In dieser Anleitung erfahren Sie, wie Sie mit Dataflow SQL einen Datenstrom aus Pub/Sub mit Daten aus einer BigQuery-Tabelle verknüpfen.
Ziele
In dieser Anleitung lernen Sie, wie Sie:
- Eine Dataflow-SQL-Abfrage schreiben, die Pub/Sub-Streamingdaten mit BigQuery-Tabellendaten zusammenführt,.
- Einen Dataflow-Job über die Dataflow-SQL-Benutzeroberfläche bereitstellen.
Kosten
In diesem Dokument verwenden Sie die folgenden kostenpflichtigen Komponenten von Google Cloud:
- Dataflow
- Cloud Storage
- Pub/Sub
- Data Catalog
Mit dem Preisrechner können Sie eine Kostenschätzung für Ihre voraussichtliche Nutzung vornehmen.
Hinweise
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Cloud Dataflow, Compute Engine, Logging, Cloud Storage, Cloud Storage JSON, BigQuery, Cloud Pub/Sub, Cloud Resource Manager and Data Catalog. APIs.
-
Create a service account:
-
In the Google Cloud console, go to the Create service account page.
Go to Create service account - Select your project.
-
In the Service account name field, enter a name. The Google Cloud console fills in the Service account ID field based on this name.
In the Service account description field, enter a description. For example,
Service account for quickstart. - Click Create and continue.
-
Grant the Project > Owner role to the service account.
To grant the role, find the Select a role list, then select Project > Owner.
- Click Continue.
-
Click Done to finish creating the service account.
Do not close your browser window. You will use it in the next step.
-
-
Create a service account key:
- In the Google Cloud console, click the email address for the service account that you created.
- Click Keys.
- Click Add key, and then click Create new key.
- Click Create. A JSON key file is downloaded to your computer.
- Click Close.
-
Set the environment variable
GOOGLE_APPLICATION_CREDENTIALSto the path of the JSON file that contains your credentials. This variable applies only to your current shell session, so if you open a new session, set the variable again. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Cloud Dataflow, Compute Engine, Logging, Cloud Storage, Cloud Storage JSON, BigQuery, Cloud Pub/Sub, Cloud Resource Manager and Data Catalog. APIs.
-
Create a service account:
-
In the Google Cloud console, go to the Create service account page.
Go to Create service account - Select your project.
-
In the Service account name field, enter a name. The Google Cloud console fills in the Service account ID field based on this name.
In the Service account description field, enter a description. For example,
Service account for quickstart. - Click Create and continue.
-
Grant the Project > Owner role to the service account.
To grant the role, find the Select a role list, then select Project > Owner.
- Click Continue.
-
Click Done to finish creating the service account.
Do not close your browser window. You will use it in the next step.
-
-
Create a service account key:
- In the Google Cloud console, click the email address for the service account that you created.
- Click Keys.
- Click Add key, and then click Create new key.
- Click Create. A JSON key file is downloaded to your computer.
- Click Close.
-
Set the environment variable
GOOGLE_APPLICATION_CREDENTIALSto the path of the JSON file that contains your credentials. This variable applies only to your current shell session, so if you open a new session, set the variable again. - Installieren und initialisieren Sie die gcloud CLI. Wählen Sie eine der Installationsoptionen aus.
Möglicherweise müssen Sie das Attribut
projectauf das Projekt festlegen, das Sie für diese Schritt-für-Schritt-Anleitung verwenden. - Öffnen Sie in der Cloud Console die Dataflow SQL-Web-UI. Diese wird mit dem zuletzt aufgerufenen Projekt geöffnet. Klicken Sie am oberen Rand der Dataflow SQL-Web-UI auf diesen Projektnamen, wenn Sie ein anderes Projekt verwenden möchten. Suchen Sie dann nach dem gewünschten Projekt.
Zur Dataflow SQL-Web-UI
Beispielquellen erstellen
Wenn Sie das Beispiel in dieser Anleitung durcharbeiten möchten, erstellen Sie für die Schritte der Anleitung folgende Quellen.
