完了までの推定時間: 4 日
操作可能なコンポーネントのオーナー: HW
スキル プロファイル: デプロイ エンジニア
Google Distributed Cloud(GDC)のエアギャップ環境で実行されているデバイスとシステムをリセットするには、次のタスクを完了します。
6.1. 目次
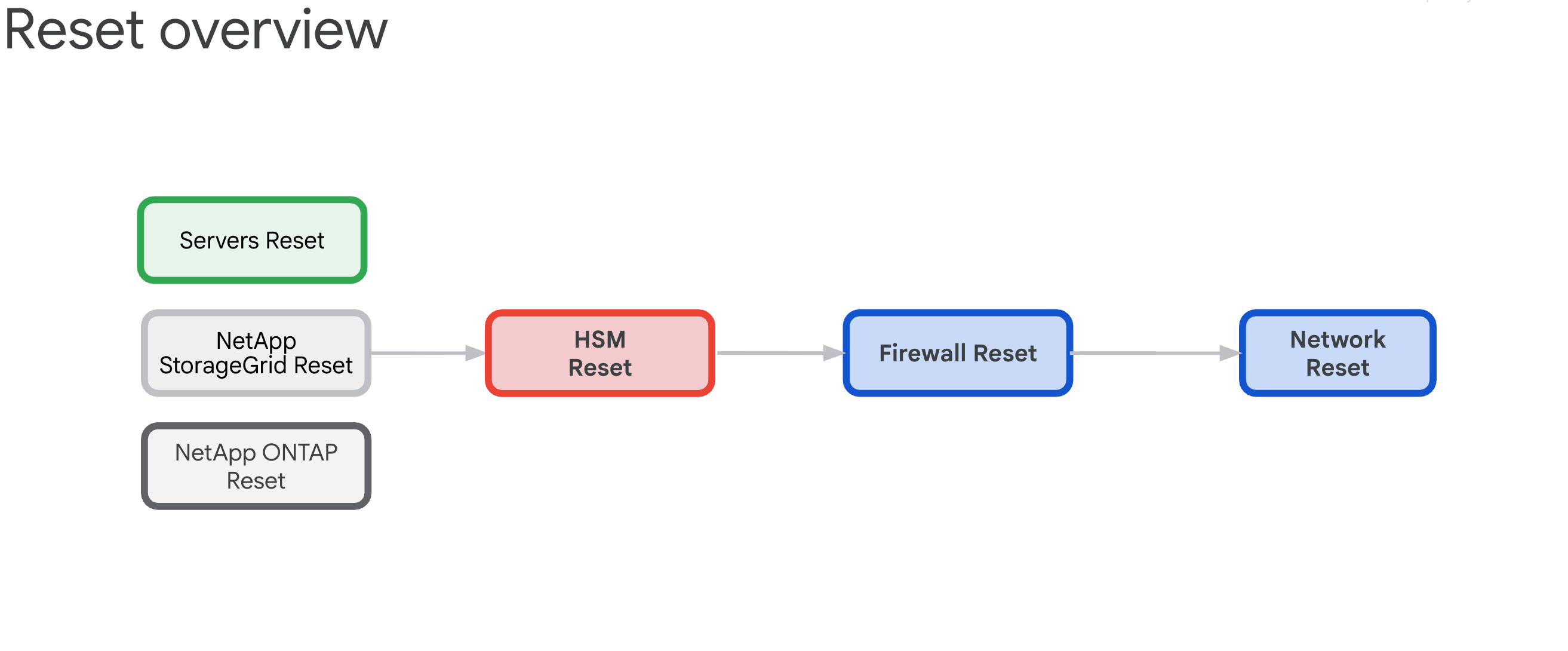
- リセット手順の概要
- HPE サーバーのリセット
- NetApp StorageGRID のリセット
- NetApp ONTAP のリセット
- Thales HSM のリセット
- Palo Alto ファイアウォールのリセット
- Cisco スイッチのリセット
- 参考情報
6.2. 前提条件と安全性
6.2.1. 必要なアクセス権
- 物理アクセス: クラッシュカート機器を使用した DC ルームへのアクセス
- ネットワーク アクセス: 管理インターフェースの接続またはコンソール アクセス
- 認証情報: すべてのシステムに対する管理者アクセス権
- バックアップ: すべてのシークレットと構成データの完全バックアップ
6.2.2. 安全性チェックリスト
- [ ] インフラストラクチャへの物理アクセス
- [ ] ブレークグラス シークレットがオフラインで保護されている
- [ ] インフラストラクチャのバックアップ(必要な場合)
6.3. リセット手順の概要
既存の GDC セルゾーンのリセット手順は、すべての HW アプライアンスを依存関係から解放し、ファブリック状態に戻すことを目的としています。
6.3.1. インフラストラクチャの依存関係
コンポーネントには、リセット順序を決定する次の相互依存関係があります。
- サーバー、NetApp ONTAP、NetApp StorageGrid は、Thales HSM アプライアンスに依存しています。これは、ILO、ディスク、テナント、バケットの暗号鍵を提供するためです。
- Thales HSM アプライアンスは、IDP/境界ファイアウォールと Cisco スイッチの接続に依存しています。
- IDP/ペリメータ ファイアウォールは、Cisco スイッチのネットワーキング インフラストラクチャに依存しています。
- Cisco スイッチは、リセット後に接続が中断されるため、最後の手段としてリセットする必要があります。
6.3.2. Reset Order(クリティカル)
システム ロックアウトを防ぐため、必ず以下の順番で操作してください。
- HPE サーバー - まず HSM の依存関係を削除する
- NetApp StorageGRID - 暗号化をクリアしてノードをリセットする
- NetApp ONTAP - HSM を無効にしてクラスタをリセットする
- Thales HSM - 初期状態にリセットしてルート オブ トラストをクリアする
- ファイアウォール - 出荷時の設定にリセット
- Cisco スイッチ - リセット(接続が中断されます)
6.4. Hewlett Packard Enterprise のセキュア消去
リセット オペレーションには 3 種類あり、それぞれが iLO Key Manager 構成をクリーンアップする代替方法として機能します。主な目的は、ハードウェア セキュリティ モジュール(HSM)への依存関係を解消することです。
通常、ILO の出荷時設定へのリセットで KMS 構成をクリーンアップできます。次のブートストラップで、サーバー ブートストラップ プロセスがサーバー設定の BIOS パラメータを初期化し、ディスクを消去してサーバーを再初期化します。
このセクションでは、次の 3 種類の消去を行う方法について説明します。
これらの削除スクリプトでは、example.csv という名前の CSV ファイルの例を使用します。続行する前に、次の CSV ファイルを準備します。
root@example-bootstrapper:/home/ubuntu/md# cat example.csv
ip,passd
10.251.248.62,XXXXXXXX
10.251.248.64,XXXXXXXX
10.251.248.66,XXXXXXXX
10.251.248.68,XXXXXXXX
10.251.248.70,XXXXXXXX
10.251.248.72,XXXXXXXX
10.251.248.74,XXXXXXXX
10.251.248.76,XXXXXXXX
6.4.1. iLO の出荷時設定へのリセット
通常の iLO の初期状態へのリセットを完了します。
serversreset.pyという名前のファイルを作成し、次の Python スクリプトを追加します。import csv import argparse import requests import urllib3 import json urllib3.disable_warnings() PARSER = argparse.ArgumentParser(prog='serversreset.py', \ description='reset ilo to factory settings') PARSER.add_argument('-csv', '--file', help='choose the csv file', type=str) ARGS = vars(PARSER.parse_args()) headers = {'content-type': 'application/json'} payload = {'ResetType': 'Default'} url = '/redfish/v1/Managers/1/Actions/Oem/Hpe/HpeiLO.ResetToFactoryDefaults/' with open(ARGS['file'], encoding="utf8", mode='r') as csv_file: CSV_READER = csv.DictReader(csv_file) for row in CSV_READER: try: system = requests.post('https://'+row['ip']+url,data=json.dumps(payload),headers=headers,verify=False,auth=('administrator',row['passd'])) systemData = system.json() print(systemData) except Exception as err: print(err)次のコマンドを実行し、
example.csvを CSV ファイルに置き換えます。python3 serversreset.py -csv example.csv出力は次のようになります。
{'error': {'code': 'iLO.0.10.ExtendedInfo', 'message': 'See @Message.ExtendedInfo for more information.', '@Message.ExtendedInfo': [{'MessageId': 'iLO.2.15.ResetInProgress'}]}} {'error': {'code': 'iLO.0.10.ExtendedInfo', 'message': 'See @Message.ExtendedInfo for more information.', '@Message.ExtendedInfo': [{'MessageId': 'iLO.2.15.ResetInProgress'}]}} {'error': {'code': 'iLO.0.10.ExtendedInfo', 'message': 'See @Message.ExtendedInfo for more information.', '@Message.ExtendedInfo': [{'MessageId': 'iLO.2.15.ResetInProgress'}]}}
