Cloud Run 함수 트리거를 사용하여 보안 VM 무결성 모니터링 이벤트에 대해 자동으로 조치를 취하는 방법을 알아봅니다.
개요
무결성 모니터링 기능은 보안 VM 인스턴스에서 측정 데이터를 수집하여 Cloud Logging에 보여줍니다. 보안 VM 인스턴스가 여러 차례 부팅되는 과정에서 무결성 측정 데이터가 변경되는 경우, 무결성 확인이 실패합니다. 이러한 실패는 로깅되는 이벤트로 캡처되고 Cloud Monitoring에서도 제기됩니다.
때로는 보안 VM 무결성 측정 데이터가 타당한 이유로 변경되기도 합니다. 예를 들어 시스템을 업데이트하면 운영체제 커널에 예상되는 변화가 발생할 수 있습니다. 이러한 이유로 인해 무결성 모니터링을 통해 보안 VM 인스턴스에 예상한 무결성 확인이 실패할 경우, 새로운 무결성 정책 기준을 학습하도록 지시할 수 있습니다.
이 튜토리얼에서는 먼저 무결성 확인에 실패하는 보안 VM 인스턴스를 종료하는 간단한 자동 시스템을 만듭니다.
- 모든 무결성 모니터링 이벤트를 Cloud Pub/Sub 주제로 내보냅니다.
- 해당 주제의 이벤트를 사용하여 무결성 확인에 실패한 보안 VM 인스턴스를 식별하고 종료하는 Cloud Run 함수 트리거를 만듭니다.
그런 다음, 무결성 확인에 실패한 보안 VM 인스턴스에 새 기준이 유효한 것으로 알려진 측정과 일치하는 경우에는 해당 기준을 학습하고 그렇지 않으면 종료하라는 지시를 하도록 시스템을 선택적으로 확장할 수 있습니다.
- 유효한 것으로 알려진 무결성 기준 측정 데이터 집합을 유지하기 위한 Firestore 데이터베이스를 만듭니다.
- 무결성 확인에 실패한 보안 VM 인스턴스에 새 기준이 데이터베이스에 있으면 해당 기준을 학습하고 그렇지 않으면 종료하라는 지시를 하도록 Cloud Run 함수 트리거를 업데이트합니다.
확장된 솔루션을 구현할 경우에는 다음 방법으로 사용하세요.
- 타당한 이유로 확인이 실패할 것으로 예상되는 업데이트가 있을 때마다 인스턴스 그룹에 있는 단일 보안 VM 인스턴스에서 해당 업데이트를 실행합니다.
- 업데이트된 VM 인스턴스에서 후기 부팅 이벤트를 소스로 사용하여 known_good_measurements 모음에 새 문서를 만들어 새 정책 기준 측정을 데이터베이스에 추가합니다. 자세한 내용은 유효한 것으로 알려진 기준 측정 데이터의 데이터베이스 만들기를 참조하세요.
- 나머지 보안 VM 인스턴스를 업데이트합니다. 새 기준이 유효한 것으로 알려져 있다고 확인할 수 있으므로, 이 트리거는 나머지 인스턴스에 새 기준을 학습하도록 지시합니다. 자세한 내용은 Cloud Run 함수 트리거를 업데이트하여 유효한 것으로 알려진 기준 학습을 참조하세요.
기본 요건
- 네이티브 모드의 Firestore가 데이터베이스 서비스로 선택되어 있는 프로젝트를 사용합니다. 프로젝트 생성 시 이를 선택하면 변경할 수 없습니다. 프로젝트에서 네이티브 모드의 Firestore를 사용하지 않을 경우, Firestore 콘솔을 열 때 '이 프로젝트에서는 다른 데이터베이스 서비스를 사용합니다.'라는 메시지가 나타납니다.
- 해당 프로젝트에서 Compute Engine 보안 VM 인스턴스가 무결성 기준 측정 데이터의 소스 역할을 하도록 합니다. 보안 VM 인스턴스가 최소 한 번 이상 다시 시작되었음이 틀림없습니다.
gcloud명령줄 도구를 설치했습니다.다음 단계를 따라 Cloud Logging과 Cloud Run 함수 API를 사용 설정합니다.
