Cloud Composer 3 | Cloud Composer 2 | Cloud Composer 1
本页面介绍了如何使用监控信息中心内的关键指标来监控 Cloud Composer 环境的整体健康状况和性能。
简介
本教程重点介绍关键的 Cloud Composer 监控指标,这些指标可以很好地概括环境级的健康状况和性能。
Cloud Composer 提供了多种用于描述环境总体状态的指标。本教程中的监控指南基于 Cloud Composer 环境的监控信息中心上显示的指标。
在本教程中,您将了解一些关键指标,这些指标可作为环境性能和健康状况问题的主要指示器,同时您还将了解如何根据每个指标制定纠正措施,以保持环境健康。您还将为每个指标设置提醒规则,运行示例 DAG,并使用这些指标和提醒来优化环境的性能。
目标
费用
本教程使用 Google Cloud的以下收费组件:
完成本教程后,您可以删除所创建的资源以避免继续计费。如需了解详情,请参阅清理。
准备工作
本部分介绍了在开始本教程之前需要执行的操作。
创建和配置项目
在本教程中,您需要一个 Google Cloud 项目。 按如下方式配置项目:
在 Google Cloud 控制台中,选择或创建一个项目:
确保您的项目已启用结算功能。 了解如何检查项目是否已启用结算功能。
确保您的 Google Cloud 项目用户拥有以下角色,以便创建必要的资源:
- Environment and Storage Object Administrator
(
roles/composer.environmentAndStorageObjectAdmin) - Compute Admin (
roles/compute.admin) - Monitoring Editor (
roles/monitoring.editor)
- Environment and Storage Object Administrator
(
为您的项目启用 API
Enable the Cloud Composer API.
创建 Cloud Composer 环境
在此过程的最后一步,您将 Cloud Composer v2 API Service Agent Extension (roles/composer.ServiceAgentV2Ext) 角色授予 Composer Service Agent 账号。Cloud Composer 使用此账号在您的 Google Cloud 项目中执行操作。
探索环境级健康状况和性能的关键指标
本教程重点介绍了一些关键指标,这些指标可让您大致了解环境的整体健康状况和性能。
Google Cloud 控制台中的监控信息中心包含各种指标和图表,可用于监控环境中的趋势,以及识别 Airflow 组件和 Cloud Composer 资源的问题。
每个 Cloud Composer 环境都有自己的监控信息中心。
熟悉以下关键指标,并在“监控”信息中心内找到每个指标:
在 Google Cloud 控制台中,前往环境页面。
在环境列表中,点击您的环境名称。环境详情页面会打开。
转到监控标签页。
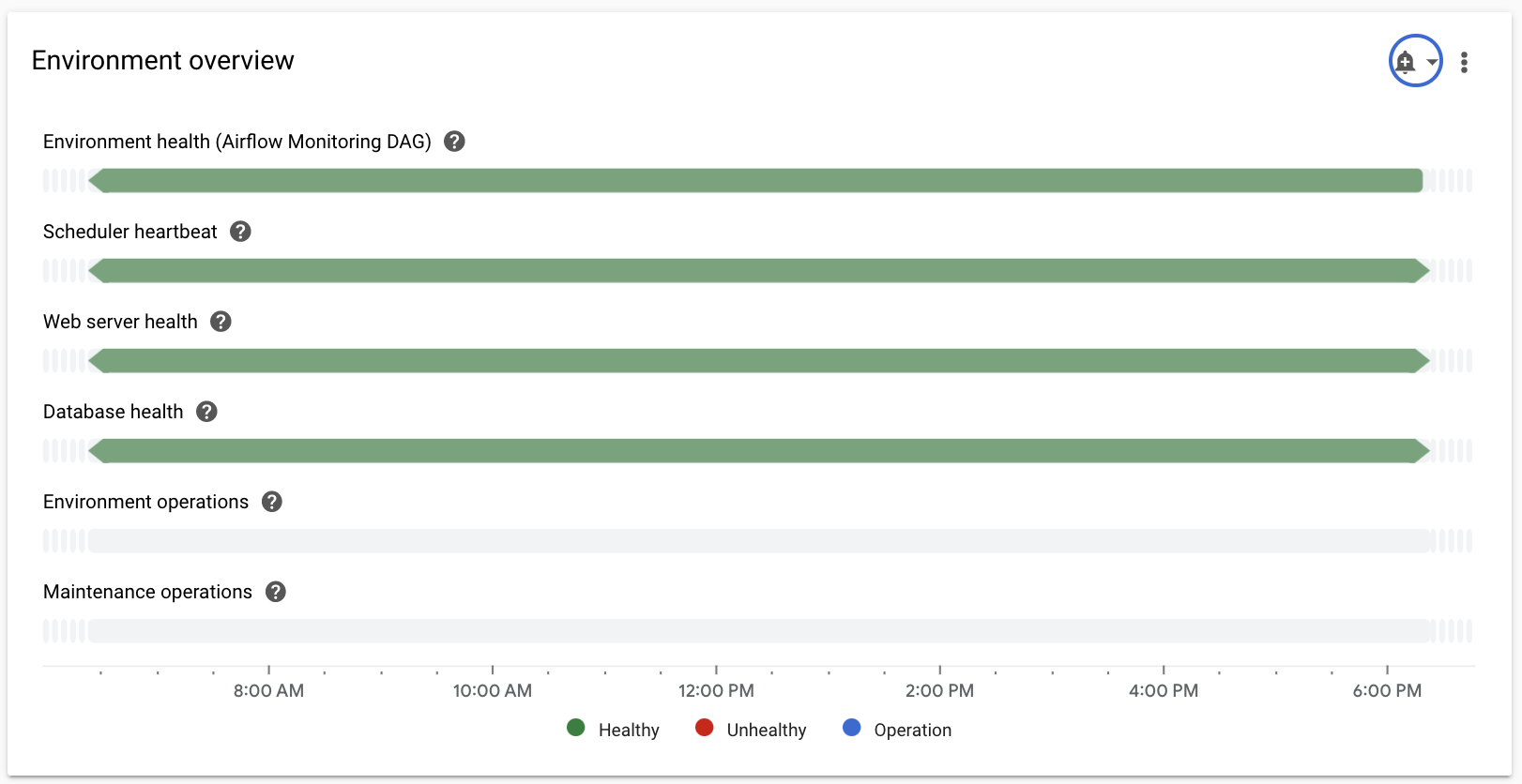
选择概览部分,在信息中心内找到环境概览项,然后观察环境健康状况(Airflow 监控 DAG)指标。
此时间轴显示了 Cloud Composer 环境的运行状况。环境健康状况栏的绿色表示环境健康状况良好,红色表示环境健康状况不佳。
Cloud Composer 会每隔几分钟执行一个名为
airflow_monitoring的活跃性 DAG。如果活性 DAG 运行成功完成,则运行状况为True。如果活性 DAG 运行失败(例如,由于 Pod 逐出、外部进程终止或维护),则健康状况为False。
选择 SQL 数据库部分,在信息中心内找到数据库健康状况项,然后查看数据库健康状况指标。
此时间轴显示了与您环境的 Cloud SQL 实例的连接状态。绿色的“数据库健康状况”栏表示连接正常,而红色表示连接失败。
Airflow 监控 Pod 会定期对数据库执行 ping 操作。如果可以建立连接,则报告运行状态
True,否则报告False。
在数据库运行状况项中,查看数据库 CPU 用量和数据库内存用量指标。
“数据库 CPU 使用量”图表显示了您环境的 Cloud SQL 数据库实例的 CPU 核心使用量与可用的数据库 CPU 总限额。
“数据库内存用量”图表显示了环境中的 Cloud SQL 数据库实例的内存用量与可用的数据库内存总限制。
选择调度器部分,在信息中心内找到调度器心跳项,然后观察调度器心跳指标。
此时间轴显示了 Airflow 调度程序的运行状况。检查是否存在红色区域,以识别 Airflow 调度程序问题。如果您的环境有多个调度器,只要至少有一个调度器在响应,检测信号状态就为正常。
如果上次收到心跳的时间距离当前时间超过 30 秒(默认值),则调度器会被视为不健康。
选择 DAG 统计信息部分,在信息中心内找到已终止的僵尸任务项,然后观察已终止的僵尸任务指标。
此图表显示在较小时间窗口内终止的僵尸任务数量。僵尸任务通常由 Airflow 进程的外部终止(例如当任务的进程被终止时)导致。
Airflow 调度程序会定期终止僵尸任务,这些任务会反映在此图表中。
选择工作器部分,在信息中心内找到工作器容器重启项,然后观察工作器容器重启指标。
- 图表显示了各个工作器容器的总重启次数。容器重启次数过多可能会影响服务的可用性,或影响将该服务用作依赖项的其他下游服务的可用性。
了解关键指标的基准和可能的纠正措施
下表介绍了可能表明存在问题的基准值,并提供了您可能采取的纠正措施来解决这些问题。
环境健康情况(Airflow 监控 DAG)
在 4 小时的时间窗口内,成功率低于 90%
失败可能意味着 Pod 被逐出或工作器终止,因为环境过载或出现故障。环境健康状况时间轴上的红色区域通常与各个环境组件的其他健康状况栏中的红色区域相关。通过查看 Monitoring 信息中心内的其他指标来确定根本原因。
数据库健康状况
在 4 小时的时间窗口内,成功率低于 95%
