Model training as a CI/CD system: Part II
Sayak Paul
ML Google Developer Expert
Chansung Park
ML Google Developer Expert
Try Google Cloud
Start building on Google Cloud with $300 in free credits and 20+ always free products.
Free trialIn the first part of the blog post, we discussed how to monitor code changes and submit a TensorFlow Extended (TFX) pipeline to Vertex AI for execution. We concluded that post with a few questions:
What if we wanted to maintain a schedule (say hourly -- usually dependent on the use-case) to trigger the pipeline runs on Vertex AI?
What if we wanted a system such that during the experimentation phase whenever a new architecture is published as a Pub/Sub topic the same pipeline needs to be executed (but with different hyperparameters)?
In this final half of the blog post, we will tackle these situations and discuss some possible workarounds.
Approach
We present a diagrammatic overview of the workflow we will realize in Figures 1 and 2. First, we will use Cloud Build to:
Clone a repository from GitHub that contains all the code needed to build and compile a TFX pipeline ready for execution.
Build and push a custom Docker image that will be used to execute the pipeline.
Upload the compiled pipeline to a bucket on Google Cloud Storage (GCS).
This is pictorially depicted in Figure 1.

The said pipeline is capable of taking runtime parameters as inputs. This is particularly helpful when you’d want to keep your pipeline components the same while performing different experiments with different sets of hyperparameters, for example. As a result, you will reuse the pipeline and only create different experiments with varying hyperparameters. Note that you could use this same pipeline for model retraining based on the availability of new data as well. For the purpose of this post, we will keep things simple and will pass the model hyperparameters (number of epochs and optimizer learning rate) as the pipeline runtime parameters.
In Figure 2, we present the other half of our workflow that would take the compiled TFX pipeline and submit it to Vertex AI for execution.
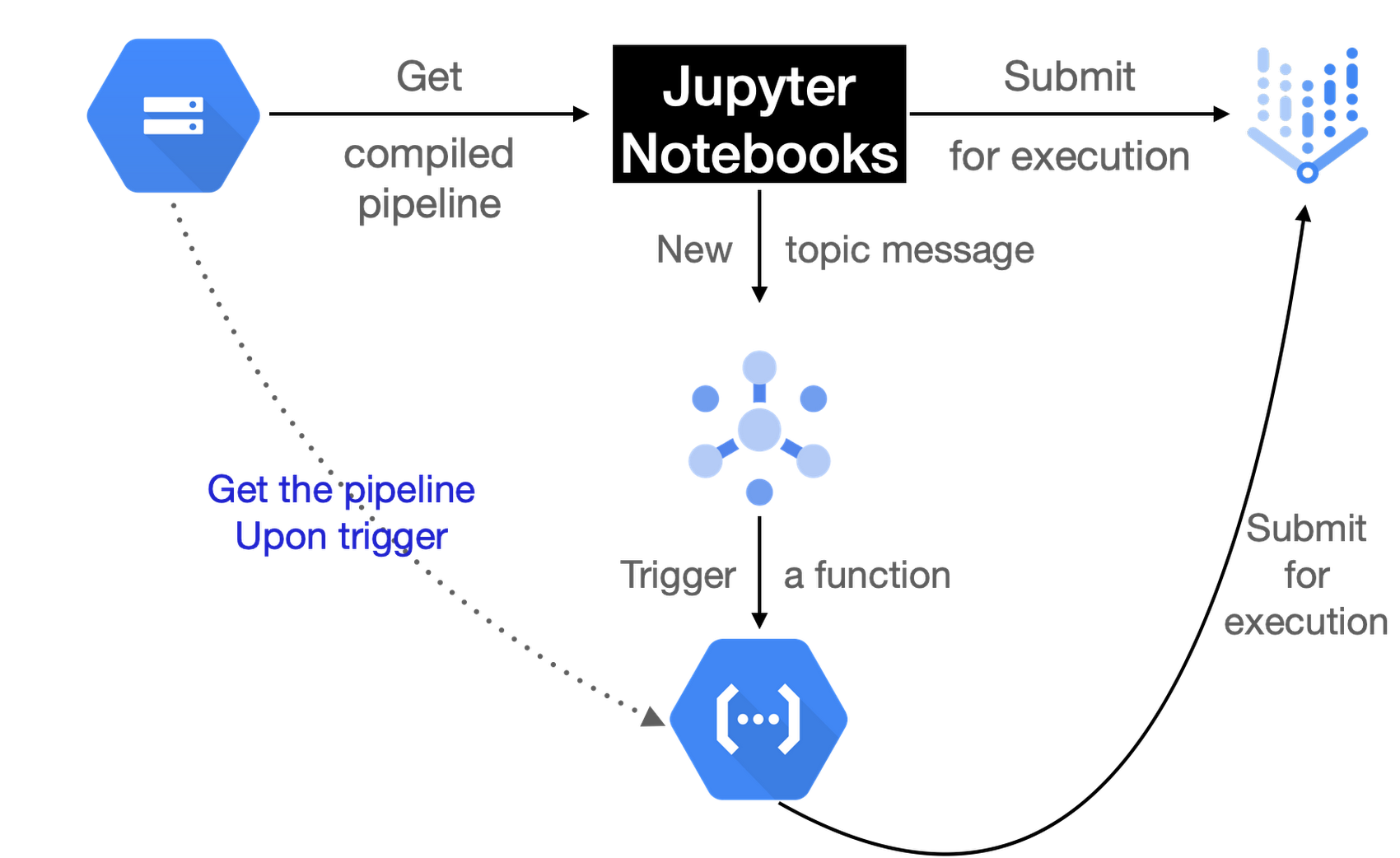
We can either take the compiled pipeline spec and submit it to Vertex AI for execution, or we can use a trigger mechanism for initiating the pipeline execution. The latter case is particularly useful to handle situations when you want to connect the bridge between an event and pipeline execution. Examples for this event include the arrival of new data, new model architectures, a new set of hyperparameters, new preprocessing logic, etc. Based on events like these you’d want to have a mechanism that automatically triggers or schedules the execution of your pipelines.
