Cloud Composer 3 | Cloud Composer 2 | Cloud Composer 1
本页介绍了如何使用 Google Kubernetes Engine Operator 在 Google Kubernetes Engine 中创建集群,以及在这些集群中启动 Kubernetes pod。
Google Kubernetes Engine Operator 在指定集群中运行 Kubernetes pod,该集群可以是与您的环境无关的独立集群。相比之下,KubernetesPodOperator 会在您环境的集群中运行 Kubernetes pod。
本页面将向您介绍一个示例 DAG,即使用 GKECreateClusterOperator 创建 Google Kubernetes Engine 集群,使用具有以下配置的 GKEStartPodOperator,并使用 GKEDeleteClusterOperator 将其删除:
准备工作
我们建议使用最新版本的 Cloud Composer。 此版本必须至少作为弃用和支持政策的一部分受到支持。
GKE Operator 配置
如需继续参照本示例执行操作,请将整个 gke_operator.py 文件放入您环境的 dags/ 文件夹中,或将相关代码添加到某个 DAG。
创建集群
此处显示的代码创建包含一个 Google Kubernetes Engine 集群,它包含两个节点池(pool-0 和 pool-1),并且每个节点池各有一个节点。如果需要,您可以在 body 中通过 Google Kubernetes Engine API 来设置其他参数。
我们建议在 Airflow 2 中使用区域级集群。可用区级集群更容易受到可用区级故障的影响。例如,您可能希望为集群使用 us-central1 区域,而不是 us-central1-a 可用区。
如需详细了解特定区域的注意事项,请参阅地理位置和区域。
发布 apache-airflow-providers-google 5.1.0 版之前,无法在 GKECreateClusterOperator 中传递 node_pools 对象。如果您使用 Airflow 2,请确保您的环境使用的是 apache-airflow-providers-google 5.1.0 或更高版本。通过指定 apache-airflow-providers-google 和 >=5.1.0 作为要求的版本,您就可以安装此 PyPI 软件包的较新版本。为了解决 Airflow 1 用户的问题,我们使用 BashOperator 和 gcloud 创建这些节点池。
Airflow 2
# TODO(developer): update with your values
PROJECT_ID = "my-project-id"
# It is recommended to use regional clusters for increased reliability
# though passing a zone in the location parameter is also valid
CLUSTER_REGION = "us-west1"
CLUSTER_NAME = "example-cluster"
CLUSTER = {
"name": CLUSTER_NAME,
"node_pools": [
{"name": "pool-0", "initial_node_count": 1},
{"name": "pool-1", "initial_node_count": 1},
],
}
create_cluster = GKECreateClusterOperator(
task_id="create_cluster",
project_id=PROJECT_ID,
location=CLUSTER_REGION,
body=CLUSTER,
)Airflow 1
# TODO(developer): update with your values
PROJECT_ID = "my-project-id"
CLUSTER_ZONE = "us-west1-a"
CLUSTER_NAME = "example-cluster"
CLUSTER = {"name": CLUSTER_NAME, "initial_node_count": 1}
create_cluster = GKECreateClusterOperator(
task_id="create_cluster",
project_id=PROJECT_ID,
location=CLUSTER_ZONE,
body=CLUSTER,
)
# Using the BashOperator to create node pools is a workaround
# In Airflow 2, because of https://github.com/apache/airflow/pull/17820
# Node pool creation can be done using the GKECreateClusterOperator
create_node_pools = BashOperator(
task_id="create_node_pools",
bash_command=f"gcloud container node-pools create pool-0 \
--cluster {CLUSTER_NAME} \
--num-nodes 1 \
--zone {CLUSTER_ZONE} \
&& gcloud container node-pools create pool-1 \
--cluster {CLUSTER_NAME} \
--num-nodes 1 \
--zone {CLUSTER_ZONE}",
)在集群中启动工作负载
以下部分介绍了示例中的每个 GKEStartPodOperator 配置。要详细了解每个配置变量,请参见 GKE Operator 的 Airflow 参考文档。
Airflow 2
from airflow import models
from airflow.providers.google.cloud.operators.kubernetes_engine import (
GKECreateClusterOperator,
GKEDeleteClusterOperator,
GKEStartPodOperator,
)
from airflow.utils.dates import days_ago
from kubernetes.client import models as k8s_models
with models.DAG(
"example_gcp_gke",
schedule_interval=None, # Override to match your needs
start_date=days_ago(1),
tags=["example"],
) as dag:
# TODO(developer): update with your values
PROJECT_ID = "my-project-id"
# It is recommended to use regional clusters for increased reliability
# though passing a zone in the location parameter is also valid
CLUSTER_REGION = "us-west1"
CLUSTER_NAME = "example-cluster"
CLUSTER = {
"name": CLUSTER_NAME,
"node_pools": [
{"name": "pool-0", "initial_node_count": 1},
{"name": "pool-1", "initial_node_count": 1},
],
}
create_cluster = GKECreateClusterOperator(
task_id="create_cluster",
project_id=PROJECT_ID,
location=CLUSTER_REGION,
body=CLUSTER,
)