失败表示与 Airflow 数据库的连接存在问题,这可能是数据库崩溃或停机造成的,因为数据库过载(例如,CPU 或内存使用率过高,或者连接到数据库时延迟较高)。这些症状最常由次优 DAG 引起,例如当 DAG 使用许多全局定义的 Airflow 或环境变量时。通过查看 SQL 数据库资源使用情况指标来确定根本原因。您还可以检查调度程序日志,了解是否存在与数据库连接相关的错误。
数据库 CPU 和内存用量
在 12 小时的时间窗口内,平均 CPU 或内存用量超过 80%
数据库可能过载。分析 DAG 运行与数据库 CPU 或内存用量峰值之间的相关性。
您可以通过以下方式来减少数据库负载:使用更高效的 DAG,其中包含经过优化的正在运行的查询和连接;或者随着时间的推移更均匀地分布负载。
或者,您可以为数据库分配更多 CPU 或内存。 数据库资源由环境的环境大小属性控制,并且环境必须扩容到更大的大小。
调度程序检测信号
在 4 小时的时间窗口内,成功率低于 90%
为调度器分配更多资源,或将调度器的数量从 1 增加到 2(推荐)。
已终止的僵尸任务
每 24 小时内出现多个僵尸任务
僵尸任务最常见的原因是环境的集群中 CPU 或内存资源不足。查看工作器资源使用情况图表,并为工作器分配更多资源,或者增加僵尸任务超时时间,以便调度器在将任务视为僵尸任务之前等待更长时间。
工作器容器重启
创建通知渠道
按照创建通知渠道中所述的说明创建电子邮件通知渠道。
如需详细了解通知渠道,请参阅管理通知渠道。
创建提醒政策
根据本教程前面部分提供的基准创建提醒政策,以持续监控指标的值,并在这些指标违反条件时接收通知。
控制台
您可以点击监控信息中心中每个指标对应的铃铛图标,为相应指标设置提醒:
在 Monitoring 信息中心内找到要监控的每个指标,然后点击相应指标项一角的铃铛图标。创建提醒政策页面随即打开。
在转换数据部分,执行以下操作:
按照指标的提醒政策配置中的说明,配置在每个时序中部分。
点击下一步,然后按照指标的提醒政策配置中的说明配置配置提醒触发器部分。
点击下一步。
配置通知。展开通知渠道菜单,然后选择您在上一步中创建的通知渠道。
点击确定。
在为提醒政策命名部分中,填写提醒政策名称字段。为每个指标使用描述性名称。使用“为提醒政策命名”值,如指标的提醒政策配置中所述。
点击下一步。
查看提醒政策,然后点击创建政策。
环境健康情况(Airflow 监控 DAG)指标 - 提醒政策配置
- 指标名称:Cloud Composer 环境 - 正常
- API:composer.googleapis.com/environment/healthy
过滤条件:
environment_name = [ENVIRONMENT_NAME] location = [CLUSTER_LOCATION]转换数据 > 在每个时序内:
- 滚动窗口:自定义
- 自定义值:4
- 自定义单位:小时
- 滚动窗口函数:比例 (true)
配置提醒触发器:
- 条件类型:阈值
- 提醒触发器:任何时序违反
- 阈值位置:低于阈值
- 阈值:90
- 条件名称:环境健康状况
配置通知并最终确定提醒:
- 将提醒政策命名为:Airflow 环境健康状况
数据库健康状况指标 - 提醒政策配置
- 指标名称:Cloud Composer 环境 - 数据库运行正常
- API:composer.googleapis.com/environment/database_health
过滤条件:
environment_name = [ENVIRONMENT_NAME] location = [CLUSTER_LOCATION]转换数据 > 在每个时序内:
- 滚动窗口:自定义
- 自定义值:4
- 自定义单位:小时
- 滚动窗口函数:比例 (true)
配置提醒触发器:
- 条件类型:阈值
- 提醒触发器:任何时序违反
- 阈值位置:低于阈值
- 阈值:95
- 条件名称:数据库健康状况条件
配置通知并最终确定提醒:
- 将提醒政策命名为:Airflow 数据库健康状况
数据库 CPU 使用量指标 - 提醒政策配置
- 指标名称:Cloud Composer 环境 - 数据库 CPU 利用率
- API:composer.googleapis.com/environment/database/cpu/utilization
过滤条件:
environment_name = [ENVIRONMENT_NAME] location = [CLUSTER_LOCATION]转换数据 > 在每个时序内:
- 滚动窗口:自定义
- 自定义值:12
- 自定义单位:小时
- 滚动窗口函数:平均值
配置提醒触发器:
- 条件类型:阈值
- 提醒触发器:任何时序违反
- 阈值位置:高于阈值
- 阈值:80
- 条件名称:数据库 CPU 使用率条件
配置通知并最终确定提醒:
- 将提醒政策命名为:Airflow 数据库 CPU 用量
数据库内存用量指标 - 提醒政策配置
- 指标名称:Cloud Composer 环境 - 数据库内存利用率
- API:composer.googleapis.com/environment/database/memory/utilization
过滤条件:
environment_name = [ENVIRONMENT_NAME] location = [CLUSTER_LOCATION]转换数据 > 在每个时序内:
- 滚动窗口:自定义
- 自定义值:12
- 自定义单位:小时
- 滚动窗口函数:平均值
配置提醒触发器:
- 条件类型:阈值
- 提醒触发器:任何时序违反
- 阈值位置:高于阈值
- 阈值:80
- 条件名称:数据库内存用量条件
配置通知并最终确定提醒:
- 为提醒政策命名:Airflow 数据库内存用量
调度程序检测信号指标 - 提醒政策配置
- 指标名称:Cloud Composer 环境 - 调度程序心跳
- API:composer.googleapis.com/environment/scheduler_heartbeat_count
过滤条件:
environment_name = [ENVIRONMENT_NAME] location = [CLUSTER_LOCATION]转换数据 > 在每个时序内:
- 滚动窗口:自定义
- 自定义值:4
- 自定义单位:小时
