Organízate con las colecciones
Guarda y clasifica el contenido según tus preferencias.
En esta página se explica por qué y cómo usar la función MLTransform
para preparar los datos para entrenar modelos de aprendizaje automático. Al combinar varias transformaciones de procesamiento de datos en una clase, MLTransform simplifica el proceso de aplicar operaciones de procesamiento de datos de aprendizaje automático de Apache Beam a tu flujo de trabajo.
Para obtener información sobre cómo usar MLTransform en tareas de generación de incrustaciones, consulta el artículo Generar incrustaciones con MLTransform.
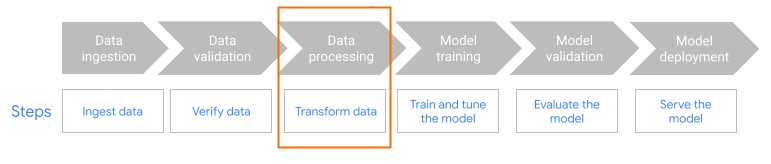
Imagen 1. Flujo de trabajo completo de Dataflow ML. Usa
MLTransform en el paso de preprocesamiento del flujo de trabajo.
Ventajas
La clase MLTransform ofrece las siguientes ventajas:
Transforma tus datos sin tener que escribir código complejo ni gestionar bibliotecas subyacentes.
Encadena de forma eficiente varios tipos de operaciones de procesamiento con una sola interfaz.
Genera incrustaciones que puedes usar para insertar datos en bases de datos vectoriales o para ejecutar inferencias.
Calcula un vocabulario único a partir de un conjunto de datos y, a continuación, asigna cada palabra o token a un índice entero distinto. Usa esta transformación para convertir datos de texto en representaciones numéricas para tareas de aprendizaje automático.
Escala tus datos para poder usarlos en el entrenamiento de tu modelo de aprendizaje automático. La clase MLTransform de Apache Beam incluye varias transformaciones de escalado de datos.
Para ver una lista completa de las transformaciones disponibles, consulta Transformaciones en la documentación de Apache Beam.
Usar MLTransform
Para usar la clase MLTransform y preprocesar datos, incluye el siguiente código en tu canalización:
[[["Es fácil de entender","easyToUnderstand","thumb-up"],["Me ofreció una solución al problema","solvedMyProblem","thumb-up"],["Otro","otherUp","thumb-up"]],[["Es difícil de entender","hardToUnderstand","thumb-down"],["La información o el código de muestra no son correctos","incorrectInformationOrSampleCode","thumb-down"],["Me faltan las muestras o la información que necesito","missingTheInformationSamplesINeed","thumb-down"],["Problema de traducción","translationIssue","thumb-down"],["Otro","otherDown","thumb-down"]],["Última actualización: 2025-09-10 (UTC)."],[[["\u003cp\u003e\u003ccode\u003eMLTransform\u003c/code\u003e streamlines the application of Apache Beam ML data processing operations by combining multiple transforms into a single class.\u003c/p\u003e\n"],["\u003cp\u003eThis class provides benefits such as transforming data without complex code, generating embeddings for vector databases, and efficiently chaining multiple processing operations.\u003c/p\u003e\n"],["\u003cp\u003e\u003ccode\u003eMLTransform\u003c/code\u003e supports both batch and streaming pipelines for text embedding generation using Vertex AI and Hugging Face, as well as batch pipelines for data processing transforms using TFT.\u003c/p\u003e\n"],["\u003cp\u003eThere are several examples available, including generating text embeddings with Vertex AI or Hugging Face, computing a vocabulary, and scaling data for ML models.\u003c/p\u003e\n"],["\u003cp\u003eTo use \u003ccode\u003eMLTransform\u003c/code\u003e, you must include specific code in your pipeline, replacing placeholder values with your transform name, bucket name, data, and transform function name.\u003c/p\u003e\n"]]],[],null,["This page explains why and how to use the\n[`MLTransform`](https://github.com/apache/beam/blob/3d501ee9dc208af2efef009daa98c49819b73ddc/sdks/python/apache_beam/ml/transforms/base.py#L112)\nfeature to prepare your data for training machine learning (ML) models. By\ncombining multiple data processing transforms in one class, `MLTransform`\nstreamlines the process of applying Apache Beam ML data processing\noperations to your workflow.