Max Ross
Laut Wikipedia bestimmt die Isolationsebene eines Datenbankverwaltungssystems, wie und wann die von einem Vorgang vorgenommenen Änderungen für andere gleichzeitige Vorgänge sichtbar werden. In diesem Artikel wird die von App Engine in Cloud Datastore verwendete Isolation von Abfragen und Transaktionen erläutert. Dieser Artikel vermittelt Ihnen einen genaueren Einblick in das Verhalten von gleichzeitigen Lese- und Schreibvorgängen sowohl innerhalb als auch außerhalb von Transaktionen.
Innerhalb von Transaktionen: Serializable (Serialisierbar)
Die vier Isolationsebenen lauten von stark nach schwach: "Serializable" (Serialisierbar), "Repeatable Read" (Wiederholbarer Lesevorgang), "Read Committed" (Lesen mit Commit) und "Read Uncommitted" (Lesen ohne Commit). Datenspeichertransaktionen erfüllen die Bedingungen der Isolationsebene "Serializable". Jede Transaktion ist vollständig von sämtlichen anderen Datenspeichertransaktionen und -vorgängen isoliert. Transaktionen für eine bestimmte Entitätengruppe werden seriell ausgeführt, also eine nach der anderen.
Weitere Informationen finden Sie im Abschnitt Isolation und Konsistenz der Transaktionsdokumentation sowie im Wikipedia-Artikel zur Snapshot-Isolation.
Externe Transaktionen: Read Committed (Lesen mit Commit)
Datenspeichervorgänge außerhalb von Transaktionen weisen die größte Ähnlichkeit mit der Isolationsebene "Read Commit" (Lesen mit Commit) auf. Entitäten, die durch Abfragen oder Abrufe aus dem Datenspeicher abgerufen werden, sehen nur per Commit übertragene Daten. Abgerufene Entitäten haben niemals teilweise übergebene Daten, also einige aus der Zeit vor dem Commit-Vorgang und einige aus der Zeit danach. Die Interaktion zwischen Abfragen und Transaktionen ist jedoch etwas komplexer und, um sie zu verstehen, müssen wir uns den Commit-Prozess genauer ansehen.
Der Commit-Prozess
Bei einem Commit mit erfolgreicher Rückgabe wird die Transaktion garantiert angewendet, aber das bedeutet nicht, dass das Ergebnis eines Schreibvorgangs sofort für Leser sichtbar ist. Die Anwendung von Transaktionen besteht aus zwei Meilensteinen:
- Meilenstein A – der Punkt, an dem Änderungen an einer Entität angewendet wurden
- Meilenstein B – der Punkt, an dem Änderungen an den Indexen für diese Entität angewendet wurden
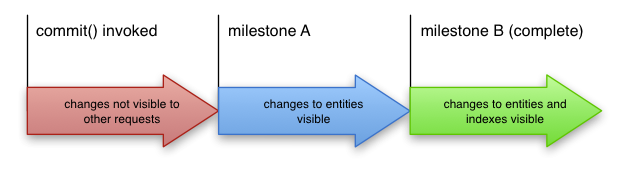
In Cloud Datastore wird die Transaktion normalerweise innerhalb einiger Hundert Millisekunden nach der Rückgabe des Commits vollständig angewendet. Aber auch wenn sie nicht vollständig angewendet wird, werden nachfolgende Lese-, Schreib- und Ancestor-Abfragen immer die Ergebnisse des Commits widerspiegeln, da diese Vorgänge alle ausstehenden Änderungen vor der Ausführung anwenden. Abfragen, die sich über mehrere Entitätengruppen erstrecken, können jedoch nicht feststellen, ob ausstehende Änderungen vor der Ausführung vorliegen, und können veraltete oder teilweise angewendete Ergebnisse zurückgeben.
Bei einer Anfrage, bei der nach Meilenstein A eine aktualisierte Entität anhand ihres Schlüssels abgefragt wird, wird garantiert die aktuellste Version der Entität verwendet. Wenn jedoch eine gleichzeitige Anfrage eine Abfrage ausführt, deren Prädikat (SQL/GQL-Klausel WHERE) nicht von der Entität erfüllt wird, bevor diese aktualisiert worden ist, jedoch von ihr erfüllt wird, nachdem sie aktualisiert worden ist, ist die Entität nur dann Teil der Ergebnismenge, wenn die Abfrage ausgeführt wird, nachdem der Anwendungsvorgang den Meilenstein B erreicht hat.
Mit anderen Worten ist es für einen kurzen Zeitraum möglich, dass eine Ergebnismenge keine Entität enthält, deren Attribute gemäß dem Ergebnis einer Schlüsselsuche das Abfrageprädikat erfüllen. Und umgekehrt ist es möglich, dass eine Ergebnismenge eine Entität enthält, deren Eigenschaften (wiederum laut dem Ergebnis eines Nachschlagens anhand des Schlüssels) das Abfrageprädikat nicht erfüllen. Bei einer Abfrage können Transaktionen, die zwischen Meilenstein A und Meilenstein B liegen, nicht berücksichtigt werden, wenn entschieden wird, welche Entitäten zurückgegeben werden sollen. Die Abfrage wird mit veralteten Daten durchgeführt, aber durch Ausführen eines get()-Vorgangs für die zurückgegebenen Schlüssel wird immer die neueste Version dieser Entität abgerufen. Das bedeutet, dass entweder Ergebnisse fehlen, die Ihrer Abfrage entsprechen, oder Ergebnisse zurückgegeben werden, die nicht übereinstimmen, sobald Sie die entsprechende Entität erhalten.
Es gibt Szenarien, in denen alle ausstehenden Änderungen garantiert vollständig angewendet werden, bevor die Abfrage ausgeführt wird, z. B. beliebige Ancestor-Abfragen in Cloud Datastore. In diesem Fall sind die Abfrageergebnisse immer aktuell und konsistent.
