Cloud Composer 3 | Cloud Composer 2 | Cloud Composer 1
Halaman ini menjelaskan cara menggunakan DataflowTemplateOperator untuk meluncurkan pipeline Dataflow dari Cloud Composer.
Pipeline Cloud Storage Text to BigQuery
adalah pipeline batch yang memungkinkan Anda mengupload file teks yang tersimpan di Cloud Storage, mengubahnya menggunakan User Defined Function (UDF) JavaScript yang Anda berikan, dan memberikan hasilnya ke BigQuery.
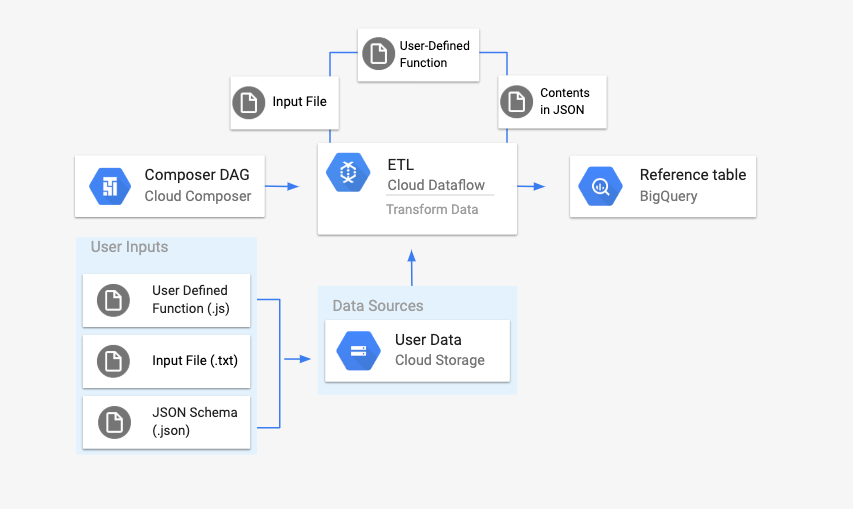
Ringkasan
Sebelum memulai alur kerja, Anda akan membuat entitas berikut:
Tabel BigQuery kosong dari set data kosong yang akan menyimpan kolom informasi berikut:
location,average_temperature,month, dan secara opsional,inches_of_rain,is_current, danlatest_measurement.File JSON yang akan menormalisasi data dari file
.txtke dalam format yang benar untuk skema tabel BigQuery. Objek JSON akan memiliki arrayBigQuery Schema, dengan setiap objek akan berisi nama kolom, jenis input, dan apakah kolom tersebut wajib diisi atau tidak.File input
.txtyang akan menyimpan data yang akan diupload secara batch ke tabel BigQuery.Fungsi Buatan Pengguna yang ditulis dalam JavaScript yang akan mengubah setiap baris file
.txtmenjadi variabel yang relevan untuk tabel kita.File DAG Airflow yang akan menunjuk ke lokasi file ini.
Selanjutnya, Anda akan mengupload file
.txt, file UDF.js, dan file skema.jsonke bucket Cloud Storage. Anda juga akan mengupload DAG ke lingkungan Cloud Composer.Setelah DAG diupload, Airflow akan menjalankan tugas dari DAG tersebut. Tugas ini akan meluncurkan pipeline Dataflow yang akan menerapkan User-Defined Function ke file
.txtdan memformatnya sesuai dengan skema JSON.Terakhir, data akan diupload ke tabel BigQuery yang Anda buat sebelumnya.
Sebelum memulai
- Panduan ini memerlukan pemahaman tentang JavaScript untuk menulis User Defined Function.
- Panduan ini mengasumsikan bahwa Anda sudah memiliki lingkungan Cloud Composer. Lihat Membuat lingkungan untuk membuatnya. Anda dapat menggunakan versi Cloud Composer apa pun dengan panduan ini.
Enable the Cloud Composer, Dataflow, Cloud Storage, BigQuery APIs.
Pastikan Anda memiliki izin berikut:
- Peran Cloud Composer: membuat lingkungan (jika Anda belum memilikinya), mengelola objek di bucket lingkungan, Menjalankan DAG, dan mengakses UI Airflow.
