Dokumen ini menjelaskan cara menggunakan Jelajah Katalog Universal Dataplex untuk mendeteksi anomali dalam set data transaksi retail.
Workbench eksplorasi data, atau Jelajahi, memungkinkan analis data membuat kueri dan menjelajahi set data besar secara interaktif dalam waktu nyata. Jelajahi membantu Anda mendapatkan insight dari data, dan memungkinkan Anda membuat kueri data yang disimpan di Cloud Storage dan BigQuery. Jelajahi penggunaan platform Spark serverless, sehingga Anda tidak perlu mengelola dan menskalakan infrastruktur yang mendasarinya.
Tujuan
Tutorial ini menunjukkan kepada Anda cara menyelesaikan tugas-tugas berikut:
- Gunakan workbench Spark SQL Jelajah untuk menulis dan menjalankan kueri Spark SQL.
- Gunakan notebook JupyterLab untuk melihat hasilnya.
- Jadwalkan notebook untuk eksekusi berulang, sehingga Anda dapat memantau anomali data.
Biaya
Dalam dokumen ini, Anda akan menggunakan komponen Google Cloudyang dapat ditagih berikut:
Untuk membuat perkiraan biaya berdasarkan proyeksi penggunaan Anda,
gunakan kalkulator harga.
Setelah menyelesaikan tugas yang dijelaskan dalam dokumen ini, Anda dapat menghindari penagihan berkelanjutan dengan menghapus resource yang Anda buat. Untuk mengetahui informasi selengkapnya, lihat Pembersihan.
Sebelum memulai
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
Install the Google Cloud CLI.
-
If you're using an external identity provider (IdP), you must first sign in to the gcloud CLI with your federated identity.
-
To initialize the gcloud CLI, run the following command:
gcloud init -
Create or select a Google Cloud project.
-
Create a Google Cloud project:
gcloud projects create PROJECT_ID
Replace
PROJECT_IDwith a name for the Google Cloud project you are creating. -
Select the Google Cloud project that you created:
gcloud config set project PROJECT_ID
Replace
PROJECT_IDwith your Google Cloud project name.
-
-
Make sure that billing is enabled for your Google Cloud project.
-
Install the Google Cloud CLI.
-
If you're using an external identity provider (IdP), you must first sign in to the gcloud CLI with your federated identity.
-
To initialize the gcloud CLI, run the following command:
gcloud init -
Create or select a Google Cloud project.
-
Create a Google Cloud project:
gcloud projects create PROJECT_ID
Replace
PROJECT_IDwith a name for the Google Cloud project you are creating. -
Select the Google Cloud project that you created:
gcloud config set project PROJECT_ID
Replace
PROJECT_IDwith your Google Cloud project name.
-
-
Make sure that billing is enabled for your Google Cloud project.
Menyiapkan data untuk eksplorasi
Download file Parquet,
retail_offline_sales_march.Buat bucket Cloud Storage bernama
offlinesales_curatedsebagai berikut:- In the Google Cloud console, go to the Cloud Storage Buckets page.
- Click Create.
- On the Create a bucket page, enter your bucket information. To go to the next
step, click Continue.
-
In the Get started section, do the following:
- Enter a globally unique name that meets the bucket naming requirements.
- To add a
bucket label,
expand the Labels section (),
click add_box
Add label, and specify a
keyand avaluefor your label.
-
In the Choose where to store your data section, do the following:
- Select a Location type.
- Choose a location where your bucket's data is permanently stored from the Location type drop-down menu.
- If you select the dual-region location type, you can also choose to enable turbo replication by using the relevant checkbox.
- To set up cross-bucket replication, select
Add cross-bucket replication via Storage Transfer Service and
follow these steps:
Set up cross-bucket replication
- In the Bucket menu, select a bucket.
In the Replication settings section, click Configure to configure settings for the replication job.
The Configure cross-bucket replication pane appears.
- To filter objects to replicate by object name prefix, enter a prefix that you want to include or exclude objects from, then click Add a prefix.