- 滚动窗口函数:count
配置提醒触发器:
- 条件类型:阈值
- 提醒触发器:任何时序违反
- 阈值位置:低于阈值
阈值:216
- 您可以在 Metrics Explorer 查询编辑器中运行可聚合值
_scheduler_heartbeat_count_mean的查询,从而获取此数字。
- 您可以在 Metrics Explorer 查询编辑器中运行可聚合值
条件名称:调度程序检测信号条件
配置通知并最终确定提醒:
- 将提醒政策命名为:Airflow 调度程序检测信号
“已终止的僵尸任务”指标 - 提醒政策配置
- 指标名称:Cloud Composer 环境 - 已终止的僵尸任务
- API:composer.googleapis.com/environment/zombie_task_killed_count
过滤条件:
environment_name = [ENVIRONMENT_NAME] location = [CLUSTER_LOCATION]转换数据 > 在每个时序内:
- 滚动窗口:1 天
- 滚动窗口函数:sum
配置提醒触发器:
- 条件类型:阈值
- 提醒触发器:任何时序违反
- 阈值位置:高于阈值
- 阈值:1
- 条件名称:僵尸任务条件
配置通知并最终确定提醒:
- 为提醒政策命名:Airflow 僵尸任务
工作器容器重启指标 - 提醒政策配置
- 指标名称:Kubernetes 容器 - 重启次数
- API:kubernetes.io/container/restart_count
过滤条件:
environment_name = [ENVIRONMENT_NAME] location = [CLUSTER_LOCATION] pod_name =~ airflow-worker-.*|airflow-k8s-worker-.* container_name =~ airflow-worker|base cluster_name = [CLUSTER_NAME]CLUSTER_NAME是您环境的集群名称,可在 Google Cloud 控制台中的“环境配置”>“资源”>“GKE 集群”下找到。转换数据 > 在每个时序内:
- 滚动窗口:1 天
- 滚动窗口函数:rate
配置提醒触发器:
- 条件类型:阈值
- 提醒触发器:任何时序违反
- 阈值位置:高于阈值
- 阈值:1
- 条件名称:工作器容器重启条件
配置通知并最终确定提醒:
- 将提醒政策命名为:Airflow Worker Restarts
Terraform
运行一个 Terraform 脚本,该脚本会创建一个电子邮件通知渠道,并根据本教程中提供的关键指标各自的基准上传相应的提醒政策:
- 将示例 Terraform 文件保存到本地计算机。
替换以下内容:
PROJECT_ID:您的项目的项目 ID。例如example-project。EMAIL_ADDRESS:在触发提醒时必须通知的电子邮件地址。ENVIRONMENT_NAME:您的 Cloud Composer 环境的名称。 例如example-composer-environment。CLUSTER_NAME:您的环境集群名称,可在 Google Cloud 控制台中的“环境配置”>“资源”>“GKE 集群”下找到。
resource "google_monitoring_notification_channel" "basic" {
project = "PROJECT_ID"
display_name = "Test Notification Channel"
type = "email"
labels = {
email_address = "EMAIL_ADDRESS"
}
# force_delete = false
}
resource "google_monitoring_alert_policy" "environment_health_metric" {
project = "PROJECT_ID"
display_name = "Airflow Environment Health"
combiner = "OR"
notification_channels = [google_monitoring_notification_channel.basic.name] // To manually add a notification channel add it with the syntax "projects/[PROJECT_ID]/notificationChannels/[CHANNEL_ID]"
conditions {
display_name = "Environment health condition"
condition_threshold {
filter = "resource.type = \"cloud_composer_environment\" AND metric.type=\"composer.googleapis.com/environment/healthy\" AND resource.label.environment_name=\"ENVIRONMENT_NAME\""
duration = "60s"
comparison = "COMPARISON_LT"
threshold_value = 0.9
aggregations {
alignment_period = "14400s"
per_series_aligner = "ALIGN_FRACTION_TRUE"
}
}
}
}
resource "google_monitoring_alert_policy" "database_health_metric" {
project = "PROJECT_ID"
display_name = "Airflow Database Health"
combiner = "OR"
notification_channels = [google_monitoring_notification_channel.basic.name] // To manually add a notification channel add it with the syntax "projects/[PROJECT_ID]/notificationChannels/[CHANNEL_ID]"