6.4.2. iLO の手動手順の追加
iLO UI を使用して iLO を手動でリセットします。
[iLO> Administration> Key Manager> Delete Settings] を選択します。
BIOS コンソールで、[System Utilities > System Configuration > Embedded Raid > Administration > Reset To Default] を選択します。
LOM1 のインターフェースをネットブートのみに設定します。すべての GPU ノードに LOM1 カードがあるわけではなく、代わりに Intel カードがあります。
iLO ネットワークを DHCP に設定します。
6.4.3. BIOS のリセット
BIOS をリセットする手順は次のとおりです。
biosreset.pyという名前のファイルを作成し、次の Python スクリプトを追加します。import csv import argparse import requests import urllib3 import json urllib3.disable_warnings() PARSER = argparse.ArgumentParser(prog='biosreset.py', \ description='reset BIOS to factory settings') PARSER.add_argument('-csv', '--file', help='choose the csv file', type=str) ARGS = vars(PARSER.parse_args()) headers = {'content-type': 'application/json'} payload = {} with open(ARGS['file'], encoding="utf8", mode='r') as csv_file: CSV_READER = csv.DictReader(csv_file) for row in CSV_READER: try: system = requests.post('https://'+row['ip']+'/redfish/v1/systems/1/bios/Actions/Bios.ResetBios/',data=json.dumps(payload),headers=headers,verify=False,auth=('administrator',row['passd'])) systemData = system.json() print(systemData) except Exception as err: print(err)次のコマンドを実行し、
example.csvを CSV ファイルに置き換えます。python3 biosreset.py -csv example.csv出力は次のようになります。
{'error': {'code': 'iLO.0.10.ExtendedInfo', 'message': 'See @Message.ExtendedInfo for more information.', '@Message.ExtendedInfo': [{'MessageId': 'iLO.2.15.SystemResetRequired'}]}}コマンドを実行すると、サーバーは電源オン状態になります。次のスクリプトを実行して、すべてのサーバーの電源をオフにする必要があります。
import csv import argparse import requests import urllib3 import json urllib3.disable_warnings() PARSER = argparse.ArgumentParser(prog='power-ilo.py', \ description='power off server') PARSER.add_argument('-csv', '--file', help='choose the csv file', type=str) ARGS = vars(PARSER.parse_args()) headers = {'content-type': 'application/json'} payload = {'ResetType': 'PushPowerButton'} with open(ARGS['file'], encoding="utf8", mode='r') as csv_file: CSV_READER = csv.DictReader(csv_file) for row in CSV_READER: try: system = requests.post( 'https://' + row['ip'] + '/redfish/v1/systems/1/Actions/ComputerSystem.Reset/', data=json.dumps(payload), headers=headers, verify=False, auth=('administrator', row['passd'])) systemData = system.json() if 'Success' in systemData['error']['@Message.ExtendedInfo'][0][ 'MessageId']: print(f"ilo with ip {row['ip']} succeeded") #print(systemData) else: print(f"ilo with ip {row['ip']} failed") print(systemData) except Exception as err: print(err)サーバーを手動で電源オフにします。
python3 power-ilo.py -csv ~/servers.csv- (省略可)ステータスを確認するには、次のスクリプトを使用します。
import csv import argparse import requests import urllib3 import json urllib3.disable_warnings() PARSER = argparse.ArgumentParser(prog='ilostatus.py', \ description='check power status of server') PARSER.add_argument('-csv', '--file', help='choose the csv file', type=str) ARGS = vars(PARSER.parse_args()) headers = {'content-type': 'application/json'} with open(ARGS['file'], encoding="utf8", mode='r') as csv_file: CSV_READER = csv.DictReader(csv_file) for row in CSV_READER: try: system = requests.get('https://'+row['ip']+'/redfish/v1/Systems/1',headers=headers,verify=False,auth=('administrator',row['passd'])) systemData = system.json() print(f"ilo with ip {row['ip']} has power status of {systemData['PowerState']}") if 'Success' in systemData['error']['@Message.ExtendedInfo'][0]['MessageId']: print(f"ilo with ip {row['ip']} succeeded") print(systemData) else: print(f"ilo with ip {row['ip']} failed") print(systemData) except Exception as err: pass次のコマンドを実行します。