- Peran Cloud Storage: Membuat bucket dan mengelola objek di dalamnya.
- Peran BigQuery: Membuat set data dan tabel, mengubah data dalam tabel, mengubah skema dan metadata tabel.
- Peran Dataflow: Melihat tugas Dataflow.
Pastikan akun layanan lingkungan Anda memiliki izin untuk membuat tugas Dataflow, mengakses bucket Cloud Storage, dan membaca serta memperbarui data untuk tabel di BigQuery.
Membuat tabel BigQuery kosong dengan definisi skema
Buat tabel BigQuery dengan definisi skema. Anda akan menggunakan definisi skema ini nanti dalam panduan ini. Tabel BigQuery ini akan menyimpan hasil upload batch.
Untuk membuat tabel kosong dengan definisi skema:
Konsol
Di konsol Google Cloud , buka halaman BigQuery:
Di panel navigasi, di bagian Resource, luaskan project Anda.
Di panel detail, klik Buat set data.
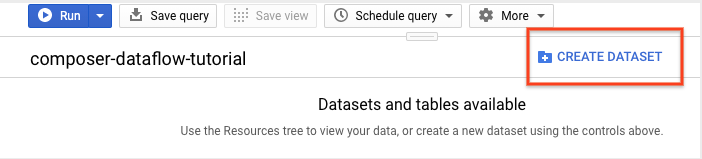
Di halaman Buat set data, di bagian ID set data, beri nama Set data Anda
average_weather. Biarkan semua kolom lain dalam status defaultnya.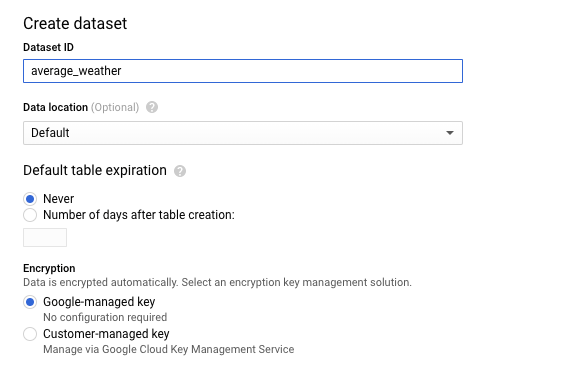
Klik Create dataset.
Kembali ke panel navigasi, di bagian Resource, luaskan project Anda. Kemudian, klik set data
average_weather.Di panel detail, klik Buat tabel.
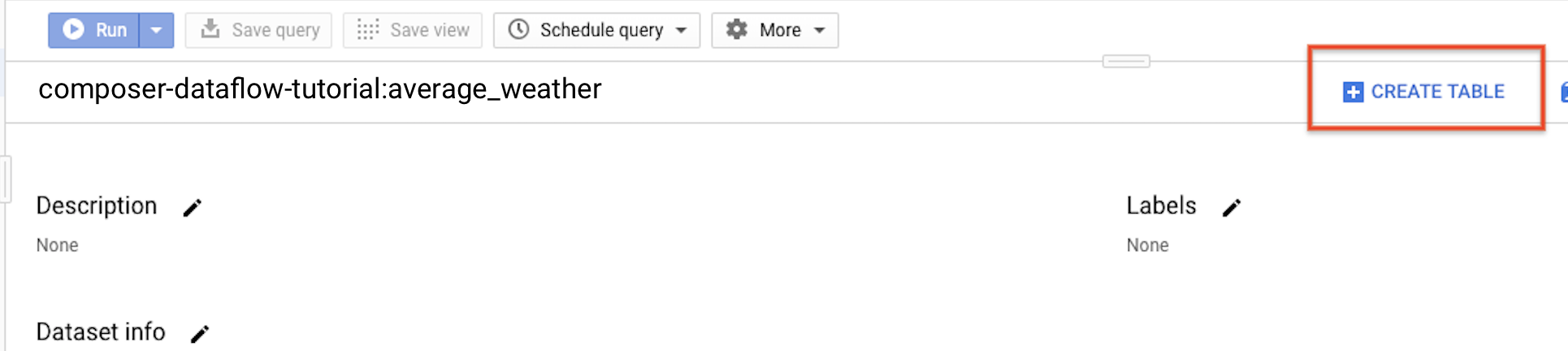
Di halaman Create table, di bagian Source, pilih Empty table.