kubernetes_min_pod = GKEStartPodOperator(
# The ID specified for the task.
task_id="pod-ex-minimum",
# Name of task you want to run, used to generate Pod ID.
name="pod-ex-minimum",
project_id=PROJECT_ID,
location=CLUSTER_REGION,
cluster_name=CLUSTER_NAME,
# Entrypoint of the container, if not specified the Docker container's
# entrypoint is used. The cmds parameter is templated.
cmds=["echo"],
# The namespace to run within Kubernetes, default namespace is
# `default`.
namespace="default",
# Docker image specified. Defaults to hub.docker.com, but any fully
# qualified URLs will point to a custom repository. Supports private
# gcr.io images if the Composer Environment is under the same
# project-id as the gcr.io images and the service account that Composer
# uses has permission to access the Google Container Registry
# (the default service account has permission)
image="gcr.io/gcp-runtimes/ubuntu_18_0_4",
)
kubenetes_template_ex = GKEStartPodOperator(
task_id="ex-kube-templates",
name="ex-kube-templates",
project_id=PROJECT_ID,
location=CLUSTER_REGION,
cluster_name=CLUSTER_NAME,
namespace="default",
image="bash",
# All parameters below are able to be templated with jinja -- cmds,
# arguments, env_vars, and config_file. For more information visit:
# https://airflow.apache.org/docs/apache-airflow/stable/macros-ref.html
# Entrypoint of the container, if not specified the Docker container's
# entrypoint is used. The cmds parameter is templated.
cmds=["echo"],
# DS in jinja is the execution date as YYYY-MM-DD, this docker image
# will echo the execution date. Arguments to the entrypoint. The docker
# image's CMD is used if this is not provided. The arguments parameter
# is templated.
arguments=["{{ ds }}"],
# The var template variable allows you to access variables defined in
# Airflow UI. In this case we are getting the value of my_value and
# setting the environment variable `MY_VALUE`. The pod will fail if
# `my_value` is not set in the Airflow UI.
env_vars={"MY_VALUE": "{{ var.value.my_value }}"},
)
kubernetes_affinity_ex = GKEStartPodOperator(
task_id="ex-pod-affinity",
project_id=PROJECT_ID,
location=CLUSTER_REGION,
cluster_name=CLUSTER_NAME,
name="ex-pod-affinity",
namespace="default",
image="perl",
cmds=["perl"],
arguments=["-Mbignum=bpi", "-wle", "print bpi(2000)"],
# affinity allows you to constrain which nodes your pod is eligible to
# be scheduled on, based on labels on the node. In this case, if the
# label 'cloud.google.com/gke-nodepool' with value
# 'nodepool-label-value' or 'nodepool-label-value2' is not found on any
# nodes, it will fail to schedule.
affinity={
"nodeAffinity": {
# requiredDuringSchedulingIgnoredDuringExecution means in order
# for a pod to be scheduled on a node, the node must have the
# specified labels. However, if labels on a node change at
# runtime such that the affinity rules on a pod are no longer
# met, the pod will still continue to run on the node.
"requiredDuringSchedulingIgnoredDuringExecution": {
"nodeSelectorTerms": [
{
"matchExpressions": [
{
# When nodepools are created in Google Kubernetes
# Engine, the nodes inside of that nodepool are
# automatically assigned the label
# 'cloud.google.com/gke-nodepool' with the value of
# the nodepool's name.
"key": "cloud.google.com/gke-nodepool",
"operator": "In",
# The label key's value that pods can be scheduled
# on.
"values": [
"pool-1",
],
}
]
}
]
}
}
},
)