python3 ilostatus.py -csv ~/servers.csv出力は次のようになります。
ilo with ip 172.22.112.96 has power status of Off ilo with ip 172.22.112.97 has power status of Off ilo with ip 172.22.112.98 has power status of Off ilo with ip 172.22.112.100 has power status of Off ilo with ip 172.22.112.101 has power status of Off ilo with ip 172.22.112.102 has power status of Off6.4.4. 安全な消去
サーバーの POST 画面で F10 キーを押します。インテリジェント プロビジョニングが起動します。
Intelligent Provisioning が起動したら、[First Time Setup Wizard] の横にある下矢印をクリックしてウィザードをスキップします。
ウィザードのプロンプトをスキップし、[はい] をクリックします。
[Perform Maintenance] をクリックします。
[One Button Secure Erase] をクリックします。
権限が不足していることを示すメッセージが表示されます。[ログイン] をクリックし、管理者の認証情報を入力します。
[完了] をクリックします。
[送信] をクリックします。
安全な消去を実行することを確認し、「ERASE」と入力します。
[消去] をクリックします。
[はい] をクリックして削除を確定します。
[ジョブキュー] セクションで [今すぐ起動] をクリックします。
2 分以内に、プロンプトに沿って [OK] をクリックします。
マシンが再起動します。10 ~ 15 分ほど何も操作しないでください。
安全な消去が完了したら、POST 起動中に F9 をクリックして BIOS に戻ります。
[Embedded Applications] > [Integrated Management Log (IML)] > [View IML] > [OK] に移動します。[One-button secure erase completed](ワンボタンの安全な消去が完了しました)というメッセージが表示されます。

serversreset.pyという名前のファイルを作成し、次の Python スクリプトを追加します。import csv import argparse import requests import urllib3 import json urllib3.disable_warnings() PARSER = argparse.ArgumentParser(prog='secureerase.py', \ description='reset ilo to factory settings') PARSER.add_argument('-csv', '--file', help='choose the csv file', type=str) ARGS = vars(PARSER.parse_args()) headers = {'content-type': 'application/json'} payload = {'SystemROMAndiLOErase': True , 'UserDataErase': True} with open(ARGS['file'], encoding="utf8", mode='r') as csv_file: CSV_READER = csv.DictReader(csv_file) for row in CSV_READER: try: system = requests.post('https://'+row['ip']+'/redfish/v1/Systems/1/Actions/Oem/Hpe/HpeComputerSystemExt.SecureSystemErase/',data=json.dumps(payload),headers=headers,verify=False,auth=('administrator',row['passd'])) systemData = system.json() print(systemData) except Exception as err: print(err)次のコマンドを実行し、
example.csvを CSV ファイルに置き換えます。python serversreset.py -csv example.csvコマンドを実行すると、サーバーは電源オフ状態になります。サーバーの電源を手動でオンにする必要があります。
6.5. NetApp StorageGRID デバイスをリセットする
6.5.1. 前提条件
NetApp StorageGRID デバイスをリセットする前に、次の点を確認してください。 - ノード暗号化またはドライブ暗号化でシステムが有効になっている場合は、HSM サイトの暗号化を無効にするに記載されている手順を行う必要があります。それ以外の場合は、StorageGRID システムをリセットします。
6.5.2. Storage Controller ノードで StorageGRID HSM サイトの暗号化を無効にする
ストレージ コントローラ ノードの IP を取得するには(各ストレージ ノードに 2 つの IP があります)。
$ kubectl get objectstoragestoragenodes -n gpc-system -o custom-columns="NAME:metadata.name,COMPUTE_NODEA_IP:.spec.network.controllerAManagementIP,COMPUTE_NODEB_IP:.spec.network.controllerBManagementIP"
NAME COMPUTE_NODEA_IP COMPUTE_NODEB_IP
ak-ac-objs01 172.22.210.166/24 172.22.210.167/24
ak-ac-objs02 172.22.210.170/24 172.22.210.171/24
ak-ac-objs03 172.22.210.174/24 172.22.210.175/24
StorageGRID システムで HSM が有効になっている場合は、出荷時の設定にリセットする前に暗号化を削除する必要があります。デバイスをリセットする前に、各ストレージ ノードに対して次の手順を行います。そうしないと、ディスクとシステムがロックアウトされる可能性があります。