Google Cloud 콘솔에서 API 및 서비스 페이지로 이동합니다.
Cloud Functions API와 Stackdriver Logging API가 사용 설정된 API 및 서비스 목록에 나타나는지 확인합니다.
API 중 어느 하나가 나타나지 않으면 API 및 서비스 추가를 클릭합니다.
필요에 따라 API를 검색하여 사용 설정합니다.
무결성 모니터링 로그 항목을 Pub/Sub 주제로 내보내기
Logging을 사용하여 보안 VM 인스턴스에서 생성된 모든 무결성 모니터링 로그 항목을 Pub/Sub 주제로 내보냅니다. 이 주제를 Cloud Run 함수 트리거에 대한 데이터 소스로 사용하여 무결성 모니터링 이벤트에 대한 응답을 자동화합니다.
로그 탐색기
Google Cloud 콘솔에서 로그 탐색기 페이지로 이동합니다.
쿼리 빌더에 다음 값을 입력합니다.
resource.type="gce_instance" AND logName: "projects/YOUR_PROJECT_ID/logs/compute.googleapis.com/shielded_vm_integrity"
필터 실행을 클릭합니다.
작업 더보기를 클릭한 후 싱크 만들기를 선택합니다.
로그 라우팅 싱크 만들기 페이지에서 다음 안내를 따르세요.
- 싱크 세부정보에서 싱크 이름에
integrity-monitoring을 입력하고 다음을 클릭합니다. - 싱크 대상에서 싱크 서비스를 확장한 후 Cloud Pub/Sub를 선택합니다.
- Cloud Pub/Sub 주제 선택을 확장한 후 주제 만들기를 선택합니다.
- 주제 만들기 대화상자의 주제 ID에
integrity-monitoring을 입력한 후 주제 만들기를 클릭합니다. - 다음을 클릭한 후 싱크 만들기를 클릭합니다.
- 싱크 세부정보에서 싱크 이름에
로그 탐색기
Google Cloud 콘솔에서 로그 탐색기 페이지로 이동합니다.
옵션을 클릭한 후 기존 로그 탐색기로 돌아가기를 선택합니다.
라벨 또는 텍스트 검색 기준 필터링을 펼친 후 고급 필터로 전환을 클릭합니다.
다음 고급 필터를 입력합니다.
resource.type="gce_instance" AND logName: "projects/YOUR_PROJECT_ID/logs/compute.googleapis.com/shielded_vm_integrity"
logName:뒤에 2개의 공백이 있습니다.필터 제출을 클릭합니다.
내보내기 만들기를 클릭합니다.
싱크 이름에
integrity-monitoring을 입력합니다.싱크 서비스의 경우 Cloud Pub/Sub를 선택합니다.
싱크 대상을 펼친 후 새 Cloud Pub/Sub 주제 만들기를 클릭합니다.
이름에
integrity-monitoring을 입력한 후 만들기를 클릭합니다.싱크 만들기를 클릭합니다.
무결성 실패에 응답하는 Cloud Run 함수 트리거 만들기
Pub/Sub 주제에 있는 데이터를 읽고 무결성 확인에 실패한 보안 VM 인스턴스를 모두 중지하는 Cloud Run 함수 트리거를 만듭니다.
