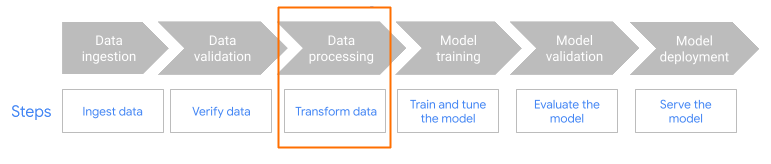
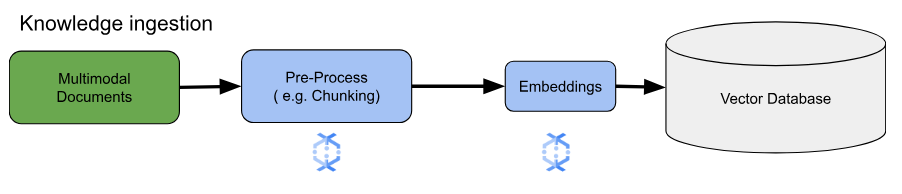
對於核心嵌入用途,主要考量是知識的擷取和處理方式。您可以選擇批次或串流方式擷取資料。這類知識的來源可能大不相同。舉例來說,這項資訊可能來自 Cloud Storage 中儲存的檔案,也可能來自 Pub/Sub 或 Google Cloud Managed Service for Apache Kafka 等串流來源。
defcreate_chunk(product:Dict[str,Any])-> Chunk:returnChunk(content=Content(text=f"{product['name']}: {product['description']}"),id=product['id'],# Use product ID as chunk IDmetadata=product,# Store all product info in metadata)[...]withbeam.Pipeline()asp:_=(p|'Create Products' >> beam.Create(products)|'Convert to Chunks' >> beam.Map(create_chunk)|'Generate Embeddings' >> MLTransform(write_artifact_location=tempfile.mkdtemp()).with_transform(huggingface_embedder)|'Write to AlloyDB' >> VectorDatabaseWriteTransform(alloydb_config))
上一個範例會為每個元素建立一個區塊,但您也可以使用 LangChain 建立區塊:
splitter=CharacterTextSplitter(chunk_size=100,chunk_overlap=20)provider=beam.ml.rag.chunking.langchain.LangChainChunker(document_field='content',metadata_fields=[],text_splitter=splitter)withbeam.Pipeline()asp:_=(p|'Create Products' >> beam.io.textio.ReadFromText(products)|'Convert to Chunks' >> provider.get_ptransform_for_processing()
[[["容易理解","easyToUnderstand","thumb-up"],["確實解決了我的問題","solvedMyProblem","thumb-up"],["其他","otherUp","thumb-up"]],[["難以理解","hardToUnderstand","thumb-down"],["資訊或程式碼範例有誤","incorrectInformationOrSampleCode","thumb-down"],["缺少我需要的資訊/範例","missingTheInformationSamplesINeed","thumb-down"],["翻譯問題","translationIssue","thumb-down"],["其他","otherDown","thumb-down"]],["上次更新時間:2025-08-18 (世界標準時間)。"],[],[],null,["This page explains why and how to use the [`MLTransform`](https://github.com/apache/beam/blob/3d501ee9dc208af2efef009daa98c49819b73ddc/sdks/python/apache_beam/ml/transforms/base.py#L112) feature to prepare\nyour data for training machine learning (ML) models. Specifically, this page\nshows you how to process data by generating embeddings using `MLTransform`.\n\nBy\ncombining multiple data processing transforms in one class, `MLTransform`\nstreamlines the process of applying Apache Beam ML data processing\noperations to your workflow.\n\n**Figure 1.** The complete Dataflow ML workflow. Use `MLTransform` in the preprocessing step of the workflow.\n\nEmbeddings overview\n\nEmbeddings are essential for modern semantic search and Retrieval Augmented\nGeneration (RAG) applications. Embeddings let systems understand and interact\nwith information on a deeper, more conceptual level. In semantic search,\nembeddings transform queries and documents into vector representations. These\nrepresentations capture their underlying meaning and relationships.\nConsequently, this lets you find relevant results even when keywords don't\ndirectly match. This is a significant leap beyond standard keyword-based search.\nYou can also use embeddings for product recommendations. This includes\nmultimodal searches that use images and text, log analytics, and for tasks such\nas deduplication.\n\nWithin RAG, embeddings play a crucial role in retrieving the most relevant\ncontext from a knowledge base to ground the responses of large language models\n(LLMs). By embedding both the user's query and the chunks of information in the\nknowledge base, RAG systems can efficiently identify and retrieve the most\nsemantically similar pieces. This semantic matching ensures that the LLM has\naccess to the necessary information to generate accurate and informative\nanswers.\n\nIngest and process data for embeddings\n\n**Figure 2.** A knowledge ingestion diagram. This shows the input multimodal documents data and two processing steps: chunking and embedding generation. Chunking is a preprocessing step used for complex data before embedding generation. After the data is processed, the embeddings are stored in a vector database.