Anda dapat menggunakan RunInference API untuk membuat pipeline yang berisi beberapa model. Pipeline multi-model
berguna untuk tugas seperti pengujian A/B dan membuat ensemble untuk
memecahkan masalah bisnis yang memerlukan lebih dari satu model ML.
Menggunakan beberapa model
Contoh kode berikut menunjukkan cara menggunakan transformasi RunInference untuk menambahkan beberapa model ke pipeline Anda.
Saat membuat pipeline dengan beberapa model, Anda dapat menggunakan salah satu dari dua pola berikut:
- Pola cabang A/B: Satu bagian dari data input akan masuk ke satu model, dan sisa data akan masuk ke model kedua.
- Pola urutan: Data input melintasi dua model, satu per satu.
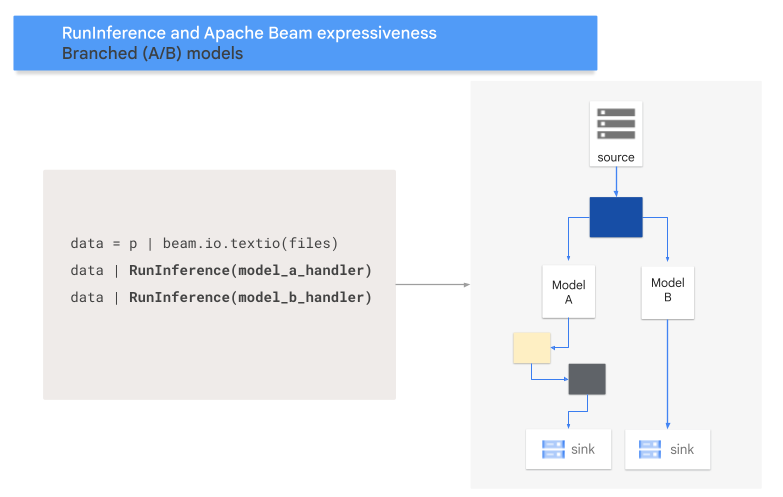
Pola A/B
Kode berikut menunjukkan cara menambahkan pola A/B ke pipeline dengan transformasi RunInference.
with pipeline as p:
data = p | 'Read' >> beam.ReadFromSource('a_source')
model_a_predictions = data | RunInference(MODEL_HANDLER_A)
model_b_predictions = data | RunInference(MODEL_HANDLER_B)
MODEL_HANDLER_A dan MODEL_HANDLER_B adalah kode penyiapan pengendali model.
Diagram berikut memberikan presentasi visual tentang proses ini.
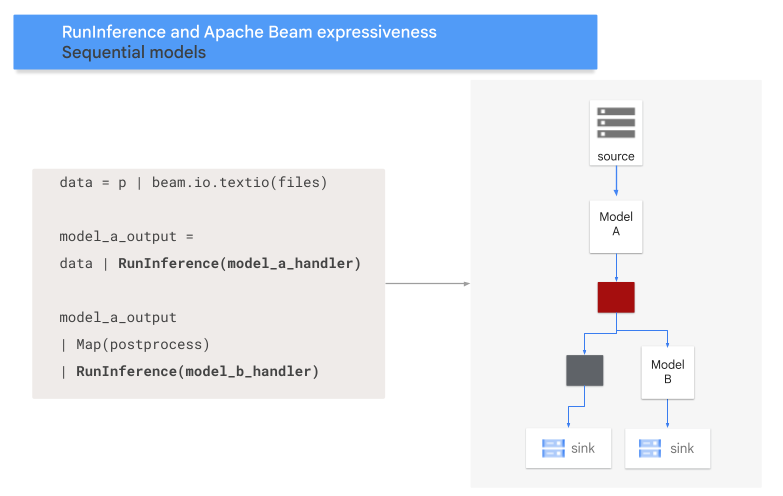
Pola urutan
Kode berikut menunjukkan cara menambahkan pola urutan ke pipeline dengan
transformasi RunInference.
with pipeline as p:
data = p | 'Read' >> beam.ReadFromSource('A_SOURCE')
model_a_predictions = data | RunInference(MODEL_HANDLER_A)
model_b_predictions = model_a_predictions | beam.Map(some_post_processing) | RunInference(MODEL_HANDLER_B)
MODEL_HANDLER_A dan MODEL_HANDLER_B adalah kode penyiapan pengendali model.
