이 가이드에서는 Dataflow SQL을 사용하여 Pub/Sub의 데이터 스트림을 BigQuery 테이블의 데이터와 조인하는 방법을 다룹니다.
목표
이 가이드의 목표는 다음과 같습니다.
- Pub/Sub 스트리밍 데이터를 BigQuery 테이블 데이터와 조인하는 Dataflow SQL 쿼리를 작성합니다.
- Dataflow SQL UI에서 Dataflow 작업을 배포합니다.
비용
이 문서에서는 비용이 청구될 수 있는 Google Cloud구성요소( )를 사용합니다.
- Dataflow
- Cloud Storage
- Pub/Sub
- Data Catalog
프로젝트 사용량을 기준으로 예상 비용을 산출하려면 가격 계산기를 사용합니다.
시작하기 전에
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Cloud Dataflow, Compute Engine, Logging, Cloud Storage, Cloud Storage JSON, BigQuery, Cloud Pub/Sub, Cloud Resource Manager and Data Catalog. APIs.
-
Create a service account:
-
In the Google Cloud console, go to the Create service account page.
Go to Create service account - Select your project.
-
In the Service account name field, enter a name. The Google Cloud console fills in the Service account ID field based on this name.
In the Service account description field, enter a description. For example,
Service account for quickstart. - Click Create and continue.
-
Grant the Project > Owner role to the service account.
To grant the role, find the Select a role list, then select Project > Owner.
- Click Continue.
-
Click Done to finish creating the service account.
Do not close your browser window. You will use it in the next step.
-
-
Create a service account key:
- In the Google Cloud console, click the email address for the service account that you created.
- Click Keys.
- Click Add key, and then click Create new key.
- Click Create. A JSON key file is downloaded to your computer.
- Click Close.
-
Set the environment variable
GOOGLE_APPLICATION_CREDENTIALSto the path of the JSON file that contains your credentials. This variable applies only to your current shell session, so if you open a new session, set the variable again. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Cloud Dataflow, Compute Engine, Logging, Cloud Storage, Cloud Storage JSON, BigQuery, Cloud Pub/Sub, Cloud Resource Manager and Data Catalog. APIs.
-
Create a service account:
-
In the Google Cloud console, go to the Create service account page.
Go to Create service account - Select your project.
-
In the Service account name field, enter a name. The Google Cloud console fills in the Service account ID field based on this name.
In the Service account description field, enter a description. For example,
Service account for quickstart. - Click Create and continue.
-
Grant the Project > Owner role to the service account.
To grant the role, find the Select a role list, then select Project > Owner.
- Click Continue.
-
Click Done to finish creating the service account.
Do not close your browser window. You will use it in the next step.
-
-
Create a service account key:
- In the Google Cloud console, click the email address for the service account that you created.
- Click Keys.
- Click Add key, and then click Create new key.
- Click Create. A JSON key file is downloaded to your computer.
- Click Close.
-
Set the environment variable
GOOGLE_APPLICATION_CREDENTIALSto the path of the JSON file that contains your credentials. This variable applies only to your current shell session, so if you open a new session, set the variable again. - gcloud CLI 설치 및 초기화 설치 옵션 중 하나를 선택하세요.
이 둘러보기에서 사용할 프로젝트에
project속성을 설정해야 할 수도 있습니다. - Google Cloud 콘솔에서 Dataflow SQL 웹 UI로 이동합니다. 그러면 가장 최근에 액세스한 프로젝트가 열립니다. 다른 프로젝트로 전환하려면 Dataflow SQL 웹 UI 맨 위에 있는 프로젝트 이름을 클릭하고 사용할 프로젝트를 검색합니다.