Object Storage サイトにログインし、サイドバーにあるノードのリストに移動します。
ストレージ ノードの名前をクリックします。
[SANtricity System Manager] タブに移動します。
[設定] > [システム] > [セキュリティ キーの管理] に移動します。

[外部鍵管理を無効にする] を選択し、パスフレーズを入力してバックアップ鍵をダウンロードします。
6.5.3. StorageGRID 管理ノードとストレージ コンピューティング ノードの出荷時設定へのリセット
管理ノードの IP を取得するには:
$ kubectl get objectstorageadminnodes -n gpc-system
NAME SITE NAME MANAGEMENT IP READY AGE
ak-ac-objsadm01 ak-obj-site-1 172.22.210.160/24 True 12d
ak-ac-objsadm02 ak-obj-site-1 172.22.210.162/24 True 12d
ストレージ コンピューティング ノードの IP を取得するには:
$ kubectl get objectstoragestoragenodes -n gpc-system
NAME SITE NAME MANAGEMENT IP READY AGE
ak-ac-objs01 ak-obj-site-1 172.22.210.164/24 True 12d
ak-ac-objs02 ak-obj-site-1 172.22.210.168/24 True 12d
ak-ac-objs03 ak-obj-site-1 172.22.210.172/24 True 12d
StorageGRID デバイスを初期状態にリセットするには、サイト内の各ノード(ストレージ ノードと管理ノードの両方)に対して次の手順を完了する必要があります。
各ノードの管理 IP を取得します。これは、cell.yaml から
ObjectStorageStorageNodeとObjectStorageAdminNodeを探すことで取得できます。これらは、ルート管理クラスタのノード リソースからも確認できます。パスワードを取得し、SSH を使用してノードに接続します。
ノードに StorageGRID がインストールされていない場合は、それぞれユーザー名とパスワードとして
admin/bycastまたはroot/netapp1!を使用します。ssh が機能しない場合は、SSH ポート 8022 を使用します。ノードに StorageGRID がインストールされているが、サイトの設定がない場合は、ユーザー名とパスワードにそれぞれ
admin/bycastまたはroot/bycastを使用します。サイトが設定されていて、ノードがサイトの一部である場合:
プロビジョニング パスフレーズを取得します。これは
grid-secretという名前のシークレットに保存され、cell.yaml ファイルにあります。必要に応じて、次のコマンドを実行できます。パスワードを Base64 でデコードしてください。echo $(kubectl get secret -n gpc-system grid-secret -ojsonpath="{.data.grid-management-provisioning-password}" | base64 -d)Object Storage Site UI で、[メンテナンス] > [システム] > [復元パッケージ] に移動し、プロビジョニング パスフレーズを入力して復元パッケージをダウンロードします。

ダウンロード後、tar ファイルを抽出します。このファイルには、別の tarball(
GIDXXXXX_REV1_SAID.zip)が含まれています。この tarball を解凍して、Passwords.txtファイルを見つけます。ssh と root アクセスの両方にPasswordを使用し、SSH Access Passwordは無視します。サンプル ファイル:
Password Data for Grid ID: 546285, Revision: 1 Revision Prepared on: 2022-06-13 20:49:56 +0000 Server "root" and "admin" Account Passwords Server Name Password SSH Access Password ____________________________________________________________ alatl14-gpcstgeadm01 <removed> <removed> alatl14-gpcstgeadm02 <removed> <removed> alatl14-gpcstgecn01 <removed> n/a alatl14-gpcstgecn02 <removed> n/a alatl14-gpcstgecn03 <removed> n/a
ノードのシリアル コンソールを開くか、SSH を使用してノードに接続します。
ssh -o ProxyCommand=None -o StrictHostKeyChecking=no \ -o UserKnownHostsFile=/dev/null admin@<node-management-ip>認証情報を入力してログインします。sudo 権限を取得するには、
su -と入力し、手順 2 で取得した root パスワードを入力します。コマンド
sgareinstallを入力し、yを押してデバイスのリセットを続行します。デバイスで暗号化が有効になっている場合は、リセットが完了したら、次の手順に沿ってディスク プールと SSD キャッシュを削除します。
6.5.4. ストレージ コントローラ ノードでディスクプールと SSD キャッシュを削除する
ストレージ コントローラ ノードの IP を取得するには(各ストレージ ノードに 2 つの IP があります)。
$ kubectl get objectstoragestoragenodes -n gpc-system -o custom-columns="NAME:metadata.name,COMPUTE_NODEA_IP:.spec.network.controllerAManagementIP,COMPUTE_NODEB_IP:.spec.network.controllerBManagementIP"
NAME COMPUTE_NODEA_IP COMPUTE_NODEB_IP
ak-ac-objs01 172.22.210.166/24 172.22.210.167/24
ak-ac-objs02 172.22.210.170/24 172.22.210.171/24
ak-ac-objs03 172.22.210.174/24 172.22.210.175/24
デバイスで暗号化が有効になっていて、最後のセクションの手順に沿ってノードがリセットされている場合は、ドライブを消去するとともにディスクプールを削除する必要があります。これは、サイトを再ブートストラップして新しいディスク プールを作成できるようにする前に行う必要があります。サイト内の各ストレージ ノード(e2860 ストレージ コントローラ)(controllerAManagementIP とも呼ばれます)に対して、次の手順を行います。
ウェブブラウザを開いて