- To set a storage class for the replicated objects, select a storage class from the Storage class menu. If you skip this step, the replicated objects will use the destination bucket's storage class by default.
- Click Done.
-
In the Choose how to store your data section, do the following:
- Select a default storage class for the bucket or Autoclass for automatic storage class management of your bucket's data.
- To enable hierarchical namespace, in the Optimize storage for data-intensive workloads section, select Enable hierarchical namespace on this bucket.
- In the Choose how to control access to objects section, select whether or not your bucket enforces public access prevention, and select an access control method for your bucket's objects.
-
In the Choose how to protect object data section, do the
following:
- Select any of the options under Data protection that you
want to set for your bucket.
- To enable soft delete, click the Soft delete policy (For data recovery) checkbox, and specify the number of days you want to retain objects after deletion.
- To set Object Versioning, click the Object versioning (For version control) checkbox, and specify the maximum number of versions per object and the number of days after which the noncurrent versions expire.
- To enable the retention policy on objects and buckets, click the Retention (For compliance) checkbox, and then do the following:
- To enable Object Retention Lock, click the Enable object retention checkbox.
- To enable Bucket Lock, click the Set bucket retention policy checkbox, and choose a unit of time and a length of time for your retention period.
- To choose how your object data will be encrypted, expand the Data encryption section (), and select a Data encryption method.