Dataflow SQL 웹 UI로 이동
transactions라는 Pub/Sub 주제 - Pub/Sub 주제 구독을 통해 도착하는 트랜잭션 데이터 스트림입니다. 각 트랜잭션의 데이터에는 구매한 제품, 할인가, 구매한 시/도와 같은 정보가 포함됩니다. Pub/Sub 주제를 만든 후 주제에 메시지를 게시하는 스크립트를 만듭니다. 이 스크립트는 이 튜토리얼의 뒷부분에서 실행됩니다.us_state_salesregions라는 BigQuery 테이블 - 시/도와 판매 지역이 매핑된 테이블입니다. 이 테이블을 만들기 전에 BigQuery 데이터세트를 만들어야 합니다.- BigQuery 웹 UI에서 BigQuery 데이터세트를 만듭니다. BigQuery 데이터세트는 테이블이 포함된 최상위 컨테이너입니다. BigQuery 테이블은 데이터세트에 속해야 합니다.
- 탐색기 패널에서 프로젝트의 작업을 엽니다. 메뉴에서 데이터 세트 만들기를 클릭합니다. 다음 스크린샷에서 프로젝트 ID는
dataflow-sql입니다.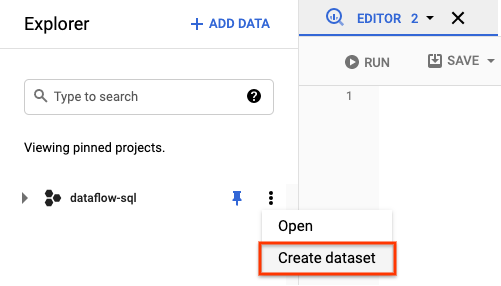
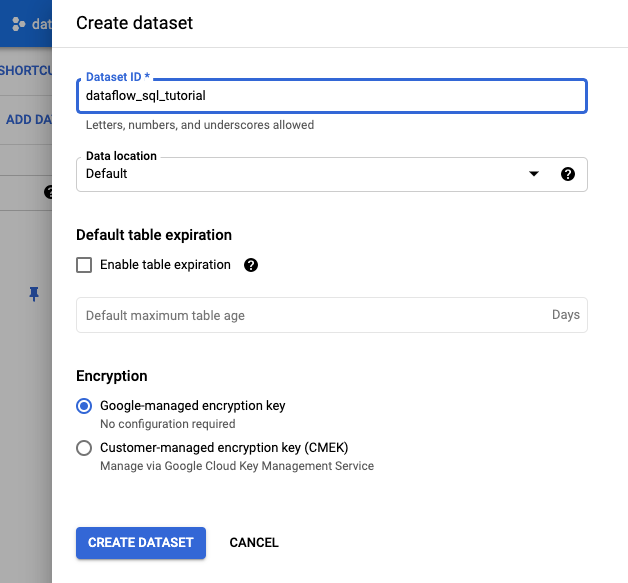
- 열리는 데이터세트 만들기 패널에서 데이터세트 ID에
dataflow_sql_tutorial을 입력합니다. - 데이터 위치의 메뉴에서 옵션을 선택합니다.
- 데이터 세트 만들기를 클릭합니다.
- 탐색기 패널에서 프로젝트의 작업을 엽니다. 메뉴에서 데이터 세트 만들기를 클릭합니다. 다음 스크린샷에서 프로젝트 ID는
- BigQuery 테이블을 만듭니다.
