Vertex AI Foundations for secure and compliant ML/AI deployment
Crispin Velez
Global AI incubation, Google
Vincent Ciaravino
Vertex AI Outbound Product Manager
Secure and enable Vertex AI platform as your end to end ML/AI platform for production workloads.
An increasing number of Enterprise customers are adopting ML/AI as their core transformational pillars, in order to differentiate, increase revenue, reduce costs and maximize efficiency. For many customers ML/AI adoption can be a challenging endeavor not only because of the broad spectrum of applications ML/AI can support, deciding on which one to prioritize can be a challenge, but because moving these solutions into production require a series of security, access and data assessments and features that some ML/AI platforms might not have. This blog post focuses on how to set up your Cloud foundations to cater specifically to the Vertex AI platform and its configuration to be able to set up proper Vertex AI foundations for your future machine learning operations (MLOps) and ML/AI use cases.
Explainability is not covered in this blog post, but as a practitioner it is one of the key components for any production ready ML system to take it into account. You can take a look at Vertex Explainable AI for a more in depth approach on feature based explanations, feature attributions methods (Sampled Shapley, Integrated methods and XRAI) and differentiable and non-differentiable models.
Vertex AI currently comprises more than 22 services, so for simplicity we will cover the five core services to get your end-to-end machine learning process enabled and enterprise ready:
Vertex AI Workbench
Vertex AI Feature Store
Vertex AI Training
Vertex AI Prediction
Vertex AI Pipelines
Vertex AI reference Enterprise Networking Architecture
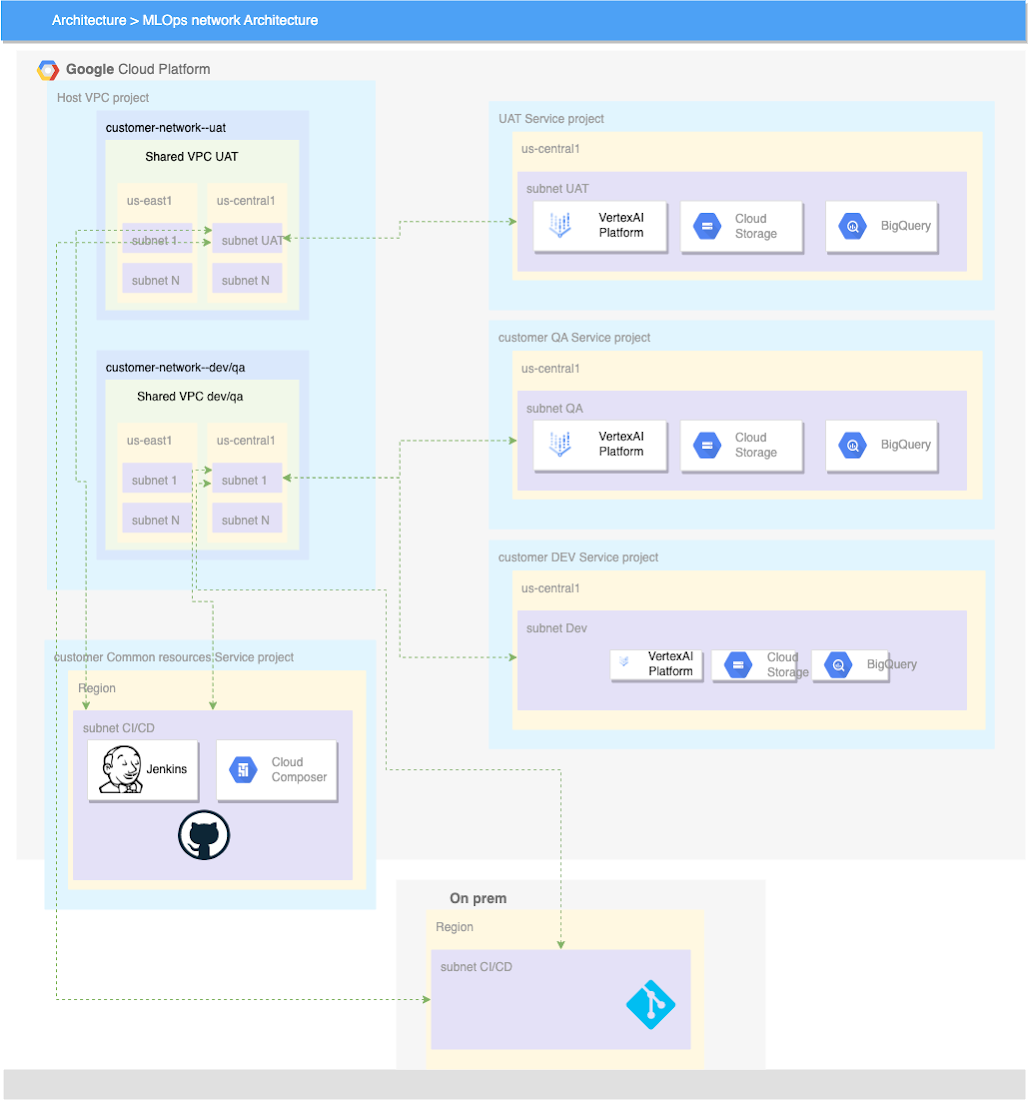
One of the key components is to understand how you should establish your development, user acceptance testing/Quality (UAT/QA) and Production environments. It's clear that as you move from one environment to another you will want to restrict external access and automate as much as possible. It's at this point when ML/AI starts to become very similar in the way it publishes code into production to the software development lifecycle. If you are familiar with DevOps Research and Assessment (DORA) or Development Operations (DevOps) and Machine Learning Operations (MLOPs) you can see how continuous integration and continuous delivery are applicable across both frameworks to ship and build code continuously, securely and reliably.
Vertex AI Machine Learning Operations
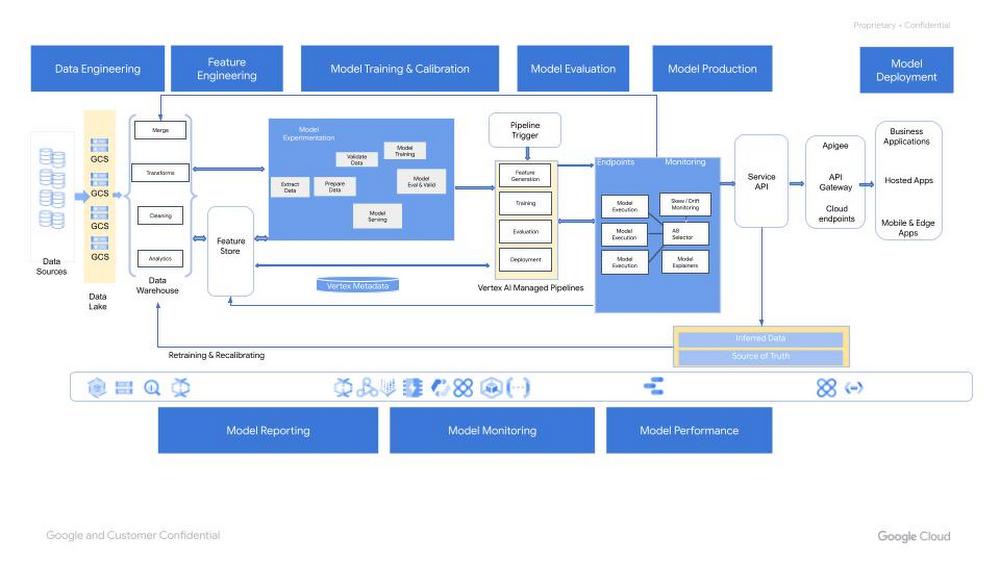
Machine learning operations borrow many elements from DevOps when it comes to ensuring an automated and reliable way of shipping software across multiple environments. Different companies might be in a different stage of their MLOps journey however, according to many research studies like the one from IDC, much of the Return On Investment (ROI) for ML/AI projects lies in moving into production.