- Ein Pub/Sub-Thema namens
transactions: ein Transaktionsdatenstrom, der über ein Abo beim Pub/Sub-Thema eingeht. Die Daten für die einzelnen Transaktionen umfassen Informationen wie die gekauften Produkte, den Verkaufspreis und die Stadt und den Bundesstaat, in denen der Kauf erfolgt ist. Nachdem Sie das Pub- bzw. Sub-Thema erstellt haben, erstellen Sie ein Skript, das Nachrichten zu Ihrem Thema veröffentlicht. Dieses Skript führen Sie weiter unten in dieser Anleitung aus. - Eine BigQuery-Tabelle namens
us_state_salesregions: eine Tabelle, die eine Zuordnung von Bundesstaaten zu Verkaufsregionen enthält. Vor dem Erstellen dieser Tabelle müssen Sie ein BigQuery-Dataset erstellen.
BigQuery-Dataset und -Tabelle erstellen
- Erstellen Sie in der BigQuery-Web-UI ein BigQuery-Dataset. Ein BigQuery-Dataset ist ein Container auf oberster Ebene, der Ihre Tabellen enthält. BigQuery-Tabellen müssen zu einem Dataset gehören.
- Öffnen Sie im Bereich **Explorer** die Aktionen für Ihr Projekt. Klicken Sie im Menü auf Dataset erstellen. Im folgenden Screenshot lautet die Projekt-ID
dataflow-sql.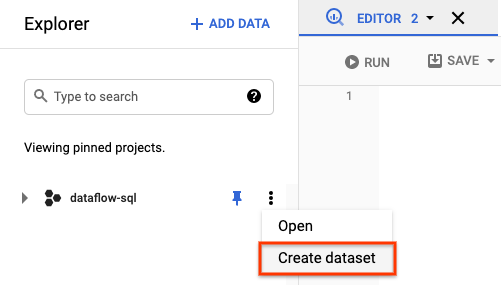
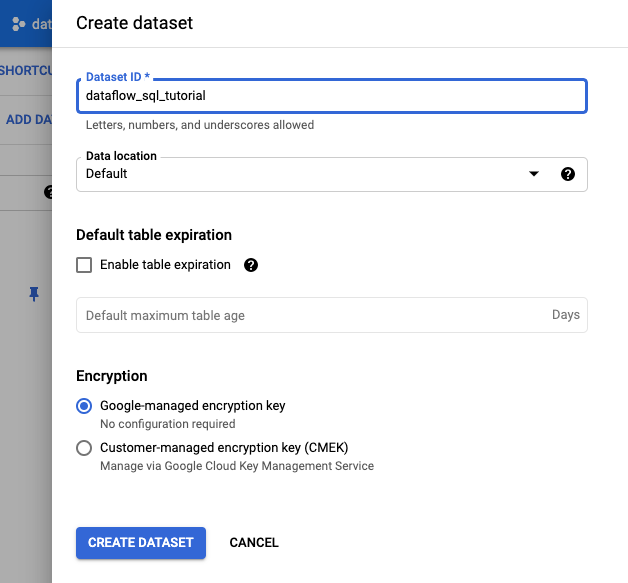
- Geben Sie im angezeigten Bereich Dataset erstellen als Dataset-ID
dataflow_sql_tutorialein. - Wählen Sie für Speicherort der Daten eine Option aus dem Menü aus.
- Klicken Sie auf Dataset erstellen.
- Öffnen Sie im Bereich **Explorer** die Aktionen für Ihr Projekt. Klicken Sie im Menü auf Dataset erstellen. Im folgenden Screenshot lautet die Projekt-ID
- Erstellen Sie eine BigQuery-Tabelle.