- 텍스트 파일을 만들고 이름을
us_state_salesregions.csv로 지정합니다. - 다음 데이터를 복사해
us_state_salesregions.csv에 붙여넣습니다. 다음 단계에서는 이 데이터를 BigQuery 테이블에 로드합니다.state_id,state_code,state_name,sales_region 1,MO,Missouri,Region_1 2,SC,South Carolina,Region_1 3,IN,Indiana,Region_1 6,DE,Delaware,Region_2 15,VT,Vermont,Region_2 16,DC,District of Columbia,Region_2 19,CT,Connecticut,Region_2 20,ME,Maine,Region_2 35,PA,Pennsylvania,Region_2 38,NJ,New Jersey,Region_2 47,MA,Massachusetts,Region_2 54,RI,Rhode Island,Region_2 55,NY,New York,Region_2 60,MD,Maryland,Region_2 66,NH,New Hampshire,Region_2 4,CA,California,Region_3 8,AK,Alaska,Region_3 37,WA,Washington,Region_3 61,OR,Oregon,Region_3 33,HI,Hawaii,Region_4 59,AS,American Samoa,Region_4 65,GU,Guam,Region_4 5,IA,Iowa,Region_5 32,NV,Nevada,Region_5 11,PR,Puerto Rico,Region_6 17,CO,Colorado,Region_6 18,MS,Mississippi,Region_6 41,AL,Alabama,Region_6 42,AR,Arkansas,Region_6 43,FL,Florida,Region_6 44,NM,New Mexico,Region_6 46,GA,Georgia,Region_6 48,KS,Kansas,Region_6 52,AZ,Arizona,Region_6 56,TN,Tennessee,Region_6 58,TX,Texas,Region_6 63,LA,Louisiana,Region_6 7,ID,Idaho,Region_7 12,IL,Illinois,Region_7 13,ND,North Dakota,Region_7 31,MN,Minnesota,Region_7 34,MT,Montana,Region_7 36,SD,South Dakota,Region_7 50,MI,Michigan,Region_7 51,UT,Utah,Region_7 64,WY,Wyoming,Region_7 9,NE,Nebraska,Region_8 10,VA,Virginia,Region_8 14,OK,Oklahoma,Region_8 39,NC,North Carolina,Region_8 40,WV,West Virginia,Region_8 45,KY,Kentucky,Region_8 53,WI,Wisconsin,Region_8 57,OH,Ohio,Region_8 49,VI,United States Virgin Islands,Region_9 62,MP,Commonwealth of the Northern Mariana Islands,Region_9
- BigQuery UI의 탐색기 패널에서 프로젝트를 펼쳐
dataflow_sql_tutorial데이터세트를 확인합니다. dataflow_sql_tutorial데이터 세트의 작업 메뉴를 열고 열기를 클릭합니다.- 테이블 만들기를 클릭합니다.
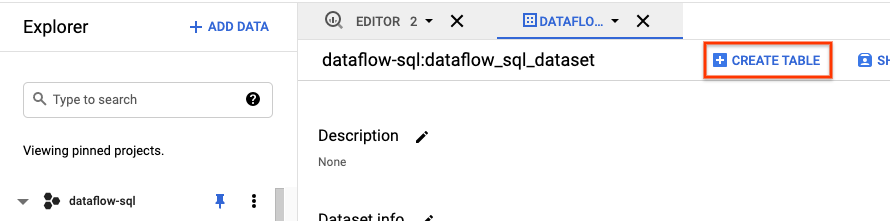
- 테이블 만들기 패널이 열립니다.
- 다음 항목으로 테이블 만들기에서 업로드를 선택합니다.
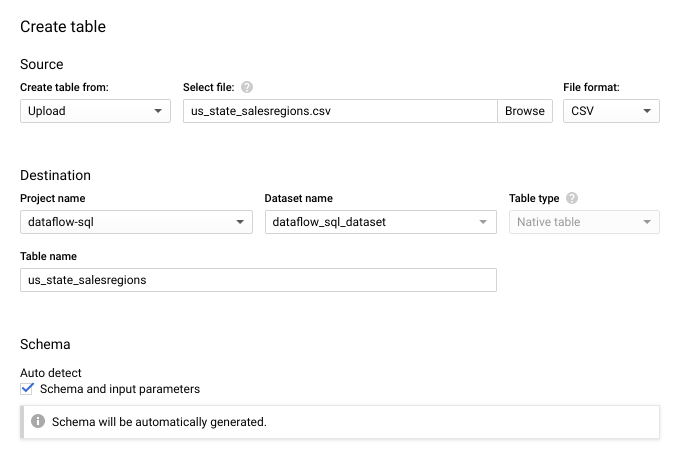
- 파일 선택에서 탐색을 클릭하고
us_state_salesregions.csv파일을 선택합니다. - 테이블에
us_state_salesregions를 입력합니다. - 스키마에서 자동 감지를 선택합니다.
- 고급 옵션을 클릭하여 고급 옵션 섹션을 펼칩니다.
- 건너뛸 헤더 행에
1을 입력한 다음 테이블 만들기를 클릭합니다.
- 다음 항목으로 테이블 만들기에서 업로드를 선택합니다.