kubernetes_full_pod = GKEStartPodOperator(
task_id="ex-all-configs",
name="full",
project_id=PROJECT_ID,
location=CLUSTER_REGION,
cluster_name=CLUSTER_NAME,
namespace="default",
image="perl:5.34.0",
# Entrypoint of the container, if not specified the Docker container's
# entrypoint is used. The cmds parameter is templated.
cmds=["perl"],
# Arguments to the entrypoint. The docker image's CMD is used if this
# is not provided. The arguments parameter is templated.
arguments=["-Mbignum=bpi", "-wle", "print bpi(2000)"],
# The secrets to pass to Pod, the Pod will fail to create if the
# secrets you specify in a Secret object do not exist in Kubernetes.
secrets=[],
# Labels to apply to the Pod.
labels={"pod-label": "label-name"},
# Timeout to start up the Pod, default is 120.
startup_timeout_seconds=120,
# The environment variables to be initialized in the container
# env_vars are templated.
env_vars={"EXAMPLE_VAR": "/example/value"},
# If true, logs stdout output of container. Defaults to True.
get_logs=True,
# Determines when to pull a fresh image, if 'IfNotPresent' will cause
# the Kubelet to skip pulling an image if it already exists. If you
# want to always pull a new image, set it to 'Always'.
image_pull_policy="Always",
# Annotations are non-identifying metadata you can attach to the Pod.
# Can be a large range of data, and can include characters that are not
# permitted by labels.
annotations={"key1": "value1"},
# Optional resource specifications for Pod, this will allow you to
# set both cpu and memory limits and requirements.
# Prior to Airflow 2.3 and the cncf providers package 5.0.0
# resources were passed as a dictionary. This change was made in
# https://github.com/apache/airflow/pull/27197
# Additionally, "memory" and "cpu" were previously named
# "limit_memory" and "limit_cpu"
# resources={'limit_memory': "250M", 'limit_cpu': "100m"},
container_resources=k8s_models.V1ResourceRequirements(
limits={"memory": "250M", "cpu": "100m"},
),
# If true, the content of /airflow/xcom/return.json from container will
# also be pushed to an XCom when the container ends.
do_xcom_push=False,
# List of Volume objects to pass to the Pod.
volumes=[],
# List of VolumeMount objects to pass to the Pod.
volume_mounts=[],
# Affinity determines which nodes the Pod can run on based on the
# config. For more information see:
# https://kubernetes.io/docs/concepts/configuration/assign-pod-node/
affinity={},
)
delete_cluster = GKEDeleteClusterOperator(
task_id="delete_cluster",
name=CLUSTER_NAME,
project_id=PROJECT_ID,
location=CLUSTER_REGION,
)
create_cluster >> kubernetes_min_pod >> delete_cluster
create_cluster >> kubernetes_full_pod >> delete_cluster
create_cluster >> kubernetes_affinity_ex >> delete_cluster
create_cluster >> kubenetes_template_ex >> delete_cluster
Airflow 1
from airflow import models
from airflow.operators.bash_operator import BashOperator
from airflow.providers.google.cloud.operators.kubernetes_engine import (
GKECreateClusterOperator,
GKEDeleteClusterOperator,
GKEStartPodOperator,
)
from airflow.utils.dates import days_ago
with models.DAG(
"example_gcp_gke",
schedule_interval=None, # Override to match your needs
start_date=days_ago(1),
tags=["example"],
) as dag:
# TODO(developer): update with your values
PROJECT_ID = "my-project-id"
CLUSTER_ZONE = "us-west1-a"
CLUSTER_NAME = "example-cluster"
CLUSTER = {"name": CLUSTER_NAME, "initial_node_count": 1}
create_cluster = GKECreateClusterOperator(
task_id="create_cluster",
project_id=PROJECT_ID,
location=CLUSTER_ZONE,
body=CLUSTER,
)
# Using the BashOperator to create node pools is a workaround
# In Airflow 2, because of https://github.com/apache/airflow/pull/17820
# Node pool creation can be done using the GKECreateClusterOperator
create_node_pools = BashOperator(
task_id="create_node_pools",
bash_command=f"gcloud container node-pools create pool-0 \
--cluster {CLUSTER_NAME} \
--num-nodes 1 \
--zone {CLUSTER_ZONE} \
&& gcloud container node-pools create pool-1 \
--cluster {CLUSTER_NAME} \
--num-nodes 1 \
--zone {CLUSTER_ZONE}",
)
