Max Ross
위키백과에 따르면 데이터베이스 관리 시스템의 격리 수준은 '한 작업의 변경사항을 다른 동시 작업에서 볼 수 있는 방법과 시기를 정의'합니다. 이 문서의 목표는 App Engine에서 사용하는 Cloud Datastore의 쿼리 및 트랜잭션 격리를 설명하는 것입니다. 이 문서를 읽고 나면 트랜잭션 내부 및 외부에서 동시 읽기와 쓰기 작동 방식을 더 잘 이해할 수 있습니다.
트랜잭션 내부: 직렬화 가능
가장 강한 격리부터 가장 약한 격리 순서로 4개의 격리 수준은 직렬화 가능, 반복 가능 읽기, 커밋된 읽기, 커밋되지 않은 읽기입니다. Datastore 트랜잭션은 직렬화 가능 격리 수준을 충족합니다. 각 트랜잭션은 다른 모든 Datastore 트랜잭션 및 작업과 완전히 격리됩니다. 주어진 항목 그룹의 트랜잭션은 차례에 따라 연속적으로 실행됩니다.
자세한 내용은 트랜잭션 문서의 격리 및 일관성 섹션과 스냅샷 격리에 대한 위키백과 문서를 참조하세요.
트랜잭션 외부: 커밋된 읽기
트랜잭션 외부의 Datastore 작업은 커밋된 읽기 수준과 유사합니다. 쿼리 또는 가져오기로 Datastore에서 검색된 항목은 커밋된 데이터만 봅니다. 검색된 항목은 부분적으로 커밋된 데이터(커밋 이전과 이후의 일부 데이터)를 갖지 않습니다. 그러나 쿼리와 트랜잭션 간의 상호작용은 그렇게 단순하지 않습니다. 이를 이해하려면 커밋 프로세스를 더 자세히 살펴봐야 합니다.
커밋 프로세스
커밋이 성공적으로 반환되면 트랜잭션 적용이 보장되지만 이것이 쓰기의 결과가 리더에 즉시 표시된다는 의미는 아닙니다. 트랜잭션 적용은 다음의 두 마일스톤으로 구성됩니다.
- 마일스톤 A - 항목에 대한 변경사항이 적용된 지점
- 마일스톤 B - 해당 항목의 색인에 대한 변경사항이 적용된 지점
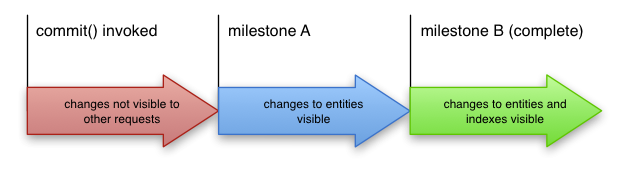
Cloud Datastore에서 트랜잭션은 일반적으로 커밋이 반환된 후 수백 밀리초 내에 완전히 적용됩니다. 완전히 적용되지 않은 경우에도 후속 읽기, 쓰기, 상위 쿼리는 항상 커밋의 결과를 반영합니다. 이러한 작업은 실행 전에 모든 미해결 수정을 적용하기 때문입니다. 단, 여러 항목 그룹에 걸친 쿼리는 실행 전에 해결되지 않은 수정사항이 있는지 여부를 확인할 수 없으며 비활성 결과 또는 일부만 적용된 결과를 반환할 수 있습니다.
마일스톤 A 이후 시점에서 업데이트된 항목을 키로 조회하는 요청은 해당 항목의 최신 버전을 보게 됩니다. 그러나 동시 요청에서 조건자(SQL/GQL 사용자를 위한 WHERE 절)가 업데이트 전 항목에 의해 충족되지 않지만 업데이트 후 항목에 의해 충족되는 쿼리를 실행하는 경우 쿼리가 적용 작업이 마일스톤 B에 도달한 후에 실행된 경우에 한해 결과 집합의 일부로 항목이 포함됩니다.
즉, 키에 의한 조회 결과 속성이 쿼리 조건자를 충족하는 항목이 짧은 기간 동안 결과 집합에 포함되지 않을 가능성이 있습니다. 또한 마찬가지로 키에 의한 조회 결과 속성이 쿼리 조건자를 충족하지 않는 항목이 결과 집합에 포함될 가능성도 있습니다. 쿼리는 반환할 항목을 결정할 때 마일스톤 A와 마일스톤 B 사이에 있는 트랜잭션을 고려할 수 없습니다. 비활성 데이터에 대해 수행되지만 반환된 키에 대한 get() 작업은 항상 해당 항목의 최신 버전을 가져옵니다. 즉, 쿼리와 일치하는 결과가 누락되거나 해당 항목을 가져온 후 일치하지 않는 결과를 얻을 수 있습니다.
Cloud Datastore의 모든 상위 쿼리와 같이 쿼리가 실행되기 전에 대기중인 모든 수정사항이 완전히 적용되는 시나리오가 있습니다. 이 경우 쿼리 결과는 항상 최신, 일관적 상태로 유지됩니다.