- 탐색기 패널에서
us_state_salesregions를 클릭합니다. 스키마에는 자동 생성된 스키마가 표시됩니다. 미리보기에서는 테이블 데이터가 표시됩니다.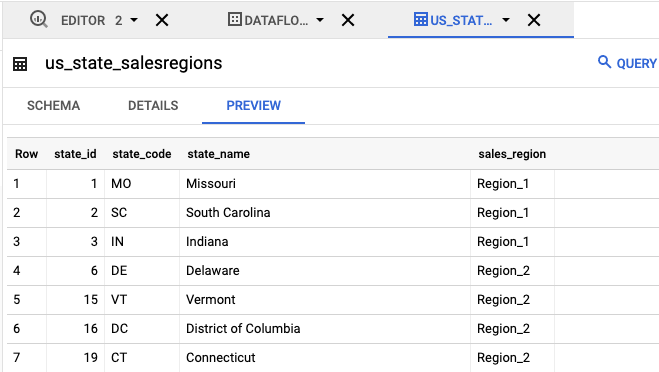
- 텍스트 파일을 만들고 이름을
텍스트 파일을 만들고 이름을
transactions_schema.yaml로 지정합니다. 다음 스키마 텍스트를 복사하여transactions_schema.yaml에 붙여넣습니다.- column: event_timestamp description: Pub/Sub event timestamp mode: REQUIRED type: TIMESTAMP - column: tr_time_str description: Transaction time string mode: NULLABLE type: STRING - column: first_name description: First name mode: NULLABLE type: STRING - column: last_name description: Last name mode: NULLABLE type: STRING - column: city description: City mode: NULLABLE type: STRING - column: state description: State mode: NULLABLE type: STRING - column: product description: Product mode: NULLABLE type: STRING - column: amount description: Amount of transaction mode: NULLABLE type: FLOATGoogle Cloud CLI를 사용하여 스키마를 할당합니다.
a. 다음 명령어를 사용하여 gcloud CLI를 업데이트합니다. gcloud CLI 버전이 242.0.0 이상인지 확인합니다.
gcloud components update
b. 명령줄 창에서 다음 명령어를 실행합니다. project-id를 프로젝트 ID로 바꾸고 path-to-file을
transactions_schema.yaml파일의 경로로 바꿉니다.gcloud data-catalog entries update \ --lookup-entry='pubsub.topic.`project-id`.transactions' \ --schema-from-file=path-to-file/transactions_schema.yaml
명령어 매개변수와 허용되는 스키마 파일 형식에 대한 자세한 내용은 gcloud data-catalog entry update 문서 페이지를 참조하세요.
c.
transactionsPub/Sub 주제에 스키마가 할당되었는지 확인합니다. project-id를 프로젝트 ID로 바꿉니다.gcloud data-catalog entries lookup 'pubsub.topic.`project-id`.transactions'
SQL 작업공간으로 이동합니다.
Dataflow SQL 편집기 패널의 검색창에서
projectid=project-id transactions를 검색합니다. project-id를 프로젝트 ID로 바꿉니다.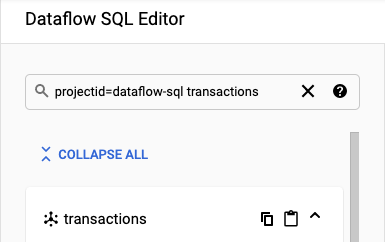
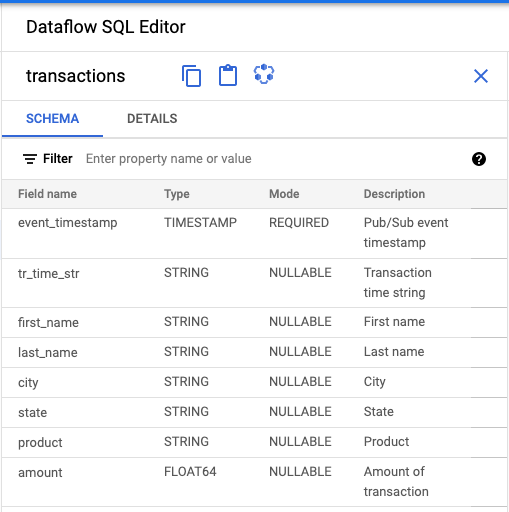
- Dataflow SQL UI의 Dataflow SQL 편집기 패널에서 트랜잭션을 클릭하거나
projectid=project-id system=cloud_pubsub를 입력하여 Pub/Sub 주제를 검색하고 주제를 선택합니다. 스키마 아래에서 Pub/Sub 주제에 할당한 스키마를 볼 수 있습니다.