https://<storage-node-controller-ip>:8443にアクセスし、認証情報を入力します。SANtricity の認証情報にアクセスできない場合は、こちらの手順に沿って操作します。[Storage] > [Pools & Volume Groups] に移動します。
SSD キャッシュを削除します。
SSD キャッシュを選択してハイライト表示します。
[Uncommon Tasks] プルダウン メニューを選択して、[削除] をクリックします。

ディスクプールを削除します。
ディスク プールを選択してハイライト表示します。
[Uncommon Tasks] プルダウン メニューを選択して、[削除] をクリックします。

新しいディスクプールを作成してみてください。作成をブロックし、ドライブの消去を求めるダイアログが表示されます。

割り当てられていないセキュリティ対応ドライブはプールの作成に使用できないため、最初に削除する必要があります。[はい - 処理で消去するドライブを選択します] ラジオボタンをクリックし、消去するドライブをすべて選択します。消去操作を確認し、[OK] をクリックします。新しいプールを作成する手順に進まないでください。
ノードの暗号化を削除するの手順に沿って操作します。
6.5.5. StorageGRID 管理ノードとストレージ コンピューティング ノードでノード暗号化を削除する
管理ノードの IP を取得するには:
$ kubectl get objectstorageadminnodes -n gpc-system
NAME SITE NAME MANAGEMENT IP READY AGE
ak-ac-objsadm01 ak-obj-site-1 172.22.210.160/24 True 12d
ak-ac-objsadm02 ak-obj-site-1 172.22.210.162/24 True 12d
ストレージ コンピューティング ノードの IP を取得するには:
$ kr get objectstoragestoragenodes -n gpc-system
NAME SITE NAME MANAGEMENT IP READY AGE
ak-ac-objs01 ak-obj-site-1 172.22.210.164/24 True 12d
ak-ac-objs02 ak-obj-site-1 172.22.210.168/24 True 12d
ak-ac-objs03 ak-obj-site-1 172.22.210.172/24 True 12d
デバイスで暗号化が有効になっており、こちらの手順に沿ってノードがリセットされ、こちらの手順に沿ってディスクプールと SSD キャッシュが削除されている場合は、各ノードで次の手順を実行してノードの暗号化を削除します。
StorageGRID Appliance Installer UI に移動します。
[Configure Hardware] > [Node Encryption] に移動します。
[KMS 鍵をクリアしてデータを削除] をクリックします。
![アプライアンス インストーラ UI の [Clear KMS Key] と [Delete Data]](https://cloud.google.com/static/distributed-cloud/hosted/docs/latest/gdch/infrastructure/images/app-installer-ui-clear-kms.png?authuser=0000&hl=ja)
クリアがトリガーされると、コントローラが再起動します。これには 15 分ほどかかることがあります。
6.5.6. StorageGRID を再インストールする
各ノードを手動で再起動します。
ノードのシリアル コンソールを開き、GRUB ブートローダー メニューをキャッチして、[StorageGRID Appliance: Force StorageGRID reinstall] を選択します。

6.5.7. SANtricity 認証情報を取得する
SANtricity コントローラのいずれか 1 つに対してシリアル コンソールを開きます。
次の認証情報を使用してログインします。
- ユーザー名:
spri - パスワード:
SPRIentry
- ユーザー名:
ログインすると、次のようなメニューが表示されます。
Service Interface Main Menu ============================== 1)Display IP Configuration 2)Change IP Configuration 3)Reset Storage Array Administrator Password 4)Display 7-segment LED codes 5)Disable SAML 6)Unlock remote admin account Q)Quit Menu Enter Selection: 3 Are you sure that you want to reset the Storage Array Password ? (Y/N): Y Storage Array Password reset successfulSANtricity コントローラにログインすると、パスワードのリセットが利用可能になります。
6.6. NetApp ONTAP デバイスをリセットする
6.6.1. 前提条件
NetApp ONTAP デバイスをリセットする前に、以下をよくお読みください。
システムが以前にハードウェア セキュリティ モジュール(HSM)で有効になっている場合は、ONTAP システムをリセットする前に、ハードウェア セキュリティ モジュールを無効にするで説明されている手順を実行する必要があります。
これは、鍵、バックアップ、バックアップ鍵、システムログなど、CipherTrust Manager のすべてのデータを消去する破壊的なオペレーションです。
すべてのデータとバックアップ鍵の有効な CipherTrust Manager バックアップがあることを確認します。
埋め込み HSM が使用可能な場合、このオペレーションの一部としてリセットされません。
省略可: このオペレーションの後に、組み込み HSM を信頼のルートとして構成するために、再初期化することを強くおすすめします。
リモート PIN 入力デバイス(PED)が使用された場合は、完了後に再接続する必要があります。
この操作には最長で 15 分ほどかかることがあります。電源バックアップが用意されていることを確認します。
6.6.2. ハードウェア セキュリティ モジュールを無効にする
システムが HSM を使用して以前に有効にされていた場合は、ONTAP システムをリセットする前に次の手順を行います。そうしないと、ディスクとシステムがロックアウトされる可能性があります。ONTAP クラスタで次のコマンドを実行します。
権限レベルを [詳細] に設定します。
set -privilege advancedディスクのデータ鍵と、使用している連邦情報処理標準(FIPS)認証鍵を一覧表示します。
storage encryption disk showシステム内のすべてのディスクについて、ノードのデータと FIPS 認証鍵 ID をデフォルトの MSID 0x0 に戻します。
storage encryption disk modify -disk * -fips-key-id 0x0 storage encryption disk modify -disk * -data-key-id 0x0次のコマンドを使用して、オペレーションが成功したことを確認します。