We will cover two workarounds:
One where we will publish a message to a topic on Pub/Sub which a Cloud Function will be subscribed to. This Cloud Function will then be responsible for initiating the pipeline execution. For context, the topic message will contain model hyperparameters and their values.
In the other solution, we will schedule a job using Cloud Scheduler which will be responsible for triggering the Cloud Function for pipeline execution.
If you’d like to know how to trigger a model training pipeline based on the arrival of new training data in a BigQuery database, refer to this blog post.
Implementation details
In this section, we discuss the technical details of the approaches we presented above. We will not go too deep into the TFX related components and instead focus on the bits primarily at play here. We will provide relevant references for readers interested to know more about the parts not covered here in great detail.
The code shown throughout this section is available in this repository. We have used this Google Cloud repository as our main source of reference.
TFX pipeline and compilation
For the purpose of this post, we will be using the TFX pipeline shown in this TFX tutorial. It uses the Palmer Penguins dataset and trains a simple neural network in TensorFlow that can predict the species of a penguin. The pipeline has the following TFX components: CsvExampleGen, Cloud AI Trainer, and Pusher.
Discussing the pipeline bits by bits is out of scope for this post and we refer the readers to the original tutorial linked above.
The pipeline code is first hosted on a GitHub repository. You can also host your code on BitBucket, GitLab, and so on, or even Cloud Repositories. Recall from Figure 1, we will be compiling this pipeline and get it uploaded to a GCS Bucket.
Our pipeline should be able to take parameters at runtime and for that, we will be using RuntimeParameters provided by TFX. In our case, these will be the number of epochs and learning rate for the optimizer we would use. We can do this like so:
You can refer to the entire pipeline creation and compilation code from here.
But the story does not end here. We still have to build and push a custom Docker image including all the utility scripts and any other Python packages. This Docker image will eventually be used by Vertex AI to run the submitted pipeline. On top of this, we will also need to automate all the steps we discussed so far as a sort of build process for which we will Cloud Build.