쿼리 편집기에 있는 작업 만들기를 클릭합니다.
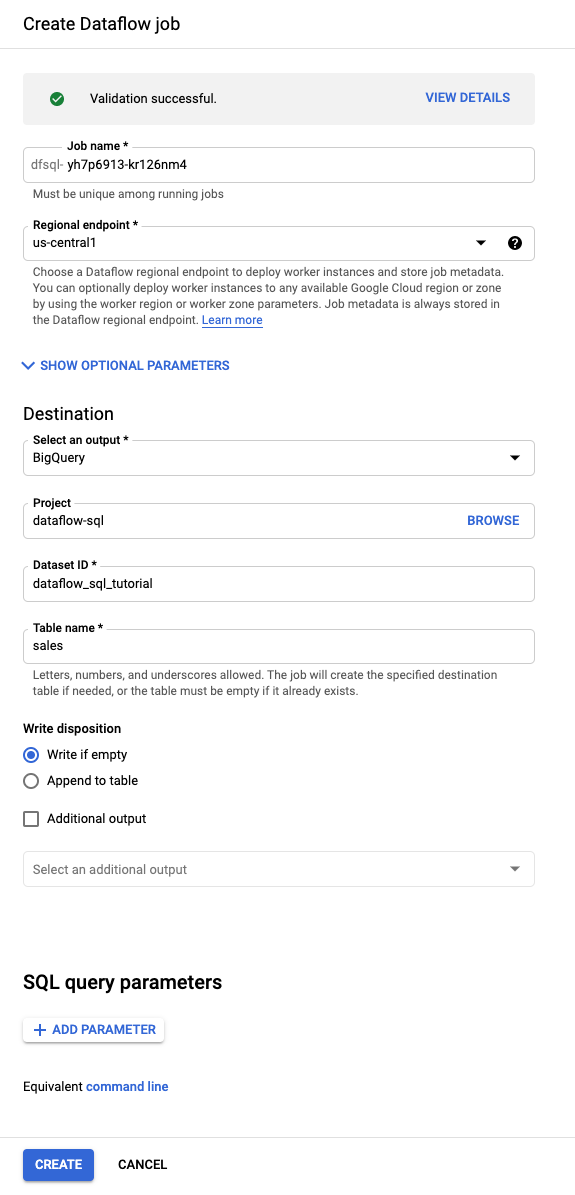
Dataflow 작업 만들기 패널이 열립니다.
- 대상에 BigQuery를 선택합니다.
- 데이터세트 ID로
dataflow_sql_tutorial을 선택합니다. - 테이블 이름에
sales를 입력합니다.
선택사항: Dataflow는 Dataflow SQL 작업에 가장 적합한 설정을 자동으로 선택하지만, 선택적 매개변수 메뉴를 확장하여 수동으로 다음 파이프 라인 옵션을 지정할 수 있습니다.
- 최대 작업자 수
- 영역
- 서비스 계정 이메일
- 머신 유형
- 추가 실험
- 작업자 IP 주소 구성
- 네트워크
- 서브네트워크
만들기를 클릭합니다. Dataflow 작업을 실행하는 데 몇 분 정도 걸립니다.
Dataflow 작업 페이지에서 수정할 작업을 클릭합니다.
작업 세부정보 페이지의 작업 정보 패널에 있는 파이프라인 옵션에서 SQL 쿼리를 찾습니다. queryString 행을 찾습니다.