storage encryption disk show-statusDisks Begun == Disks Doneが返されるまでshow-statusコマンドを繰り返します。この出力は、オペレーションが完了したことを意味します。cluster1:: storage encryption disk show-status FIPS Latest Start Execution Disks Disks Disks Node Support Request Timestamp Time (sec) Begun Done Successful ------- ------- -------- ------------------ ---------- ------ ------ ---------- cluster1 true modify 1/18/2022 15:29:38 3 14 5 5 1 entry was displayed.外部鍵マネージャーの構成を削除します。
HSM 接続が確立されている場合は、ステップ f に直接進みます。HSM 接続がダウンしている場合は、ステップ b に進みます。
cluster1::> security key-manager external show-statusset -priv diagを実行してdiagモードに移動します。次のコマンドを実行して、すべてのボリューム暗号鍵を表示します。
debug smdb table kmip_external_key_cache_mdb_v2 show。プロパティ
vserver-idを収集します。すべての鍵サーバーで次のコマンドを実行して、鍵を削除します。
debug smdb table kmip_external_key_cache_mdb_v2 delete -vserver-id <vserver-id> -key-id * -key-server <key-server endpoint>ONTAP ユーザー インターフェース(UI)を使用してすべてのボリュームを削除するか、コンソールからボリュームを手動で削除します。
コンソールから削除する場合は、ノードのルート ボリュームを無視する必要があります。通常、これらの名前は
vol0で、ノードの 1 つがvserverになります。ノードがvserverであるボリュームは、通常は削除できません。削除しないでください。前の手順の
vol0以外のボリュームを UI から削除できない場合は、CLI を使用してみてください。cluster1::> vol offline -volume volume_to_be_deleted -vserver vserve-id cluster1::> vol delete -volume volume_to_be_deleted -vserver vserver-idUI からストレージ クラスタにログインするには、次のコマンドを使用してシークレットからユーザー名とパスワードを取得します。CELL_ID は、インストールするセルの固有 ID に置き換えます。
kubectl get secret -n gpc-system ontap-CELL_ID-stge-clus-01-credential -o jsonpath='{.data.netapp_username}' | base64 --decode kubectl get secret -n gpc-system ontap-CELL_ID-stge-clus-01-credential -o jsonpath='{.data.netapp_password}' | base64 --decode次に、[ボリューム] に移動して、すべてを選択し、[削除] をクリックします。各ページで複数回繰り返す必要があります。注: ボリュームの削除に失敗したというエラーは無視してかまいません。詳細については、NetApp ナレッジベースをご覧ください。
ag-stge-clus-01::*> vol show Vserver Volume Aggregate State Type Size Available Used% --------- ------------ ------------ ---------- ---- ---------- ---------- ----- ag-ad-stge01-01 vol0 aggr0_ag_ad_stge01_01 online RW 151.3GB 84.97GB 40% ag-ad-stge01-02 vol0 aggr0_ag_ad_stge01_02 online RW 151.3GB 86.69GB 39% ag-ad-stge02-01 vol0 aggr0_ag_ad_stge02_01 online RW 151.3GB 83.62GB 41% ag-ad-stge02-02 vol0 aggr0_ag_ad_stge02_02 online RW 151.3GB 85.97GB 40% ag-ad-stge03-01 vol0 aggr0_ag_ad_stge03_01 online RW 151.3GB 89.19GB 37% ag-ad-stge03-02 vol0 aggr0_ag_ad_stge03_02 online RW 151.3GB 88.74GB 38%
すべてのボリュームを削除したら、次のコマンドを実行して復元キューをパージします。
recovery-queue purge-all -vserver <vserver>次のコマンドを実行して、外部キー マネージャー
clusterl::> security key-manager external remove-servers -vserver <CLUSTER_NAME> -key-servers <IP1:PORT,IP2:PORT,...>を削除します。この手順の後、次のエラーが表示されることがあります。Error: command failed: The key server at "172.22.112.192" contains authentication keys that are currently in use and not available from any other configured key server.このエラーは、残りのキーがあることを示します。残りの鍵を削除する手順は次のとおりです。
残りの鍵を一覧表示するには、次のコマンドを実行します。
security key-manager key query出力は次のようになります。
Node: ag-ad-stge01-01 Vserver: ag-stge-clus-01 Key Manager: 172.22.112.192:5696 Key Manager Type: KMIP Key Manager Policy: - Key Tag Key Type Encryption Restored ------------------------------------ -------- ------------ -------- ag-ad-stge01-01 NSE-AK AES-256 true Key ID: 00000000000000000200000000000100454007f1854b3e3f5c90756bc5cfa6cc0000000000000000前の出力の [Key ID] の値をメモします。