conditions {
display_name = "Database health condition"
condition_threshold {
filter = "resource.type = \"cloud_composer_environment\" AND metric.type=\"composer.googleapis.com/environment/database_health\" AND resource.label.environment_name=\"ENVIRONMENT_NAME\""
duration = "60s"
comparison = "COMPARISON_LT"
threshold_value = 0.95
aggregations {
alignment_period = "14400s"
per_series_aligner = "ALIGN_FRACTION_TRUE"
}
}
}
}
resource "google_monitoring_alert_policy" "alert_database_cpu_usage" {
project = "PROJECT_ID"
display_name = "Airflow Database CPU Usage"
combiner = "OR"
notification_channels = [google_monitoring_notification_channel.basic.name] // To manually add a notification channel add it with the syntax "projects/[PROJECT_ID]/notificationChannels/[CHANNEL_ID]"
conditions {
display_name = "Database CPU usage condition"
condition_threshold {
filter = "resource.type = \"cloud_composer_environment\" AND metric.type=\"composer.googleapis.com/environment/database/cpu/utilization\" AND resource.label.environment_name=\"ENVIRONMENT_NAME\""
duration = "60s"
comparison = "COMPARISON_GT"
threshold_value = 80
aggregations {
alignment_period = "43200s"
per_series_aligner = "ALIGN_MEAN"
}
}
}
}
resource "google_monitoring_alert_policy" "alert_database_memory_usage" {
project = "PROJECT_ID"
display_name = "Airflow Database Memory Usage"
combiner = "OR"
notification_channels = [google_monitoring_notification_channel.basic.name] // To manually add a notification channel add it with the syntax "projects/[PROJECT_ID]/notificationChannels/[CHANNEL_ID]"
conditions {
display_name = "Database memory usage condition"
condition_threshold {
filter = "resource.type = \"cloud_composer_environment\" AND metric.type=\"composer.googleapis.com/environment/database/memory/utilization\" AND resource.label.environment_name=\"ENVIRONMENT_NAME\""
duration = "60s"
comparison = "COMPARISON_GT"
threshold_value = 80
aggregations {
alignment_period = "43200s"
per_series_aligner = "ALIGN_MEAN"
}
}
}
}
resource "google_monitoring_alert_policy" "alert_scheduler_heartbeat" {
project = "PROJECT_ID"
display_name = "Airflow Scheduler Heartbeat"
combiner = "OR"
notification_channels = [google_monitoring_notification_channel.basic.name] // To manually add a notification channel add it with the syntax "projects/[PROJECT_ID]/notificationChannels/[CHANNEL_ID]"
conditions {
display_name = "Scheduler heartbeat condition"
condition_threshold {
filter = "resource.type = \"cloud_composer_environment\" AND metric.type=\"composer.googleapis.com/environment/scheduler_heartbeat_count\" AND resource.label.environment_name=\"ENVIRONMENT_NAME\""
