-stge-clus-01::> system reboot -node ag-ad-stge02-02 -ignore-quorum-warnings Warning: Are you sure you want to reboot node "ag-ad-stge02-02"? {y|n}: y Error: Could not migrate LIFs away from node: Failed to migrate one or more LIFs away from node "ag-ad-stge02-02". Use the "network interface show -curr-node ag-ad-stge02-02" command to identify LIFs that could not be migrated off that node. Use the "network interface migrate" command to manually migrate the LIFs off the node. Reissue the command with "-skip-lif-migration-before-reboot" to skip the migration and continue with takeover. ag-stge-clus-01::> system reboot -node ag-ad-stge02-02 -ignore-quorum-warnings -skip-lif-migration-before-reboot Warning: Are you sure you want to reboot node "ag-ad-stge02-02"? {y|n}: y Connection to 172.22.115.132 closed.Si vous êtes dans le menu
LOADER, saisissezboot_ontappour redémarrer. Pendant le processus de redémarrage, appuyez surCtrl-Cpour afficher le menu de démarrage lorsque vous y êtes invité. Le nœud affiche les options suivantes pour le menu de démarrage :(1) Normal Boot. (2) Boot without /etc/rc. (3) Change password. (4) Clean configuration and initialize all disks. (5) Maintenance mode boot. (6) Update flash from backup config. (7) Install new software first. (8) Reboot node. (9) Configure Advanced Drive Partitioning Selection (1-9)?Sélectionnez l'option
(9) Configure Advanced Drive Partitioning. Le nœud affiche les options suivantes :* Advanced Drive Partitioning Boot Menu Options * ************************************************* (9a) Destroy aggregates, unpartition all disks and remove their ownership information. (9b) Clean configuration and initialize node with partitioned disks. (9c) Clean configuration and initialize node with whole disks. (9d) Reboot the node. (9e) Return to main boot menu. (9f) Remove disk ownership.Sélectionnez l'option
9aet saisisseznolorsque vous êtes invité à résilier. Le nœud affiche à nouveau l'option suivante après9a:(9a) Unpartition all disks and remove their ownership information. (9b) Clean configuration and initialize node with partitioned disks. (9c) Clean configuration and initialize node with whole disks. (9d) Reboot the node. (9e) Return to main boot menu. ```Exécutez l'opération
9apour tous les nœuds de stockage existants dans le cluster avant de continuer.Pour chaque nœud, exécutez l'option
9bet saisissezyespour confirmer.(9a) Unpartition all disks and remove their ownership information. (9b) Clean configuration and initialize node with partitioned disks. (9c) Clean configuration and initialize node with whole disks. (9d) Reboot the node. (9e) Return to main boot menu.Si une paire HA existe, le message suivant s'affiche. Assurez-vous que tous les nœuds du cluster ont terminé l'étape 9a avant d'exécuter l'étape 9b.
Selection (9a-9f)?: 9b 9b Option (9a) MUST BE COMPLETED on BOTH nodes in an HA pair (and DR/DR-AUX partner nodes if applicable) prior to starting option (9b). Has option (9a) been completed on all the nodes (yes/no)? yes yes
Lorsque le message
Welcome to the cluster setup wizards'affiche, la réinitialisation est terminée.
6.7. Réinitialiser le Thales k570
Pour réinitialiser le Thales k570, commencez par rétablir la configuration d'usine de Ciphertrust Manager, puis réinitialisez le HSM Luna lui-même.
6.7.1. Rétablir la configuration d'usine du système
Créez un répertoire de travail temporaire pour les identifiants HSM :
TMPPWDDIR=/run/user/$(id --user)/hsm mkdir -p $TMPPWDDIR chmod 700 $TMPPWDDIRÉtablissez une connexion SSH avec le HSM :
export ADMIN_SSH_SECRET_NAME=`kubectl get secrets -n hsm-system -o json | jq .items[].metadata.name | tr -d '"' | grep "ssh"` kubectl get secret $ADMIN_SSH_SECRET_NAME \ --namespace=hsm-system \ --output jsonpath='{.data.ssh-privatekey}' \ | base64 --decode > $TMPPWDDIR/hsm-ssh-privatekey chmod 0600 $TMPPWDDIR/hsm-ssh-privatekey ssh -i $TMPPWDDIR/hsm-ssh-privatekey ksadmin@$HSM_MGMT_IPSi cela n'est pas possible, connectez-vous à l'aide d'un câble série de votre ordinateur au port de la console. Exécutez la commande suivante dans un autre onglet pour obtenir le mot de passe
ksadmin.export KSADMIN_SECRET_NAME=`kubectl get secrets -n hsm-system -o json | jq .items[]metadata.name | tr -d '"' | grep "ksadmin"` kubectl get secret $KSADMIN_SECRET_NAME \ --namespace=hsm-system \ --output jsonpath='{.data.password}' \ | base64 --decodeUne fois connecté au port série, une invite de connexion s'affiche. Saisissez le nom d'utilisateur
ksadminet collez le mot de passe de la commande précédente.Avant d'exécuter la commande
factory-reset:Évitez de redémarrer le système pendant cette période, car la reconnexion implique un redémarrage multiple du système et ne peut pas être annulée.
Assurez-vous de disposer d'une alimentation de secours.
Exécutez la commande suivante pour effectuer la réinitialisation des paramètres d'usine :
sudo /opt/keysecure/ks_reset_to_factory.shLe processus de réinitialisation prend environ 10 minutes.
6.7.2. Réinitialisation de Luna HSM
La réinitialisation du système aux paramètres d'usine n'efface pas la racine de confiance des HSM. Exécutez les commandes suivantes pour réinitialiser le HSM Luna :
Depuis l'hôte CipherTrust Manager, que ce soit via SSH ou la console série, exécutez la commande suivante :
/usr/safenet/lunaclient/bin/lunacmlunacm:> hsm factoryResetSupprimez le répertoire de travail temporaire du programme d'amorçage :
rm $TMPPWDDIR
6.8. Réinitialiser les pare-feu
Pour savoir comment rétablir la configuration d'usine de vos pare-feu, consultez Rétablir la configuration d'usine du pare-feu.
6.9. Réinitialiser les commutateurs Cisco
Suivez les étapes ci-dessous pour réinitialiser les commutateurs Cisco. Notez que ces instructions s'appliquent également aux commutateurs de stockage tels que stgesw.
- Connectez-vous aux commutateurs.
Écrivez, effacez et rechargez les commutateurs :
write erase reloadSi les commutateurs ont déjà été configurés et que vous disposez d'un répertoire
cellcfg, vous pouvez suivre la procédure Nettoyage avant le vol.Vérifiez que les commutateurs sont en mode POAP (Power On Auto Provisioning).
Si le commutateur est correctement réinitialisé, l'invite suivante doit s'afficher lorsque vous vous y connectez à l'aide du serveur de console :
Abort Power On Auto Provisioning [yes - continue with normal setup, skip - bypass password and basic configuration, no - continue with Power On Auto Provisioning] (yes/skip/no)[no]:
6.10. Ressources supplémentaires sur la procédure de réinitialisation
Pour en savoir plus sur la procédure de réinitialisation, consultez les ressources suivantes :
https://docs.netapp.com/us-en/ontap/system-admin/manage-node-boot-menu-task.htmlhttps://docs.netapp.com/us-en/ontap/encryption-at-rest/return-seds-unprotected-mode-task.html