다음 코드는 Cloud Run 함수 트리거를 정의합니다. 이를
main.py파일로 복사합니다.import base64 import json import googleapiclient.discovery def shutdown_vm(data, context): """A Cloud Function that shuts down a VM on failed integrity check.""" log_entry = json.loads(base64.b64decode(data['data']).decode('utf-8')) payload = log_entry.get('jsonPayload', {}) entry_type = payload.get('@type') if entry_type != 'type.googleapis.com/cloud_integrity.IntegrityEvent': raise TypeError("Unexpected log entry type: %s" % entry_type) report_event = (payload.get('earlyBootReportEvent') or payload.get('lateBootReportEvent')) if report_event is None: # We received a different event type, ignore. return policy_passed = report_event['policyEvaluationPassed'] if not policy_passed: print('Integrity evaluation failed: %s' % report_event) print('Shutting down the VM') instance_id = log_entry['resource']['labels']['instance_id'] project_id = log_entry['resource']['labels']['project_id'] zone = log_entry['resource']['labels']['zone'] # Shut down the instance. compute = googleapiclient.discovery.build( 'compute', 'v1', cache_discovery=False) # Get the instance name from instance id. list_result = compute.instances().list( project=project_id, zone=zone, filter='id eq %s' % instance_id).execute() if len(list_result['items']) != 1: raise KeyError('unexpected number of items: %d' % len(list_result['items'])) instance_name = list_result['items'][0]['name'] result = compute.instances().stop(project=project_id, zone=zone, instance=instance_name).execute() print('Instance %s in project %s has been scheduled for shut down.' % (instance_name, project_id))
main.py와 같은 위치에 이름이requirements.txt인 파일을 만들어 다음 종속 항목에 복사합니다.google-api-python-client==1.6.6 google-auth==1.4.1 google-auth-httplib2==0.0.3
터미널 창을 열고
main.py및requirements.txt가 있는 디렉터리로 이동합니다.gcloud beta functions deploy명령어를 실행하여 트리거를 배포합니다.gcloud beta functions deploy shutdown_vm \ --project PROJECT_ID \ --runtime python37 \ --trigger-resource integrity-monitoring \ --trigger-event google.pubsub.topic.publish
유효한 것으로 알려진 기준 측정의 데이터베이스 만들기
유효한 것으로 알려진 무결성 정책 기준 측정 데이터의 소스를 제공하기 위한 Firestore 데이터베이스를 만듭니다. 이 데이터베이스를 최신 상태로 유지하기 위해 기준 측정 데이터를 수동으로 추가해야 합니다.
Google Cloud 콘솔에서 VM 인스턴스 페이지로 이동합니다.
보안 VM 인스턴스 ID를 클릭하여 VM 인스턴스 세부정보 페이지를 엽니다.
로그에서 Stackdriver Logging을 클릭합니다.
가장 최근의
lateBootReportEvent로그 항목을 찾습니다.로그 항목 >
jsonPayload>lateBootReportEvent>policyMeasurements를 펼칩니다.lateBootReportEvent>policyMeasurements에 들어 있는 요소의 값을 기록합니다.Google Cloud 콘솔에서 Firestore 페이지로 이동합니다.
컬렉션 시작을 선택합니다.
컬렉션 ID에 known_good_measurements를 입력합니다.
문서 ID에 baseline1을 입력합니다.
필드 이름에
lateBootReportEvent>policyMeasurements에 있는 요소0의 pcrNum 필드 값을 입력합니다.필드 유형에서 맵을 선택합니다.
