Building Google's Game of the Year with Cloud Text-to-Speech and App Engine

JK Kafalas
Creative Engineer
Tyler Yin
Creative Coder
At the end of every year, we take a look at Google Search trends, culminating in our annual Year in Search film. This year, we decided to also build Game of the Year, the first quiz game based on Google Search trends. We thought it would be fun to bring the trends to life, and we wanted to experiment a bit with our own technology. You can see here what the game is all about:
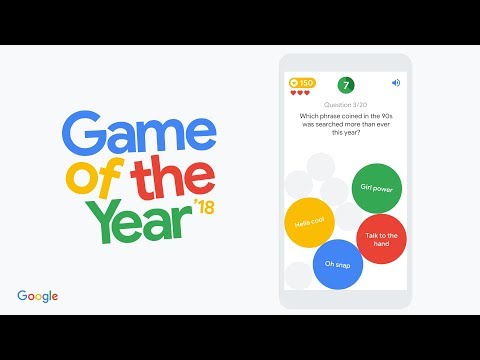
To build the game, we used Google Cloud technologies and WaveNet, which is a deep neural network that generates raw audio waveforms. Here’s how we did it.
Bringing the game to life with Cloud Text-to-Speech, WaveNet and SSML
Months before we built anything for production, our designers, writers, and developers here on the Brand Studio team worked on varying game ideas and prototypes centered around the year’s Search trends data. A key feature of these early prototypes was Cloud Text-to-Speech. From the beginning, we wanted to take advantage of its ability to personalize any statement with a user’s name on the fly using a natural-sounding voice. This feature lets us develop our “host,” a delightful feature and core part of the game.
From a practical perspective, using Cloud Text-to-Speech also significantly reduced production overhead. We could change copy easily without needing a voice actor to re-record every time we added or changed a question or answer. It also allows us to easily scale if we decide to add new questions to the game or translate it to other languages.
As part of our early prototypes, we also played with several WaveNet voices. Its ability to sound out everything from awkward brand names to difficult-to-pronounce celebrity names was uncanny—and especially important given that some of 2018’s Search trends aren’t exactly standard words you find in the dictionary. We also explored Speech Synthesis Markup Language (SSML), which lets you tailor WaveNet’s speech by modifying inflection, emphasis, timing, and other very granular speech parameters. We used SSML mostly in our initial demos to make even more natural-sounding speech. Because our final product underwent frequent content updates, we couldn’t take advantage of SSML as much as we would have liked by launch time. Fortunately, we found the default speech synthesis to be pretty impressive as is. We were pleasantly surprised when the WaveNet model pronounced certain strings like “Givenchy” (jzhiv-on-shee) as intended. Other interpretations did not quite work as we had hoped (see: Go...o.o.o.o.o.o.o.o.o.o...al), but were humorous enough to keep in the final build.
Finding the right audio balance
Our initial prototypes showcased all of the possible accents, languages, and genders available in Cloud Text-to-Speech. In some iterations we used the voice primarily as a source of comic relief in between questions, such as by ribbing the player for getting a wrong answer, or incorporating terrible puns after some questions. While fun to listen to, we realized we needed to strike the right balance between humorous audio commentary and unobtrusive gameplay. In the end, it felt more natural to have the host read the questions and answer selections like an actual game show host would, and to develop the host’s “character” via clever writing. Limiting the host to speaking only the written questions and facts also meant that those not using the audio experience wouldn’t miss any of the fun dialogue or receive a lesser game experience.
The amount of dialogue was also important in calculating the necessary API quota. Exceeding the quota causes the host to remain silent on subsequent play-throughs of the game that day, as the API returns an appropriate “quota exceeded” error. We worked with the Cloud Text-to-Speech team to estimate queries per minute and characters per minute based on expected traffic and the length and frequency of each spoken phrase. In order to avoid issues in the event that the game did exceed our quota, we wrote in a simple check to disable the host’s voice and talking animation if any client or server errors were returned by the API. This allows the game to continue seamlessly for users with the music and sound effects only.