kubernetes_min_pod = GKEStartPodOperator(
# The ID specified for the task.
task_id="pod-ex-minimum",
# Name of task you want to run, used to generate Pod ID.
name="pod-ex-minimum",
project_id=PROJECT_ID,
location=CLUSTER_ZONE,
cluster_name=CLUSTER_NAME,
# Entrypoint of the container, if not specified the Docker container's
# entrypoint is used. The cmds parameter is templated.
cmds=["echo"],
# The namespace to run within Kubernetes, default namespace is
# `default`.
namespace="default",
# Docker image specified. Defaults to hub.docker.com, but any fully
# qualified URLs will point to a custom repository. Supports private
# gcr.io images if the Composer Environment is under the same
# project-id as the gcr.io images and the service account that Composer
# uses has permission to access the Google Container Registry
# (the default service account has permission)
image="gcr.io/gcp-runtimes/ubuntu_18_0_4",
)
kubenetes_template_ex = GKEStartPodOperator(
task_id="ex-kube-templates",
name="ex-kube-templates",
project_id=PROJECT_ID,
location=CLUSTER_ZONE,
cluster_name=CLUSTER_NAME,
namespace="default",
image="bash",
# All parameters below are able to be templated with jinja -- cmds,
# arguments, env_vars, and config_file. For more information visit:
# https://airflow.apache.org/docs/apache-airflow/stable/macros-ref.html
# Entrypoint of the container, if not specified the Docker container's
# entrypoint is used. The cmds parameter is templated.
cmds=["echo"],
# DS in jinja is the execution date as YYYY-MM-DD, this docker image
# will echo the execution date. Arguments to the entrypoint. The docker
# image's CMD is used if this is not provided. The arguments parameter
# is templated.
arguments=["{{ ds }}"],
# The var template variable allows you to access variables defined in
# Airflow UI. In this case we are getting the value of my_value and
# setting the environment variable `MY_VALUE`. The pod will fail if
# `my_value` is not set in the Airflow UI.
env_vars={"MY_VALUE": "{{ var.value.my_value }}"},
)
kubernetes_affinity_ex = GKEStartPodOperator(
task_id="ex-pod-affinity",
project_id=PROJECT_ID,
location=CLUSTER_ZONE,
cluster_name=CLUSTER_NAME,
name="ex-pod-affinity",
namespace="default",
image="perl",
cmds=["perl"],
arguments=["-Mbignum=bpi", "-wle", "print bpi(2000)"],
# affinity allows you to constrain which nodes your pod is eligible to
# be scheduled on, based on labels on the node. In this case, if the
# label 'cloud.google.com/gke-nodepool' with value
# 'nodepool-label-value' or 'nodepool-label-value2' is not found on any
# nodes, it will fail to schedule.
affinity={
"nodeAffinity": {
# requiredDuringSchedulingIgnoredDuringExecution means in order
# for a pod to be scheduled on a node, the node must have the
# specified labels. However, if labels on a node change at
# runtime such that the affinity rules on a pod are no longer
# met, the pod will still continue to run on the node.
"requiredDuringSchedulingIgnoredDuringExecution": {
"nodeSelectorTerms": [
{
"matchExpressions": [
{
# When nodepools are created in Google Kubernetes
# Engine, the nodes inside of that nodepool are
# automatically assigned the label
# 'cloud.google.com/gke-nodepool' with the value of
# the nodepool's name.
"key": "cloud.google.com/gke-nodepool",
"operator": "In",
# The label key's value that pods can be scheduled
# on.
"values": [
"pool-1",
],
}
]
}
]
}
}
},
)
