Cloud Composer 1 | Cloud Composer 2 | Cloud Composer 3
Neste tutorial, mostramos como usar o Cloud Composer para criar um Gráfico acíclico dirigido (DAG) do Apache Airflow (em inglês) que executa um job de contagem de palavras do Apache Hadoop em um aglomerado.
Objetivos
- Acesse seu ambiente do Cloud Composer e use a interface do Airflow.
- Crie e visualize variáveis de ambiente do Airflow.
- Criar e executar um DAG que inclua as seguintes tarefas:
- Cria um Dataproc aglomerado.
- Executa um job de contagem de palavras do Apache Hadoop (link em inglês) no cluster.
- Gera os resultados da contagem de palavras em um bucket do Cloud Storage.
- Exclui o cluster.
Custos
Neste documento, você vai usar os seguintes componentes faturáveis do Google Cloud:
- Cloud Composer
- Dataproc
- Cloud Storage
Para gerar uma estimativa de custo baseada na sua projeção de uso,
use a calculadora de preços.
Antes de começar
Verifique se as seguintes APIs estão ativadas no seu projeto:
Console
Enable the Dataproc, Cloud Storage APIs.
gcloud
Enable the Dataproc, Cloud Storage APIs:
gcloud services enable dataproc.googleapis.com
storage-component.googleapis.com No seu projeto, criar um bucket do Cloud Storage de qualquer classe e região de armazenamento para armazenar os resultados de contagem de palavras.
Observe o caminho do bucket que você criou, por exemplo,
gs://example-bucket. Você vai definir uma variável do Airflow para esse caminho e usá-la no DAG de exemplo mais adiante neste tutorial.Crie um ambiente do Cloud Composer com parâmetros padrão. Aguarde até que a criação do ambiente seja concluída. Quando terminar, o uma marca de seleção verde é exibida à esquerda do nome do ambiente.
Anote a região onde você criou o ambiente, por exemplo
us-central: Você vai definir uma variável do Airflow para essa região e usá-la no DAG de exemplo para executar um cluster do Dataproc na mesma região.
definir variáveis do Airflow
Defina as variáveis do Airflow para usar mais tarde no DAG de exemplo. Por exemplo, é possível definir variáveis do Airflow na interface do Airflow.
| Variável do Airflow | Valor |
|---|---|
gcp_project
|
O ID do projeto
que você está usando para este tutorial, como example-project. |
gcs_bucket
|
O bucket do URI do Cloud Storage que você criou para este tutorial,
como gs://example-bucket. |
gce_region
|
A região em que você criou o ambiente, como us-central1.
Essa é a região em que o cluster do Dataproc será criado. |
Confira o exemplo de fluxo de trabalho
Um DAG do Airflow é uma coleção de tarefas organizadas que você quer programar e executar. Os DAGs são definidos em arquivos Python padrão. O código mostrado em
hadoop_tutorial.py é o código do fluxo de trabalho.
Airflow 2
Airflow 1
Operadores
Para orquestrar as três tarefas no fluxo de trabalho de exemplo, o DAG importa as a seguir, estes três operadores do Airflow:
DataprocClusterCreateOperator: cria um cluster do Dataproc.DataProcHadoopOperator: envia um job de contagem de palavras do Hadoop e grava os resultados em um bucket do Cloud Storage.DataprocClusterDeleteOperator: exclui o cluster para evitar incorrer cobranças contínuas do Compute Engine.
Dependências
Você organiza as tarefas que deseja executar de forma a refletir relações e dependências. As tarefas neste DAG são executadas sequencialmente.
Airflow 2
Airflow 1
Programação
O nome do DAG é composer_hadoop_tutorial e ele é executado uma vez por
dia. Como o start_date transmitido para a default_dag_args é
definido como yesterday, o Cloud Composer programa o fluxo de trabalho
comece imediatamente após o upload do DAG no bucket do ambiente.
Airflow 2
Airflow 1
faça upload do DAG para o bucket do ambiente
O Cloud Composer armazena DAGs na pasta /dags no bucket do seu ambiente.
Siga estas etapas para fazer o upload do DAG:
Na máquina local, salve
hadoop_tutorial.py.No console do Google Cloud, acesse a página Ambientes.
Na lista de ambientes, na coluna Pasta de DAGs do seu ambiente, clique no link DAGs.
Clique em Enviar arquivos.
Selecione
hadoop_tutorial.pyna sua máquina local e clique em Abrir.
O Cloud Composer adiciona o DAG ao Airflow e agenda o DAG automaticamente. As alterações no DAG levam de 3 a 5 minutos.
Explorar as execuções do DAG
Conferir o status da tarefa
Quando você faz o upload do arquivo DAG para a pasta dags/ no Cloud Storage,
o Cloud Composer analisa o arquivo. Quando concluído, o nome
do fluxo de trabalho aparece na lista de DAGs, e o fluxo de trabalho é colocado na fila para ser executado
imediatamente.
Para ver o status da tarefa, acesse a interface da Web do Airflow e clique em DAGs na barra de ferramentas.