- Select any of the options under Data protection that you
want to set for your bucket.
-
In the Get started section, do the following:
- Click Create.
Upload file
offlinesales_march_parquetyang Anda download ke bucket Cloud Storageofflinesales_curatedyang Anda buat, dengan mengikuti langkah-langkah di Mengupload objek dari sistem file.Buat Dataplex Universal Catalog lake dan beri nama
operations, dengan mengikuti langkah-langkah di Membuat data lake.Di lake
operations, tambahkan zona dan beri namaprocurement, dengan mengikuti langkah-langkah di Menambahkan zona.Di zona
procurement, tambahkan bucket Cloud Storageofflinesales_curatedyang Anda buat sebagai aset, dengan mengikuti langkah-langkah di Menambahkan aset.
Pilih tabel yang akan dijelajahi
Di konsol Google Cloud , buka halaman Jelajahi Katalog Universal Dataplex.
Di kolom Lake, pilih danau
operations.Klik danau
operations.Buka zona
procurementdan klik tabel untuk menjelajahi metadatanya.Pada gambar berikut, zona pengadaan yang dipilih memiliki tabel bernama
Offline, yang memiliki metadata:orderid,product,quantityordered,unitprice,orderdate, danpurchaseaddress.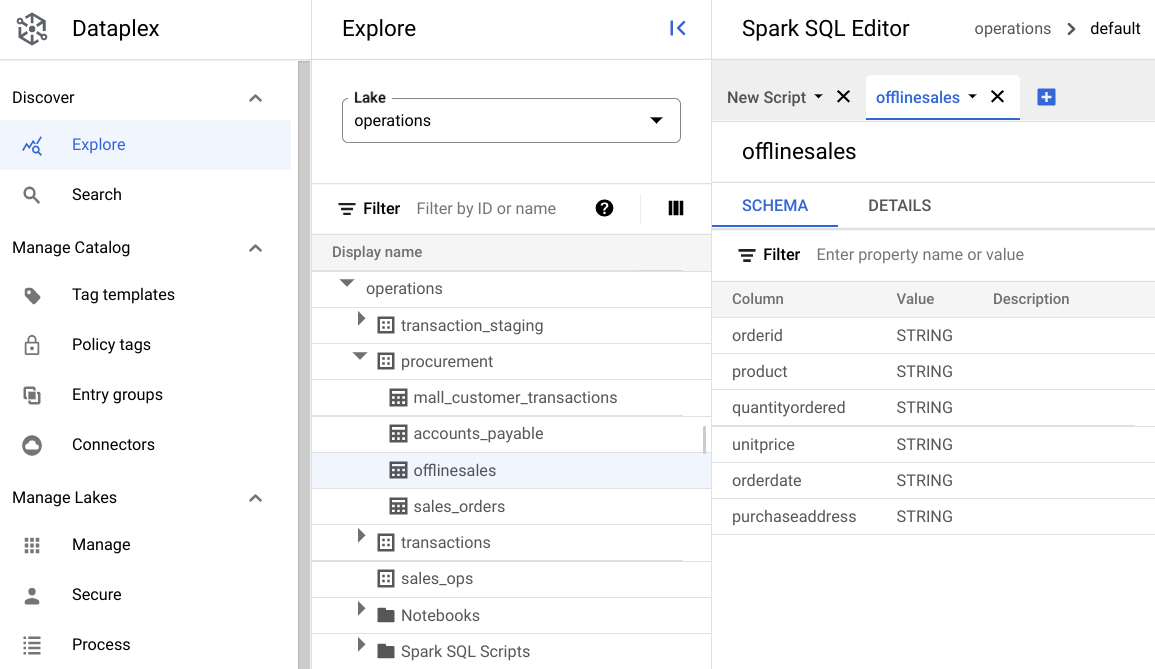
Di Spark SQL Editor, klik Add. Skrip Spark SQL akan muncul.
Opsional: Buka skrip dalam tampilan tab terpisah untuk melihat metadata dan skrip baru secara berdampingan. Klik Lainnya di tab skrip baru, lalu pilih Pisahkan tab ke kanan atau Pisahkan tab ke kiri.
Menjelajahi data
Lingkungan menyediakan resource komputasi serverless untuk kueri dan notebook Spark SQL Anda agar dapat berjalan dalam data lake. Sebelum menulis kueri Spark SQL, buat lingkungan tempat menjalankan kueri.