- Erstellen Sie eine Textdatei und nennen Sie sie
us_state_salesregions.csv. - Kopieren Sie die folgenden Daten in
us_state_salesregions.csv. Diese Daten laden Sie in den nächsten Schritten in Ihre BigQuery-Tabelle.state_id,state_code,state_name,sales_region 1,MO,Missouri,Region_1 2,SC,South Carolina,Region_1 3,IN,Indiana,Region_1 6,DE,Delaware,Region_2 15,VT,Vermont,Region_2 16,DC,District of Columbia,Region_2 19,CT,Connecticut,Region_2 20,ME,Maine,Region_2 35,PA,Pennsylvania,Region_2 38,NJ,New Jersey,Region_2 47,MA,Massachusetts,Region_2 54,RI,Rhode Island,Region_2 55,NY,New York,Region_2 60,MD,Maryland,Region_2 66,NH,New Hampshire,Region_2 4,CA,California,Region_3 8,AK,Alaska,Region_3 37,WA,Washington,Region_3 61,OR,Oregon,Region_3 33,HI,Hawaii,Region_4 59,AS,American Samoa,Region_4 65,GU,Guam,Region_4 5,IA,Iowa,Region_5 32,NV,Nevada,Region_5 11,PR,Puerto Rico,Region_6 17,CO,Colorado,Region_6 18,MS,Mississippi,Region_6 41,AL,Alabama,Region_6 42,AR,Arkansas,Region_6 43,FL,Florida,Region_6 44,NM,New Mexico,Region_6 46,GA,Georgia,Region_6 48,KS,Kansas,Region_6 52,AZ,Arizona,Region_6 56,TN,Tennessee,Region_6 58,TX,Texas,Region_6 63,LA,Louisiana,Region_6 7,ID,Idaho,Region_7 12,IL,Illinois,Region_7 13,ND,North Dakota,Region_7 31,MN,Minnesota,Region_7 34,MT,Montana,Region_7 36,SD,South Dakota,Region_7 50,MI,Michigan,Region_7 51,UT,Utah,Region_7 64,WY,Wyoming,Region_7 9,NE,Nebraska,Region_8 10,VA,Virginia,Region_8 14,OK,Oklahoma,Region_8 39,NC,North Carolina,Region_8 40,WV,West Virginia,Region_8 45,KY,Kentucky,Region_8 53,WI,Wisconsin,Region_8 57,OH,Ohio,Region_8 49,VI,United States Virgin Islands,Region_9 62,MP,Commonwealth of the Northern Mariana Islands,Region_9
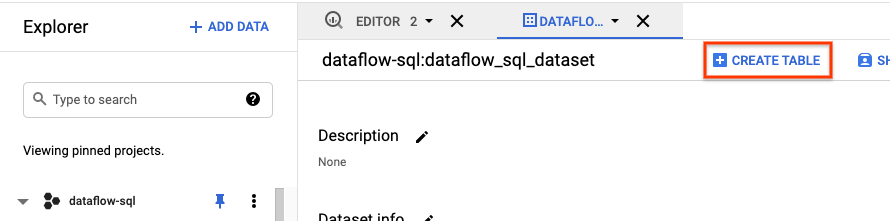
- Maximieren Sie im Bereich Explorer der BigQuery-UI Ihr Projekt, um das Dataset
dataflow_sql_tutorialaufzurufen. - Öffnen Sie das Aktionsmenü für das Dataset
dataflow_sql_tutorialund klicken Sie auf Öffnen. - Klicken Sie auf Tabelle erstellen.
- Gehen Sie im angezeigten Bereich Tabelle erstellen so vor:
- Wählen Sie unter Tabelle erstellen aus die Option Hochladen aus.

- Klicken Sie unter Datei auswählen auf Durchsuchen und wählen Sie die Datei
us_state_salesregions.csvaus. - Geben Sie für Tabelle den Wert
us_state_salesregionsein. - Wählen Sie unter Schema die Option Automatisch erkennen aus.
- Klicken Sie auf Advanced options (Erweiterte Optionen), um den gleichnamigen Abschnitt zu maximieren.
- Geben Sie unter Header rows to skip (Zu überspringende Kopfzeilen)
1ein und klicken Sie dann auf Create table (Tabelle erstellen).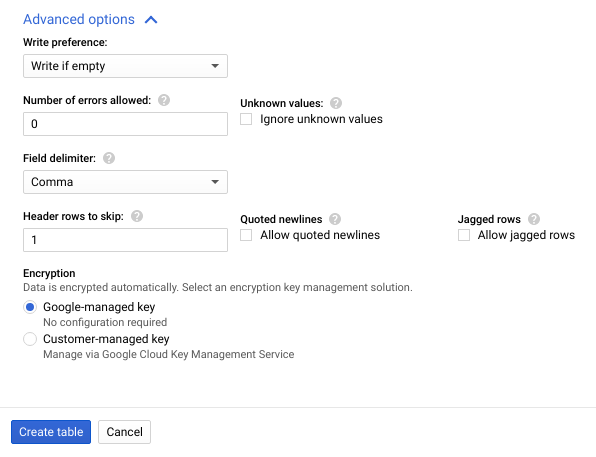
- Wählen Sie unter Tabelle erstellen aus die Option Hochladen aus.