Diagram berikut memberikan presentasi visual tentang proses ini.
Memetakan model ke kunci
Anda dapat memuat beberapa model dan memetakan model tersebut ke kunci menggunakan
pengendali model dengan kunci.
Pemetaan model ke kunci memungkinkan penggunaan model
yang berbeda dalam transformasi RunInference yang sama.
Contoh berikut menggunakan pengendali model dengan kunci yang
memuat satu model menggunakan CONFIG_1 dan model kedua menggunakan CONFIG_2.
Pipeline menggunakan model yang terkait dengan CONFIG_1 untuk menjalankan inferensi
pada contoh yang terkait dengan KEY_1.
Model yang terkait dengan CONFIG_2 menjalankan inferensi pada
contoh yang terkait dengan KEY_2 dan KEY_3.
from apache_beam.ml.inference.base import KeyedModelHandler
keyed_model_handler = KeyedModelHandler([
KeyModelMapping(['KEY_1'], PytorchModelHandlerTensor(CONFIG_1)),
KeyModelMapping(['KEY_2', 'KEY_3'], PytorchModelHandlerTensor(CONFIG_2))
])
with pipeline as p:
data = p | beam.Create([
('KEY_1', torch.tensor([[1,2,3],[4,5,6],...])),
('KEY_2', torch.tensor([[1,2,3],[4,5,6],...])),
('KEY_3', torch.tensor([[1,2,3],[4,5,6],...])),
])
predictions = data | RunInference(keyed_model_handler)
Untuk contoh yang lebih mendetail, lihat Menjalankan inferensi ML dengan beberapa model yang dilatih secara berbeda.
Mengelola memori
Saat memuat beberapa model secara bersamaan, Anda mungkin mengalami error kehabisan memori (OOM). Saat Anda menggunakan pengendali model dengan kunci, Apache Beam tidak otomatis membatasi jumlah model yang dimuat ke dalam memori. Jika semua model tidak sesuai dengan memori, akan terjadi error kekurangan memori, dan pipeline akan gagal.
Untuk menghindari masalah ini, gunakan parameter max_models_per_worker_hint untuk membatasi
jumlah model yang dimuat ke dalam memori secara bersamaan. Contoh berikut
menggunakan pengendali model dengan kunci dengan parameter max_models_per_worker_hint.
Karena nilai parameter max_models_per_worker_hint ditetapkan ke 2,
pipeline memuat maksimum dua model pada setiap proses pekerja SDK secara bersamaan.
mhs = [
KeyModelMapping(['KEY_1'], PytorchModelHandlerTensor(CONFIG_1)),
KeyModelMapping(['KEY_2', 'KEY_3'], PytorchModelHandlerTensor(CONFIG_2)),
KeyModelMapping(['KEY_4'], PytorchModelHandlerTensor(CONFIG_3)),
KeyModelMapping(['KEY_5', 'KEY_5', 'KEY_6'], PytorchModelHandlerTensor(CONFIG_4)),
]
keyed_model_handler = KeyedModelHandler(mhs, max_models_per_worker_hint=2)
Saat mendesain pipeline, pastikan pekerja memiliki memori yang cukup untuk model dan transformasi pipeline. Karena memori yang digunakan oleh model mungkin tidak segera dirilis, untuk menghindari OOM, sertakan buffer memori tambahan.
Jika memiliki banyak model dan menggunakan nilai rendah dengan parameter max_models_per_worker_hint, Anda mungkin mengalami thrashing memori. Memory thrashing terjadi saat
waktu eksekusi yang berlebihan digunakan untuk menukar model masuk dan keluar dari memori. Untuk menghindari masalah ini, sertakan transformasi GroupByKey dalam pipeline sebelum langkah inferensi. Transformasi GroupByKey
memastikan bahwa elemen dengan kunci dan model yang sama berada di pekerja yang sama.
Pelajari lebih lanjut
- Baca tentang Pipeline multi-model dalam dokumentasi Apache Beam
- Menjalankan inferensi ML dengan beberapa model yang dilatih secara berbeda.
- Jalankan notebook interaktif di Colab.