\n\nFor information about using `MLTransform` for embedding generation tasks, see\n[Generate embeddings with MLTransform](/dataflow/docs/machine-learning/ml-generate-embeddings).\n\n**Figure 1.** The complete Dataflow ML workflow. Use `MLTransform` in the preprocessing step of the workflow.\n\nBenefits\n\nThe `MLTransform` class provides the following benefits:\n\n- Transform your data without writing complex code or managing underlying libraries.\n- Efficiently chain multiple types of processing operations with one interface.\n- Generate embeddings that you can use to push data into vector databases or\n to run inference.\n\n For more information about embedding generation, see\n [Generate embeddings with MLTransform](/dataflow/docs/machine-learning/ml-generate-embeddings).\n\nSupport and limitations\n\nThe `MLTransform` class has the following limitations:\n\n- Available for pipelines that use the Apache Beam Python SDK versions 2.53.0 and later.\n- Pipelines must use [default windows](https://beam.apache.org/documentation/programming-guide/#single-global-window).\n\n**Data processing transforms that use TFT:**\n\n- Support Python 3.9, 3.10, 3.11.\n- Support batch pipelines.\n\nUse cases\n\nThe example notebooks demonstrate how to use `MLTransform` for\nembeddings-specific use cases.\n\n[I want to compute a vocabulary from a dataset](/dataflow/docs/notebooks/compute_and_apply_vocab)\n: Compute a unique vocabulary from a dataset and then map each word or token to\n a distinct integer index. Use this transform to change textual data into\n numerical representations for machine learning tasks.\n\n[I want to scale my data to train my ML model](/dataflow/docs/notebooks/scale_data)\n: Scale your data so that you can use it to train your ML model. The\n Apache Beam `MLTransform` class includes multiple data scaling transforms.\n\nFor a full list of available transforms, see\n[Transforms](https://beam.apache.org/documentation/ml/preprocess-data#transforms)\nin the Apache Beam documentation.\n\nUse MLTransform\n\nTo use the `MLTransform` class to preprocess data, include the following code in\nyour pipeline: \n\n import apache_beam as beam\n from apache_beam.ml.transforms.base import MLTransform\n from apache_beam.ml.transforms.tft import \u003cvar translate=\"no\"\u003eTRANSFORM_NAME\u003c/var\u003e\n import tempfile\n\n data = [\n {\n \u003cvar translate=\"no\"\u003eDATA\u003c/var\u003e\n },\n ]\n\n artifact_location = gs://\u003cvar translate=\"no\"\u003eBUCKET_NAME\u003c/var\u003e\n \u003cvar translate=\"no\"\u003e\u003cspan class=\"devsite-syntax-nv\"\u003eTRANSFORM_FUNCTION_NAME\u003c/span\u003e\u003c/var\u003e = \u003cvar translate=\"no\"\u003eTRANSFORM_NAME\u003c/var\u003e(columns=['x'])\n\n with beam.Pipeline() as p:\n transformed_data = (\n p\n | beam.Create(data)\n | MLTransform(write_artifact_location=artifact_location).with_transform(\n \u003cvar translate=\"no\"\u003eTRANSFORM_FUNCTION_NAME\u003c/var\u003e)\n | beam.Map(print))\n\nReplace the following values:\n\n- \u003cvar translate=\"no\"\u003eTRANSFORM_NAME\u003c/var\u003e: the name of the [transform](https://beam.apache.org/documentation/ml/preprocess-data/#transforms) to use\n- \u003cvar translate=\"no\"\u003eBCUKET_NAME\u003c/var\u003e: the name of your [Cloud Storage bucket](/storage/docs/buckets#naming)\n- \u003cvar translate=\"no\"\u003eDATA\u003c/var\u003e: the input data to transform\n- \u003cvar translate=\"no\"\u003eTRANSFORM_FUNCTION_NAME\u003c/var\u003e: the name that you assign to your transform function in your code\n\nWhat's next\n\n- For more details about `MLTransform`, see [Preprocess data](https://beam.apache.org/documentation/ml/preprocess-data) in the Apache Beam documentation.\n- For more examples, see [`MLTransform` for data processing](https://beam.apache.org/documentation/transforms/python/elementwise/mltransform) in the Apache Beam transform catalog.\n- Run an [interactive notebook in Colab](https://colab.sandbox.google.com/github/apache/beam/blob/master/examples/notebooks/beam-ml/mltransform_basic.ipynb)."]]