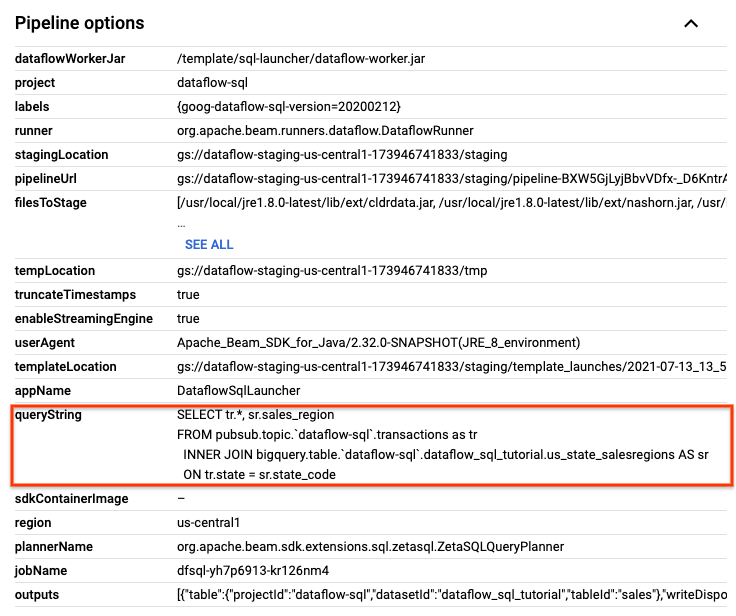
다음 SQL 쿼리를 복사하여 SQL 작업공간의 Dataflow SQL 편집기에 붙여넣어 텀블링 윈도우를 추가합니다. project-id를 프로젝트 ID로 바꿉니다.
SELECT sr.sales_region, TUMBLE_START("INTERVAL 15 SECOND") AS period_start, SUM(tr.amount) as amount FROM pubsub.topic.`project-id`.transactions AS tr INNER JOIN bigquery.table.`project-id`.dataflow_sql_tutorial.us_state_salesregions AS sr ON tr.state = sr.state_code GROUP BY sr.sales_region, TUMBLE(tr.event_timestamp, "INTERVAL 15 SECOND")
작업 만들기를 클릭하여 수정된 쿼리로 새 작업을 만듭니다.
transactions_injector.py게시 스크립트가 실행 중이면 스크립트를 중지합니다.실행 중인 Dataflow 작업을 중지합니다. Google Cloud 콘솔에서 Dataflow 웹 UI로 이동합니다.
이 둘러보기를 따라 만든 각 작업에 다음 단계를 수행합니다.
작업 이름을 클릭합니다.
작업 세부정보 페이지에서 중지를 클릭합니다. 작업 중지 방법 옵션이 있는 작업 중지 대화상자가 나타납니다.
취소를 선택합니다.
작업 중지를 클릭합니다. 서비스가 모든 데이터 수집 및 처리를 최대한 빨리 중지합니다. 취소는 처리를 즉시 중단하므로 '처리 중인' 데이터가 손실될 수 있습니다. 작업을 중지하는 데 몇 분 정도 걸릴 수 있습니다.
BigQuery 데이터세트를 삭제합니다. Google Cloud 콘솔에서 BigQuery 웹 UI로 이동합니다.
탐색기 패널의 리소스 섹션에서 만든 dataflow_sql_tutorial 데이터 세트를 클릭합니다.
세부정보 패널에서 삭제를 클릭합니다. 확인 대화상자가 열립니다.
데이터 세트 삭제 대화상자에서
delete를 입력하여 삭제 명령어를 확인한 후 삭제를 클릭합니다.
Pub/Sub 주제를 삭제합니다. Google Cloud 콘솔에서 Pub/Sub 주제 페이지로 이동합니다.
transactions주제를 선택합니다.삭제를 클릭하여 주제를 영구 삭제합니다. 확인 대화상자가 열립니다.
주제 삭제 대화상자에서
delete를 입력하여 삭제 명령어를 확인한 후 삭제를 클릭합니다.Pub/Sub 구독 페이지로 이동합니다.
transactions에 대해 남아있는 구독을 선택합니다. 작업이 더 이상 실행되지 않으면 구독이 없을 수 있습니다.삭제를 클릭하여 구독을 영구 삭제합니다. 확인 대화상자에서 삭제를 클릭합니다.
Cloud Storage에서 Dataflow 스테이징 버킷을 삭제합니다. Google Cloud 콘솔에서 Cloud Storage 버킷 페이지로 이동합니다.