Jelajahi data Anda menggunakan kueri SparkSQL berikut. Di SparkSQL Editor, masukkan kueri ke panel New Script.
Contoh 10 baris tabel
Masukkan kueri berikut:
select * from procurement.offlinesales where orderid != 'orderid' limit 10;Klik Run.
Mendapatkan jumlah total transaksi dalam set data
Masukkan kueri berikut:
select count(*) from procurement.offlinesales where orderid!='orderid';Klik Run.
Menemukan jumlah jenis produk yang berbeda dalam set data
Masukkan kueri berikut:
select count(distinct product) from procurement.offlinesales where orderid!='orderid';Klik Run.
Menemukan produk yang memiliki nilai transaksi besar
Pahami produk mana yang memiliki nilai transaksi besar dengan mengelompokkan penjualan menurut jenis produk dan harga jual rata-rata.
Masukkan kueri berikut:
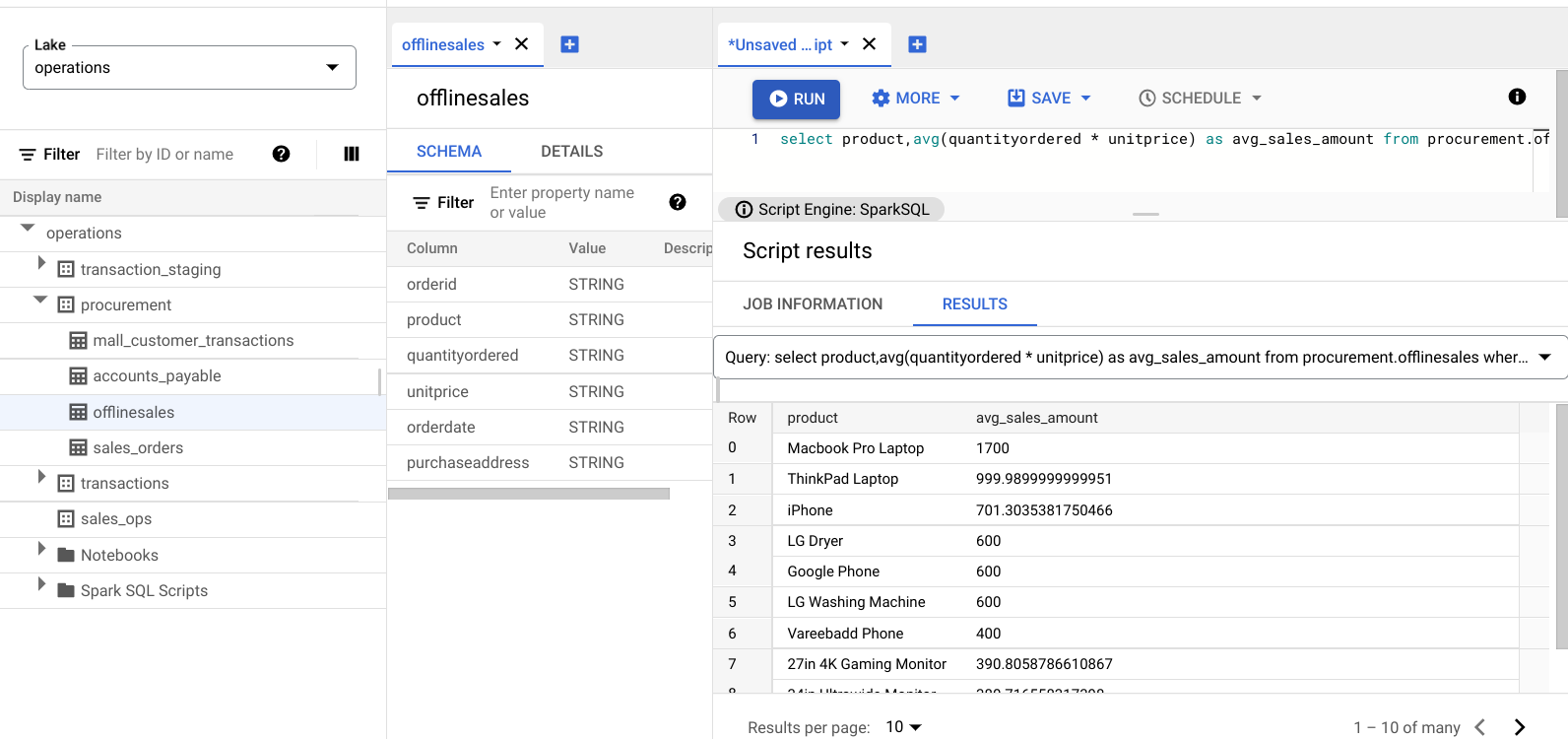
select product,avg(quantityordered * unitprice) as avg_sales_amount from procurement.offlinesales where orderid!='orderid' group by product order by avg_sales_amount desc;Klik Run.
Gambar berikut menampilkan panel Results yang menggunakan kolom bernama
product untuk mengidentifikasi item penjualan dengan nilai transaksi besar, yang ditampilkan di
kolom bernama avg_sales_amount.
Mendeteksi anomali menggunakan koefisien variasi
Kueri terakhir menunjukkan bahwa laptop memiliki jumlah transaksi rata-rata yang tinggi. Kueri berikut menunjukkan cara mendeteksi transaksi laptop yang tidak bersifat anomali dalam set data.
Kueri berikut menggunakan metrik "koefisien variasi",
rsd_value, untuk menemukan transaksi yang tidak biasa, dengan penyebaran
nilai yang rendah dibandingkan dengan nilai rata-rata. Koefisien variasi yang lebih rendah
menunjukkan lebih sedikit anomali.