DevOps is a popular practice in developing and operating large-scale software systems. This practice provides benefits such as shortening the development cycles, increasing deployment velocity, and dependable releases. To achieve these benefits, you introduce two concepts in the software system development:
An ML system is a software system, so similar practices apply to help guarantee that you can reliably build and operate ML systems at scale. However it is important to understand the difference between DevOps and MLOps (“MLOps: Continuous delivery and automation pipelines in machine learning | Cloud Architecture Center”):
Team skills: In an ML project, the team usually includes data scientists or ML researchers, who focus on exploratory data analysis, model development, and experimentation. These members might not be experienced software engineers who can build production-class services.
Development: ML is experimental in nature. You should try different features, algorithms, modeling techniques, and parameter configurations to find what works best for the problem as quickly as possible. The challenge is tracking what worked and what didn't, and maintaining reproducibility while maximizing code reusability.
Testing: Testing an ML system is more involved than testing other software systems. In addition to typical unit and integration tests, you need data validation, trained model quality evaluation, and model validation.
Deployment: In ML systems, deployment isn't as simple as deploying an offline-trained ML model as a prediction service. ML systems can require you to deploy a multi-step pipeline to automatically retrain and deploy models. This pipeline adds complexity and requires you to automate steps that are manually done before deployment by data scientists to train and validate new models.
Production: ML models can have reduced performance not only due to suboptimal coding, but also due to constantly evolving data profiles. In other words, models can decay in more ways than conventional software systems, and you need to consider this degradation. Therefore, you need to track summary statistics of your data and monitor the online performance of your model to send notifications or roll back when values deviate from your expectations.
Vertex AI Workbench - User Managed
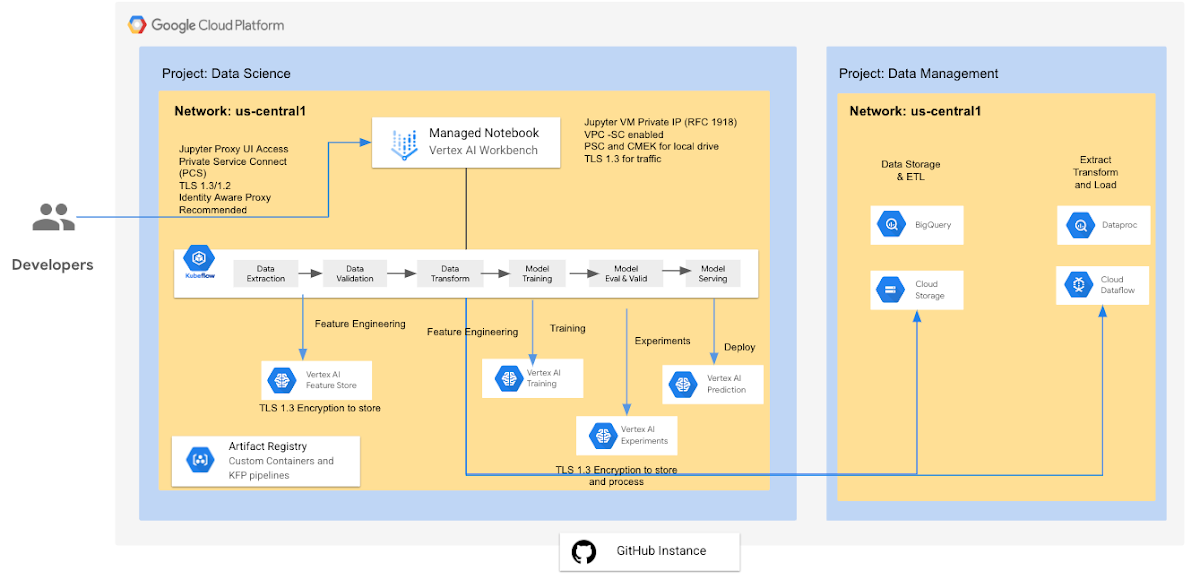
User-Managed Notebooks are Deep Learning VM Images instances with JupyterLab notebook environments enabled and ready for use. This page describes how to upgrade the environment of a user-managed notebooks instance. When running a Jupyter notebook in Google Cloud on a User-Managed Notebook, your instance runs on a virtual machine (VM) managed by Vertex AI Workbench. From the Jupyter Notebook, you can access BigQuery and Google Cloud Storage data. For added security, you can run a Shielded VM as your computer instance for Workbench Notebooks. Log streaming to the consumer project via Logs Viewer is supported. You can also include the notebooks API to any legacy VM you might have following this guide.