Di halaman Create table, di bagian Destination:
Untuk Dataset name, pilih set data
average_weather.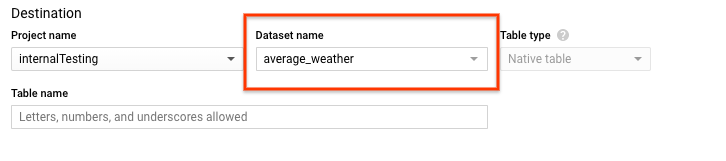
Di kolom Table name, masukkan nama
average_weather.Pastikan Table type disetel ke Native table.
Di bagian Schema, masukkan definisi skema. Anda dapat menggunakan salah satu pendekatan berikut:
Masukkan informasi skema secara manual dengan mengaktifkan Edit sebagai teks dan memasukkan skema tabel sebagai array JSON. Ketik kolom berikut:
[ { "name": "location", "type": "GEOGRAPHY", "mode": "REQUIRED" }, { "name": "average_temperature", "type": "INTEGER", "mode": "REQUIRED" }, { "name": "month", "type": "STRING", "mode": "REQUIRED" }, { "name": "inches_of_rain", "type": "NUMERIC" }, { "name": "is_current", "type": "BOOLEAN" }, { "name": "latest_measurement", "type": "DATE" } ]Gunakan Tambahkan kolom untuk memasukkan skema secara manual:
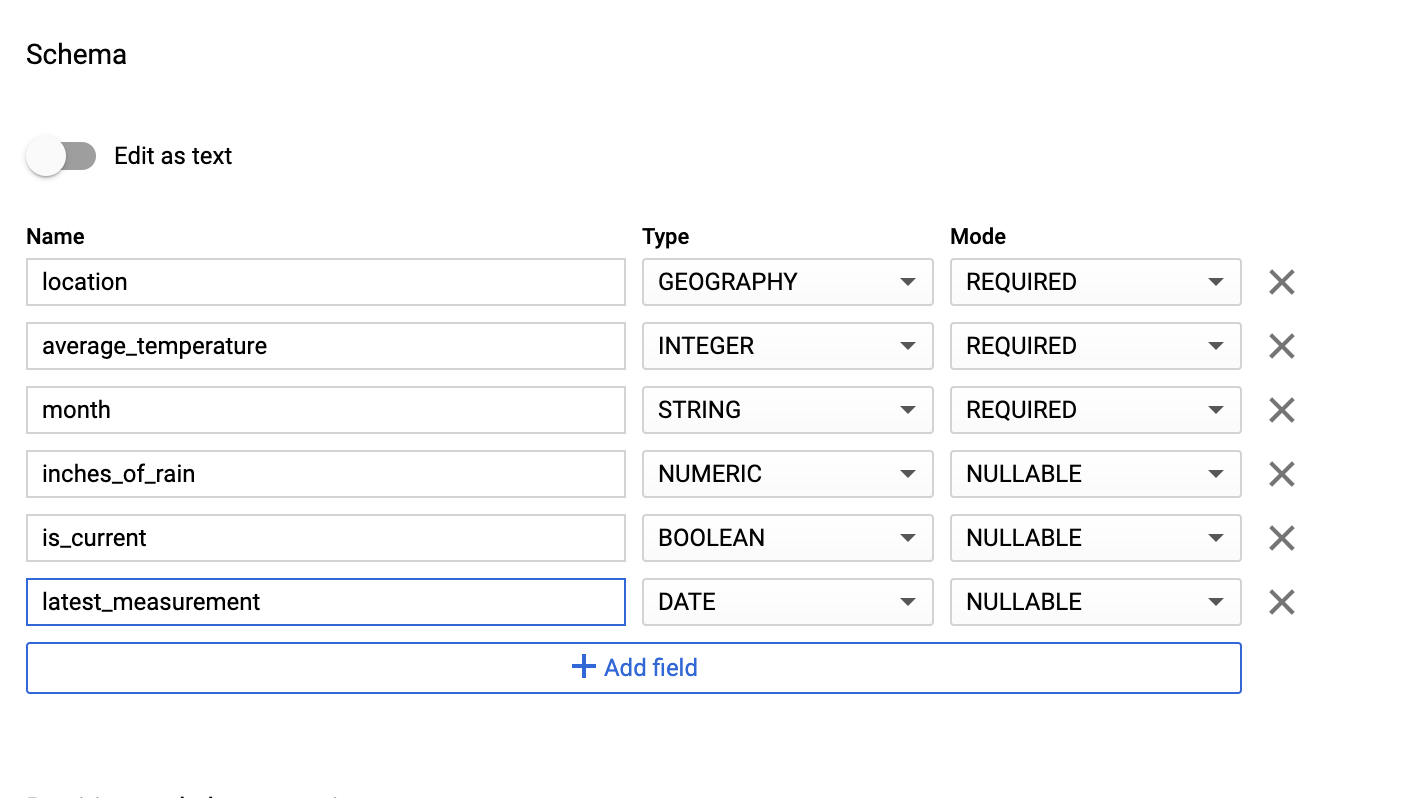
Untuk Partition and cluster settings, gunakan nilai default,
No partitioning.Di bagian Opsi lanjutan, untuk Enkripsi, biarkan nilai defaultnya,
Google-owned and managed key.Klik Create table.
bq
Gunakan perintah bq mk untuk membuat set data kosong dan tabel dalam set data ini.
Jalankan perintah berikut untuk membuat set data cuaca global rata-rata:
bq --location=LOCATION mk \
--dataset PROJECT_ID:average_weather
Ganti kode berikut:
LOCATION: region tempat lingkungan berada.PROJECT_ID: Project ID.
Jalankan perintah berikut untuk membuat tabel kosong dalam set data ini dengan definisi skema:
bq mk --table \
PROJECT_ID:average_weather.average_weather \
location:GEOGRAPHY,average_temperature:INTEGER,month:STRING,inches_of_rain:NUMERIC,is_current:BOOLEAN,latest_measurement:DATE
Setelah tabel dibuat, Anda dapat memperbarui masa berlaku, deskripsi, dan label tabel. Anda juga dapat mengubah definisi skema.
Python
Simpan kode ini sebagai