Dataflow 스테이징 버킷을 선택합니다.
삭제를 클릭하여 버킷을 삭제합니다. 확인 대화상자가 열립니다.
버킷 삭제 대화상자에서
DELETE를 입력하여 삭제 명령어를 확인한 후 삭제를 클릭합니다.
소스 예 만들기
이 튜토리얼에 제공된 예시를 수행하려면 다음 소스를 만들어 튜토리얼 단계에 사용합니다.
BigQuery 데이터 세트와 테이블 만들기
Pub/Sub 주제에 스키마 할당
스키마를 할당하면 Pub/Sub 주제 데이터에서 SQL 쿼리를 실행할 수 있습니다. 현재 Dataflow SQL은 Pub/Sub 주제의 메시지가 JSON 형식으로 직렬화되도록 합니다.
Cloud Pub/Sub 주제 예시 transactions에 스키마를 할당하려면 다음 안내를 따르세요.
Pub/Sub 소스 찾기
Dataflow SQL UI는 액세스 권한이 있는 프로젝트의 Pub/Sub 데이터 소스 객체를 찾을 수 있으므로 전체 이름을 기억할 필요가 없습니다.
이 튜토리얼의 예시에서는 Dataflow SQL 편집기로 이동하여 생성된 transactions Pub/Sub 주제를 검색합니다.
스키마 보기
SQL 쿼리 만들기
Dataflow SQL UI에서 Dataflow 작업을 실행하는 SQL 쿼리를 만들 수 있습니다.
다음 SQL 쿼리는 데이터 보강 쿼리입니다. 시/도와 판매 지역을 매핑하는 BigQuery 테이블(us_state_salesregions)을 사용하여 이벤트(transactions)의 Pub/Sub 스트림에 다른 필드 sales_region을 추가합니다.
다음 SQL 쿼리를 복사하여 쿼리 편집기에 붙여넣습니다. project-id는 프로젝트 ID로 바꿉니다.
SELECT tr.*, sr.sales_region FROM pubsub.topic.`project-id`.transactions as tr INNER JOIN bigquery.table.`project-id`.dataflow_sql_tutorial.us_state_salesregions AS sr ON tr.state = sr.state_code
Dataflow SQL UI에 쿼리를 입력하면 쿼리 검사기가 쿼리 구문을 확인합니다. 쿼리가 유효하면 녹색 체크표시 아이콘이 표시되고 쿼리가 잘못되면 빨간색 느낌표 아이콘이 표시됩니다. 쿼리 구문이 잘못된 경우 검사기 아이콘을 클릭하면 수정해야 하는 항목의 정보가 표시됩니다.
다음 스크린샷은 쿼리 편집기에서 유효한 쿼리를 보여줍니다. 검사기에 녹색 체크표시가 표시되어 있습니다.

SQL 쿼리를 실행하는 Dataflow 작업 만들기
SQL 쿼리를 실행하려면 Dataflow SQL UI에서 Dataflow 작업을 만듭니다.
Dataflow 작업 보기
Dataflow는 SQL 쿼리를 Apache Beam 파이프라인으로 변환합니다. 작업 보기를 클릭하여 파이프라인의 그래픽 표현을 볼 수 있는 Dataflow 웹 UI를 엽니다.
