Cloud Composer 3 | Cloud Composer 2 | Cloud Composer 1
En este tutorial se explica cómo depurar un DAG de Airflow que ha fallado en Cloud Composer y cómo diagnosticar problemas relacionados con los recursos de los trabajadores, como la falta de memoria o espacio de almacenamiento, con la ayuda de los registros y la monitorización del entorno.
Introducción
Este tutorial se centra en los problemas relacionados con los recursos para mostrar cómo depurar un DAG.
La falta de recursos de trabajador asignados provoca errores en los DAG. Si una tarea de Airflow se queda sin memoria o almacenamiento, es posible que veas una excepción de Airflow, como la siguiente:
WARNING airflow.exceptions.AirflowException: Task received SIGTERM signal
INFO - Marking task as FAILED.
o
Task exited with return code Negsignal.SIGKILL
En estos casos, la recomendación general es aumentar los recursos del trabajador de Airflow o reducir el número de tareas por trabajador. Sin embargo, como las excepciones de Airflow pueden ser genéricas, puede ser difícil identificar el recurso concreto que está causando el problema.
En este tutorial se explica cómo diagnosticar el motivo de un fallo de un DAG e identificar el tipo de recurso que causa problemas depurando dos DAG de ejemplo que fallan debido a la falta de memoria y almacenamiento de los trabajadores.
Objetivos
Ejecuta DAGs de ejemplo que fallen por los siguientes motivos:
- Falta de memoria de los trabajadores
- Falta de almacenamiento de los trabajadores
Diagnosticar los motivos del error
Aumentar los recursos de los trabajadores asignados
Probar los DAGs con nuevos límites de recursos
Costes
En este tutorial se usan los siguientes componentes facturables de Google Cloud:
- Cloud Composer (consulta los costes adicionales).
- Cloud Monitoring
Cuando termines este tutorial, puedes evitar que se te siga facturando eliminando los recursos que has creado. Para obtener más información, consulta Limpiar.
Antes de empezar
En esta sección se describen las acciones que debes llevar a cabo antes de empezar el tutorial.
Crear y configurar un proyecto
Para este tutorial, necesitas un Google Cloud proyecto. Configura el proyecto de la siguiente manera:
En la Google Cloud consola, selecciona o crea un proyecto:
Comprueba que la facturación esté habilitada en tu proyecto. Consulta cómo comprobar si la facturación está habilitada en un proyecto.
Asegúrate de que el usuario de tu proyecto Google Cloud tenga los siguientes roles para crear los recursos necesarios:
- Administrador de objetos de entorno y almacenamiento
(
roles/composer.environmentAndStorageObjectAdmin) - Administrador de Compute (
roles/compute.admin) - Editor de monitorización (
roles/monitoring.editor)
- Administrador de objetos de entorno y almacenamiento
(
Habilitar APIs en tu proyecto
Enable the Cloud Composer API.
Crear un entorno de Cloud Composer
Crea un entorno de Cloud Composer 2.
.Como parte de la creación del entorno,
asignas el rol Extensión del agente de servicio de la API de Cloud Composer v2
(roles/composer.ServiceAgentV2Ext) a la cuenta del agente de servicio de Composer. Cloud Composer usa esta cuenta para realizar operaciones en tu proyecto Google Cloud .
Consultar los límites de recursos para trabajadores
Comprueba los límites de recursos de los trabajadores de Airflow en tu entorno:
En la Google Cloud consola, ve a la página Entornos.
En la lista de entornos, haz clic en el nombre del entorno. Se abrirá la página Detalles del entorno.
Ve a la pestaña Configuración del entorno.
Ve a Recursos > Configuración de cargas de trabajo > Trabajador.
Comprueba que los valores sean 0,5 vCPUs, 1,875 GB de memoria y 1 GB de almacenamiento. Estos son los límites de recursos de los workers de Airflow con los que trabajarás en los siguientes pasos de este tutorial.
Ejemplo: diagnosticar problemas de falta de memoria
Sube el siguiente DAG de ejemplo al entorno que has creado en los pasos anteriores. En este tutorial, el DAG se llama create_list_with_many_strings.