All data at rest in GCP is encrypted. By default, this encryption will use a Google-managed key, though for greater control some customers use a Customer-Managed Encryption Key (CMEK), or even provide the key from their own Hardware Security Module (HSM) using our External Key Manager. Data in transit is also encrypted by default using TLS.
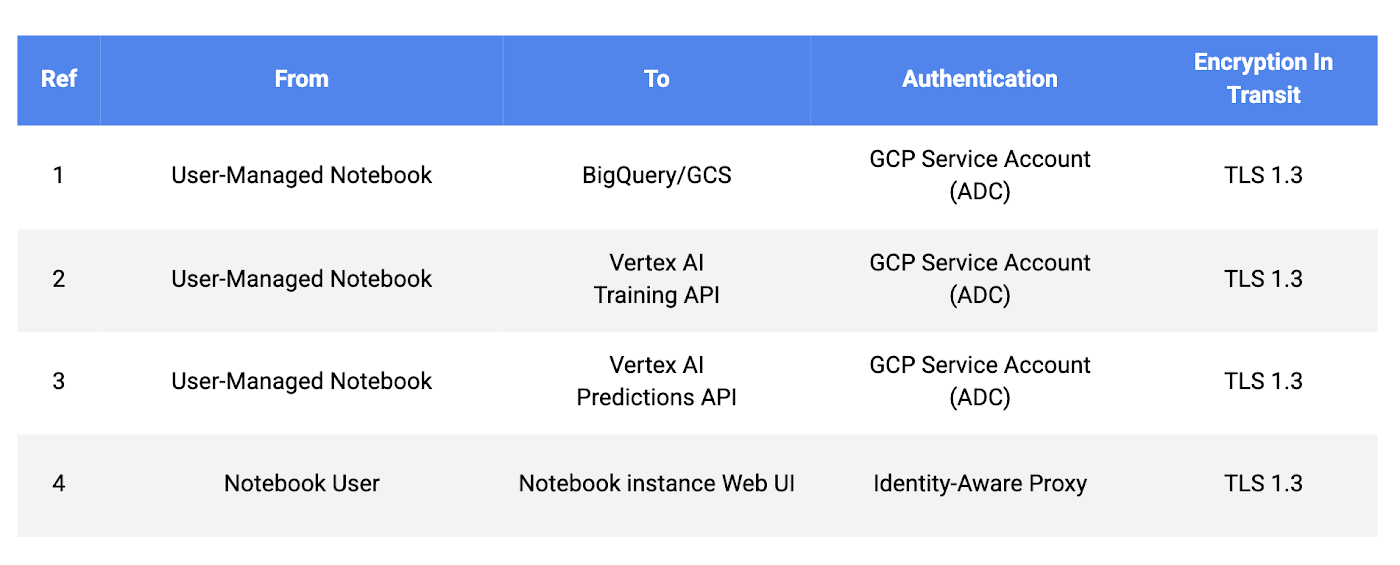
Additionally, we recommend you use Google Cloud Client Libraries for your application. Google Cloud Client Libraries use a library called Application Default Credentials (ADC) to automatically find your service account credentials. Another recommendation is that you use custom service accounts instead of predefined or basic roles.