kubernetes_full_pod = GKEStartPodOperator(
task_id="ex-all-configs",
name="full",
project_id=PROJECT_ID,
location=CLUSTER_ZONE,
cluster_name=CLUSTER_NAME,
namespace="default",
image="perl",
# Entrypoint of the container, if not specified the Docker container's
# entrypoint is used. The cmds parameter is templated.
cmds=["perl"],
# Arguments to the entrypoint. The docker image's CMD is used if this
# is not provided. The arguments parameter is templated.
arguments=["-Mbignum=bpi", "-wle", "print bpi(2000)"],
# The secrets to pass to Pod, the Pod will fail to create if the
# secrets you specify in a Secret object do not exist in Kubernetes.
secrets=[],
# Labels to apply to the Pod.
labels={"pod-label": "label-name"},
# Timeout to start up the Pod, default is 120.
startup_timeout_seconds=120,
# The environment variables to be initialized in the container
# env_vars are templated.
env_vars={"EXAMPLE_VAR": "/example/value"},
# If true, logs stdout output of container. Defaults to True.
get_logs=True,
# Determines when to pull a fresh image, if 'IfNotPresent' will cause
# the Kubelet to skip pulling an image if it already exists. If you
# want to always pull a new image, set it to 'Always'.
image_pull_policy="Always",
# Annotations are non-identifying metadata you can attach to the Pod.
# Can be a large range of data, and can include characters that are not
# permitted by labels.
annotations={"key1": "value1"},
# Resource specifications for Pod, this will allow you to set both cpu
# and memory limits and requirements.
# Prior to Airflow 1.10.4, resource specifications were
# passed as a Pod Resources Class object,
# If using this example on a version of Airflow prior to 1.10.4,
# import the "pod" package from airflow.contrib.kubernetes and use
# resources = pod.Resources() instead passing a dict
# For more info see:
# https://github.com/apache/airflow/pull/4551
resources={"limit_memory": "250M", "limit_cpu": "100m"},
# If true, the content of /airflow/xcom/return.json from container will
# also be pushed to an XCom when the container ends.
do_xcom_push=False,
# List of Volume objects to pass to the Pod.
volumes=[],
# List of VolumeMount objects to pass to the Pod.
volume_mounts=[],
# Affinity determines which nodes the Pod can run on based on the
# config. For more information see:
# https://kubernetes.io/docs/concepts/configuration/assign-pod-node/
affinity={},
)
delete_cluster = GKEDeleteClusterOperator(
task_id="delete_cluster",
name=CLUSTER_NAME,
project_id=PROJECT_ID,
location=CLUSTER_ZONE,
)
create_cluster >> create_node_pools >> kubernetes_min_pod >> delete_cluster
create_cluster >> create_node_pools >> kubernetes_full_pod >> delete_cluster
create_cluster >> create_node_pools >> kubernetes_affinity_ex >> delete_cluster
create_cluster >> create_node_pools >> kubenetes_template_ex >> delete_cluster
最少的配置工作量
如需在 GKE 集群中使用 GKEStartPodOperator 启动 pod,仅需要 project_id、location、cluster_name、name、namespace、image 和 task_id 选项。
当您将以下代码段放入 DAG 时,只要定义了之前列出的参数且有效,pod-ex-minimum 任务就会成功。
Airflow 2
# TODO(developer): update with your values
PROJECT_ID = "my-project-id"
# It is recommended to use regional clusters for increased reliability
# though passing a zone in the location parameter is also valid
CLUSTER_REGION = "us-west1"
CLUSTER_NAME = "example-cluster"
kubernetes_min_pod = GKEStartPodOperator(
# The ID specified for the task.
task_id="pod-ex-minimum",
# Name of task you want to run, used to generate Pod ID.
name="pod-ex-minimum",
project_id=PROJECT_ID,
location=CLUSTER_REGION,
cluster_name=CLUSTER_NAME,
# Entrypoint of the container, if not specified the Docker container's
# entrypoint is used. The cmds parameter is templated.
cmds=["echo"],
# The namespace to run within Kubernetes, default namespace is
# `default`.
namespace="default",
# Docker image specified. Defaults to hub.docker.com, but any fully
# qualified URLs will point to a custom repository. Supports private
# gcr.io images if the Composer Environment is under the same
# project-id as the gcr.io images and the service account that Composer
# uses has permission to access the Google Container Registry
# (the default service account has permission)
image="gcr.io/gcp-runtimes/ubuntu_18_0_4",
)Airflow 1
# TODO(developer): update with your values
PROJECT_ID = "my-project-id"
CLUSTER_ZONE = "us-west1-a"
CLUSTER_NAME = "example-cluster"
kubernetes_min_pod = GKEStartPodOperator(
# The ID specified for the task.
task_id="pod-ex-minimum",
# Name of task you want to run, used to generate Pod ID.
name="pod-ex-minimum",
project_id=PROJECT_ID,
location=CLUSTER_ZONE,
cluster_name=CLUSTER_NAME,
# Entrypoint of the container, if not specified the Docker container's
# entrypoint is used. The cmds parameter is templated.
cmds=["echo"],
# The namespace to run within Kubernetes, default namespace is
# `default`.
namespace="default",
# Docker image specified. Defaults to hub.docker.com, but any fully
# qualified URLs will point to a custom repository. Supports private
# gcr.io images if the Composer Environment is under the same
# project-id as the gcr.io images and the service account that Composer
# uses has permission to access the Google Container Registry
# (the default service account has permission)
image="gcr.io/gcp-runtimes/ubuntu_18_0_4",
)模板配置
Airflow 支持使用 Jinja 生成模板。您必须在 Operator 中声明所需变量(task_id、name、namespace、image)。如以下示例所示,您可以搭配使用 Jinja 和所有其他参数生成模板,包括 cmds、arguments 和 env_vars。
在不更改 DAG 或您的环境的情况下,ex-kube-templates 任务失败。设置名为 my_value 的 Airflow 变量,以使此 DAG 成功。
如需通过 gcloud 或 Airflow 界面设置 my_value,请执行以下操作:
gcloud
对于 Airflow 2,请输入以下命令:
gcloud composer environments run ENVIRONMENT \
--location LOCATION \
variables set -- \
my_value example_value
对于 Airflow 1,请输入以下命令:
gcloud composer environments run ENVIRONMENT \
--location LOCATION \
variables -- \
--set my_value example_value
替换:
ENVIRONMENT替换为环境的名称。LOCATION替换为环境所在的区域。
Airflow 界面
在 Airflow 2 界面中:
在工具栏中,选择 Admin > Variables。
在 List Variable 页面上,点击 Add a new record。
在 Add Variable 页面上,输入以下信息:
- Key:
my_value - Val:
example_value
- Key:
点击保存。
在 Airflow 1 界面中:
在工具栏中,选择 Admin > Variables。
在 Variables 页面上,点击 Create 标签页。
在 Variable 页面上,输入以下信息:
- Key:
my_value - Val:
example_value
- Key:
点击保存。
模板配置
Airflow 2
# TODO(developer): update with your values
PROJECT_ID = "my-project-id"
# It is recommended to use regional clusters for increased reliability
# though passing a zone in the location parameter is also valid
CLUSTER_REGION = "us-west1"
CLUSTER_NAME = "example-cluster"