Este DAG contiene una tarea que ejecuta los siguientes pasos:
- Crea una lista vacía
s. - Ejecuta un ciclo para añadir la cadena
Morea la lista. - Imprime la cantidad de memoria que consume la lista y espera 1 segundo en cada iteración de 1 minuto.
import time
import airflow
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
import sys
from datetime import timedelta
default_args = {
'start_date': airflow.utils.dates.days_ago(0),
'retries': 0,
'retry_delay': timedelta(minutes=10)
}
dag = DAG(
'create_list_with_many_strings',
default_args=default_args,
schedule_interval=None)
def consume():
s = []
for i in range(120):
for j in range(1000000):
s.append("More")
print(f"i={i}; size={sys.getsizeof(s) / (1000**3)}GB")
time.sleep(1)
t1 = PythonOperator(
task_id='task0',
python_callable=consume,
dag=dag,
depends_on_past=False,
retries=0
)
Activar el DAG de ejemplo
Activa el DAG de ejemplo create_list_with_many_strings:
En la Google Cloud consola, ve a la página Entornos.
En la columna Servidor web de Airflow, siga el enlace Airflow de su entorno.
En la interfaz web de Airflow, en la página DAGs, en la columna Links de tu DAG, haz clic en el botón Trigger Dag.
Haz clic en Activador.
En la página DAGs (DAGs), haz clic en la tarea que has activado y revisa los registros de salida para asegurarte de que tu DAG se ha empezado a ejecutar.
Mientras se ejecuta la tarea, los registros de salida mostrarán el tamaño de la memoria en GB que está usando el DAG.
Al cabo de varios minutos, la tarea fallará porque supera el límite de memoria de los trabajadores de Airflow, que es de 1,875 GB.
Diagnosticar el DAG fallido
Si estabas ejecutando varias tareas en el momento del fallo, prueba a ejecutar solo una tarea y diagnostica la presión de los recursos durante ese tiempo para identificar qué tareas causan presión de los recursos y qué recursos debes aumentar.
Revisar los registros de tareas de Airflow
Observa que la tarea del DAG create_list_with_many_strings tiene el estado Failed.
Revisa los registros de la tarea. Verá la siguiente entrada de registro:
```none
{local_task_job.py:102} INFO - Task exited with return code
Negsignal.SIGKILL
```
`Netsignal.SIGKILL` might be an indication of your task using more memory
than the Airflow worker is allocated. The system sends
the `Negsignal.SIGKILL` signal to avoid further memory consumption.
Revisar cargas de trabajo
Revisa las cargas de trabajo para comprobar que la carga de tu tarea no provoque que el nodo en el que se ejecuta el pod supere el límite de consumo de memoria:
En la Google Cloud consola, ve a la página Entornos.
En la lista de entornos, haz clic en el nombre del entorno. Se abrirá la página Detalles del entorno.
Ve a la pestaña Configuración del entorno.
En Recursos > Clúster de GKE > Cargas de trabajo, haz clic en Ver cargas de trabajo del clúster.
Comprueba si algunos de los pods de carga de trabajo tienen estados similares a los siguientes:
Error with exit code 137 and 1 more issue. ContainerStatusUnknown with exit code 137 and 1 more issueExit code 137significa que un contenedor o un pod está intentando usar más memoria de la permitida. El proceso se termina para evitar el uso de memoria.
Revisar la monitorización del estado del entorno y del consumo de recursos
Revisa la monitorización del estado del entorno y del consumo de recursos:
En la Google Cloud consola, ve a la página Entornos.
En la lista de entornos, haz clic en el nombre del entorno. Se abrirá la página Detalles del entorno.
Vaya a la pestaña Monitorización y seleccione Resumen.
En el panel Resumen del entorno, busca el gráfico Estado del entorno (DAG de monitorización de Airflow). Contiene un área roja que corresponde al momento en el que los registros empezaron a imprimir errores.
Selecciona Trabajadores y busca el gráfico Uso total de memoria de los trabajadores. Observa que la línea Uso de memoria tiene un pico en el momento en que se estaba ejecutando la tarea.
