7 Technical Takeaways from Using Gemini to Generate Code Samples at Scale

Nim Jayawardena
Senior Developer Relations Engineer
Adam Ross
Staff Developer Relations Engineer
Using Generative AI to write code is a well-known task, but relying on it to produce production-ready educational content is a different challenge. When we started using Gemini to assist with our work to expand the breadth of resources available to explain Google Cloud products, we realized we needed something more than just existing, general purpose GenAI-powered apps and tools; we needed a specialized system tailored to our use case.
The problem we were solving
Google Cloud has over a hundred products. Each product has its own unique set of resources that you can create, manipulate, and query using client libraries for languages like JavaScript, Python, Go, Java, and more. Our team at Google works on the sample code that teaches developers how to use those client libraries.
As an example, we have a sample that demonstrates how to list Google Cloud Storage “folder” resources using the @google-cloud/storage-control Node.js client library:
In recent years, we have been leveraging GenAI — no surprise, I’m sure — to help us develop these samples. However, in late 2024, we started taking a more systematic approach, and developed a specialized set of tools to help our team rapidly produce high quality samples. These tools consist of a set of deterministic automations and AI workflows, leveraging Gemini on Vertex AI and Genkit (an open-source framework for GenAI tool development).
This blog post first outlines the architecture of the sample-generating system and then shares 7 technical takeaways from the development process.
Samples Generation Architecture
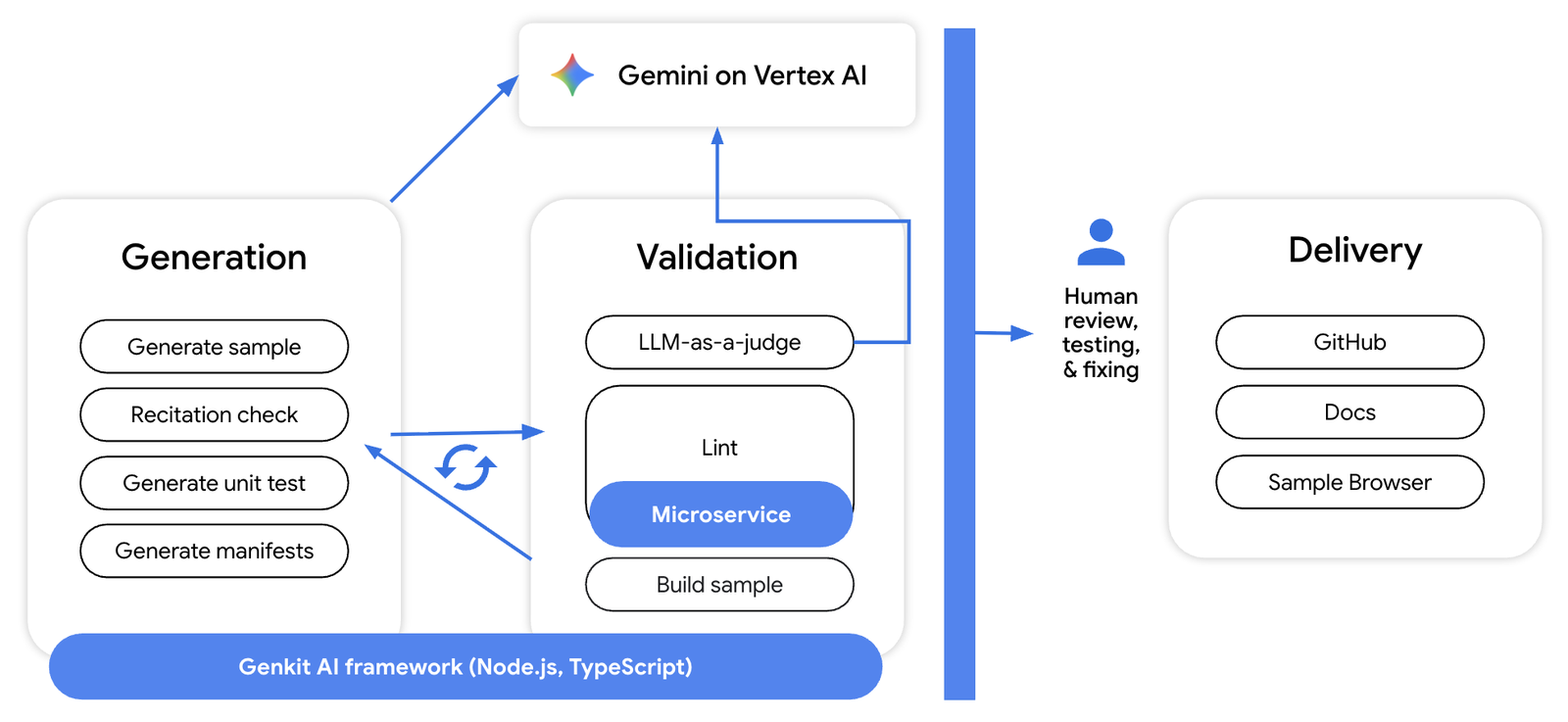
This system is comprised of the following subsystems:
- Generation: This subsystem uses Gemini to create the sample file and other necessary artifacts such as unit tests and dependency manifests (for example package.json or requirements.txt).
- Validation: Generated code is evaluated by the validation subsystem using a mix of "LLM-as-a-judge" and deterministic tools (like linters) to score the code on categories like cloud style and language-specific best practices. The resulting feedback is then sent back to the generation system to refine the sample.