kubenetes_template_ex = GKEStartPodOperator(
task_id="ex-kube-templates",
name="ex-kube-templates",
project_id=PROJECT_ID,
location=CLUSTER_REGION,
cluster_name=CLUSTER_NAME,
namespace="default",
image="bash",
# All parameters below are able to be templated with jinja -- cmds,
# arguments, env_vars, and config_file. For more information visit:
# https://airflow.apache.org/docs/apache-airflow/stable/macros-ref.html
# Entrypoint of the container, if not specified the Docker container's
# entrypoint is used. The cmds parameter is templated.
cmds=["echo"],
# DS in jinja is the execution date as YYYY-MM-DD, this docker image
# will echo the execution date. Arguments to the entrypoint. The docker
# image's CMD is used if this is not provided. The arguments parameter
# is templated.
arguments=["{{ ds }}"],
# The var template variable allows you to access variables defined in
# Airflow UI. In this case we are getting the value of my_value and
# setting the environment variable `MY_VALUE`. The pod will fail if
# `my_value` is not set in the Airflow UI.
env_vars={"MY_VALUE": "{{ var.value.my_value }}"},
)Airflow 1
# TODO(developer): update with your values
PROJECT_ID = "my-project-id"
CLUSTER_ZONE = "us-west1-a"
CLUSTER_NAME = "example-cluster"
kubenetes_template_ex = GKEStartPodOperator(
task_id="ex-kube-templates",
name="ex-kube-templates",
project_id=PROJECT_ID,
location=CLUSTER_ZONE,
cluster_name=CLUSTER_NAME,
namespace="default",
image="bash",
# All parameters below are able to be templated with jinja -- cmds,
# arguments, env_vars, and config_file. For more information visit:
# https://airflow.apache.org/docs/apache-airflow/stable/macros-ref.html
# Entrypoint of the container, if not specified the Docker container's
# entrypoint is used. The cmds parameter is templated.
cmds=["echo"],
# DS in jinja is the execution date as YYYY-MM-DD, this docker image
# will echo the execution date. Arguments to the entrypoint. The docker
# image's CMD is used if this is not provided. The arguments parameter
# is templated.
arguments=["{{ ds }}"],
# The var template variable allows you to access variables defined in
# Airflow UI. In this case we are getting the value of my_value and
# setting the environment variable `MY_VALUE`. The pod will fail if
# `my_value` is not set in the Airflow UI.
env_vars={"MY_VALUE": "{{ var.value.my_value }}"},
)Pod 亲和性配置
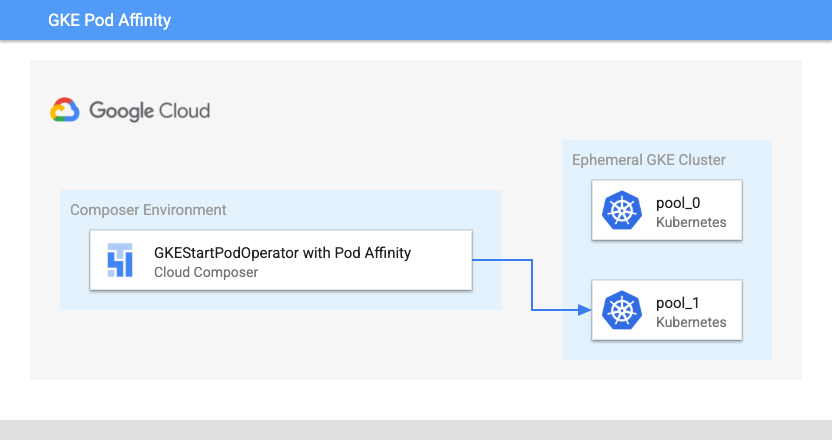
在 GKEStartPodOperator 中配置 affinity 参数后,您可以控制要在哪些节点上安排 Pod,例如仅在特定节点池中的节点上安排。创建集群时,创建了两个名为 pool-0 和 pool-1 的节点池。此操作节点指定必须仅在 pool-1 中运行 pod。
Airflow 2
# TODO(developer): update with your values
PROJECT_ID = "my-project-id"
# It is recommended to use regional clusters for increased reliability
# though passing a zone in the location parameter is also valid
CLUSTER_REGION = "us-west1"
CLUSTER_NAME = "example-cluster"