security key-manager key delete -key-idコマンドとキー ID の値を使用して、残りのキーを削除します。security key-manager key delete -key-id 00000000000000000200000000000100454007f1854b3e3f5c90756bc5cfa6cc0000000000000000手順 i と j を繰り返して、残りのキーを削除します。完了すると、出力は次のようになります。
ag-stge-clus-01::*> security key-manager key query No matching keys found.6.6.3. ONTAP ノードをリセットする
ONTAP ノードをリセットするには:
システム プロンプトで
system node rebootコマンドを使用してノードを再起動し、ブートメニューにアクセスします。注: システムの再起動に関する警告は無視してかまいません。例:
ag-stge-clus-01::> system reboot -node ag-ad-stge03-02 Warning: Are you sure you want to reboot node "ag-ad-stge03-02"? {y|n}: y Error: Could not migrate LIFs away from node: Failed to migrate one or more LIFs away from node "ag-ad-stge03-02". Use the "network interface show -curr-node ag-ad-stge03-02" command to identify LIFs that could not be migrated off that node. Use the "network interface migrate" command to manually migrate the LIFs off the node. Reissue the command with "-skip-lif-migration-before-reboot" to skip the migration and continue with takeover. ag-stge-clus-01::> system reboot -node ag-ad-stge03-02 -skip-lif-migration-before-reboot Warning: Are you sure you want to reboot node "ag-ad-stge03-02"? {y|n}: y Connection to 172.22.115.134 closed.ag-stge-clus-01::> system reboot -node ag-ad-stge02-02 Error: command failed: Taking node "ag-ad-stge02-02" out of service might result in a data service failure and client disruption for the entire cluster. If possible, bring an additional node online to improve the resiliency of the cluster and to ensure continuity of service. Verify the health of the node using the "cluster show" command, then try the command again, or provide "-ignore-quorum-warnings" to bypass this check. ag-stge-clus-01::> system reboot -node ag-ad-stge02-02 -ignore-quorum-warnings Warning: Are you sure you want to reboot node "ag-ad-stge02-02"? {y|n}: y Error: Could not migrate LIFs away from node: Failed to migrate one or more LIFs away from node "ag-ad-stge02-02". Use the "network interface show -curr-node ag-ad-stge02-02" command to identify LIFs that could not be migrated off that node. Use the "network interface migrate" command to manually migrate the LIFs off the node. Reissue the command with "-skip-lif-migration-before-reboot" to skip the migration and continue with takeover. ag-stge-clus-01::> system reboot -node ag-ad-stge02-02 -ignore-quorum-warnings -skip-lif-migration-before-reboot Warning: Are you sure you want to reboot node "ag-ad-stge02-02"? {y|n}: y Connection to 172.22.115.132 closed.LOADERメニューが表示されている場合は、boot_ontapと入力して再起動を続行します。再起動プロセス中に、プロンプトが表示されたらCtrl-Cを押してブートメニューを表示します。ノードには、ブートメニューの次のオプションが表示されます。(1) Normal Boot. (2) Boot without /etc/rc. (3) Change password. (4) Clean configuration and initialize all disks. (5) Maintenance mode boot. (6) Update flash from backup config. (7) Install new software first. (8) Reboot node. (9) Configure Advanced Drive Partitioning Selection (1-9)?オプション
(9) Configure Advanced Drive Partitioningを選択します。ノードに次のオプションが表示されます。* Advanced Drive Partitioning Boot Menu Options * ************************************************* (9a) Destroy aggregates, unpartition all disks and remove their ownership information. (9b) Clean configuration and initialize node with partitioned disks. (9c) Clean configuration and initialize node with whole disks. (9d) Reboot the node. (9e) Return to main boot menu. (9f) Remove disk ownership.終了を求められたら、オプション