Cloud Build operates with YAML specifications and our specification looks like so:
This specification file may be easier to read once you refer to the YAML specification document we linked above. The variables prepended with “$” are the ones we set when we call this YAML file for initiating the build process on Cloud Build. After this specification file is configured, we just need to initiate a run on Cloud Build:
SUBSTITUTIONS hold all of our variables relevant to the pipeline specification:
The entire build process is demonstrated in this notebook. If the build is submitted successfully to Cloud Build it would appear like so on the dashboard:
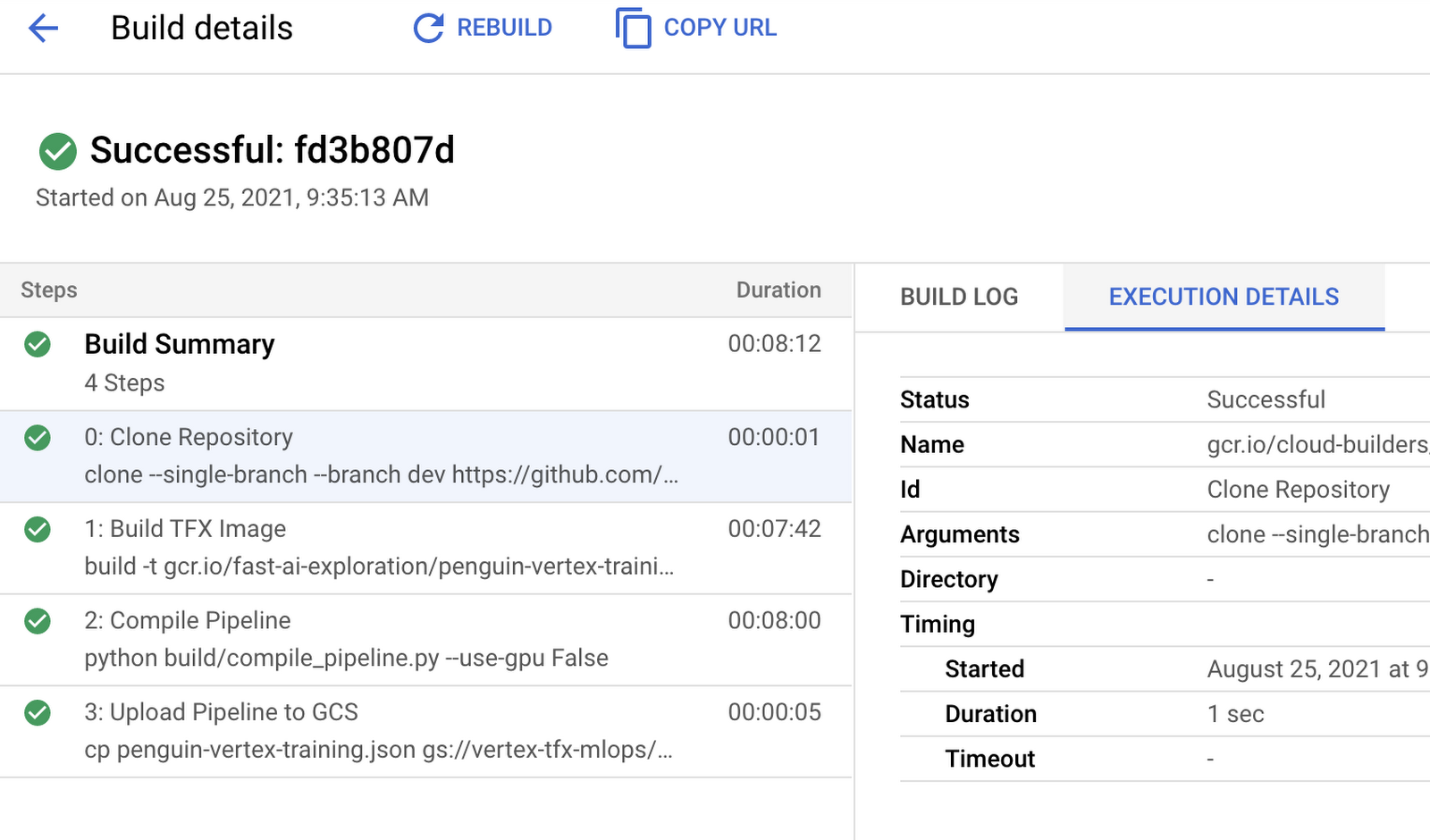
The output of the build will be a compiled pipeline specification file (in .json) that can be submitted to Vertex AI (or other orchestrators) for execution.
Pub/Sub & Cloud Functions
We now create a Pub/Sub topic and deploy a Cloud Function that will be subscribed to this Pub/Sub topic.
We will publish messages to this topic and as soon as this is done our Cloud Function will be triggered. If you are confused with this bit don’t worry, it will get cleared up in a moment.
The Cloud Function will be responsible for parsing the message published to the Pub/Sub topic and then triggering the pipeline run on Vertex AI and it looks like so:
Take note of the Python function (trigger_pipeline()), this is going to be important when deploying our Cloud Function. You can find all the components of the Cloud Function from here.
To deploy the Cloud Function we first specify our environment variables and then perform the deployment of it.
Some important parameters from the gcloud functions deploy command:
trigger-topic which is the name of our Pub/Sub topic, source is the directory where the relevant files specific to Cloud Function are hosted, and entry-point is the name of the Python function we discussed above. For more context, the directory to which source is pointing at contains the following files: requirements.txt specifying the Python packages needed for the Cloud Function, main.py containing the definition of trigger_pipeline().