맵 필드에 각각 hashAlgo, pcrNum, value로 명명된 3개의 문자열 필드를 추가합니다. 이들의 값을
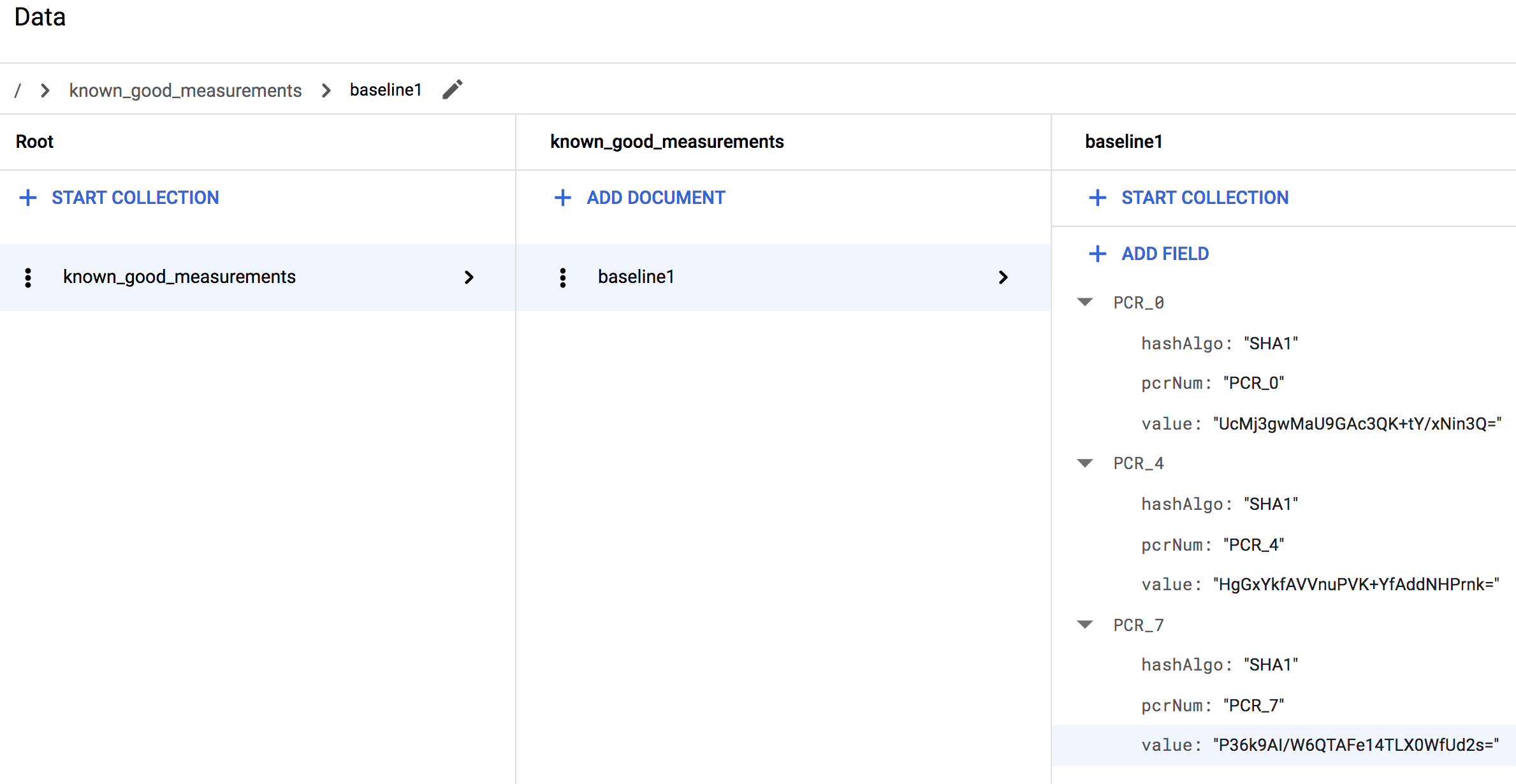
lateBootReportEvent>policyMeasurements에 있는 요소0필드의 값으로 만듭니다.lateBootReportEvent>policyMeasurements에서 각각의 추가 요소에 대해 하나씩, 더 많은 맵 필드를 만듭니다. 이들 필드에 첫 번째 맵 필드와 똑같은 하위 필드를 제공합니다. 이러한 하위 필드의 값을 각각의 추가 요소에 있는 값과 매핑해야 합니다.예를 들어 Linux VM을 사용 중인 경우 이 절차를 마치면 컬렉션이 다음과 유사하게 보여야 합니다.