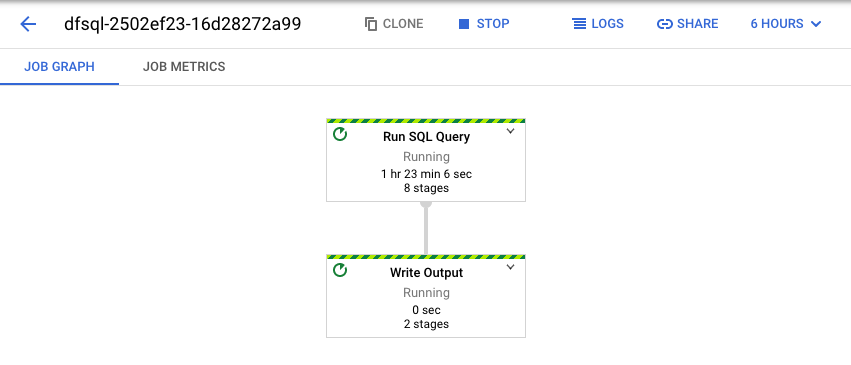
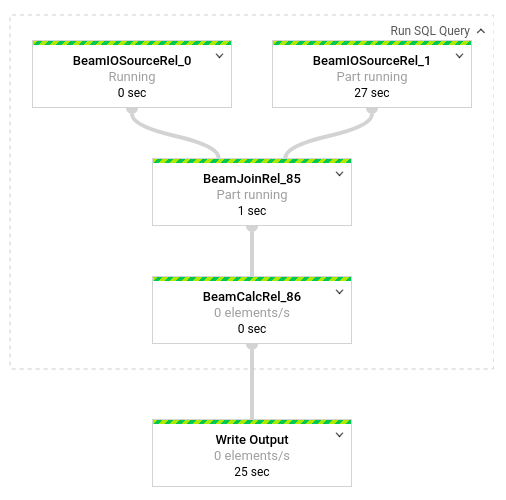
파이프라인에서 발생하는 변환을 세부적으로 확인하려면 상자를 클릭합니다. 예를 들어 그래픽 표시에서 SQL 쿼리 실행이라는 첫 번째 상자를 클릭하면 백그라운드로 수행되는 작업을 보여주는 그래픽이 나타납니다.
처음 상자 두 개는 Pub/Sub 주제 transactions와 BigQuery 테이블 us_state_salesregions를 조인한 입력 두 개를 나타냅니다.
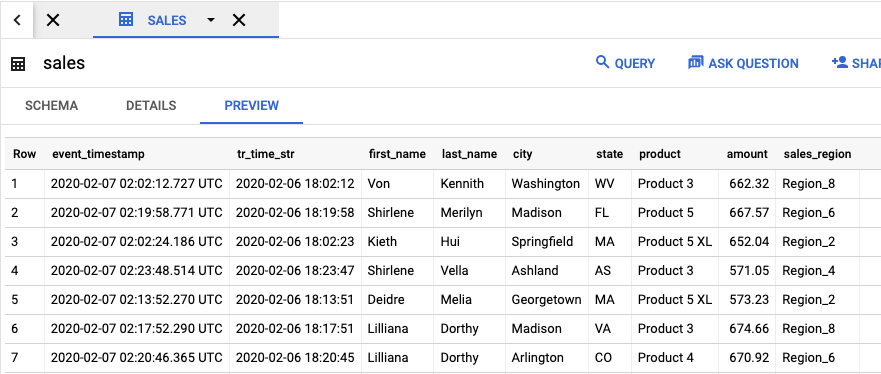
작업 결과가 포함된 출력 테이블을 보려면 BigQuery UI로 이동합니다.
탐색기 패널의 프로젝트에서 만든 dataflow_sql_tutorial 데이터 세트를 클릭합니다. 그런 다음 출력 테이블인 sales을 클릭합니다. 미리보기 탭에 출력 테이블의 콘텐츠가 표시됩니다.
이전 작업 보기 및 쿼리 편집
Dataflow UI는 이전 작업 및 쿼리를 Dataflow 작업 페이지에 저장합니다.
작업 기록 목록을 사용하여 이전 SQL 쿼리를 볼 수 있습니다. 예를 들어 15초마다 판매 지역별로 판매를 집계하도록 쿼리를 수정하려고 합니다. 작업 페이지를 사용하여 이 튜토리얼의 앞부분에서 시작한 실행 중인 작업에 액세스하고 SQL 쿼리를 복사한 후 수정된 쿼리로 다른 작업을 실행합니다.
삭제
이 튜토리얼에서 사용된 리소스 비용이 Cloud Billing 계정에 청구되지 않게 하려면 다음 안내를 따르세요.
다음 단계
- Dataflow SQL 소개 참조하기
- 스트리밍 파이프라인 기본사항 알아보기
- Dataflow SQL 참조 살펴보기
- Cloud Next 2019에서 제공된 스트리밍 분석 데모 보기