예시
동시 업데이트와 쿼리가 상호작용하는 방식을 개략적으로 설명했지만 구체적인 예시를 보면 이러한 개념을 더 쉽게 이해할 수 있습니다. 몇 가지를 살펴보겠습니다. 간단한 예시부터 시작한 다음 더 흥미로운 예시로 마무리하겠습니다.
Person 항목을 저장하는 애플리케이션이 있다고 가정해 보겠습니다. Person에는 다음과 같은 속성이 있습니다.
- 이름
- Height
이 애플리케이션은 다음 작업을 지원합니다.
updatePerson()getTallPeople(): 신장이 72인치를 초과하는 모든 사람을 반환합니다.
Datastore에 2개의 Person 항목이 있습니다.
- Adam, 신장 68인치
- Bob, 신장 73인치
예시 1 - Adam 키 늘리기
애플리케이션이 사실상 동시에 2개의 요청을 받는다고 가정해 보겠습니다. 첫 번째 요청은 Adam의 신장을 68인치에서 74인치로 업데이트합니다. 급성장이군요! 두 번째 요청은 getTallPeople()을 호출합니다. getTallPeople()은 무엇을 반환할까요?
답은 요청 1에 의해 트리거된 두 커밋 마일스톤과 요청 2에 의해 실행된 getTallPeople() 쿼리 사이의 관계에 따라 달라집니다. 다음과 같이 가정해 보겠습니다.
- 요청 1,
put() - 요청 2,
getTallPeople() - 요청 1,
put()-->commit() - 요청 1,
put()-->commit()-->마일스톤 A - 요청 1,
put()-->commit()-->마일스톤 B
이 시나리오에서 getTallPeople()은 Bob만 반환합니다. 왜일까요? Adam의 키를 늘리는 업데이트가 아직 커밋되지 않았고, 따라서 요청 2에서 실행한 쿼리가 아직 변경사항을 볼 수 없기 때문입니다.
이제 다음과 같이 가정해 보겠습니다.
- 요청 1,
put() - 요청 1,
put()-->commit() - 요청 1,
put()-->commit()-->마일스톤 A - 요청 2,
getTallPeople() - 요청 1,
put()-->commit()-->마일스톤 B
이 시나리오에서 쿼리는 요청 1이 마일스톤 B에 도달하기 전에 실행되므로 Person 색인의 업데이트가 아직 적용되지 않았습니다. 따라서 getTallPeople()은 Bob만 반환합니다. 이는 속성이 쿼리 조건자를 충족하는 항목이 제외되는 결과 집합의 예시입니다.
예시 2 - Bob 신장 줄이기(Bob에게는 미안하지만)
이 예시에서 요청 1은 다른 작업을 수행합니다. Adam의 신장을 68인치에서 74인치로 늘리는 대신 Bob의 신장을 73인치에서 65인치로 줄입니다. 이번에 getTallPeople()은
- 요청 1,
put() - 요청 2,
getTallPeople() - 요청 1,
put()-->commit() - 요청 1,
put()-->commit()-->마일스톤 A - 요청 1,
put()-->commit()-->마일스톤 B
이 시나리오에서 getTallPeople()은 Bob만 반환합니다. 왜일까요? Bob의 키를 줄이는 업데이트가 아직 커밋되지 않았고, 따라서 요청 2에서 실행한 쿼리가 아직 변경사항을 볼 수 없기 때문입니다.
이제 다음과 같이 가정해 보겠습니다.
- 요청 1,
put() - 요청 1,
put()-->commit() - 요청 1,
put()-->commit()-->마일스톤 A - 요청 1,
put()-->commit()-->마일스톤 B - 요청 2,
getTallPeople()
이 시나리오에서는 getTallPeople()은 누구도 반환하지 않습니다. 왜일까요? 요청 2에서 쿼리를 실행한 시점에 Bob의 키를 줄이는 업데이트는 커밋된 상태이기 때문입니다.
이제 다음과 같이 가정해 보겠습니다.
- 요청 1,
put() - 요청 1,
put()-->commit() - 요청 1,
put()-->commit()-->마일스톤 A - 요청 2,
getTallPeople() - 요청 1,
put()-->commit()-->마일스톤 B
이 시나리오에서 쿼리는 마일스톤 B 전에 실행되므로 Person 색인에 대한 업데이트가 아직 적용되지 않았습니다. 결과적으로 getTallPeople()은 여전히 Bob을 반환하지만 반환되는 Person 항목의 height 속성은 업데이트된 값인 65입니다. 이는 속성이 쿼리 조건자를 충족하지 않는 항목이 결과 집합에 포함되는 예시입니다.
결론
위 예시에서 볼 수 있듯이 Cloud Datastore의 트랜잭션 격리 수준은 커밋된 읽기와 매우 비슷합니다. 물론 유의미한 차이점이 있습니다. 이제 이러한 차이점과 그 이유를 이해했으므로 여러분의 애플리케이션에서 더 현명한 Datastore 관련 의사 결정을 내릴 수 있을 것입니다.