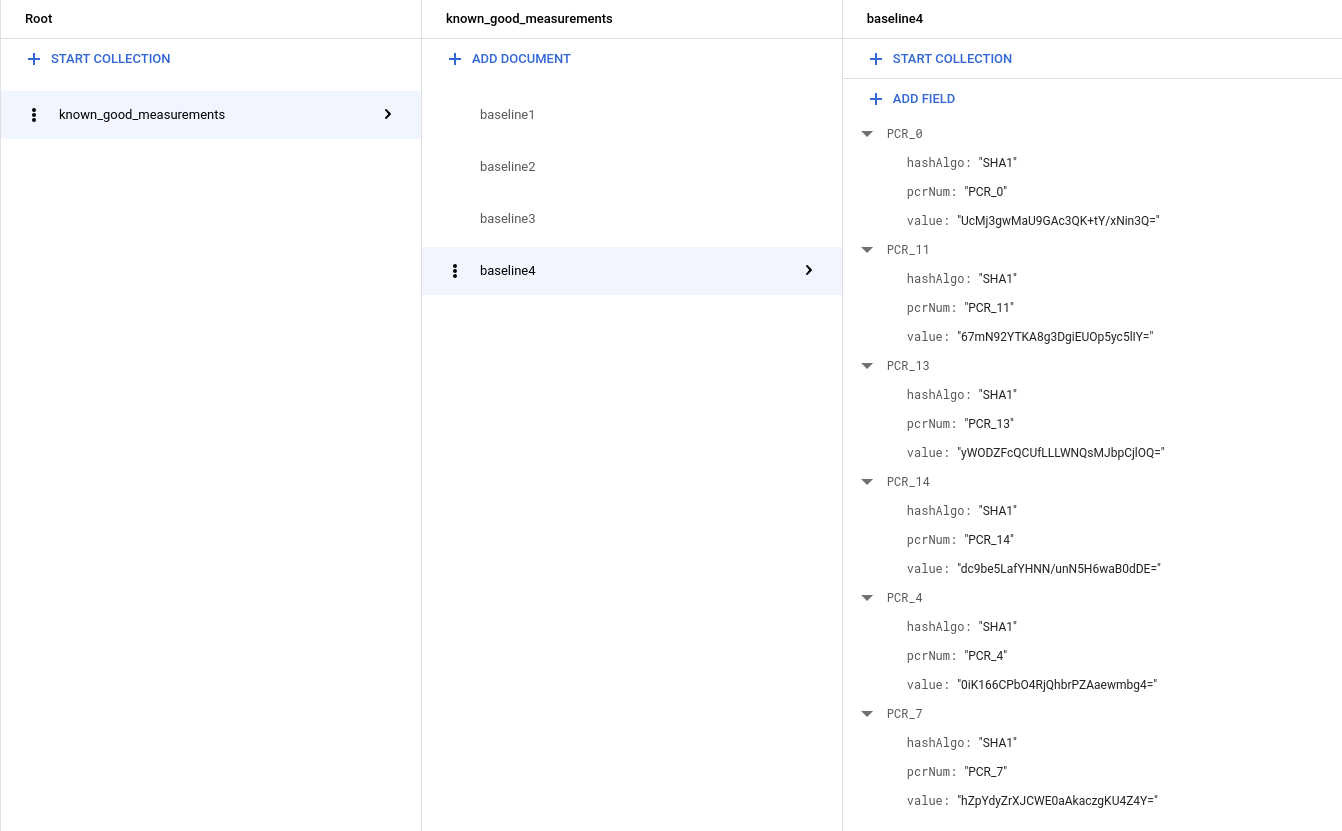
Windows VM을 사용하는 경우 측정 데이터가 더 많아지므로 컬렉션이 다음과 비슷하게 표시됩니다.