- Klicken Sie im Bereich Explorer auf
us_state_salesregions. Unter Schema sehen Sie das Schema, das automatisch generiert wurde. Unter Vorschau sehen Sie die Tabellendaten.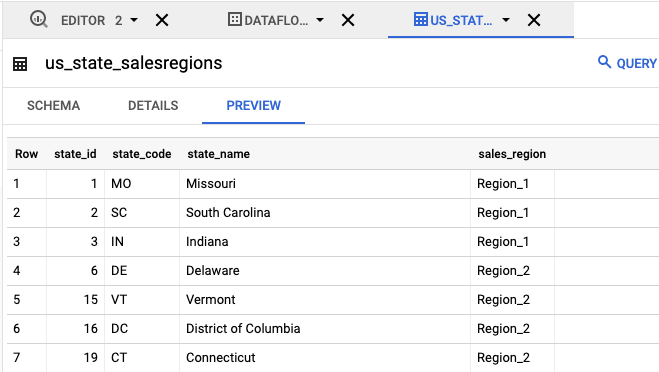
- Erstellen Sie eine Textdatei und nennen Sie sie
Pub/Sub-Thema ein Schema zuweisen
Durch das Zuweisen eines Schemas können Sie SQL-Abfragen für die Daten Ihres Pub/Sub-Themas ausführen. Derzeit erwartet Dataflow SQL, dass Nachrichten in Pub-/Sub-Themen im JSON-Format serialisiert werden.
So weisen Sie dem Pub/Sub-Beispielthema transactions ein Schema zu:
Erstellen Sie eine Textdatei und nennen Sie sie
transactions_schema.yaml. Kopieren Sie den folgenden Schematext und fügen Sie ihn intransactions_schema.yamlein.- column: event_timestamp description: Pub/Sub event timestamp mode: REQUIRED type: TIMESTAMP - column: tr_time_str description: Transaction time string mode: NULLABLE type: STRING - column: first_name description: First name mode: NULLABLE type: STRING - column: last_name description: Last name mode: NULLABLE type: STRING - column: city description: City mode: NULLABLE type: STRING - column: state description: State mode: NULLABLE type: STRING - column: product description: Product mode: NULLABLE type: STRING - column: amount description: Amount of transaction mode: NULLABLE type: FLOATWeisen Sie das Schema über Google Cloud CLI zu.
a. Aktualisieren Sie gcloud CLI mit dem folgenden Befehl. Achten Sie darauf, dass die gcloud CLI die Version 242.0.0 oder höher hat.
gcloud components update
b. Führen Sie in einem Befehlszeilenfenster den folgenden Befehl aus. Ersetzen Sie project-id durch Ihre Projekt-ID und path-to-file durch den Pfad zu Ihrer Datei
transactions_schema.yaml.gcloud data-catalog entries update \ --lookup-entry='pubsub.topic.`project-id`.transactions' \ --schema-from-file=path-to-file/transactions_schema.yaml
Weitere Informationen zu den Parametern des Befehls und den zulässigen Schemadateiformaten finden Sie auf der Dokumentationsseite für gcloud data-catalog entries update.
c. Bestätigen Sie, dass Ihr Schema dem Pub/Sub-Thema
transactionszugewiesen wurde. Ersetzen Sie project-id durch Ihre Projekt-ID.gcloud data-catalog entries lookup 'pubsub.topic.`project-id`.transactions'
Pub/Sub-Quellen finden
Die SQL-UI von Dataflow bietet eine Möglichkeit, Pub/Sub-Datenquellenobjekte für jedes Projekt zu finden, auf das Sie Zugriff haben, sodass Sie sich deren vollständige Namen nicht merken müssen.
Öffnen Sie für das Beispiel in dieser Anleitung den Dataflow SQL-Editor und suchen Sie nach dem von Ihnen erstellten Pub/Sub-Thema transactions:
Wechseln Sie zum SQL-Arbeitsbereich.