\n\nFor core embedding use cases, the key consideration is how to ingest and process\nknowledge. This ingestion can be either in a batch or streaming manner. The\nsource of this knowledge can vary widely. For example, this information can come\nfrom files stored in Cloud Storage,\nor can come from streaming sources like Pub/Sub or\nGoogle Cloud Managed Service for Apache Kafka.\n\nFor streaming sources, the data itself might be the raw content (for example,\nplain text) or URIs pointing to documents. Regardless of the source, the first\nstage typically involves preprocessing the information. For raw text, this might\nbe minimal, such as basic data cleaning. However, for larger documents or more\ncomplex content, a crucial step is *chunking*. Chunking involves breaking down\nthe source material into smaller, manageable units. The optimal chunking\nstrategy isn't standardized and depends on the specific data and application.\nPlatforms like Dataflow offer built-in capabilities to handle\ndiverse chunking needs, simplifying this essential preprocessing stage.\n\nBenefits\n\nThe `MLTransform` class provides the following benefits:\n\n- Generate embeddings that you can use to push data into vector databases or to run inference.\n- Transform your data without writing complex code or managing underlying libraries.\n- Efficiently chain multiple types of processing operations with one interface.\n\nSupport and limitations\n\nThe `MLTransform` class has the following limitations:\n\n- Available for pipelines that use the Apache Beam Python SDK versions 2.53.0 and later.\n- Pipelines must use [default\n windows](https://beam.apache.org/documentation/programming-guide/#single-global-window).\n\n**Text embedding transforms:**\n\n- Support Python 3.8, 3.9, 3.10, 3.11, and 3.12.\n- Support both batch and streaming pipelines.\n- Support the [Vertex AI text-embeddings API](/vertex-ai/docs/generative-ai/embeddings/get-text-embeddings) and the [Hugging Face Sentence Transformers module](https://huggingface.co/sentence-transformers).\n\nUse cases\n\nThe example notebooks demonstrate how to use `MLTransform` for specific use\ncases.\n\n[I want to generate text embeddings for my LLM by using Vertex AI](/dataflow/docs/notebooks/vertex_ai_text_embeddings)\n: Use the Apache Beam `MLTransform` class with the\n [Vertex AI text-embeddings API](/vertex-ai/docs/generative-ai/embeddings/get-text-embeddings)\n to generate text embeddings. Text embeddings are a way to\n represent text as numerical vectors, which is necessary for many natural\n language processing (NLP) tasks.\n\n[I want to generate text embeddings for my LLM by using Hugging Face](/dataflow/docs/notebooks/huggingface_text_embeddings)\n: Use the Apache Beam `MLTransform` class with\n [Hugging Face Hub](https://huggingface.co/docs/hub/models-the-hub)\n models to generate text embeddings. The Hugging Face\n [`SentenceTransformers`](https://huggingface.co/sentence-transformers)\n framework uses Python to generate sentence, text, and image embeddings.\n\n[I want to generate text embeddings and ingest them into AlloyDB for PostgreSQL](/dataflow/docs/notebooks/alloydb_product_catalog_embeddings)\n: Use Apache Beam, specifically its `MLTransform` class with [Hugging Face\n Hub](https://huggingface.co/docs/hub/models-the-hub) models to generate\n text embeddings. Then, use the `VectorDatabaseWriteTransform` to load these\n embeddings and associated metadata into AlloyDB for PostgreSQL. This notebook\n demonstrates building scalable batch and streaming Beam data\n pipelines for populating an AlloyDB for PostgreSQL vector database. This\n includes handling data from various sources like Pub/Sub or existing\n database tables, making custom schemas, and updating data.