duration = "60s"
comparison = "COMPARISON_LT"
threshold_value = 216 // Threshold is 90% of the average for composer.googleapis.com/environment/scheduler_heartbeat_count metric in an idle environment
aggregations {
alignment_period = "14400s"
per_series_aligner = "ALIGN_COUNT"
}
}
}
}
resource "google_monitoring_alert_policy" "alert_zombie_task" {
project = "PROJECT_ID"
display_name = "Airflow Zombie Tasks"
combiner = "OR"
notification_channels = [google_monitoring_notification_channel.basic.name] // To manually add a notification channel add it with the syntax "projects/[PROJECT_ID]/notificationChannels/[CHANNEL_ID]"
conditions {
display_name = "Zombie tasks condition"
condition_threshold {
filter = "resource.type = \"cloud_composer_environment\" AND metric.type=\"composer.googleapis.com/environment/zombie_task_killed_count\" AND resource.label.environment_name=\"ENVIRONMENT_NAME\""
duration = "60s"
comparison = "COMPARISON_GT"
threshold_value = 1
aggregations {
alignment_period = "86400s"
per_series_aligner = "ALIGN_SUM"
}
}
}
}
resource "google_monitoring_alert_policy" "alert_worker_restarts" {
project = "PROJECT_ID"
display_name = "Airflow Worker Restarts"
combiner = "OR"
notification_channels = [google_monitoring_notification_channel.basic.name] // To manually add a notification channel add it with the syntax "projects/[PROJECT_ID]/notificationChannels/[CHANNEL_ID]"
conditions {
display_name = "Worker container restarts condition"
condition_threshold {
filter = "resource.type = \"k8s_container\" AND (resource.labels.cluster_name = \"CLUSTER_NAME\" AND resource.labels.container_name = monitoring.regex.full_match(\"airflow-worker|base\") AND resource.labels.pod_name = monitoring.regex.full_match(\"airflow-worker-.*|airflow-k8s-worker-.*\")) AND metric.type = \"kubernetes.io/container/restart_count\""
duration = "60s"
comparison = "COMPARISON_GT"
threshold_value = 1
aggregations {
alignment_period = "86400s"
per_series_aligner = "ALIGN_RATE"
}
}
}
}
测试提醒政策
本部分介绍了如何测试创建的提醒政策并解读结果。
上传示例 DAG
本教程中提供的示例 DAG memory_consumption_dag.py 模拟了密集的工作器内存利用率。该 DAG 包含 4 项任务,每项任务都会将数据写入示例字符串,消耗 380 MB 的内存。示例 DAG 安排为每 2 分钟运行一次,在您将其上传到 Composer 环境后会自动开始运行。
将以下示例 DAG 上传到您在之前步骤中创建的环境:
from datetime import datetime
import sys
import time
from airflow import DAG
from airflow.operators.python import PythonOperator
def ram_function():
data = ""
start = time.time()
for i in range(38):
data += "a" * 10 * 1000**2
time.sleep(0.2)
print(f"{i}, {round(time.time() - start, 4)}, {sys.getsizeof(data) / (1000 ** 3)}")
print(f"Size={sys.getsizeof(data) / (1000 ** 3)}GB")
time.sleep(30 - (time.time() - start))
print(f"Complete in {round(time.time() - start, 2)} seconds!")