Vertex AI Feature Store
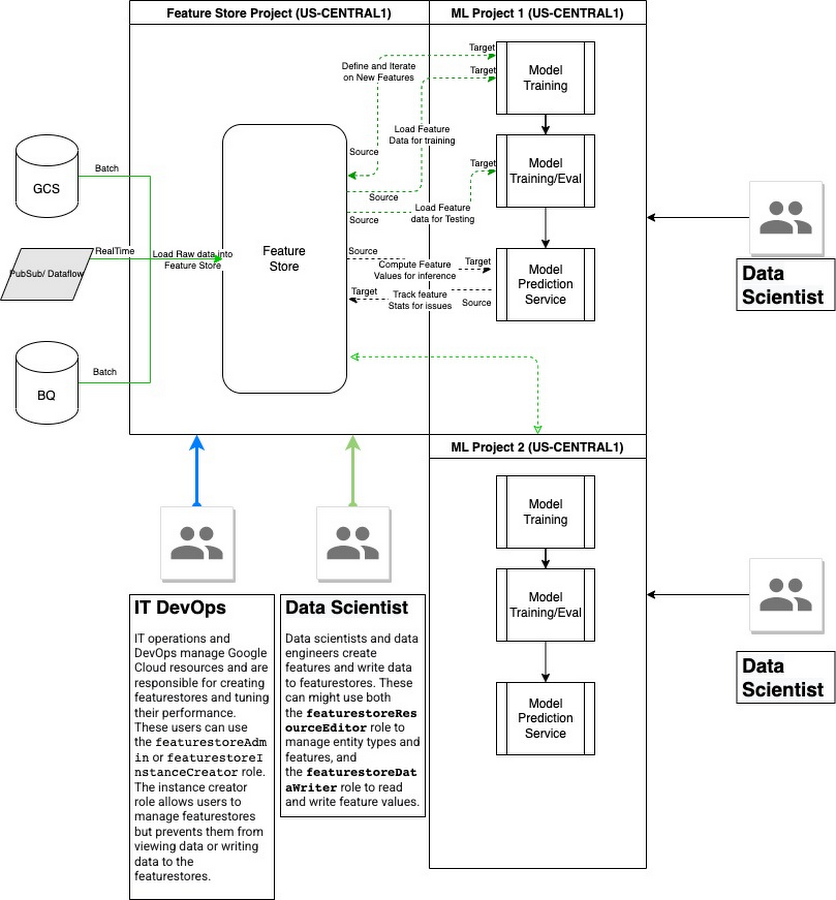
Vertex AI Feature Store provides a centralized repository for organizing, storing, and serving ML features. Using a central feature store enables an organization to efficiently share, discover, and re-use ML features at scale, which can increase the velocity of developing and deploying new ML applications.
Since Feature Store is a regionalized service, all data stays in the same GCP region as the featurestore resource or the region in the user's request. For enterprise deployment, it is recommended to configure a shared services project where many data science projects can contribute and cross collaborate. Feature Store keeps feature values until the configurable data retention limit up to the default of 4000 days. Each serving node can store up to 5TB. You can find more information about quotas and limits for Feature Store here.
Storage Systems (GCS, BigQuery, Notebook boot and persistent disks) that are used to ingest/export data provide encryption. All data (Feature/EntityType Metadata and feature values data) is encrypted in transit (TLS 1.3 is supported). The feature store and all content in the feature store supports CMEK (Create a feature store that uses a CMEK). Vertex Feature Store supports VPC Service Control.