After the Cloud Function is deployed, we can view it on a dashboard and get a number of important statistics:
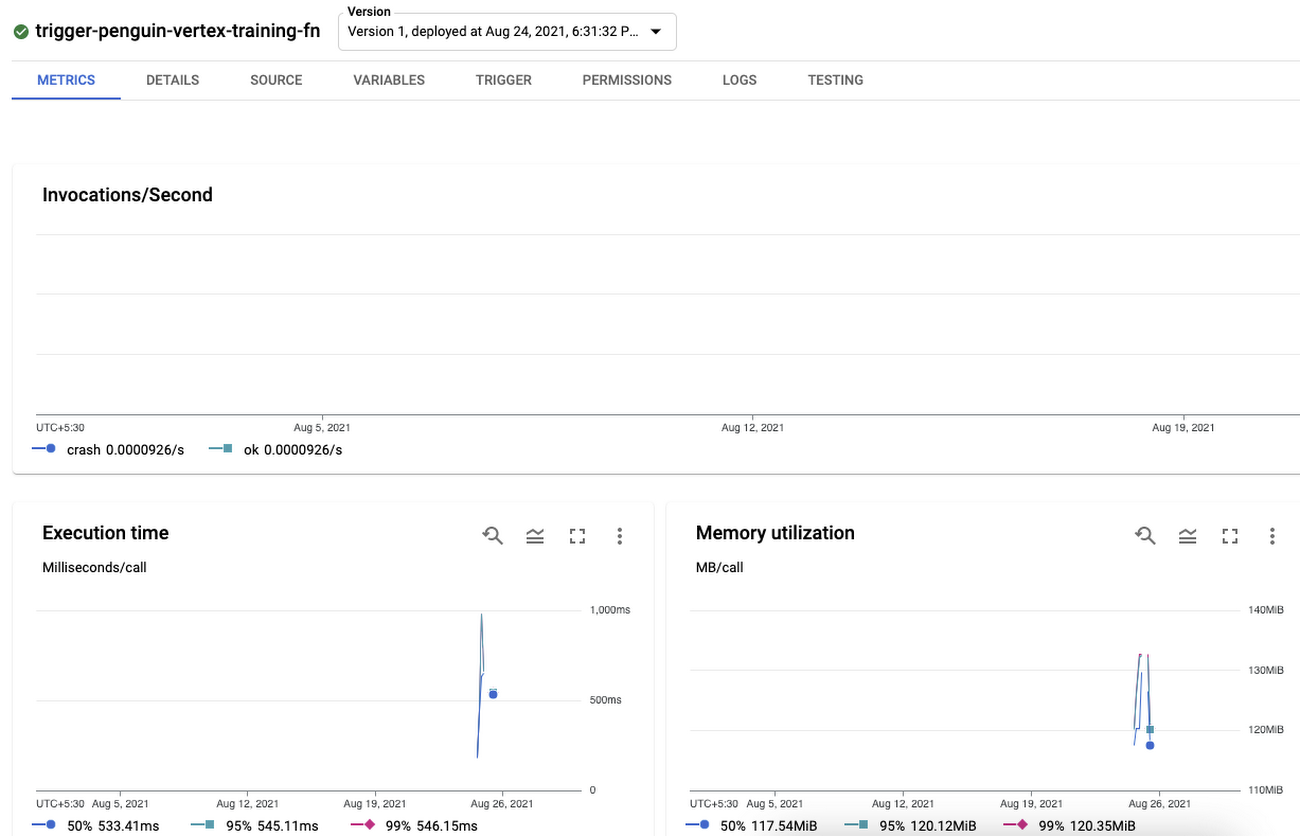
Now we can publish a message to the Pub/Sub topic we had created earlier. As soon as we do so the Cloud Function subscribed to the topic will get triggered and submit our pipeline with the parsed parameters to Vertex AI.
