Max Ross
De acordo com a Wikipedia, o nível de isolamento de um sistema de gestão de base de dados "define como/quando as alterações feitas por uma operação se tornam visíveis para outras operações simultâneas". O objetivo deste artigo é explicar o isolamento de consultas e transações no Cloud Datastore usado pelo App Engine. Depois de ler este artigo, deve compreender melhor o comportamento das leituras e escritas simultâneas, tanto dentro como fora das transações.
Transações internas: serializáveis
Por ordem da mais forte para a mais fraca, os quatro níveis de isolamento são: Serializable, Repeatable Read, Read Committed e Read Uncommitted. As transações do Datastore satisfazem o nível de isolamento serializável. Cada transação está completamente isolada de todas as outras transações e operações do arquivo de dados. As transações num determinado grupo de entidades são executadas em série, uma após a outra.
Consulte a secção Isolamento e consistência da documentação de transações para mais informações, bem como o artigo da Wikipédia sobre o isolamento de instantâneos.
Transações externas: leitura confirmada
As operações do Datastore fora das transações assemelham-se mais ao nível de isolamento Read Committed. As entidades obtidas a partir do arquivo de dados por consultas ou obtenções só veem dados comprometidos. Uma entidade obtida nunca tem dados parcialmente confirmados (alguns de antes de uma confirmação e alguns de depois). No entanto, a interação entre as consultas e as transações é um pouco mais subtil e, para a compreender, temos de analisar o processo de confirmação mais detalhadamente.
O processo de consolidação
Quando uma confirmação é devolvida com êxito, a transação é garantidamente aplicada, mas isso não significa que o resultado da sua gravação seja imediatamente visível para os leitores. A aplicação de uma transação consiste em dois marcos:
- Marco A: o ponto em que as alterações a uma entidade foram aplicadas
- Marco B: o ponto em que as alterações aos índices dessa entidade foram aplicadas
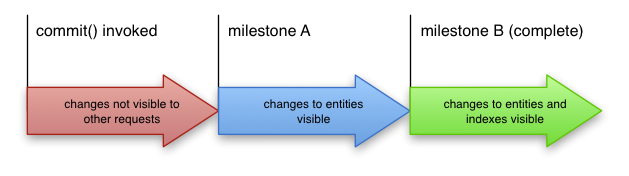
No Cloud Datastore, a transação é normalmente aplicada na totalidade no prazo de algumas centenas de milissegundos após o retorno da confirmação. No entanto, mesmo que não seja completamente aplicada, as leituras, as escritas e as consultas de antepassados subsequentes refletem sempre os resultados da confirmação, porque estas operações aplicam quaisquer modificações pendentes antes da execução. No entanto, as consultas que abrangem vários grupos de entidades não podem determinar se existem modificações pendentes antes da execução e podem devolver resultados desatualizados ou parcialmente aplicados.
Um pedido que procure uma entidade atualizada pela respetiva chave num momento posterior ao marco A tem a garantia de ver a versão mais recente dessa entidade. No entanto, se um pedido concorrente executar uma consulta cujo predicado (a cláusula WHERE, para os fãs de SQL/GQL) não for satisfeito pela entidade pré-atualização, mas for satisfeito pela entidade pós-atualização, a entidade fará parte do conjunto de resultados apenas se a consulta for executada depois de a operação de aplicação ter atingido o marco B.
Por outras palavras, durante breves períodos, é possível que um conjunto de resultados não inclua uma entidade cujas propriedades, de acordo com o resultado de uma pesquisa por chave, satisfaçam o predicado da consulta. Também é possível que um conjunto de resultados inclua uma entidade cujas propriedades, novamente de acordo com o resultado de uma pesquisa por chave, não satisfaçam o predicado de consulta. Uma consulta não pode ter em conta as transações que se encontram entre o marco A e o marco B ao decidir que entidades devolver. É realizada em dados desatualizados, mas a execução de uma operação get() nas chaves devolvidas obtém sempre a versão mais recente dessa entidade. Isto significa que pode não encontrar resultados que correspondam à sua consulta ou receber resultados que não correspondam quando obtiver a entidade correspondente.
Existem cenários em que é garantido que todas as modificações pendentes são aplicadas completamente antes da execução da consulta, como qualquer consulta de antepassados no Cloud Datastore. Neste caso, os resultados da consulta estão sempre atualizados e são consistentes.