dataflowtemplateoperator_create_dataset_and_table_helper.py
dan perbarui variabel di dalamnya untuk mencerminkan project dan lokasi Anda, lalu
jalankan dengan perintah berikut:
python dataflowtemplateoperator_create_dataset_and_table_helper.py
Python
Untuk melakukan autentikasi ke Cloud Composer, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan autentikasi untuk lingkungan pengembangan lokal.
Membuat bucket Cloud Storage
Buat bucket untuk menyimpan semua file yang diperlukan untuk alur kerja. DAG yang Anda buat nanti dalam panduan ini akan mereferensikan file yang Anda upload ke bucket penyimpanan ini. Untuk membuat bucket penyimpanan baru:
Konsol
Buka Cloud Storage di konsol Google Cloud .
Klik Buat Bucket untuk membuka formulir pembuatan bucket.
Masukkan informasi bucket Anda, lalu klik Continue untuk menyelesaikan setiap langkah:
Tentukan Nama yang unik secara global untuk bucket Anda. Panduan ini menggunakan
bucketNamesebagai contoh.Pilih Region untuk jenis lokasi. Selanjutnya, pilih Location tempat data bucket akan disimpan.
Pilih Standard sebagai kelas penyimpanan default untuk data Anda.
Pilih kontrol akses Seragam untuk mengakses objek Anda.
Klik Selesai.
gcloud
Gunakan perintah gcloud storage buckets create:
gcloud storage buckets create gs://bucketName/
Ganti kode berikut:
bucketName: nama bucket yang Anda buat sebelumnya dalam panduan ini.
Contoh kode
C#
Untuk melakukan autentikasi ke Cloud Composer, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan autentikasi untuk lingkungan pengembangan lokal.
Go
Untuk melakukan autentikasi ke Cloud Composer, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan autentikasi untuk lingkungan pengembangan lokal.
Java
Untuk melakukan autentikasi ke Cloud Composer, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan autentikasi untuk lingkungan pengembangan lokal.