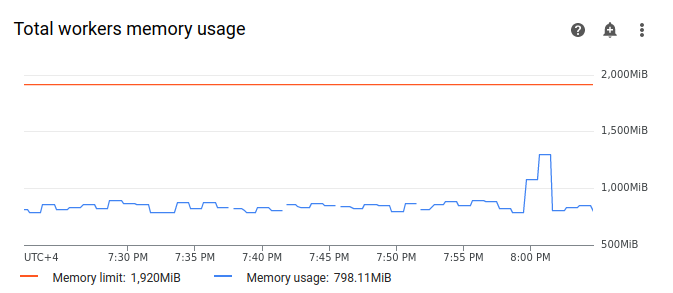
Aunque la línea de uso de memoria del gráfico no alcance el límite, al diagnosticar los motivos del fallo, debe tener en cuenta el uso de memoria de cada trabajador. Cada trabajador usa una parte de su memoria para ejecutar otros contenedores que realizan las acciones necesarias para el funcionamiento del trabajador, como sincronizar sus archivos DAG con el segmento del entorno. La cantidad real de memoria disponible para que un trabajador ejecute tareas de Airflow es inferior a su límite de memoria. Si un trabajador alcanza el límite de la memoria real disponible, la tarea ejecutada puede fallar debido a que no hay suficiente memoria de trabajador. En estos casos, puedes observar fallos en las tareas aunque la línea del gráfico de uso total de memoria de los trabajadores no alcance el límite de memoria.
Aumentar el límite de memoria de los trabajadores
Asigna memoria de trabajador adicional para que el DAG de ejemplo se complete correctamente:
En la Google Cloud consola, ve a la página Entornos.
En la lista de entornos, haz clic en el nombre del entorno. Se abrirá la página Detalles del entorno.
Ve a la pestaña Configuración del entorno.
Busca la configuración de Recursos > Cargas de trabajo y haz clic en Editar.
En la sección Worker (Trabajador), en el campo Memory (Memoria), especifica el nuevo límite de memoria para los trabajadores de Airflow. En este tutorial, usa 3 GB.
Guarda los cambios y espera varios minutos a que se reinicien los trabajadores de Airflow.
Prueba tu DAG con el nuevo límite de memoria
Vuelve a activar el DAG create_list_with_many_strings y espera a que termine de ejecutarse.
En los registros de salida de la ejecución del DAG, verás
Marking task as SUCCESS. El estado de la tarea será Correcto.Consulta la sección Resumen del entorno de la pestaña Monitorización y comprueba que no haya ninguna zona roja.
Haz clic en la sección Trabajadores y busca el gráfico Uso total de memoria de los trabajadores. Verás que la línea Límite de memoria refleja el cambio en el límite de memoria y que la línea Uso de memoria está muy por debajo del límite de memoria asignable real.
Ejemplo: diagnosticar problemas de falta de almacenamiento
En este paso, subirá dos DAGs que crearán archivos de gran tamaño. El primer DAG crea un archivo de gran tamaño. El segundo DAG crea un archivo grande e imita una operación de larga duración.
El tamaño del archivo de ambos DAGs supera el límite de almacenamiento predeterminado de 1 GB del trabajador de Airflow, pero el segundo DAG tiene una tarea de espera adicional para ampliar su duración de forma artificial.
En los próximos pasos, investigarás las diferencias en el comportamiento de ambos DAGs.
Subir un DAG que cree un archivo de gran tamaño
Sube el siguiente DAG de ejemplo al entorno que has creado en los pasos anteriores. En este tutorial, el DAG se llama create_large_txt_file_print_logs.
Este DAG contiene una tarea que ejecuta los siguientes pasos:
- Escribe un archivo
localfile.txtde 1,5 GB en el almacenamiento de trabajadores de Airflow. - Imprime el tamaño del archivo creado mediante el módulo
osde Python. - Imprime la duración de la ejecución del DAG cada minuto.
import airflow
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
import os
from datetime import timedelta
import time
default_args = {
'start_date': airflow.utils.dates.days_ago(0),
'retries': 0,
'retry_delay': timedelta(minutes=10)
}
dag = DAG(
'create_large_txt_file_print_logs',
default_args=default_args,
schedule_interval=None)
def consume():
size = 1000**2 # bytes in 1 MB
amount = 100
def create_file():
print(f"Start creating a huge file")
with open("localfile.txt", "ab") as f:
for j in range(15):
f.write(os.urandom(amount) * size)
print("localfile.txt size:", os.stat("localfile.txt").st_size / (1000**3), "GB")
create_file()
print("Success!")
t1 = PythonOperator(
task_id='create_huge_file',
python_callable=consume,
dag=dag,
depends_on_past=False,
retries=0)
Subir un DAG que cree un archivo de gran tamaño en una operación de larga duración
Para imitar un DAG de larga duración e investigar el impacto de la duración de la tarea en el estado final, sube el segundo DAG de ejemplo a tu entorno. En este tutorial, el DAG se llama long_running_create_large_txt_file_print_logs.