Cloud Run 함수 트리거를 업데이트하여 유효한 것으로 알려진 기준 학습
다음 코드는 무결성 확인에 실패한 보안 VM 인스턴스가 새 기준이 유효한 것으로 알려진 측정 데이터의 데이터베이스에 있으면 그 기준을 학습하고 그렇지 않으면 종료하도록 하는 Cloud Run 함수 트리거를 만듭니다. 이 코드를 복사하여
main.py의 기존 코드를 덮어씁니다.import base64 import json import googleapiclient.discovery import firebase_admin from firebase_admin import credentials from firebase_admin import firestore PROJECT_ID = 'PROJECT_ID' firebase_admin.initialize_app(credentials.ApplicationDefault(), { 'projectId': PROJECT_ID, }) def pcr_values_to_dict(pcr_values): """Converts a list of PCR values to a dict, keyed by PCR num""" result = {} for value in pcr_values: result[value['pcrNum']] = value return result def instance_id_to_instance_name(compute, zone, project_id, instance_id): list_result = compute.instances().list( project=project_id, zone=zone, filter='id eq %s' % instance_id).execute() if len(list_result['items']) != 1: raise KeyError('unexpected number of items: %d' % len(list_result['items'])) return list_result['items'][0]['name'] def relearn_if_known_good(data, context): """A Cloud Function that shuts down a VM on failed integrity check. """ log_entry = json.loads(base64.b64decode(data['data']).decode('utf-8')) payload = log_entry.get('jsonPayload', {}) entry_type = payload.get('@type') if entry_type != 'type.googleapis.com/cloud_integrity.IntegrityEvent': raise TypeError("Unexpected log entry type: %s" % entry_type) # We only send relearn signal upon receiving late boot report event: if # early boot measurements are in a known good database, but late boot # measurements aren't, and we send relearn signal upon receiving early boot # report event, the VM will also relearn late boot policy baseline, which we # don't want, because they aren't known good. report_event = payload.get('lateBootReportEvent') if report_event is None: return evaluation_passed = report_event['policyEvaluationPassed'] if evaluation_passed: # Policy evaluation passed, nothing to do. return # See if the new measurement is known good, and if it is, relearn. measurements = pcr_values_to_dict(report_event['actualMeasurements']) db = firestore.Client() kg_ref = db.collection('known_good_measurements') # Check current measurements against known good database. relearn = False for kg in kg_ref.get(): kg_map = kg.to_dict() # Check PCR values for lateBootReportEvent measurements against the known good # measurements stored in the Firestore table if ('PCR_0' in kg_map and kg_map['PCR_0'] == measurements['PCR_0'] and 'PCR_4' in kg_map and kg_map['PCR_4'] == measurements['PCR_4'] and 'PCR_7' in kg_map and kg_map['PCR_7'] == measurements['PCR_7']): # Linux VM (3 measurements), only need to check above 3 measurements if len(kg_map) == 3: relearn = True # Windows VM (6 measurements), need to check 3 additional measurements elif len(kg_map) == 6: if ('PCR_11' in kg_map and kg_map['PCR_11'] == measurements['PCR_11'] and 'PCR_13' in kg_map and kg_map['PCR_13'] == measurements['PCR_13'] and 'PCR_14' in kg_map and kg_map['PCR_14'] == measurements['PCR_14']): relearn = True compute = googleapiclient.discovery.build('compute', 'beta', cache_discovery=False) instance_id = log_entry['resource']['labels']['instance_id'] project_id = log_entry['resource']['labels']['project_id'] zone = log_entry['resource']['labels']['zone'] instance_name = instance_id_to_instance_name(compute, zone, project_id, instance_id) if not relearn: # Issue shutdown API call. print('New measurement is not known good. Shutting down a VM.') result = compute.instances().stop(project=project_id, zone=zone, instance=instance_name).execute() print('Instance %s in project %s has been scheduled for shut down.' % (instance_name, project_id)) else: # Issue relearn API call. print('New measurement is known good. Relearning...') result = compute.instances().setShieldedInstanceIntegrityPolicy( project=project_id, zone=zone, instance=instance_name, body={'updateAutoLearnPolicy':True}).execute() print('Instance %s in project %s has been scheduled for relearning.' % (instance_name, project_id))
다음 종속 항목을 복사하여
requirements.txt의 기존 코드를 덮어씁니다.google-api-python-client==1.6.6 google-auth==1.4.1 google-auth-httplib2==0.0.3 google-cloud-firestore==0.29.0 firebase-admin==2.13.0
터미널 창을 열고
main.py및requirements.txt가 있는 디렉터리로 이동합니다.gcloud beta functions deploy명령어를 실행하여 트리거를 배포합니다.gcloud beta functions deploy relearn_if_known_good \ --project PROJECT_ID \ --runtime python37 \ --trigger-resource integrity-monitoring \ --trigger-event google.pubsub.topic.publishCloud 함수 콘솔에서 이전
shutdown_vm함수를 수동으로 삭제합니다.Google Cloud 콘솔에서 Cloud Functions 페이지로 이동합니다.
shutdown_vm 함수를 선택하고 삭제를 클릭합니다.