Suchen Sie im Dataflow SQL-Editor in der Suchleiste nach
projectid=project-id transactions. Ersetzen Sie project-id durch Ihre Projekt-ID.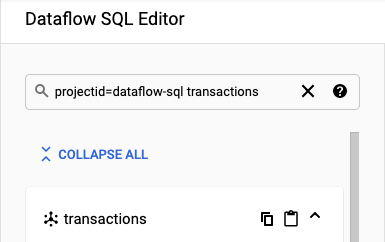
Schema ansehen
- Klicken Sie im Bereich Dataflow SQL-Editor der Dataflow SQL-UI auf Transaktionen oder suchen Sie nach einem Pub/Sub-Thema, indem Sie
projectid=project-id system=cloud_pubsubeingeben. Wählen Sie das Thema aus. Unter Schema können Sie das Schema anzeigen, das Sie dem Pub/Sub-Thema zugewiesen haben.
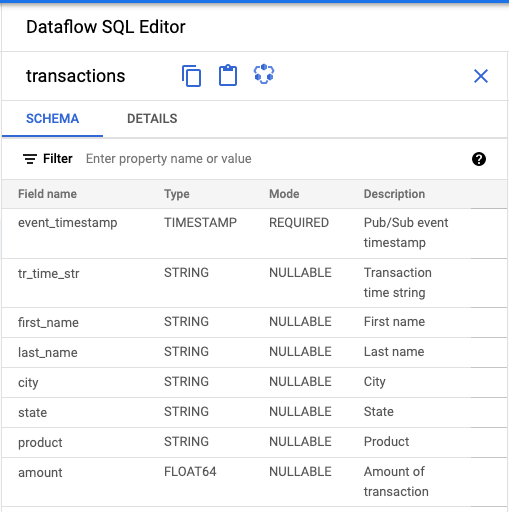
SQL-Abfrage erstellen
In der Dataflow SQL-UI können Sie SQL-Abfragen erstellen, um Ihre Dataflow-Jobs auszuführen.
Die folgende SQL-Abfrage dient der Datenanreicherung. Mithilfe einer BigQuery-Tabelle (us_state_salesregions), die eine Zuordnung von Bundesstaaten zu Verkaufsregionen vornimmt, erweitert sie den Stream von Pub/Sub-Ereignissen (transactions) um das Feld sales_region.
Kopieren Sie die folgende SQL-Abfrage und fügen Sie sie in den Abfrageeditor ein. Ersetzen Sie project-id durch Ihre Projekt-ID.
SELECT tr.*, sr.sales_region FROM pubsub.topic.`project-id`.transactions as tr INNER JOIN bigquery.table.`project-id`.dataflow_sql_tutorial.us_state_salesregions AS sr ON tr.state = sr.state_code
Wenn Sie in der Dataflow SQL-UI eine Abfrage eingeben, wird die Abfragesyntax vom Validator geprüft. Wenn die Abfrage gültig ist, wird ein grünes Häkchen angezeigt. Ist sie ungültig, ist ein rotes Ausrufezeichen zu sehen. Wenn die Abfragesyntax ungültig ist, erhalten Sie durch Klicken auf das Symbol des Validators Informationen darüber, was korrigiert werden muss.
Im folgenden Screenshot ist die gültige Abfrage im Abfrageeditor zu sehen. Das grüne Häkchen des Validators wird angezeigt.

Dataflow-Job zum Ausführen der SQL-Abfrage erstellen
Erstellen Sie zum Ausführen Ihrer SQL-Abfrage einen Dataflow-Job über die Dataflow-SQL-UI.
Klicken Sie im Abfrageeditor auf Job erstellen.
Gehen Sie im angezeigten Bereich Dataflow-Job erstellen so vor:
- Wählen Sie als Ziel BigQuery aus.
- Wählen Sie
dataflow_sql_tutorialals Dataset-ID aus. - Geben Sie für Tabellenname
salesein.