kubernetes_affinity_ex = GKEStartPodOperator(
task_id="ex-pod-affinity",
project_id=PROJECT_ID,
location=CLUSTER_REGION,
cluster_name=CLUSTER_NAME,
name="ex-pod-affinity",
namespace="default",
image="perl",
cmds=["perl"],
arguments=["-Mbignum=bpi", "-wle", "print bpi(2000)"],
# affinity allows you to constrain which nodes your pod is eligible to
# be scheduled on, based on labels on the node. In this case, if the
# label 'cloud.google.com/gke-nodepool' with value
# 'nodepool-label-value' or 'nodepool-label-value2' is not found on any
# nodes, it will fail to schedule.
affinity={
"nodeAffinity": {
# requiredDuringSchedulingIgnoredDuringExecution means in order
# for a pod to be scheduled on a node, the node must have the
# specified labels. However, if labels on a node change at
# runtime such that the affinity rules on a pod are no longer
# met, the pod will still continue to run on the node.
"requiredDuringSchedulingIgnoredDuringExecution": {
"nodeSelectorTerms": [
{
"matchExpressions": [
{
# When nodepools are created in Google Kubernetes
# Engine, the nodes inside of that nodepool are
# automatically assigned the label
# 'cloud.google.com/gke-nodepool' with the value of
# the nodepool's name.
"key": "cloud.google.com/gke-nodepool",
"operator": "In",
# The label key's value that pods can be scheduled
# on.
"values": [
"pool-1",
],
}
]
}
]
}
}
},
)Airflow 1
# TODO(developer): update with your values
PROJECT_ID = "my-project-id"
CLUSTER_ZONE = "us-west1-a"
CLUSTER_NAME = "example-cluster"
kubernetes_affinity_ex = GKEStartPodOperator(
task_id="ex-pod-affinity",
project_id=PROJECT_ID,
location=CLUSTER_ZONE,
cluster_name=CLUSTER_NAME,
name="ex-pod-affinity",
namespace="default",
image="perl",
cmds=["perl"],
arguments=["-Mbignum=bpi", "-wle", "print bpi(2000)"],
# affinity allows you to constrain which nodes your pod is eligible to
# be scheduled on, based on labels on the node. In this case, if the
# label 'cloud.google.com/gke-nodepool' with value
# 'nodepool-label-value' or 'nodepool-label-value2' is not found on any
# nodes, it will fail to schedule.
affinity={
"nodeAffinity": {
# requiredDuringSchedulingIgnoredDuringExecution means in order
# for a pod to be scheduled on a node, the node must have the
# specified labels. However, if labels on a node change at
# runtime such that the affinity rules on a pod are no longer
# met, the pod will still continue to run on the node.
"requiredDuringSchedulingIgnoredDuringExecution": {
"nodeSelectorTerms": [
{
"matchExpressions": [
{
# When nodepools are created in Google Kubernetes
# Engine, the nodes inside of that nodepool are
# automatically assigned the label
# 'cloud.google.com/gke-nodepool' with the value of
# the nodepool's name.
"key": "cloud.google.com/gke-nodepool",
"operator": "In",
# The label key's value that pods can be scheduled
# on.
"values": [
"pool-1",
],
}
]
}
]
}
}
},
)完整配置
此示例展示了您可以在 GKEStartPodOperator 中配置的所有变量。您不用修改代码,ex-all-configs 任务也会成功。
如需详细了解每个变量,请参见 GKE Operator 的 Airflow 参考文档。
Airflow 2
# TODO(developer): update with your values
PROJECT_ID = "my-project-id"
# It is recommended to use regional clusters for increased reliability
# though passing a zone in the location parameter is also valid
CLUSTER_REGION = "us-west1"
CLUSTER_NAME = "example-cluster"