with DAG(
dag_id="memory_consumption_dag",
start_date=datetime(2023, 1, 1, 1, 1, 1),
schedule="1/2 * * * *",
catchup=False,
) as dag:
for i in range(4):
PythonOperator(
task_id=f"task_{i+1}",
python_callable=ram_function,
retries=0,
dag=dag,
)
解读 Monitoring 中的提醒和指标
等待示例 DAG 开始运行约 10 分钟后,评估测试结果:
检查您的电子邮件收件箱,验证您是否收到了来自Google Cloud 的通知,该通知的主题行以
[ALERT]开头。此消息的内容包含提醒政策突发事件的详细信息。点击电子邮件通知中的查看突发事件按钮。系统会将您重定向到 Metrics Explorer。查看提醒事件的详细信息:
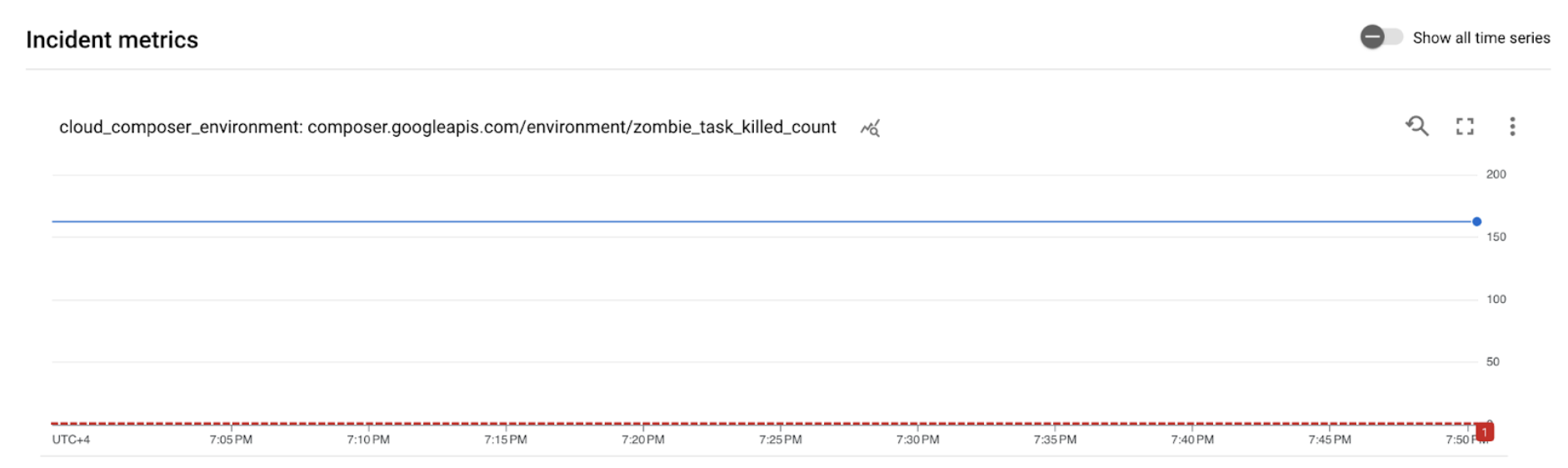
图 2. 提醒突发事件的详细信息(点击可放大) 突发事件指标图表表明,您创建的指标超过了 1 的阈值,这意味着 Airflow 检测到并终止了 1 个以上的僵尸任务。
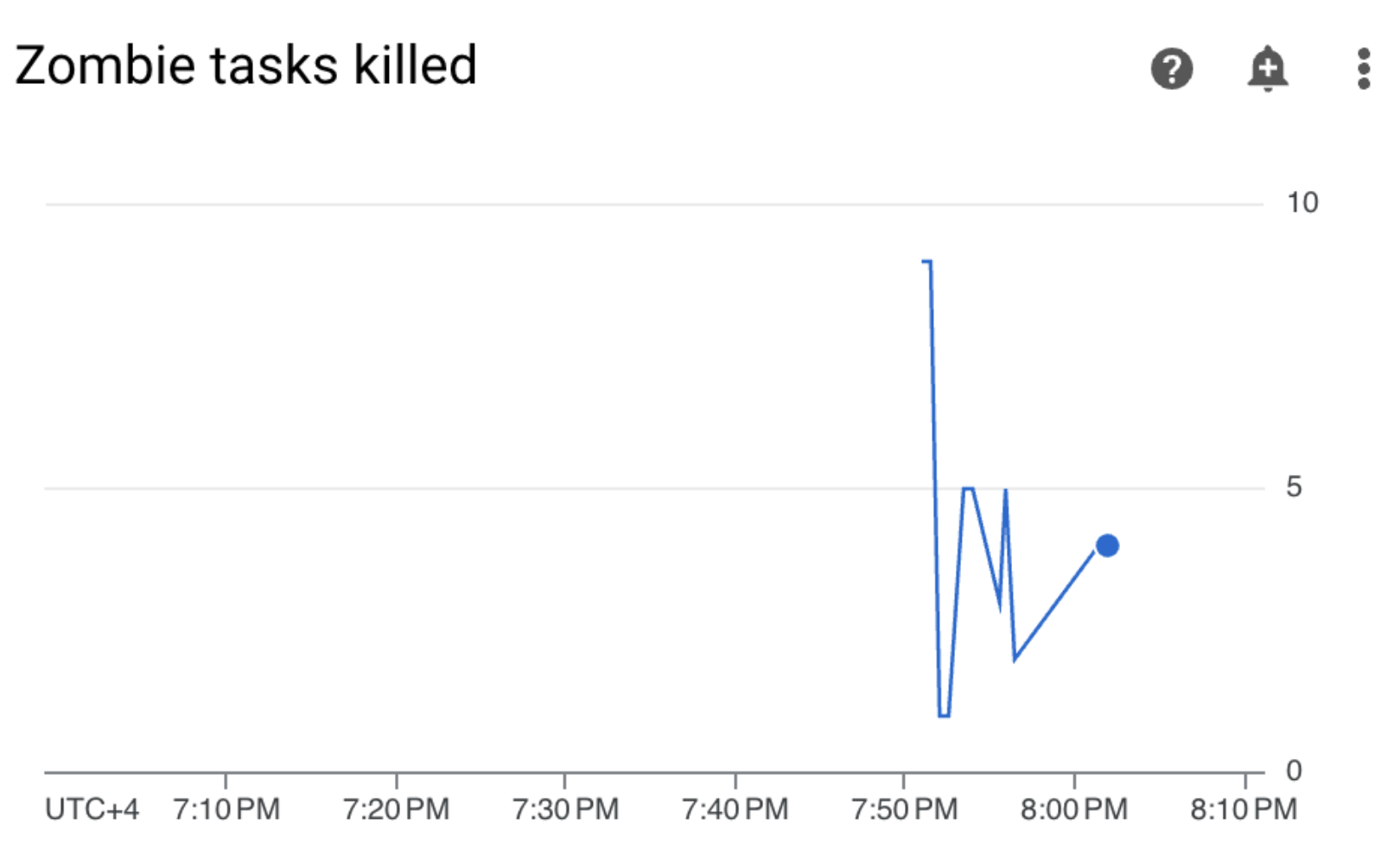
在 Cloud Composer 环境中,前往 Monitoring(监控)标签页,打开 DAG statistics(DAG 统计信息)部分,然后找到 Zombie tasks killed(已终止的僵尸任务)图表:

图 3. 僵尸任务图表(点击可放大) 该图表表明,在运行示例 DAG 的前 10 分钟内,Airflow 终止了大约 20 个僵尸任务。
根据基准和纠正措施,僵尸任务的最常见原因是工作器内存或 CPU 不足。通过分析工作器资源利用率,确定僵尸任务的根本原因。
在 Monitoring 信息中心内打开“工作器”部分,然后查看工作器的 CPU 和内存用量指标:
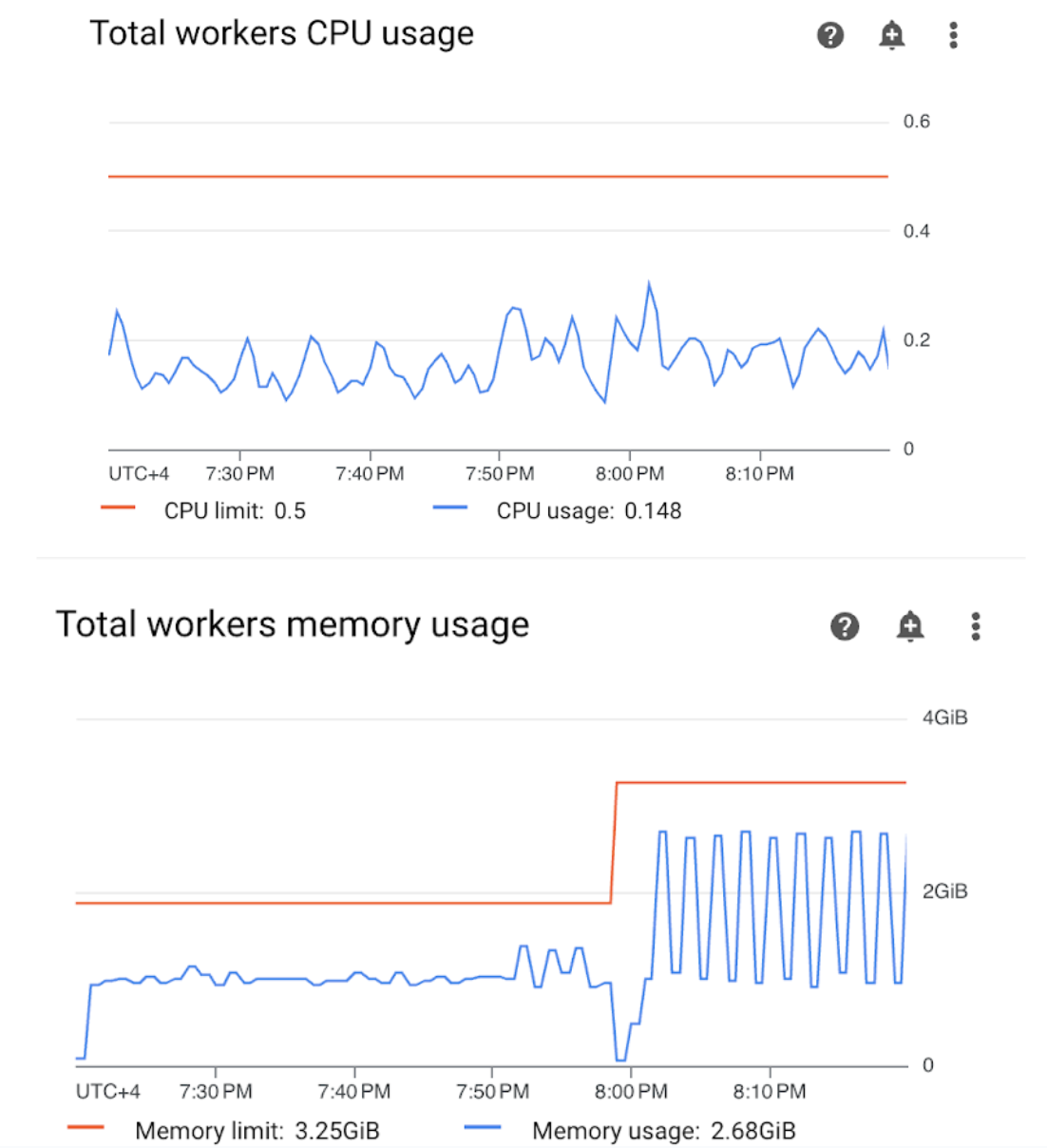
图 4. 工作器 CPU 和内存使用情况指标(点击可放大) “工作器 CPU 总用量”图表显示,工作器 CPU 用量始终低于可用总限额的 50%,因此可用 CPU 充足。“工作器内存总用量”图表显示,运行示例 DAG 导致内存用量达到可分配内存限制,该限制相当于图表上显示的总内存限制的近 75%(GKE 会预留前 4 GiB 内存的 25%,并在每个节点上额外预留 100 MiB 内存,用于处理 pod 逐出)。
由此可以得出结论,工作器缺少成功运行示例 DAG 所需的内存资源。
优化环境并评估其性能
根据对工作器资源利用率的分析,您需要为工作器分配更多内存,才能使 DAG 中的所有任务成功完成。
在 Composer 环境中,打开 DAG 标签页,点击示例 DAG 的名称 (
memory_consumption_dag),然后点击暂停 DAG。分配额外的工作器内存:
在“环境配置”标签页中,找到资源 > 工作负载配置,然后点击修改。
在工作器项中,增加内存上限。在本教程中,请使用 3.25 GB。
保存更改,并等待几分钟,让工作器重新启动。
打开“DAG”标签页,点击示例 DAG 的名称 (