9aを選択してnoと入力します。ノードは9aの後に次のオプションを再度表示します。(9a) Unpartition all disks and remove their ownership information. (9b) Clean configuration and initialize node with partitioned disks. (9c) Clean configuration and initialize node with whole disks. (9d) Reboot the node. (9e) Return to main boot menu. ```続行する前に、クラスタに存在するすべてのストレージ ノードに対して
9aオペレーションを実行します。各ノードでオプション
9bを実行し、yesを入力して確定します。(9a) Unpartition all disks and remove their ownership information. (9b) Clean configuration and initialize node with partitioned disks. (9c) Clean configuration and initialize node with whole disks. (9d) Reboot the node. (9e) Return to main boot menu.HA ペアがある場合は、次のメッセージが表示されます。クラスタ内のすべてのノードで 9a が完了してから、9b を実行します。
Selection (9a-9f)?: 9b 9b Option (9a) MUST BE COMPLETED on BOTH nodes in an HA pair (and DR/DR-AUX partner nodes if applicable) prior to starting option (9b). Has option (9a) been completed on all the nodes (yes/no)? yes yes
メッセージ
Welcome to the cluster setup wizardが表示されたら、リセットは完了です。
6.7. Thales k570 をリセットする
Thales k570 をリセットするには、まず Ciphertrust Manager を出荷時設定にリセットし、次に Luna HSM 自体をリセットします。
6.7.1. システムを出荷時の設定にリセットする
HSM 認証情報の一時的な作業ディレクトリを作成します。
TMPPWDDIR=/run/user/$(id --user)/hsm mkdir -p $TMPPWDDIR chmod 700 $TMPPWDDIRHSM への SSH 接続を確立します。
export ADMIN_SSH_SECRET_NAME=`kubectl get secrets -n hsm-system -o json | jq .items[].metadata.name | tr -d '"' | grep "ssh"` kubectl get secret $ADMIN_SSH_SECRET_NAME \ --namespace=hsm-system \ --output jsonpath='{.data.ssh-privatekey}' \ | base64 --decode > $TMPPWDDIR/hsm-ssh-privatekey chmod 0600 $TMPPWDDIR/hsm-ssh-privatekey ssh -i $TMPPWDDIR/hsm-ssh-privatekey ksadmin@$HSM_MGMT_IPそれができない場合は、パソコンからコンソール ポートにシリアル ケーブルを使用して接続します。別のタブで次のコマンドを実行して、
ksadminパスワードを取得します。export KSADMIN_SECRET_NAME=`kubectl get secrets -n hsm-system -o json | jq .items[]metadata.name | tr -d '"' | grep "ksadmin"` kubectl get secret $KSADMIN_SECRET_NAME \ --namespace=hsm-system \ --output jsonpath='{.data.password}' \ | base64 --decodeシリアルにログインすると、ログイン プロンプトが表示されます。ユーザー名として
ksadminを入力し、前のコマンドのパスワードを貼り付けます。factory-resetコマンドを実行する前に:この間は、システムを再起動しないでください。再接続には複数のシステムの再起動が必要であり、元に戻すことはできません。
電源バックアップが用意されていることを確認します。
次のコマンドを実行して出荷時の設定にリセットします。
sudo /opt/keysecure/ks_reset_to_factory.shリセット プロセスが完了するまでに 10 分ほどかかります。
6.7.2. Luna HSM のリセット
システムの出荷時設定へのリセットでは、HSM から信頼のルートは消去されません。次のコマンドを実行して、Luna HSM をリセットします。
CipherTrust Manager ホスト内から、SSH またはシリアル コンソールを使用して次のコマンドを実行します。
/usr/safenet/lunaclient/bin/lunacmlunacm:> hsm factoryResetブートストラッパーから一時作業ディレクトリを削除します。
rm $TMPPWDDIR
6.8. ファイアウォールをリセットする
ファイアウォールを出荷時の設定にリセットする手順については、ファイアウォールの出荷時設定へのリセットをご覧ください。
6.9. Cisco スイッチをリセットする
次の手順に沿って、Cisco スイッチをリセットします。これらの手順は、stgesw などのストレージ スイッチにも適用されます。
- スイッチにログインします。
スイッチの書き込み、消去、再読み込みを行います。
write erase reloadスイッチが以前に構成されていて、
cellcfgディレクトリが使用可能な場合は、代わりに事前チェックのクリーンアップの手順に沿って操作できます。スイッチが Power On Auto Provisioning(POAP)状態であることを確認します。
スイッチが正しくリセットされると、コンソール サーバーを使用して接続したときに次のプロンプトが表示されます。
Abort Power On Auto Provisioning [yes - continue with normal setup, skip - bypass password and basic configuration, no - continue with Power On Auto Provisioning] (yes/skip/no)[no]:
6.10. リセット プロセスに関するその他のリソース
リセット プロセスの詳細については、次のリソースをご覧ください。
https://docs.netapp.com/us-en/ontap/system-admin/manage-node-boot-menu-task.htmlhttps://docs.netapp.com/us-en/ontap/encryption-at-rest/return-seds-unprotected-mode-task.html