Python
Untuk melakukan autentikasi ke Cloud Composer, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan autentikasi untuk lingkungan pengembangan lokal.
Ruby
Untuk melakukan autentikasi ke Cloud Composer, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan autentikasi untuk lingkungan pengembangan lokal.
Buat skema BigQuery berformat JSON untuk tabel output Anda
Buat file skema BigQuery berformat JSON yang cocok dengan tabel output yang Anda buat sebelumnya. Perhatikan bahwa nama, jenis, dan mode kolom harus cocok dengan yang ditentukan sebelumnya dalam skema tabel BigQuery Anda. File ini akan menormalisasi data dari file .txt Anda ke dalam format yang kompatibel dengan skema BigQuery Anda. Beri nama file ini
jsonSchema.json.
{
"BigQuery Schema": [
{
"name": "location",
"type": "GEOGRAPHY",
"mode": "REQUIRED"
},
{
"name": "average_temperature",
"type": "INTEGER",
"mode": "REQUIRED"
},
{
"name": "month",
"type": "STRING",
"mode": "REQUIRED"
},
{
"name": "inches_of_rain",
"type": "NUMERIC"
},
{
"name": "is_current",
"type": "BOOLEAN"
},
{
"name": "latest_measurement",
"type": "DATE"
}]
}
Membuat file JavaScript untuk memformat data Anda
Dalam file ini, Anda akan menentukan UDF (User Defined Function) yang menyediakan logika untuk mengubah baris teks dalam file input. Perhatikan bahwa fungsi ini menggunakan setiap baris teks dalam file input sebagai argumennya sendiri, sehingga fungsi akan berjalan satu kali untuk setiap baris file input Anda. Beri nama file ini
transformCSVtoJSON.js.
Buat file input Anda
File ini akan menyimpan informasi yang ingin Anda upload ke tabel BigQuery. Salin file ini secara lokal dan beri nama
inputFile.txt.
POINT(40.7128 74.006),45,'July',null,true,2020-02-16
POINT(41.8781 87.6298),23,'October',13,false,2015-02-13
POINT(48.8566 2.3522),80,'December',null,true,null
POINT(6.5244 3.3792),15,'March',14,true,null
Mengupload file ke bucket Anda
Upload file berikut ke bucket Cloud Storage yang Anda buat sebelumnya:
- Skema BigQuery berformat JSON (
.json) - Fungsi yang Ditentukan Pengguna JavaScript (
transformCSVtoJSON.js) File input teks yang ingin Anda proses (
.txt)
Konsol
- Di Google Cloud konsol, buka halaman Bucket Cloud Storage.
Dalam daftar bucket, klik bucket Anda.
Di tab Objek untuk bucket, lakukan salah satu hal berikut:
Tarik lalu lepas file yang diinginkan dari desktop atau pengelola file ke panel utama di konsol Google Cloud .
Klik tombol Upload File, pilih file yang ingin diupload dalam dialog yang muncul, lalu klik Buka.
gcloud
Jalankan perintah gcloud storage cp:
gcloud storage cp OBJECT_LOCATION gs://bucketName
Ganti kode berikut:
bucketName: nama bucket yang Anda buat sebelumnya dalam panduan ini.OBJECT_LOCATION: jalur lokal ke objek Anda. Contoh,Desktop/transformCSVtoJSON.js.
Contoh kode
Python
Untuk melakukan autentikasi ke Cloud Composer, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan autentikasi untuk lingkungan pengembangan lokal.
Ruby
Untuk melakukan autentikasi ke Cloud Composer, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan autentikasi untuk lingkungan pengembangan lokal.
Konfigurasi DataflowTemplateOperator
Sebelum menjalankan DAG, tetapkan variabel Airflow berikut.
| Variabel Airflow | Nilai |
|---|---|
project_id
|
Project ID. Contoh: example-project. |
gce_zone
|
Zona Compute Engine tempat cluster Dataflow harus dibuat. Contoh: us-central1-a. Untuk mengetahui informasi selengkapnya tentang zona yang valid, lihat Region dan zona. |
bucket_path
|
Lokasi bucket Cloud Storage yang Anda buat sebelumnya. Contoh: gs://example-bucket |
Sekarang Anda akan mereferensikan file yang Anda buat sebelumnya untuk membuat DAG yang memulai alur kerja Dataflow. Salin DAG ini dan simpan secara lokal sebagai composer-dataflow-dag.py.