memory_consumption_dag),然后点击取消暂停 DAG。
前往监控,并验证在更新工作器资源限制后是否未出现新的僵尸任务:
摘要
在本教程中,您了解了关键的环境级健康状况和性能指标,学习了如何为每个指标设置提醒政策,以及如何将每个指标解读为纠正措施。然后,您运行了一个示例 DAG,在提醒和监控图表的帮助下确定了环境健康状况问题的根本原因,并通过为工作器分配更多内存来优化环境。不过,建议您先优化 DAG,以减少工作器资源消耗,因为资源无法增加到超出一定阈值。
清理
为避免因本教程中使用的资源导致您的 Google Cloud 账号产生费用,请删除包含这些资源的项目,或者保留该项目但删除各个资源。
删除项目
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
删除各个资源
如果您打算探索多个教程和快速入门,重复使用项目可以帮助您避免超出项目配额上限。
控制台
- 删除 Cloud Composer 环境。在此过程中,您还可以删除环境的存储桶。
- 删除您在 Cloud Monitoring 中创建的每项提醒政策。
Terraform
- 确保您的 Terraform 脚本不包含项目仍需要的资源条目。例如,您可能希望保持某些 API 处于启用状态,并仍分配 IAM 权限(如果您已在 Terraform 脚本中添加此类定义)。
- 运行
terraform destroy。 - 手动删除环境的存储桶。Cloud Composer 不会自动删除它。您可以通过 Google Cloud 控制台或 Google Cloud CLI 执行此操作。