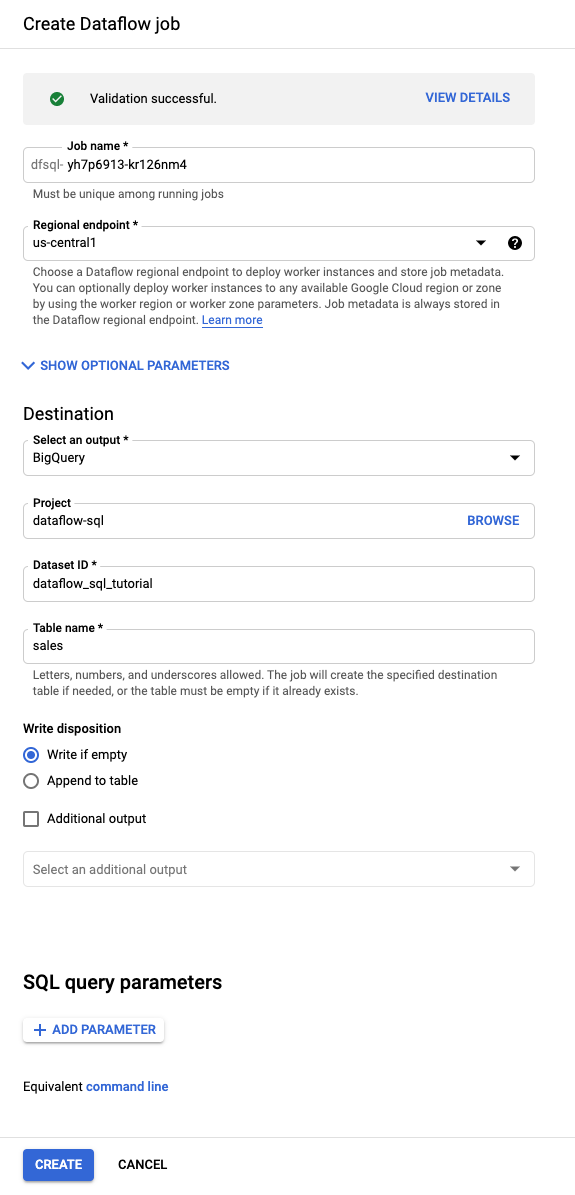
Optional: Dataflow wählt automatisch die Einstellungen aus, die für Ihren Dataflow-SQL-Job optimal sind. Sie können jedoch das Menü Optionale Parameter erweitern, um die folgenden Pipelineoptionen manuell festzulegen:
- Maximale Anzahl von Workern
- Zone
- E-Mail-Adresse des Dienstkontos
- Maschinentyp
- Zusätzliche Tests
- Konfiguration der Worker-IP-Adresse
- Netzwerk
- Subnetzwerk
Klicken Sie auf Erstellen. Die Ausführung Ihres Dataflow-Auftrags dauert einige Minuten.
Dataflow-Job ansehen
Dataflow wandelt die SQL-Abfrage in eine Apache Beam-Pipeline um. Klicken Sie auf Job ansehen, um die Dataflow-Web-UI zu öffnen, wo Sie eine grafische Darstellung Ihrer Pipeline sehen.
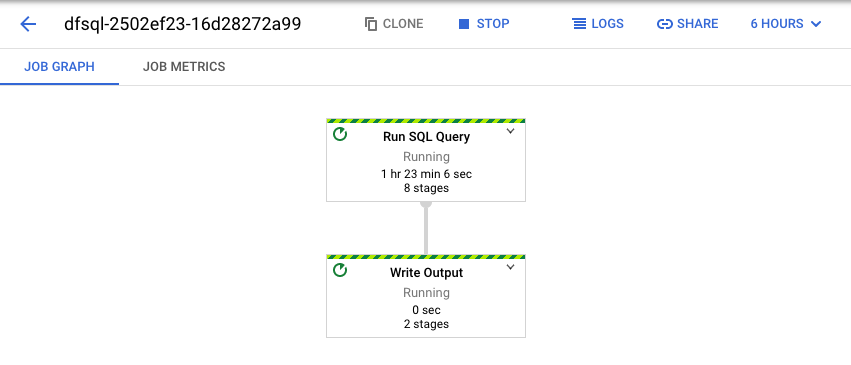
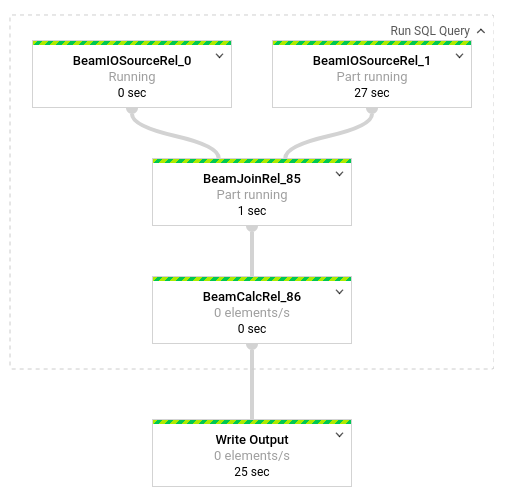
Klicken Sie auf die Felder, um eine Aufschlüsselung der Transformationen aufzurufen, die in der Pipeline auftreten. Wenn Sie beispielsweise in der grafischen Darstellung auf das erste Feld namens SQL-Abfrage ausführen klicken, wird eine Grafik mit den Vorgängen angezeigt, die im Hintergrund ablaufen.