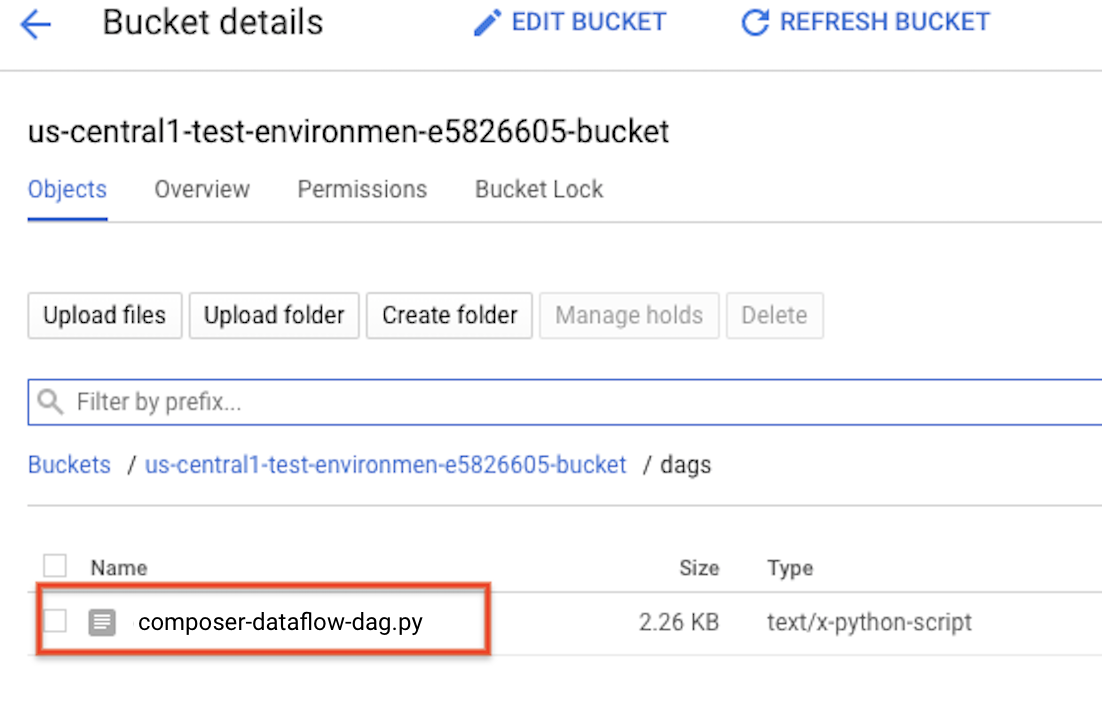
Mengupload DAG ke Cloud Storage
Upload DAG Anda ke folder /dags di bucket lingkungan Anda. Setelah upload berhasil diselesaikan, Anda dapat melihatnya dengan
mengklik link Folder DAG di halaman Lingkungan Cloud Composer.
Melihat status tugas
- Buka antarmuka web Airflow.
- Di halaman DAG, klik nama DAG (seperti
composerDataflowDAG). - Di halaman Detail DAG, klik Graph View.
Periksa status:
Failed: Tugas memiliki kotak merah di sekelilingnya. Anda juga dapat menahan kursor di atas tugas dan mencari Status: Gagal.Success: Tugas memiliki kotak hijau di sekelilingnya. Anda juga dapat mengarahkan kursor ke tugas dan memeriksa Status: Berhasil.
Setelah beberapa menit, Anda dapat memeriksa hasilnya di Dataflow dan BigQuery.