Este DAG contiene una tarea que ejecuta los siguientes pasos:
- Escribe un archivo
localfile.txtde 1,5 GB en el almacenamiento de trabajadores de Airflow. - Imprime el tamaño del archivo creado mediante el módulo
osde Python. - Espera 1 hora y 15 minutos para imitar el tiempo necesario para las operaciones con el archivo, por ejemplo, la lectura del archivo.
- Imprime la duración de la ejecución del DAG cada minuto.
import airflow
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
import os
from datetime import timedelta
import time
default_args = {
'start_date': airflow.utils.dates.days_ago(0),
'retries': 0,
'retry_delay': timedelta(minutes=10)
}
dag = DAG(
'long_running_create_large_txt_file_print_logs',
default_args=default_args,
schedule_interval=None)
def consume():
size = 1000**2 # bytes in 1 MB
amount = 100
def create_file():
print(f"Start creating a huge file")
with open("localfile.txt", "ab") as f:
for j in range(15):
f.write(os.urandom(amount) * size)
print("localfile.txt size:", os.stat("localfile.txt").st_size / (1000**3), "GB")
create_file()
for k in range(75):
time.sleep(60)
print(f"{k+1} minute")
print("Success!")
t1 = PythonOperator(
task_id='create_huge_file',
python_callable=consume,
dag=dag,
depends_on_past=False,
retries=0)
Activar DAGs de ejemplo
Activa el primer DAG, create_large_txt_file_print_logs:
En la Google Cloud consola, ve a la página Entornos.
En la columna Servidor web de Airflow, siga el enlace Airflow de su entorno.
En la interfaz web de Airflow, en la página DAGs, en la columna Links de tu DAG, haz clic en el botón Trigger Dag.
Haz clic en Activador.
En la página DAGs (DAGs), haz clic en la tarea que has activado y revisa los registros de salida para asegurarte de que tu DAG se ha empezado a ejecutar.
Espera a que se complete la tarea que has creado con el DAG
create_large_txt_file_print_logs. Este proceso puede tardar varios minutos.En la página DAGs (DAGs), haz clic en la ejecución del DAG. Verás que tu tarea tiene el estado
Success, aunque se haya superado el límite de almacenamiento.
Revisa los registros de Airflow de la tarea:
En la Google Cloud consola, ve a la página Entornos.
En la lista de entornos, haz clic en el nombre del entorno. Se abrirá la página Detalles del entorno.
Ve a la pestaña Registros y, a continuación, a Todos los registros > Registros de Airflow > Workers > Ver en Explorador de registros.
Filtra los registros por tipo: muestra solo los mensajes de Error.
En los registros, verá mensajes similares a los siguientes:
Worker: warm shutdown (Main Process)
o
A worker pod was evicted at 2023-12-01T12:30:05Z with message: Pod ephemeral
local storage usage exceeds the total limit of containers 1023Mi.
Estos registros indican que el pod ha iniciado el proceso de cierre gradual porque el almacenamiento utilizado ha superado el límite y se ha expulsado en 1 hora. Sin embargo, la ejecución del DAG no ha fallado porque se ha completado dentro del periodo de gracia de finalización de Kubernetes, que se explica con más detalle en este tutorial.
Para ilustrar el concepto del periodo de gracia de finalización, consulta el resultado del segundo DAG de ejemplo, long_running_create_large_txt_file_print_logs.
Activa el segundo DAG, long_running_create_large_txt_file_print_logs:
En la Google Cloud consola, ve a la página Entornos.
En la columna Servidor web de Airflow, siga el enlace Airflow de su entorno.
En la interfaz web de Airflow, en la página DAGs, en la columna Links de tu DAG, haz clic en el botón Trigger Dag.
Haz clic en Activador.