kubernetes_full_pod = GKEStartPodOperator(
task_id="ex-all-configs",
name="full",
project_id=PROJECT_ID,
location=CLUSTER_REGION,
cluster_name=CLUSTER_NAME,
namespace="default",
image="perl:5.34.0",
# Entrypoint of the container, if not specified the Docker container's
# entrypoint is used. The cmds parameter is templated.
cmds=["perl"],
# Arguments to the entrypoint. The docker image's CMD is used if this
# is not provided. The arguments parameter is templated.
arguments=["-Mbignum=bpi", "-wle", "print bpi(2000)"],
# The secrets to pass to Pod, the Pod will fail to create if the
# secrets you specify in a Secret object do not exist in Kubernetes.
secrets=[],
# Labels to apply to the Pod.
labels={"pod-label": "label-name"},
# Timeout to start up the Pod, default is 120.
startup_timeout_seconds=120,
# The environment variables to be initialized in the container
# env_vars are templated.
env_vars={"EXAMPLE_VAR": "/example/value"},
# If true, logs stdout output of container. Defaults to True.
get_logs=True,
# Determines when to pull a fresh image, if 'IfNotPresent' will cause
# the Kubelet to skip pulling an image if it already exists. If you
# want to always pull a new image, set it to 'Always'.
image_pull_policy="Always",
# Annotations are non-identifying metadata you can attach to the Pod.
# Can be a large range of data, and can include characters that are not
# permitted by labels.
annotations={"key1": "value1"},
# Optional resource specifications for Pod, this will allow you to
# set both cpu and memory limits and requirements.
# Prior to Airflow 2.3 and the cncf providers package 5.0.0
# resources were passed as a dictionary. This change was made in
# https://github.com/apache/airflow/pull/27197
# Additionally, "memory" and "cpu" were previously named
# "limit_memory" and "limit_cpu"
# resources={'limit_memory': "250M", 'limit_cpu': "100m"},
container_resources=k8s_models.V1ResourceRequirements(
limits={"memory": "250M", "cpu": "100m"},
),
# If true, the content of /airflow/xcom/return.json from container will
# also be pushed to an XCom when the container ends.
do_xcom_push=False,
# List of Volume objects to pass to the Pod.
volumes=[],
# List of VolumeMount objects to pass to the Pod.
volume_mounts=[],
# Affinity determines which nodes the Pod can run on based on the
# config. For more information see:
# https://kubernetes.io/docs/concepts/configuration/assign-pod-node/
affinity={},
)Airflow 1
# TODO(developer): update with your values
PROJECT_ID = "my-project-id"
CLUSTER_ZONE = "us-west1-a"
CLUSTER_NAME = "example-cluster"
kubernetes_full_pod = GKEStartPodOperator(
task_id="ex-all-configs",
name="full",
project_id=PROJECT_ID,
location=CLUSTER_ZONE,
cluster_name=CLUSTER_NAME,
namespace="default",
image="perl",
# Entrypoint of the container, if not specified the Docker container's
# entrypoint is used. The cmds parameter is templated.
cmds=["perl"],
# Arguments to the entrypoint. The docker image's CMD is used if this
# is not provided. The arguments parameter is templated.
arguments=["-Mbignum=bpi", "-wle", "print bpi(2000)"],
# The secrets to pass to Pod, the Pod will fail to create if the
# secrets you specify in a Secret object do not exist in Kubernetes.
secrets=[],
# Labels to apply to the Pod.
labels={"pod-label": "label-name"},
# Timeout to start up the Pod, default is 120.
startup_timeout_seconds=120,
# The environment variables to be initialized in the container
# env_vars are templated.
env_vars={"EXAMPLE_VAR": "/example/value"},
# If true, logs stdout output of container. Defaults to True.
get_logs=True,
# Determines when to pull a fresh image, if 'IfNotPresent' will cause
# the Kubelet to skip pulling an image if it already exists. If you
# want to always pull a new image, set it to 'Always'.
image_pull_policy="Always",
# Annotations are non-identifying metadata you can attach to the Pod.
# Can be a large range of data, and can include characters that are not
# permitted by labels.
annotations={"key1": "value1"},
# Resource specifications for Pod, this will allow you to set both cpu
# and memory limits and requirements.
# Prior to Airflow 1.10.4, resource specifications were
# passed as a Pod Resources Class object,
# If using this example on a version of Airflow prior to 1.10.4,
# import the "pod" package from airflow.contrib.kubernetes and use
# resources = pod.Resources() instead passing a dict
# For more info see:
# https://github.com/apache/airflow/pull/4551
resources={"limit_memory": "250M", "limit_cpu": "100m"},
# If true, the content of /airflow/xcom/return.json from container will
# also be pushed to an XCom when the container ends.
do_xcom_push=False,
# List of Volume objects to pass to the Pod.
volumes=[],
# List of VolumeMount objects to pass to the Pod.
volume_mounts=[],
# Affinity determines which nodes the Pod can run on based on the
# config. For more information see:
# https://kubernetes.io/docs/concepts/configuration/assign-pod-node/
affinity={},
)删除集群
此处所示代码会删除在本指南开头创建的集群。
Airflow 2
delete_cluster = GKEDeleteClusterOperator(
task_id="delete_cluster",
name=CLUSTER_NAME,
project_id=PROJECT_ID,
location=CLUSTER_REGION,
)Airflow 1
delete_cluster = GKEDeleteClusterOperator(
task_id="delete_cluster",
name=CLUSTER_NAME,
project_id=PROJECT_ID,
location=CLUSTER_ZONE,
)