Exemplos
Fornecemos uma explicação geral de como as atualizações e as consultas simultâneas interagem, mas, se for como eu, normalmente, é mais fácil compreender estes conceitos através de exemplos concretos. Vejamos alguns exemplos. Vamos começar com alguns exemplos simples e, em seguida, terminar com os mais interessantes.
Suponhamos que temos uma aplicação que armazena entidades de pessoas. Uma pessoa tem as seguintes propriedades:
- Nome
- Altura
Esta aplicação suporta as seguintes operações:
updatePerson()getTallPeople(), que devolve todas as pessoas com mais de 183 cm de altura.
Temos 2 entidades Person na base de dados:
- O Adam, que tem 172,72 cm de altura.
- O Bob, que tem 185 cm de altura.
Exemplo 1 – Aumentar a altura de Adam
Suponhamos que uma aplicação recebe dois pedidos praticamente ao mesmo tempo. O primeiro pedido atualiza a altura de Adam de 173 cm para 188 cm. Um estirão de crescimento! O segundo pedido chama getTallPeople(). O que é devolvido por getTallPeople()?
A resposta depende da relação entre os dois marcos de confirmação acionados pelo pedido 1 e a consulta getTallPeople() executada pelo pedido 2. Suponhamos que tem este aspeto:
- Pedido 1,
put() - Pedido 2,
getTallPeople() - Request 1,
put()-->commit() - Pedido 1,
put()-->commit()-->marco A - Pedido 1,
put()-->commit()-->milestone B
Neste cenário, getTallPeople() só devolve o nome Bob. Porquê? Uma vez que a atualização de Adam que aumenta a sua altura ainda não foi confirmada, a alteração ainda não está visível para a consulta que emitimos no pedido 2.
Agora, suponhamos que tem este aspeto:
- Pedido 1,
put() - Request 1,
put()-->commit() - Pedido 1,
put()-->commit()-->marco A - Pedido 2,
getTallPeople() - Pedido 1,
put()-->commit()-->milestone B
Neste cenário, a consulta é executada antes de o pedido 1 atingir o marco B, pelo que as atualizações aos índices de pessoas ainda não foram aplicadas. Como resultado, getTallPeople() só devolve o João. Este é um exemplo de um conjunto de resultados que exclui uma entidade cujas propriedades satisfazem o predicado de consulta.
Exemplo 2: encurtar o Bob (desculpa, Bob)
Neste exemplo, vamos fazer com que o pedido 1 faça algo diferente. Em vez de aumentar a altura do Adam de 173 cm para 188 cm, vai reduzir a altura do Bob de 185 cm para 165 cm. Mais uma vez, o que significa
getTallPeople()
- Pedido 1,
put() - Pedido 2,
getTallPeople() - Request 1,
put()-->commit() - Pedido 1,
put()-->commit()-->marco A - Pedido 1,
put()-->commit()-->milestone B
Neste cenário, getTallPeople() devolve apenas o João. Porquê? Isto acontece porque
a atualização de Bob que diminui a sua altura ainda não foi confirmada,
pelo que a alteração ainda não está visível para a consulta que emitimos no pedido 2.
Agora, suponhamos que tem este aspeto:
- Pedido 1,
put() - Request 1,
put()-->commit() - Pedido 1,
put()-->commit()-->marco A - Pedido 1,
put()-->commit()-->milestone B - Pedido 2,
getTallPeople()
Neste cenário, getTallPeople() não devolve ninguém. Porquê? Porque a atualização de Bob que diminui a sua altura foi confirmada quando emitimos a nossa consulta no pedido 2.
Agora, suponhamos que tem este aspeto:
- Pedido 1,
put() - Request 1,
put()-->commit() - Pedido 1,
put()-->commit()-->marco A - Pedido 2,
getTallPeople() - Pedido 1,
put()-->commit()-->milestone B
Neste cenário, a consulta é executada antes do marco B, pelo que as atualizações
aos índices de pessoas ainda não foram aplicadas. Como resultado,
getTallPeople() continua a devolver Bob, mas a propriedade de altura da entidade Person
que é devolvida é o valor atualizado: 65. Este é um exemplo de um conjunto de resultados que inclui uma entidade cujas propriedades não satisfazem o predicado de consulta.
Conclusão
Como pode ver nos exemplos acima, o nível de isolamento de transações do Cloud Datastore é bastante semelhante ao Read Committed. Claro que existem diferenças significativas, mas agora que compreende estas diferenças e os motivos subjacentes, deve estar em melhor posição para tomar decisões de design inteligentes relacionadas com o armazenamento de dados nas suas aplicações.