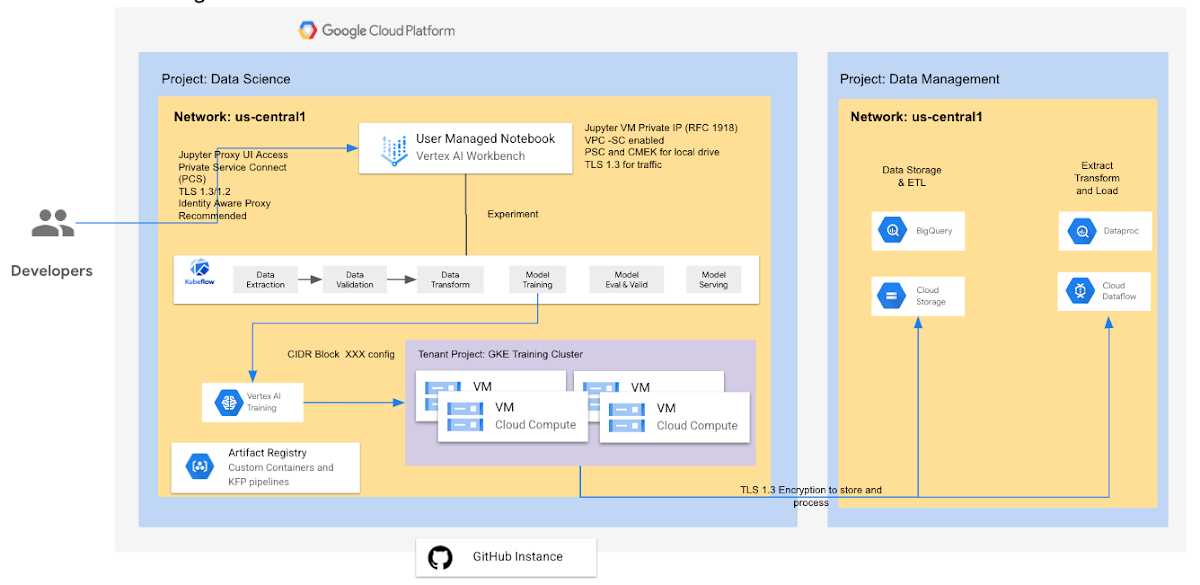
One of the key benefits of Vertex AI Training is the ability to specify multiple machines (nodes) in a training cluster when you run a distributed training job with Vertex AI. The training service allocates the resources for the machine types you specify and your running job on a given node is called a replica. A group of replicas with the same configuration is called a worker pool and this type of configuration will help speed up your machine learning model training considerably.
Vertex AI Training is a Google managed GCE/kubernetes cluster in a tenant project that is torn down (container and data destroyed) when the job is done. The tenant project is 1:1 with the customer project and exists in the same region, so data residency is respected. The training job does not store data in tenant projects, only on the VMs (either in RAM or on bootdisk) as required to execute the customer's code. The training process can store data in the user project GCS by explicit request from the user. CMEK is supported to encrypt code, pulled data on boot disk, and temporary data on disk saved by your code. You can take a look at this guide to use a private IP for a custom training Job.
Vertex AI Training provides managed, Kubernetes-based training clusters that are created and destroyed as needed, for each training job that you run. This allows you to minimize training time when needed, without paying for resources that you're not using between jobs. Then you can choose the cost/performance ratio that works for each job you run by adjusting the shape and quantity of the containers. This is especially valuable when you have training jobs that would benefit from GPUs. You can leverage Google Cloud's substantial investment in GPU infrastructure, choosing from among several types depending on your use-case. You can also leverage Vertex AI Vizier as your blackbox tool to perform Hyperparameter tuning and simplify the process of searching for the ideal model architecture.
With Vertex AI Training you won't need to worry about setting up, configuring, hardening, patching or otherwise maintaining these clusters. Just submit your training code and let it run. This lets you focus on what you do best: writing ML code.
As of now, Terraform does not allow ‘Job Resources’ to be created, making training challenging to set up through IaC. There are however some prerequisite resources required to creating a Managed Pipeline such as Service Accounts, Cloud Storage Buckets, and APIs. These prerequisite resources are nicely bundled in this Terraform module.
Vertex AI does not "train" your code. Vertex AI Training executes your training code. Your training code can decide to cache data locally or stream directly to memory. Whether the data will touch a local storage on a compute node will depend on the storage mechanism your code uses. If it uses GCSFuse, the data may touch the local disk. If you use NFS mounts the data may touch local disks. If you access GCS, BigQuery, etc. directly then you have control how the data flows.
When creating a Vertex AI Training resource, there are two different training methods. AutoML and custom training. More information can be found on AutoML in a subsequent section below. Custom training jobs (CustomJob resources in the Vertex AI API) are the basic way to run your custom machine learning (ML) training code in Vertex AI. This allows you to run your TensorFlow, PyTorch, scikit-learn, and XGBoost training applications in the cloud. To learn more about Custom Training, check out the documentation here. Additional information to run your Training jobs using Kubeflow on GKE can be found here.
Vertex AI Training allows you to use Vertex AI managed datasets to train your custom models. When you create a custom training pipeline, you can specify that your training application uses a Vertex AI dataset. To learn more about using Managed Datasets in your Vertex AI Trainings, check out the documentation here.