Masukkan kueri berikut:
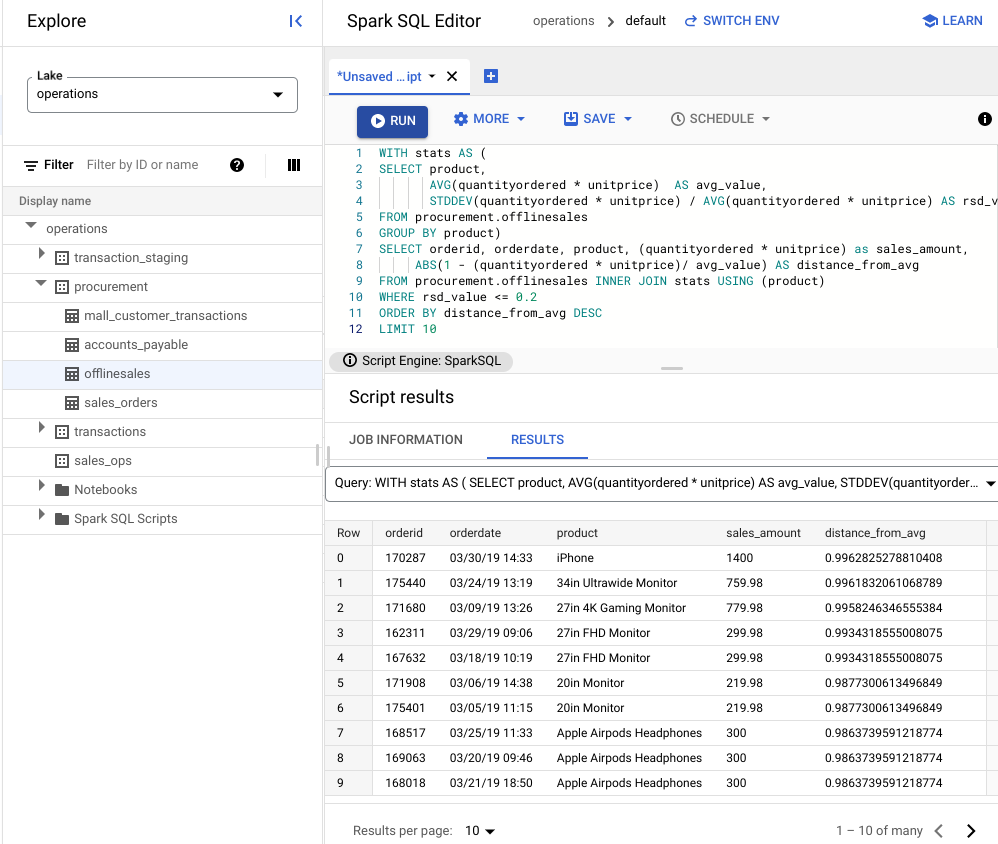
WITH stats AS ( SELECT product, AVG(quantityordered * unitprice) AS avg_value, STDDEV(quantityordered * unitprice) / AVG(quantityordered * unitprice) AS rsd_value FROM procurement.offlinesales GROUP BY product) SELECT orderid, orderdate, product, (quantityordered * unitprice) as sales_amount, ABS(1 - (quantityordered * unitprice)/ avg_value) AS distance_from_avg FROM procurement.offlinesales INNER JOIN stats USING (product) WHERE rsd_value <= 0.2 ORDER BY distance_from_avg DESC LIMIT 10Klik Run.
Lihat hasil skrip.
Pada gambar berikut, panel Hasil menggunakan kolom yang disebut produk untuk mengidentifikasi item penjualan dengan nilai transaksi yang berada dalam koefisien variasi 0,2.
Memvisualisasikan anomali menggunakan notebook JupyterLab
Buat model ML untuk mendeteksi dan memvisualisasikan anomali dalam skala besar.
Buka notebook di tab terpisah dan tunggu hingga dimuat. Sesi tempat Anda menjalankan kueri Spark SQL akan berlanjut.