En la página DAGs (DAGs), haz clic en la tarea que has activado y revisa los registros de salida para asegurarte de que tu DAG se ha empezado a ejecutar.
Espera a que falle la ejecución del DAG
long_running_create_large_txt_file_print_logs. Este proceso tardará aproximadamente una hora.
Revisa los resultados de la ejecución del DAG:
En la página DAGs (DAGs), haz clic en la ejecución de
long_running_create_large_txt_file_print_logsDAG. Verás que la tarea tiene el estadoFailedy que la duración de la ejecución ha sido de 1 hora y 5 minutos, que es inferior al periodo de espera de la tarea, que es de 1 hora y 15 minutos.Revisa los registros de la tarea. Una vez que el DAG haya creado el archivo
localfile.txten el contenedor del trabajador de Airflow, el registro indicará que el DAG ha empezado a esperar y la duración de la ejecución se mostrará en los registros de tareas cada minuto. En este ejemplo, el DAG imprime el registrolocalfile.txt size:y el tamaño del archivolocalfile.txtserá de 1,5 GB.
Cuando el archivo escrito en el contenedor del trabajador de Airflow supera el límite de almacenamiento, se supone que la ejecución del DAG falla. Sin embargo, la tarea no falla inmediatamente y sigue ejecutándose hasta que alcanza una duración de 1 hora y 5 minutos. Esto ocurre porque Kubernetes no finaliza la tarea inmediatamente y sigue ejecutándose para permitir que transcurra una hora hasta la recuperación, lo que se conoce como "periodo de gracia de finalización". Cuando un nodo se queda sin recursos, Kubernetes no finaliza el pod inmediatamente para gestionar la finalización correctamente, de modo que el impacto en el usuario final sea mínimo.
El periodo de gracia de finalización ayuda a los usuarios a recuperar archivos después de que se produzcan errores en las tareas, pero puede generar confusión al diagnosticar DAGs. Si se supera el límite de almacenamiento del trabajador de Airflow, el estado de la tarea final dependerá de la duración de la ejecución del DAG:
Si la ejecución del DAG supera el límite de almacenamiento del trabajador, pero se completa en menos de 1 hora, la tarea se completa con el estado
Successporque se ha completado dentro del periodo de gracia de finalización. Sin embargo, Kubernetes finaliza el pod y el archivo escrito se elimina del contenedor inmediatamente.Si el DAG supera el límite de almacenamiento del trabajador y se ejecuta durante más de 1 hora, el DAG seguirá ejecutándose durante 1 hora y podrá superar el límite de almacenamiento en miles de puntos porcentuales antes de que Kubernetes elimine el pod y Airflow marque la tarea como
Failed.
Diagnosticar el DAG fallido
Si estabas ejecutando varias tareas en el momento del fallo, prueba a ejecutar solo una tarea y diagnostica la presión de los recursos durante ese tiempo para identificar qué tareas causan presión de los recursos y qué recursos debes aumentar.
Revisa los registros de tareas del segundo DAG,
long_running_create_large_txt_file_print_logs:
En la Google Cloud consola, ve a la página Entornos.
En la lista de entornos, haz clic en el nombre del entorno. Se abrirá la página Detalles del entorno.
Ve a la pestaña Registros y, a continuación, a Todos los registros > Registros de Airflow > Workers > Ver en Explorador de registros.
Filtra los registros por tipo: muestra solo los mensajes de Error.
En los registros, verá mensajes similares a los siguientes:
Container storage usage of worker reached 155.7% of the limit.
This likely means that the total size of local files generated by your DAGs is
close to the storage limit of worker.
You may need to decrease the storage usage or increase the worker storage limit
in your Cloud Composer environment configuration.
o
Pod storage usage of worker reached 140.2% of the limit.
A worker pod was evicted at 2023-12-01T12:30:05Z with message: Pod ephemeral
local storage usage exceeds the total limit of containers 1023Mi.
This eviction likely means that the total size of dags and plugins folders plus
local files generated by your DAGs exceeds the storage limit of worker.
Please decrease the storage usage or increase the worker storage limit in your
Cloud Composer environment configuration.