Our pipeline looks like so graphically:
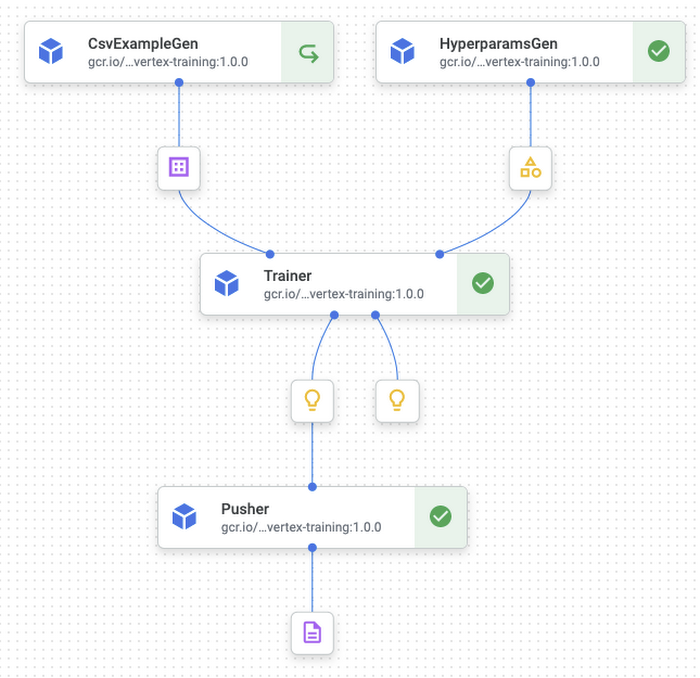
You can find the entire integration with Pub/Sub and Cloud Function in this notebook.
Cloud Scheduler
There are a number of situations where you want to run the pipeline periodically. For example, we might want to wait for a certain period of time until we get enough data. Based on this we can perform batch predictions to extract embeddings or monitor the model performance.
This can be done by integrating Cloud Scheduler to the existing system. Cloud Scheduler is a fully managed enterprise-ready service to handle cron jobs, and we can easily connect it to other GCP services such as Pub/Sub.
There are two ways to create a job for Cloud Scheduler. The first option is to use the gcloud CLI tool. You need to get credentials for Cloud Scheduler for your service account. Please follow this official document on how to create a service account and download the service account key. Once you have downloaded the service account key, you need to set up the environment variable pointing to the service account key JSON file:
The gcloud command will recognize the environment variable automatically. The gcloud scheduler jobs create pubsub creates a periodic job to publish a Pub/Sub topic with a given message. The value of the --schedule option should be set according to the standard cron job format. For instance “*/3 * * * *” means run a task every three minutes. Running a MLOps pipeline every three minutes doesn’t reflect a real world situation, but it is only set to demonstrate the behaviour of Cloud Scheduler.
The value of the --topic option should be matched to the topic name that you have created for the Pub/Sub previously. The --message-body option lets you deliver additional data to the Pub/Sub in JSON format. In this example, we have used it to push hyperparameters to the Cloud Function. One thing to note when you use Jupyter Notebook is that the JSON format string should be encoded by json.dumps method. This makes sure the JSON format string isn’t broken when injected in the CLI.

The second option is to use Python API for Google Cloud Scheduler. Actually, there are a number of APIs supporting different programming languages since the API is built on top of the language-neutral gRPC/Protocol buffer. Here we only demonstrate the usage in Python.
There are three main differences compared to gcloud command. First, the message should be encoded in utf-8. This makes sure the message is encoded in bytes, and data parameter in PubsubTarget requires the message to be bytes. Second, the name of Pub/Sub topic should follow the "projects/<PROJECT-ID>/topics/<TOPIC-NAME>" format. Third, the Scheduler Job name should follow the "projects/<PROJECT-ID>/locations/<REGION-ID>/jobs/<JOB-NAME>" format. With these differences in mind, the code above should be straight-forward to understand.
For further details about the Python API, please check out RPC specification and the official document on Python API. Also, you can find a complete demonstration of what is covered in this notebook.
Cost
For this post, the costing only stems from Vertex AI because the rest of the components like Pub/Sub, Cloud Functions have very minimal usage. Each pipeline execution run on Vertex AI costs $0.03. For training the model, we chose a n1-standard-4 machine type whose price is $0.19 per hour and we did not use GPUs. So, as per our estimates, the upper bound of the costs incurred should not be more than $5.
In any case, you should use this GCP Price Calculator to get a better understanding of how your costing might come up after consuming the GCP services.
Conclusion
In this two-part blog post, we covered how we can treat model training as a CI/CD system. We covered various tools that are needed in order to accomplish that especially in the context of GCP. We hope you gained some insights as to why this approach might be beneficial when you are operating at scale. But this is only the tip of an iceberg. With tools like Vertex AI the possibilities are practically endless, and we encourage you to implement your own workflows on Vertex AI.
Acknowledgements
We are grateful to the ML-GDE program that provided GCP credits for supporting our experiments. We sincerely thank Karl Weinmeister of Google for his help with the review.