Die ersten zwei Felder stellen die beiden Eingaben dar, die Sie verknüpft haben: das Pub/Sub-Thema transactions und die BigQuery-Tabelle us_state_salesregions.
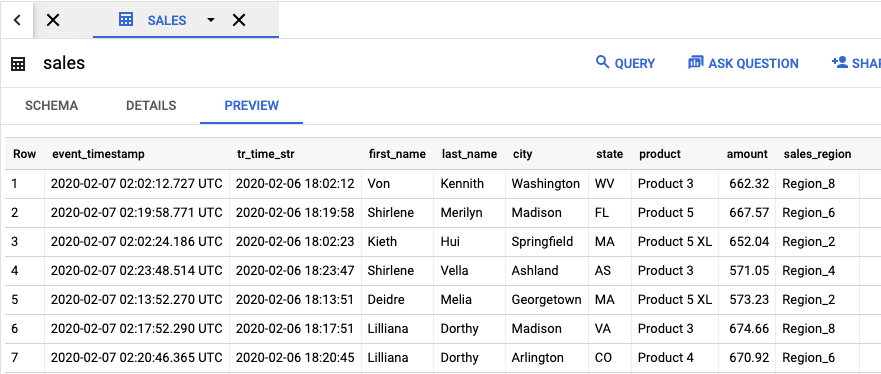
Rufen Sie die BigQuery-UI auf, um die Ausgabetabelle mit den Jobergebnissen anzusehen.
Klicken Sie im Bereich Explorer in Ihrem Projekt auf das von Ihnen erstellte Dataset dataflow_sql_tutorial. Klicken Sie anschließend auf die Ausgabetabelle sales. Auf dem Tab Vorschau wird der Inhalt der Ausgabetabelle angezeigt.
Ältere Jobs ansehen und Abfragen bearbeiten
In der Dataflow-UI werden frühere Jobs und Abfragen auf der Seite Dataflow-Jobs gespeichert.
Sie können die Jobverlaufsliste verwenden, um vorherige SQL-Abfragen anzusehen. Beispiel: Sie möchten die Abfrage ändern, mit der alle 15 Sekunden die Verkaufszahlen nach Verkaufsregion zusammengefasst werden. Verwenden Sie die Seite Jobs, um auf den laufenden Job zuzugreifen, den Sie zuvor in der Anleitung gestartet haben. Kopieren Sie die SQL-Abfrage und führen Sie einen weiteren Job mit einer geänderten Abfrage aus.
Klicken Sie auf der Dataflow-Seite Jobs auf den Job, den Sie bearbeiten möchten.
Suchen Sie auf der Seite Jobdetails im Bereich Jobdetails unter Pipeline-Optionen die SQL-Abfrage. Suchen Sie die Zeile für queryString.
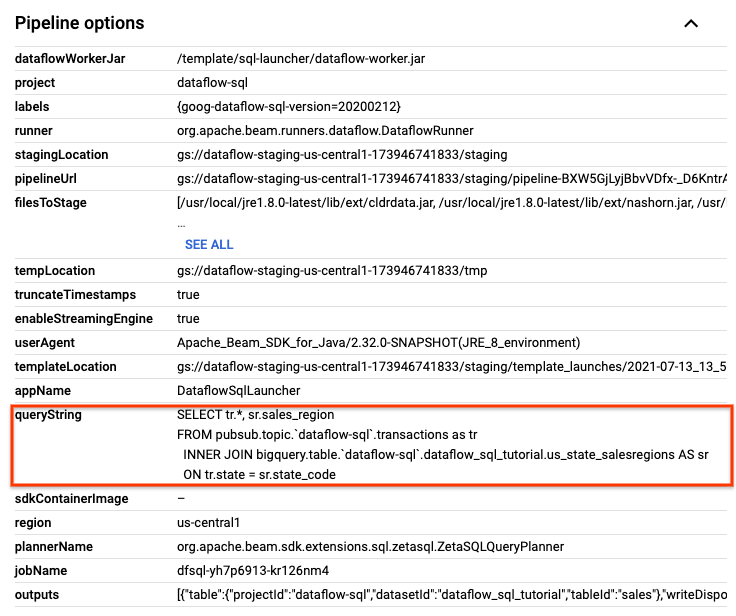
Kopieren Sie die folgende SQL-Abfrage und fügen Sie sie in den Dataflow SQL-Editor im SQL-Arbeitsbereich ein, um rollierende Fenster hinzuzufügen. Ersetzen Sie project-id durch Ihre Projekt-ID.