Beispiele
Wir haben eine allgemeine Erklärung dafür geliefert, wie gleichzeitige Aktualisierungen und Abfragen interagieren. Anhand konkreter Beispiele lassen sich diese Konzepte zusätzlich veranschaulichen. Sehen wir uns einige an. Wir beginnen mit einigen einfachen Beispielen und gehen dann zu den interessanteren über.
Angenommen, wir haben eine Anwendung, die Personenentitäten speichert. Eine Person hat die folgenden Attribute:
- Name
- Größe
Die Anwendung unterstützt folgende Vorgänge:
updatePerson()getTallPeople(), womit alle Personen über 1,83 m in die Ergebnisse einfließen.
Wir haben zwei Personenentitäten im Datenspeicher:
- Adam, der 1,73 m groß ist.
- Robert, der 1,85 m groß ist.
Beispiel 1 – Adams Körpergröße erhöhen
Angenommen, eine Anwendung erhält zwei Anforderungen praktisch gleichzeitig. Mit der ersten Anforderung wird die Größe von Adam von 1,73 m auf 1,88 m geändert. Ein Wachstumsschub! Die zweite Anfrage ruft getTallPeople() auf. Was gibt getTallPeople() zurück?
Die Antwort hängt von der Beziehung zwischen den beiden von Anfrage 1 ausgelösten Commit-Meilensteinen und der Abfrage „getTallPeople()“ ab, die durch Anfrage 2 ausgeführt wird. Angenommen, das Ganze sieht so aus:
- Anfrage 1,
put() - Anfrage 2,
getTallPeople() - Anfrage 1,
put()->commit() - Anfrage 1,
put()->commit()-> Meilenstein A - Anfrage 1,
put()->commit()-> Meilenstein B
In diesem Szenario gibt getTallPeople() nur Robert zurück. Warum? Weil die Aktualisierung für Adam, mit der seine Größe erhöht wird, noch nicht in einem Commit-Vorgang übergeben wurde. Die Änderung ist somit für die in Anfrage 2 ausgegebene Abfrage noch nicht sichtbar.
Nehmen wir nun an, das Ganze sieht so aus:
- Anfrage 1,
put() - Anfrage 1,
put()->commit() - Anfrage 1,
put()->commit()-> Meilenstein A - Anfrage 2,
getTallPeople() - Anfrage 1,
put()->commit()-> Meilenstein B
In diesem Szenario wird die Abfrage ausgeführt, bevor Anfrage 1 Meilenstein B erreicht. Die Aktualisierungen an den Personenindexen wurden also noch nicht übernommen. Daher gibt getTallPeople() nur Robert zurück. Dies ist ein Beispiel für eine Ergebnismenge, bei der eine Entität nicht enthalten ist, deren Eigenschaften das Abfrageprädikat erfüllen.
Beispiel 2 – Roberts Körpergröße reduzieren
In diesem Beispiel lassen wir von Anfrage 1 eine andere Aktion durchführen. Anstatt Adams Körpergröße von 1,73 m auf 1,88 m zu erhöhen, verringern wir Roberts Körpergröße von 1,85 m auf 1,65 m. Und was gibt getTallPeople() in diesem Fall
- Anfrage 1,
put() - Anfrage 2,
getTallPeople() - Anfrage 1,
put()->commit() - Anfrage 1,
put()->commit()-> Meilenstein A - Anfrage 1,
put()->commit()-> Meilenstein B
In diesem Szenario gibt getTallPeople() nur Robert zurück. Warum? Weil die Aktualisierung für Robert, mit der seine Größe verringert wird, noch nicht in einem Commit-Vorgang übergeben wurde. Die Änderung ist somit für die in Anfrage 2 ausgegebene Abfrage noch nicht sichtbar.
Nehmen wir nun an, das Ganze sieht so aus:
- Anfrage 1,
put() - Anfrage 1,
put()->commit() - Anfrage 1,
put()->commit()-> Meilenstein A - Anfrage 1,
put()->commit()-> Meilenstein B - Anfrage 2,
getTallPeople()
In diesem Szenario gibt getTallPeople() niemanden zurück. Warum? Weil die Aktualisierung für Robert, mit der seine Größe verringert wird, zum Zeitpunkt der Ausgabe unserer Abfrage in Anfrage 2 bereits in einem Commit-Vorgang übergeben wurde.
Nehmen wir nun an, das Ganze sieht so aus:
- Anfrage 1,
put() - Anfrage 1,
put()->commit() - Anfrage 1,
put()->commit()-> Meilenstein A - Anfrage 2,
getTallPeople() - Anfrage 1,
put()->commit()-> Meilenstein B
In diesem Szenario wird die Abfrage vor Meilenstein B ausgeführt. Die Aktualisierungen an den Personenindexen wurden also noch nicht übernommen. Infolgedessen gibt getTallPeople() weiterhin Robert zurück, doch die Größeneigenschaft der Personenentität, die zurückgegeben wird, weist den aktualisierten Wert 1,65 m auf. Dies ist ein Beispiel für eine Ergebnismenge, bei der eine Entität eingeschlossen ist, deren Eigenschaften das Abfrageprädikat nicht erfüllen.
Fazit
Wie Sie anhand der obigen Beispiele sehen können, liegt die Transaktionsisolationsebene von Cloud Datastore nahe bei „Read Committed“ (Lesen mit Commit). Es gibt natürlich bedeutende Unterschiede, aber da Sie diese Unterschiede und die Gründe dafür nun kennen, sollten Sie besser in der Lage sein, intelligente, datenspeicherbezogene Designentscheidungen bei Ihren Anwendungen zu treffen.