Vertex AI Predictions
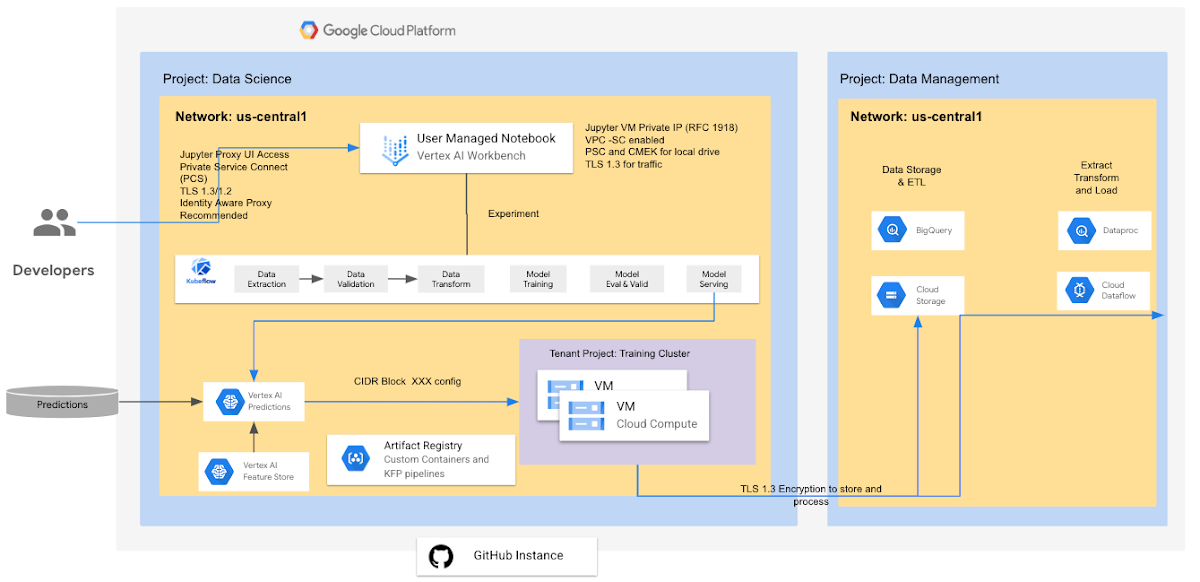
Vertex AI Batch Prediction provides a managed service for serving Machine Learning batch predictions. It can take input data from BigQuery and Google Cloud Storage, run predictions against the data, and return the results to GCS or BigQuery, respectively.
The tenant project is 1:1 with the customer project, and exists in the same region, so data residency is respected. The tenant project does not store any input data for batch prediction, only on the VMs (either in RAM or on bootdisk) as required to execute the customer's code. The input & output data in-memory is wiped when the job is complete (everything is wiped). Any temporary files (for example, model files, logs, VM disks) used in the job to proceed the batch prediction job are encrypted with CMEK. If the written results of the BatchPrediction are stored in the user provided destination, it will respect the encryption config of its default value. Otherwise, it will also be encrypted with CMEK.
To customize how Vertex AI serves online predictions from your custom-trained model, you can specify a custom container instead of a pre-built container when you create a Model resource. When you use a custom container, Vertex AI runs a Docker container of your choice on each prediction node. To learn more about custom containers for predictions check out the documentation here.
Online prediction
Vertex AI Online Prediction provides a managed service for serving Machine Learning predictions for your online use cases. This allows you to easily get online (real-time) predictions and explanations from your tabular classification or regression models using the Google Cloud console or the Vertex AI API. Use Online Predictions to get a synchronous request as opposed to a batch prediction, which is an asynchronous request such as when you are making requests in response to application input or in other situations where you require timely inference. You can take a look at this guide to set up a private prediction endpoint, a recommended practice for enterprise.
Before you can get online predictions, you must first train a classification or regression model and evaluate it for accuracy.You can request an online prediction by sending your input data instances as a JSON string in a predict request. For formatting of the request and response body, see the details of the prediction request.