Impor paket yang diperlukan dan hubungkan ke tabel eksternal BigQuery yang berisi data transaksi. Jalankan kode berikut:
from google.cloud import bigquery from google.api_core.client_options import ClientOptions import os import warnings warnings.filterwarnings('ignore') import pandas as pd project = os.environ['GOOGLE_CLOUD_PROJECT'] options = ClientOptions(quota_project_id=project) client = bigquery.Client(client_options=options) client = bigquery.Client() #Load data into DataFrame sql = '''select * from procurement.offlinesales limit 100;''' df = client.query(sql).to_dataframe()Jalankan algoritma isolation forest untuk menemukan anomali dalam set data:
to_model_columns = df.columns[2:4] from sklearn.ensemble import IsolationForest clf=IsolationForest(n_estimators=100, max_samples='auto', contamination=float(.12), \ max_features=1.0, bootstrap=False, n_jobs=-1, random_state=42, verbose=0) clf.fit(df[to_model_columns]) pred = clf.predict(df[to_model_columns]) df['anomaly']=pred outliers=df.loc[df['anomaly']==-1] outlier_index=list(outliers.index) #print(outlier_index) #Find the number of anomalies and normal points here points classified -1 are anomalous print(df['anomaly'].value_counts())Buat plot anomali yang diprediksi menggunakan visualisasi Matplotlib:
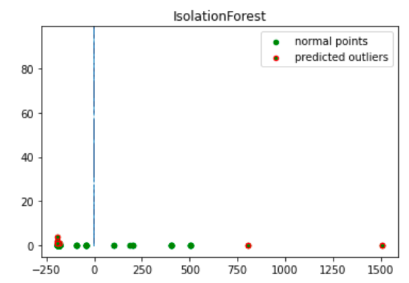
import numpy as np from sklearn.decomposition import PCA pca = PCA(2) pca.fit(df[to_model_columns]) res=pd.DataFrame(pca.transform(df[to_model_columns])) Z = np.array(res) plt.title("IsolationForest") plt.contourf( Z, cmap=plt.cm.Blues_r) b1 = plt.scatter(res[0], res[1], c='green', s=20,label="normal points") b1 =plt.scatter(res.iloc[outlier_index,0],res.iloc[outlier_index,1], c='green',s=20, edgecolor="red",label="predicted outliers") plt.legend(loc="upper right") plt.show()
Gambar ini menampilkan data transaksi dengan anomali yang ditandai dengan warna merah.
Menjadwalkan notebook
Jelajahi memungkinkan Anda menjadwalkan notebook untuk dijalankan secara berkala. Ikuti langkah-langkah untuk menjadwalkan Jupyter Notebook yang Anda buat.
Katalog Universal Dataplex membuat tugas penjadwalan untuk menjalankan notebook Anda secara berkala. Untuk memantau progres tugas, klik Lihat jadwal.
Membagikan atau mengekspor notebook
Jelajahi memungkinkan Anda berbagi notebook dengan orang lain di organisasi menggunakan izin IAM.
Tinjau peran. Berikan atau cabut peran Dataplex Universal Catalog Viewer
(roles/dataplex.viewer), Dataplex Universal Catalog Editor
(roles/dataplex.editor), dan Dataplex Universal Catalog Administrator
(roles/dataplex.admin) kepada pengguna untuk notebook ini. Setelah Anda membagikan
notebook, pengguna dengan peran pelihat atau editor di tingkat danau dapat membuka
danau dan mengerjakan notebook bersama.
Untuk membagikan atau mengekspor notebook, lihat Membagikan notebook atau Mengekspor notebook.
Pembersihan
Agar tidak perlu membayar biaya pada akun Google Cloud Anda untuk resource yang digunakan dalam tutorial ini, hapus project yang berisi resource tersebut, atau simpan project dan hapus setiap resource.
Menghapus project
Delete a Google Cloud project:
gcloud projects delete PROJECT_ID
Menghapus resource satu per satu
-
Hapus bucket:
gcloud storage buckets delete BUCKET_NAME
-
Hapus instance:
gcloud compute instances delete INSTANCE_NAME
Langkah berikutnya
- Pelajari Jelajahi Katalog Universal Dataplex lebih lanjut.
- Menjadwalkan skrip dan notebook.