무결성 확인 실패에 대한 자동 응답 확인
- 먼저 보안 VM 옵션으로 사용 설정된 보안 부팅을 사용하여 실행 중인 인스턴스가 있는지 확인합니다. 그렇지 않은 경우 보안 VM 이미지(Ubuntu 18.04LTS)로 새 인스턴스를 만들고 보안 부팅 옵션을 사용 설정할 수 있습니다. 인스턴스에 대해 몇 센트의 요금이 부과될 수 있습니다. 이 단계는 1시간 이내에 완료할 수 있습니다.
- 이제 어떤 이유로든 커널을 수동으로 업그레이드한다고 가정합니다.
SSH로 인스턴스에 연결하고 다음 명령어를 사용하여 현재 커널을 확인합니다.
uname -srLinux 4.15.0-1028-gcp와 같이 표시됩니다.https://kernel.ubuntu.com/~kernel-ppa/mainline/에서 일반 커널을 다운로드합니다.
다음 명령어를 사용하여 설치합니다.
sudo dpkg -i *.debVM을 재부팅합니다.
SSH를 통해 머신에 연결할 수 없으므로 VM이 부팅되지 않은 것을 알 수 있습니다. 이는 새로운 커널의 서명이 보안 부팅 허용 목록에 없으므로 예상된 문제입니다. 또한 보안 부팅이 승인되지 않거나 악의적인 커널 수정을 방지하는 방법도 보여줍니다.
하지만 커널 업그레이드가 악의적이지 않다는 것을 알고 있으며 실제로 직접 수행하므로 보안 부팅을 사용 중지하여 새 커널을 부팅할 수 있습니다.
VM을 종료하고 보안 부팅 옵션을 선택 해제한 다음 VM을 다시 시작합니다.
머신 부팅이 다시 실패합니다. 하지만 이번에는 보안 부팅 옵션을 변경할 때 생성한 Cloud 함수에 의해 자동으로 종료되고(새 커널 이미지 때문이기도 함), 측정 데이터가 기준과 달라집니다. (Cloud 함수의 Stackdriver 로그에서 확인 가능)
악의적인 수정이 아니라는 것과 근본 원인을 알고 있으므로
lateBootReportEvent의 현재 측정 데이터를 유효한 것으로 알려진 측정 데이터 Firebase 테이블에 추가할 수 있습니다. 변경되는 사항은 1. 보안 부팅 옵션 2. 커널 이미지입니다.이전 단계인 유효한 것으로 알려진 기준 측정 데이터의 데이터베이스 만들기에 따라 최신
lateBootReportEvent의 실제 측정 데이터를 사용하여 Firestore 데이터베이스에 새 기준을 추가합니다.
이제 머신을 재부팅합니다. Stackdriver 로그를 점검하면
lateBootReportEvent가 계속 실패한 것으로 표시되지만, Cloud 함수가 새 측정 데이터를 신뢰하고 다시 학습했으므로 이제 머신이 성공적으로 부팅됩니다. Cloud 함수의 Stackdriver를 보면 성공적인 부팅을 확인할 수 있습니다.보안 부팅이 사용 중지되어 이제 커널로 부팅할 수 있습니다. SSH를 통해 머신에 연결하고 커널을 다시 확인하면 새 커널 버전이 표시됩니다.
uname -sr마지막으로, 이 단계에서 사용한 리소스와 데이터를 정리합니다.
이 단계에서 VM을 만든 경우 VM을 종료해야 추가 비용이 발생하지 않습니다.
Google Cloud 콘솔에서 VM 인스턴스 페이지로 이동합니다.
이 단계에서 추가한 유효한 것으로 알려진 측정 데이터를 삭제합니다.
Google Cloud 콘솔에서 Firestore 페이지로 이동합니다.