If your organization want to keep all traffic private it is recommended you use private endpoints to serve online predictions with Vertex AI this provides a low-latency, secure connection to the Vertex AI online prediction service. Before you serve online predictions with private endpoints, you must configure private services access to create peering connections between your network and Vertex AI. Once you have set it up you can go over the Using private endpoint predictions for online prediction guide. Keep in mind each prediction must be below 1.5MB.
Vertex AI Managed Pipelines
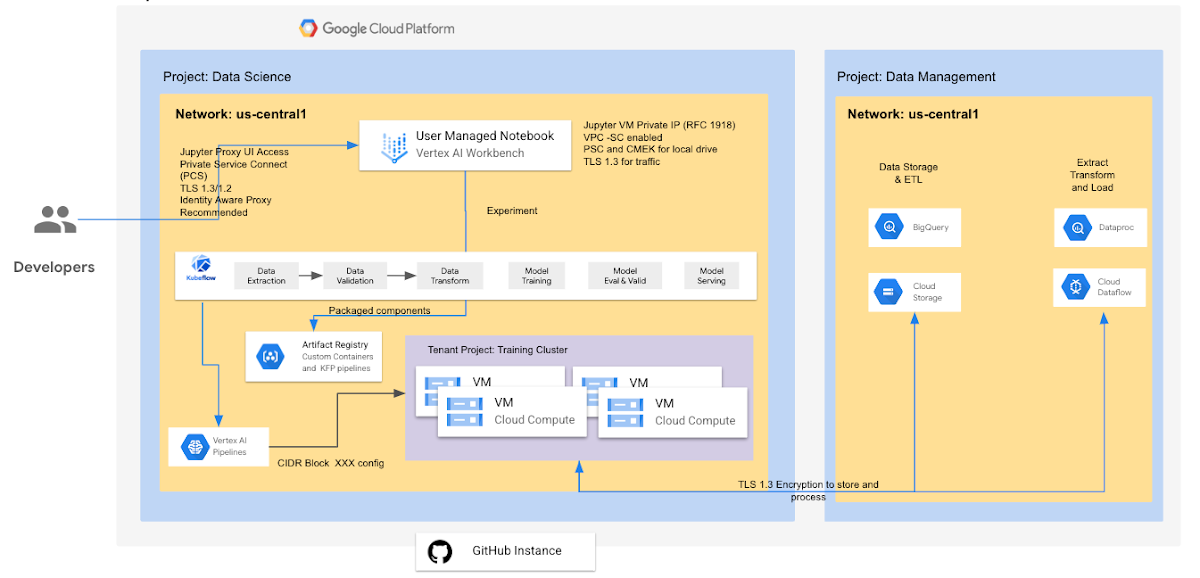
Vertex AI Pipelines run in a Google-owned VPC network in a tenant project that is peered to the network in your project. Each pipeline step (component instance) has an associated container image. Your pipelines use container images hosted in Container/Artifact Registry. By default, the component will run on as a Vertex AI CustomJob. Additional information to build your pipelines using Kubeflow on GKE can be found here.
Vertex AI Pipelines uses Cloud Storage to store the artifacts of your pipeline runs. Vertex ML Metadata stores metadata for pipelines run using Vertex AI Pipelines in the tenant project. Vertex AI Pipelines support custom service account, customer-managed encryption key, and peered VPC network. All data at rest is encrypted by default.
As of now, Terraform does not allow ‘Job Resources’ to be created making Managed Pipelines tricky to set up through IaC. There are some prerequisite resources required to create a Managed Pipeline such as Service Accounts, Cloud Storage Buckets, and APIs. These prerequisite resources are nicely bundled in this Terraform module.
The artifacts of your pipeline runs are stored within the pipeline root. We recommend that you create a service account to run your pipelines and then grant this account granular permissions to the Google Cloud resources that are needed to run your pipeline. If you want your data encrypted using a customer-managed encryption key (CMEK), you must create your metadata store using a CMEK key before you run a pipeline. After the metadata store has been created, the CMEK key that the metadata store uses is independent of the CMEK key used in a pipeline