SELECT sr.sales_region, TUMBLE_START("INTERVAL 15 SECOND") AS period_start, SUM(tr.amount) as amount FROM pubsub.topic.`project-id`.transactions AS tr INNER JOIN bigquery.table.`project-id`.dataflow_sql_tutorial.us_state_salesregions AS sr ON tr.state = sr.state_code GROUP BY sr.sales_region, TUMBLE(tr.event_timestamp, "INTERVAL 15 SECOND")
Klicken Sie auf Job erstellen, um einen neuen Job mit der geänderten Abfrage zu erstellen.
Bereinigen
So vermeiden Sie, dass Ihrem Cloud-Rechnungskonto die in diesem Tutorial verwendeten Ressourcen in Rechnung gestellt werden:
Beenden Sie das Veröffentlichungsskript
transactions_injector.py, sofern es noch ausgeführt wird.Beenden Sie Ihre laufenden Dataflow-Jobs. Öffnen Sie in der Google Cloud Console die Dataflow-Web-UI.
Führen Sie für jeden Job, den Sie in dieser Schritt-für-Schritt-Anleitung erstellt haben, folgende Schritte aus:
Klicken Sie auf den Namen des Jobs.
Klicken Sie auf der Seite mit den Jobdetails auf Beenden. Das Dialogfeld Job beenden mit den Optionen zum Beenden des Jobs wird angezeigt.
Wählen Sie Abbrechen aus.
Klicken Sie auf Job beenden. Der Dienst hält jegliche Datenaufnahme und -verarbeitung so schnell wie möglich an. Da durch Abbrechen die Verarbeitung sofort gestoppt wird, können alle In-Flight-Daten verloren gehen. Das Beenden eines Jobs kann einige Minuten dauern.
Löschen Sie Ihr BigQuery-Dataset. Öffnen Sie in der Google Cloud Console die BigQuery-Web-UI.
Klicken Sie im Bereich Explorer im Abschnitt Ressourcen auf das von Ihnen erstellte Dataset dataflow_sql_tutorial.
Klicken Sie im Detailbereich auf Löschen. Ein Bestätigungsdialogfeld wird geöffnet.
Bestätigen Sie im Dialogfeld Dataset löschen den Löschbefehl. Geben Sie dazu
deleteein und klicken Sie dann auf Löschen.
Löschen Sie Ihr Pub/Sub-Thema. Rufen Sie in der Cloud Console die Seite Pub/Sub-Themen auf.
Wählen Sie das Thema
transactionsaus.Klicken Sie auf Löschen, um das Thema endgültig zu löschen. Ein Bestätigungsdialogfeld wird geöffnet.
Bestätigen Sie im Dialogfeld Thema löschen den Löschbefehl. Geben Sie dazu
deleteein und klicken Sie dann auf Löschen.Rufen Sie die Seite Pub/Sub-Abonnements auf.
Wählen Sie alle verbleibenden Abos für
transactionsaus. Falls Ihre Jobs nicht mehr ausgeführt werden, gibt es unter Umständen keine Abos mehr.Klicken Sie auf Löschen, um die Abos endgültig zu löschen. Klicken Sie im Bestätigungsdialogfeld auf Löschen.
Löschen Sie den Dataflow-Staging-Bucket in Cloud Storage. Rufen Sie in der Google Cloud Console die Seite Cloud Storage-Buckets auf.
Wählen Sie den Dataflow-Staging-Bucket aus.
Klicken Sie auf Löschen, um den Bucket endgültig zu löschen. Ein Bestätigungsdialogfeld wird geöffnet.
Bestätigen Sie im Dialogfeld Bucket löschen den Löschbefehl. Geben Sie dazu
DELETEein und klicken Sie dann auf Löschen.