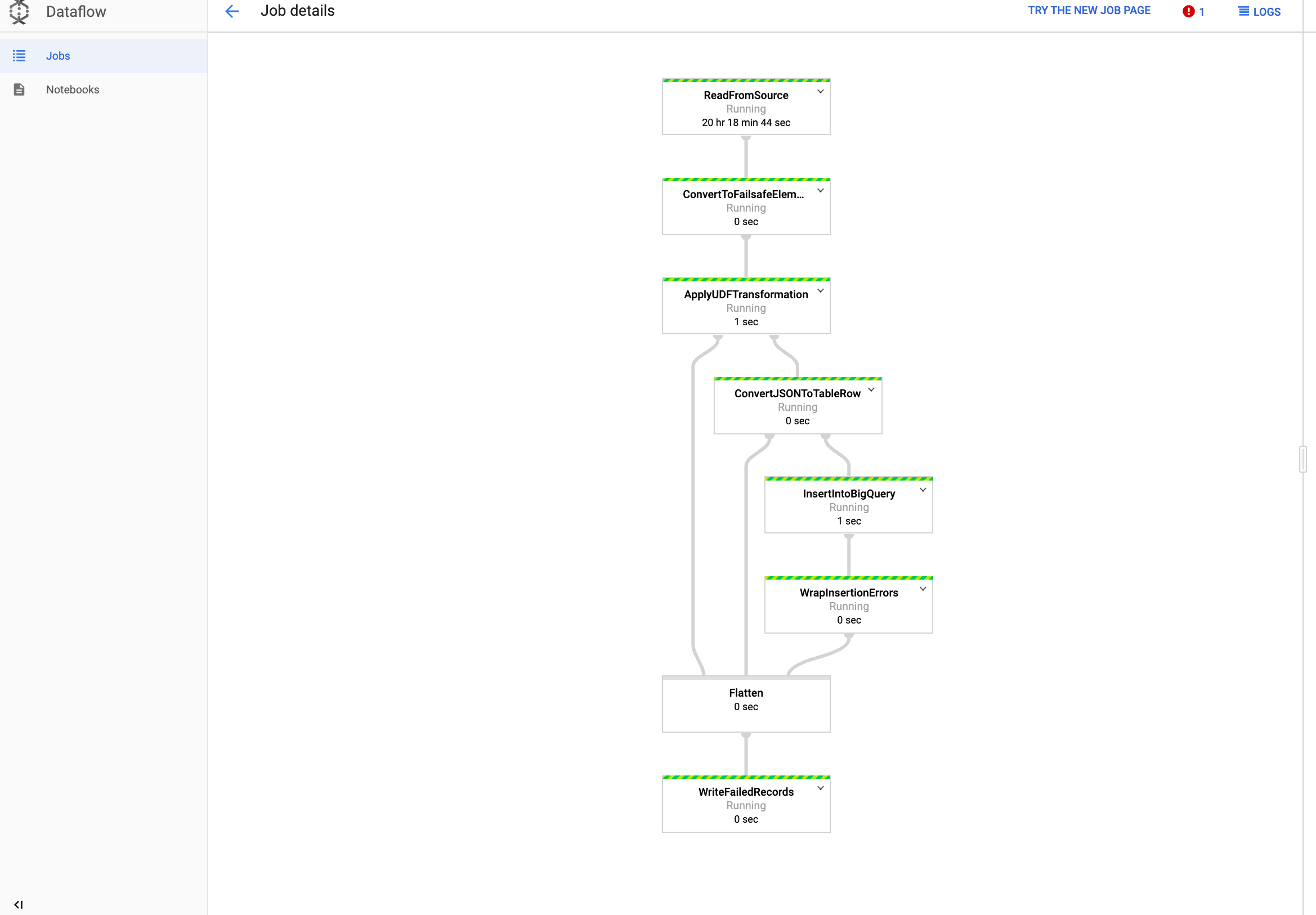
Melihat tugas Anda di Dataflow
Di konsol Google Cloud , buka halaman Dataflow.
Tugas Anda diberi nama
dataflow_operator_transform_csv_to_bqdengan ID unik yang ditambahkan di akhir nama dengan tanda hubung, seperti berikut:
Klik nama untuk melihat detail tugas.
Melihat hasil di BigQuery
Di Google Cloud konsol, buka halaman BigQuery.
Anda dapat mengirimkan kueri menggunakan SQL standar. Gunakan kueri berikut untuk melihat baris yang ditambahkan ke tabel Anda:
SELECT * FROM projectId.average_weather.average_weather