Estos mensajes indican que, a medida que avanzaba la tarea, los registros de Airflow empezaron a mostrar errores cuando el tamaño de los archivos generados por tu DAG superó el límite de almacenamiento del trabajador y se inició el periodo de gracia de finalización. Durante el periodo de gracia de la finalización, el consumo de almacenamiento no volvió al límite, lo que provocó el desalojo del pod una vez finalizado el periodo de gracia.
Revisa la monitorización del estado del entorno y del consumo de recursos:
En la Google Cloud consola, ve a la página Entornos.
En la lista de entornos, haz clic en el nombre del entorno. Se abrirá la página Detalles del entorno.
Vaya a la pestaña Monitorización y seleccione Resumen.
En el panel Resumen del entorno, busca el gráfico Estado del entorno (DAG de monitorización de Airflow). Contiene un área roja que corresponde al momento en el que los registros empezaron a imprimir errores.
Selecciona Trabajadores y busca el gráfico Uso total del disco de los trabajadores. Observa que la línea Uso del disco tiene un pico y supera la línea Límite del disco en el momento en que se estaba ejecutando tu tarea.
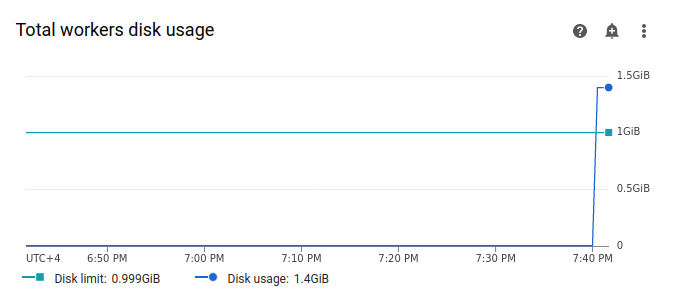
Aumentar el límite de almacenamiento de los trabajadores
Asigna almacenamiento adicional a los workers de Airflow para que el DAG de ejemplo se complete correctamente:
En la Google Cloud consola, ve a la página Entornos.
En la lista de entornos, haz clic en el nombre del entorno. Se abrirá la página Detalles del entorno.
Ve a la pestaña Configuración del entorno.
Busca la configuración de Recursos > Cargas de trabajo y haz clic en Editar.
En la sección Worker (Trabajador), en el campo Storage (Almacenamiento), especifica el nuevo límite de almacenamiento para los trabajadores de Airflow. En este tutorial, configúralo en 2 GB.
Guarda los cambios y espera varios minutos a que se reinicien los trabajadores de Airflow.
Probar el DAG con el nuevo límite de almacenamiento
Vuelve a activar el DAG long_running_create_large_txt_file_print_logs y espera 1 hora y 15 minutos hasta que termine de ejecutarse.
En los registros de salida de la ejecución del DAG, verás
Marking task as SUCCESS. El estado de la tarea será Correcto, con una duración de 1 hora y 15 minutos, que es el tiempo de espera definido en el código del DAG.Consulta la sección Resumen del entorno de la pestaña Monitorización y comprueba que no haya ninguna zona roja.
Haz clic en la sección Trabajadores y busca el gráfico Uso total del disco de los trabajadores. Verás que la línea Límite de disco refleja el cambio en el límite de almacenamiento y que la línea Uso del disco está dentro del intervalo permitido.
Resumen
En este tutorial, has diagnosticado el motivo de un fallo de un DAG y has identificado el tipo de recurso que provoca presión depurando dos DAG de ejemplo que fallan debido a la falta de memoria y almacenamiento de los trabajadores. Después, ejecutaste los DAGs correctamente tras asignar más memoria y almacenamiento a tus trabajadores. Sin embargo, te recomendamos que optimices tus DAGs (flujos de trabajo) para reducir el consumo de recursos de los trabajadores, ya que no es posible aumentar los recursos más allá de un determinado umbral.
Limpieza
Para evitar que se apliquen cargos en tu cuenta de Google Cloud por los recursos utilizados en este tutorial, elimina el proyecto que contiene los recursos o conserva el proyecto y elimina los recursos.
Eliminar el proyecto
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Eliminar recursos concretos
Si tienes previsto consultar varios tutoriales y guías de inicio rápido, reutilizar los proyectos puede ayudarte a no superar los límites de cuota de proyectos.
Elimina el entorno de Cloud Composer. También eliminarás el contenedor del entorno durante este procedimiento.