Though we ended up narrowing down the host’s voice to only two options (one male and one female), which are randomized at the start, users can customize those voices in-game by changing the speed and pitch on the intro page, as shown below. We decided to limit those ranges to avoid unintended audio-timing bugs that appeared with extreme changes to the voice speed—for example, the host talking too slowly to finish speaking before the next line of dialogue begins. We hope that users find this balance of audio features as delightful as we do!
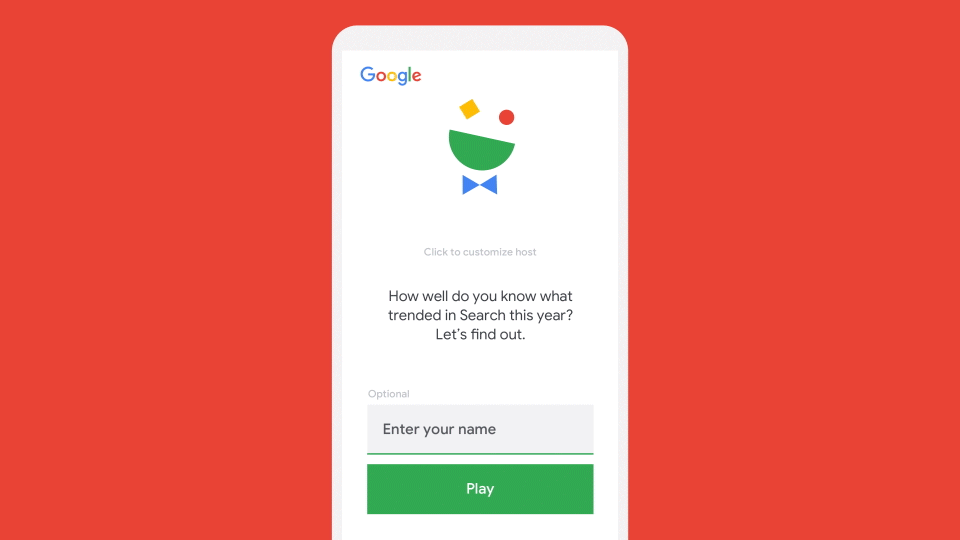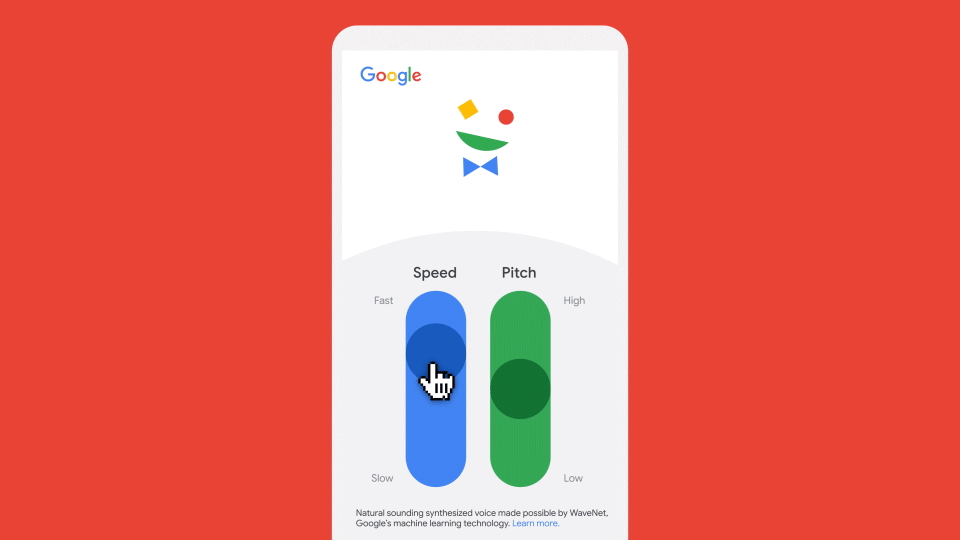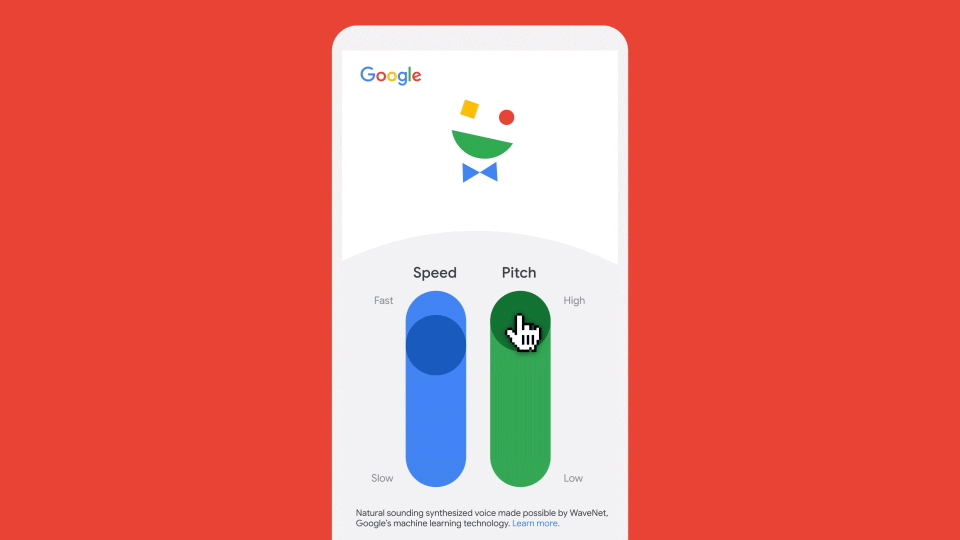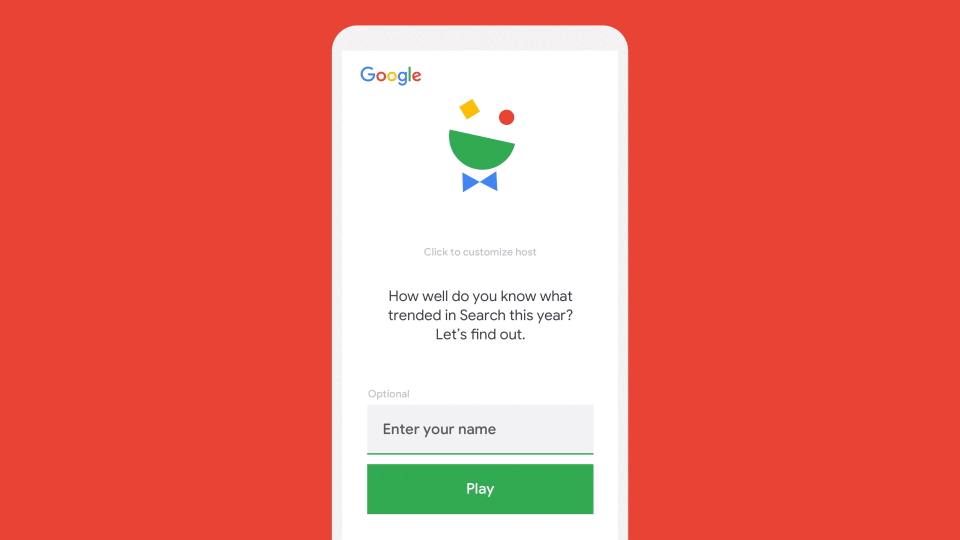
Building the game at scale
We built the game on App Engine to take advantage of Google Cloud’s ability to quickly scale based on traffic, its developer-friendly environment, access management, easy deployment and versioning, and API management tools. The game is a single-page Angular app, which is statically served and front-end-cached to reduce latency, and integrates the Cloud Text-to-Speech API, Matter.js for physics, Hammer.js for touch gestures, and Tween.js for animation. To easily scale and maintain the content, we used an internally built content management system to store and edit the questions, answers, fun facts and images used throughout the game.
The Cloud Text-to-Speech API integrated seamlessly into the game’s build, creating a smooth, natural audio experience across all supported platforms. Knowing how easily we can include this technology in our applications opens a lot of doors to enhance future projects in delightfully unexpected ways. We’re equally excited to see what other developers come up with using this awesome piece of technology.
Give Game of the Year a shot and find out how well you know the trends of 2018.