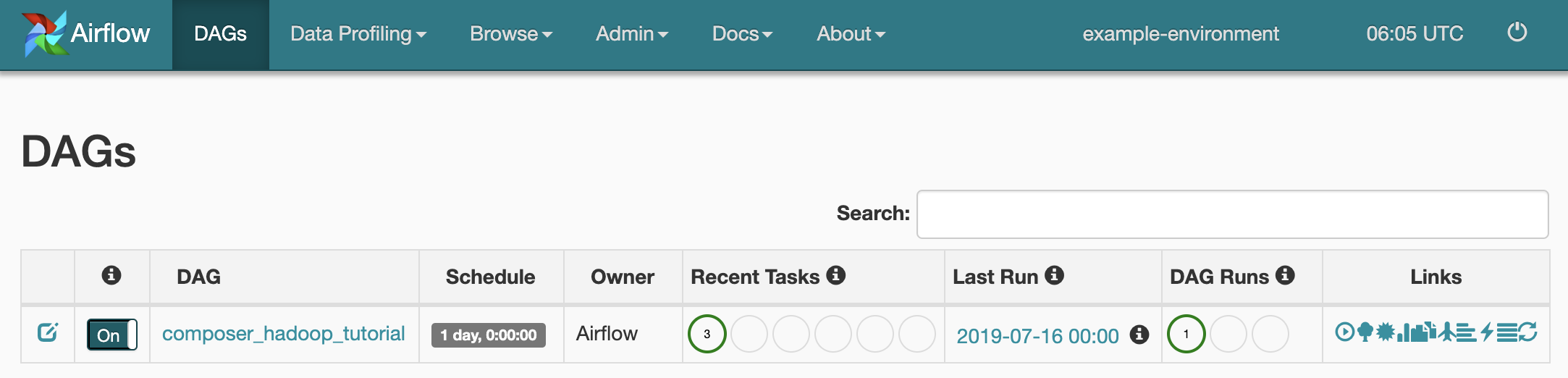
Para abrir a página de detalhes do DAG, clique em
composer_hadoop_tutorial. Isso inclui uma representação gráfica das tarefas do fluxo de trabalho e dependências.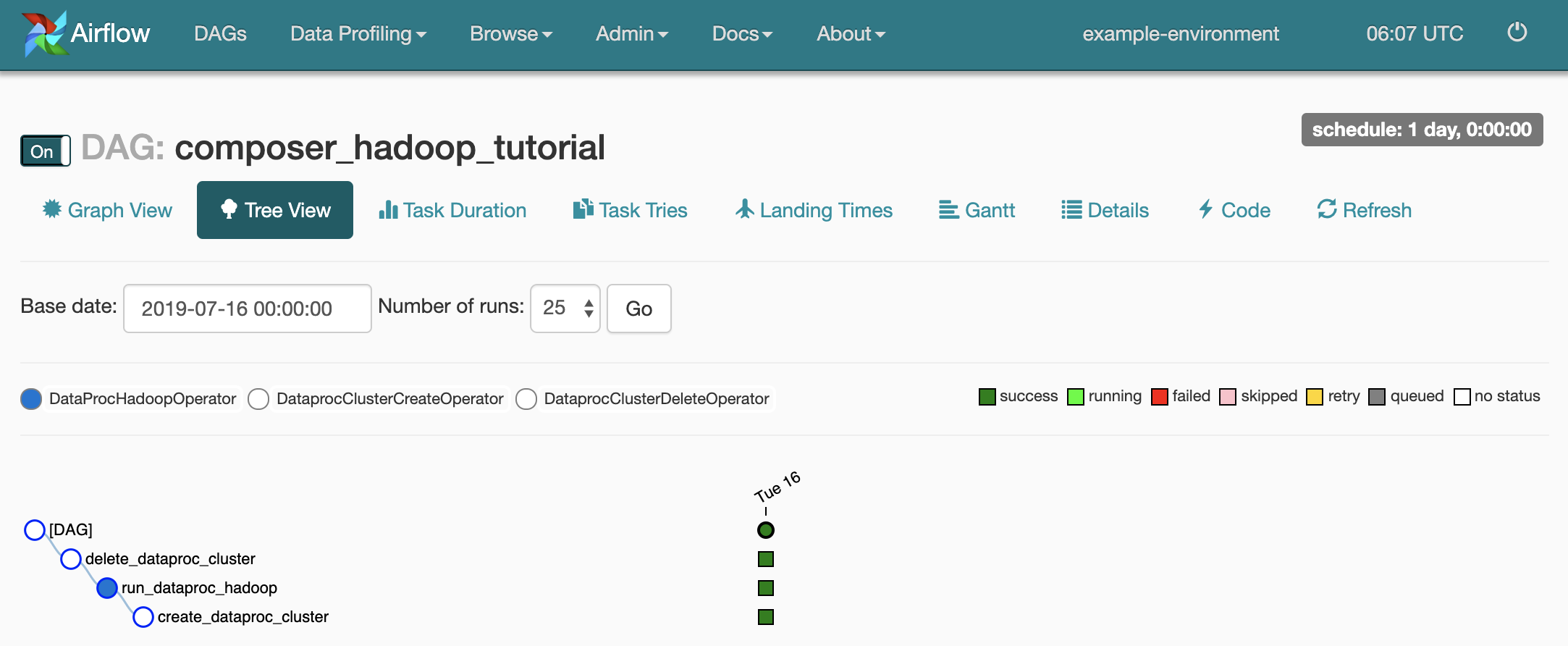
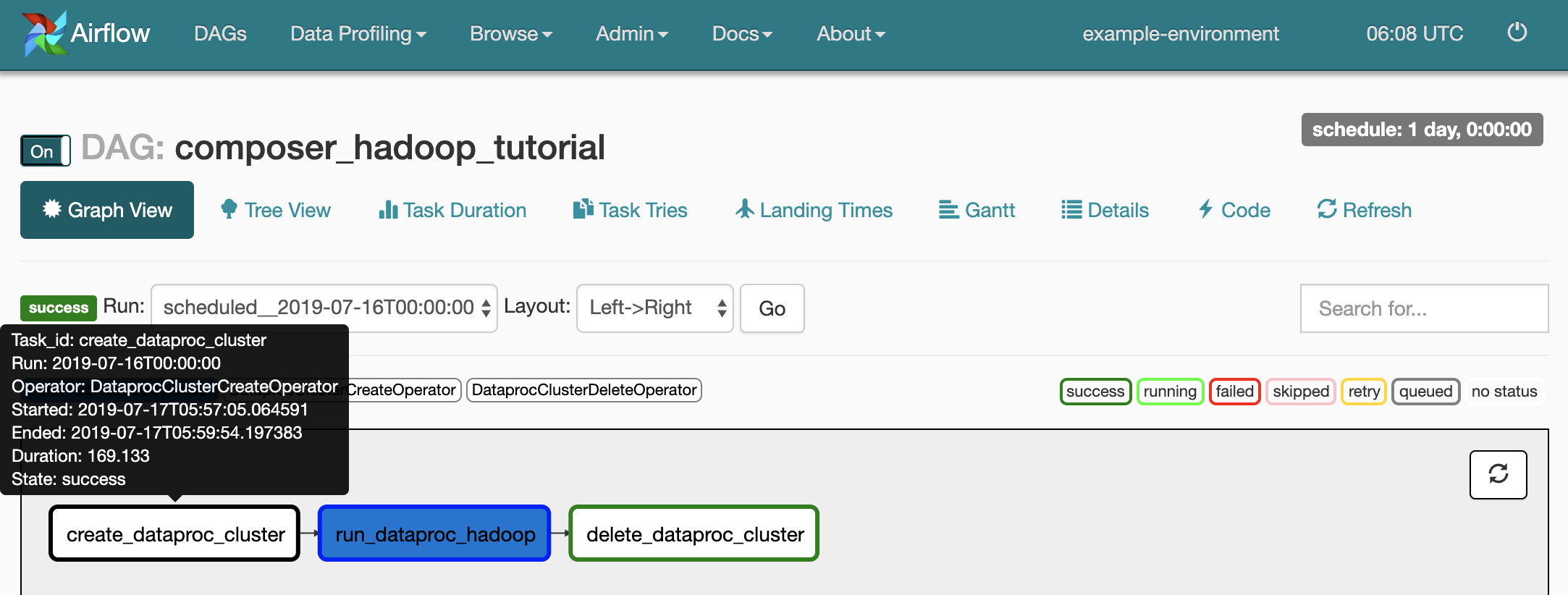
Para ver o status de cada tarefa, clique em Visualização de gráfico e, em seguida, passe o mouse sobre a imagem de cada tarefa.
Enfileirar o fluxo de trabalho novamente
Para executar o fluxo de trabalho novamente a partir da Visualização de gráfico:
- Na visualização de gráfico da IU do Airflow, clique no gráfico
create_dataproc_cluster. - Para redefinir as três tarefas, clique em Limpar e em OK para confirmar.
- Clique em
create_dataproc_clusternovamente na visualização de gráfico. - Para enfileirar o fluxo de trabalho novamente, clique em Executar.
Conferir resultados de tarefas
Também é possível verificar o status e os resultados do composer_hadoop_tutorial.
do BigQuery acessando as seguintes páginas do console do Google Cloud:
Clusters do Dataproc: para monitorar a criação e exclusão de clusters. O cluster criado pelo fluxo de trabalho é temporário: ele existe apenas durante o fluxo de trabalho e é excluído como parte do a última tarefa do fluxo de trabalho.
Jobs do Dataproc: para visualizar ou monitorar o job de contagem de palavras do Apache Hadoop. Clique no ID do job para ver a saída do registro dele.
Navegador do Cloud Storage: para ver os resultados da contagem de palavras no a pasta
wordcountno bucket do Cloud Storage que você criou para este tutorial.
Limpeza
Exclua os recursos usados neste tutorial:
Exclua o ambiente do Cloud Composer, incluindo a exclusão manual do bucket do ambiente.
Exclua o bucket do Cloud Storage que armazena os resultados do job de contagem de palavras do Hadoop.