\n\n[I want to generate text embeddings and ingest them into BigQuery](/dataflow/docs/notebooks/bigquery_vector_ingestion_and_search)\n: Use the Apache Beam `MLTransform` class with [Hugging Face Hub](https://huggingface.co/docs/hub/models-the-hub) models\n to generate text embeddings from application data, such as a product catalog.\n The Apache Beam `HuggingfaceTextEmbeddings` transform is used for this.\n This transform uses the Hugging Face [SentenceTransformers](https://huggingface.co/sentence-transformers) framework,\n which provides models for generating sentence and text embeddings. These\n generated embeddings and their metadata are then ingested into\n BigQuery using the Apache Beam `VectorDatabaseWriteTransform`.\n The notebook further demonstrates vector similarity searches in\n BigQuery using the Enrichment transform.\n\nFor a full list of available transforms, see [Transforms](https://beam.apache.org/documentation/ml/preprocess-data#transforms) in the\nApache Beam documentation.\n\nUse MLTransform for embedding generation\n\nTo use the `MLTransform` class to chunk information and generate embeddings,\ninclude the following code in your pipeline: \n\n \n def create_chunk(product: Dict[str, Any]) -\u003e Chunk:\n return Chunk(\n content=Content(\n text=f\"{product['name']}: {product['description']}\"\n ),\n id=product['id'], # Use product ID as chunk ID\n metadata=product, # Store all product info in metadata\n )\n\n \u003cvar translate=\"no\"\u003e\u003cspan class=\"devsite-syntax-p\"\u003e[\u003c/span\u003e\u003cspan class=\"devsite-syntax-o\"\u003e...\u003c/span\u003e\u003cspan class=\"devsite-syntax-p\"\u003e]\u003c/span\u003e\u003c/var\u003e\n with beam.Pipeline() as p:\n _ = (\n p\n | 'Create Products' \u003e\u003e beam.Create(products)\n | 'Convert to Chunks' \u003e\u003e beam.Map(create_chunk)\n | 'Generate Embeddings' \u003e\u003e MLTransform(\n write_artifact_location=tempfile.mkdtemp())\n .with_transform(huggingface_embedder)\n | 'Write to AlloyDB' \u003e\u003e VectorDatabaseWriteTransform(alloydb_config)\n )\n\nThe previous example creates a single chunk per element, but you can also use\nLangChain for to create chunks instead: \n\n splitter = CharacterTextSplitter(chunk_size=100, chunk_overlap=20)\n provider = beam.ml.rag.chunking.langchain.LangChainChunker(\n document_field='content', metadata_fields=[], text_splitter=splitter)\n\n with beam.Pipeline() as p:\n _ = (\n p\n | 'Create Products' \u003e\u003e beam.io.textio.ReadFromText(products)\n | 'Convert to Chunks' \u003e\u003e provider.get_ptransform_for_processing()\n\nWhat's next\n\n- Read the blog post [\"How to enable real time semantic search and RAG\n applications with Dataflow ML\"](https://cloud.google.com/blog/topics/developers-practitioners/create-and-retrieve-embeddings-with-a-few-lines-of-dataflow-ml-code?content_ref=how+to+enable+real+time+semantic+search+and+rag+applications+with+dataflow+ml).\n- For more details about `MLTransform`, see [Preprocess data](https://beam.apache.org/documentation/ml/preprocess-data) in the Apache Beam documentation.\n- For more examples, see [`MLTransform` for data processing](https://beam.apache.org/documentation/transforms/python/elementwise/mltransform) in the Apache Beam transform catalog.\n- Run an [interactive notebook in Colab](https://colab.sandbox.google.com/github/apache/beam/blob/master/examples/notebooks/beam-ml/mltransform_basic.ipynb)."]]