- Delivery: The generated samples (and associated artifacts such as unit tests) are human-reviewed, tested, and published to a GitHub repository, the sample browser, and other docs.cloud.google.com pages.
With the architecture outlined, here are the 7 technical takeaways we gathered from the development process.
7 Technical Takeaways
These learnings are a practical roadmap for building and scaling production-ready generative AI systems, moving beyond basic prompt engineering.
Takeaway 1: Decompose
The problem we were initially throwing at Gemini was too big of a problem.
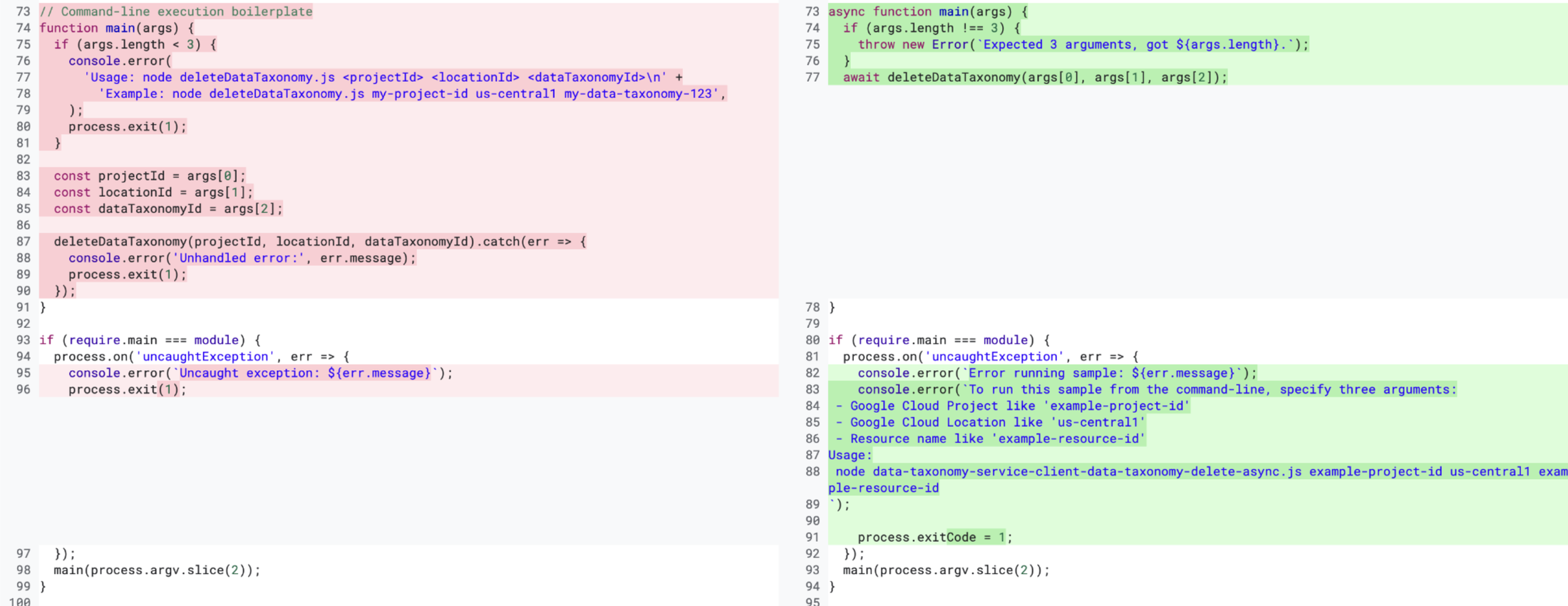
Each sample file is about 50-100 lines long. Early versions of our system expected Gemini to generate most of the file contents via a single prompt. However, we found that this was too big of a problem for Gemini (2.5), especially since our use case is very particular about each line of code. There were many ways in which Gemini deviated from our instructions. In the image below, the code on the left contains some code (specifically, about 20 lines of code) that Gemini generated, and the code on the right contains what we wanted those lines of code to actually look like. You can see many deltas (or differences) between the two chunks of code, such as an unwanted comment and the unwanted process.exit() call.
It was clear that we have to break down the problem into smaller subproblems. We had to decompose. For us, this meant breaking down the sample file into multiple parts. A sample file consists of the:
-
snippet, which is the educational part of the sample file that helps developers
-
CLI logic, which allows users to invoke the sample file using command-line interfaces
Breaking down the sample into these meaningful parts and then devoting separate generation prompts for each part significantly reduced LLM hallucinations and deviations from our instructions.
Takeaway 2: Embrace determinism
If a problem you encounter can easily be solved deterministically, solve it deterministically.
At times, it was easy to drift into a mode of tunnel vision where Gemini was the first tool we would think of when solving a particular problem we encountered. It was sometimes easy to forget the broader goal — to adopt automation, not necessarily to adopt LLMs. It was easy to forget that there are existing, proven deterministic ways to solve many of the problems we encountered.
Today, there are still many things our systems do deterministically such as prepending Apache license headers to files, generating dependency manifests (such as package.json files), auto-fixing lint related issues in LLM-generated code, and even generating lint-related feedback to send back to Gemini.
Takeaway 3: Be specific in your prompts
Be specific in your prompts, and make the implicit explicit. Yes, this is prompt engineering 101. But it cannot go overstated.
Being specific was especially important to us because — unlike most other types of code that developers write — sample code:
- Has a large audience, many of whom may be new to programming.
- Exists for educational purposes. The primary audience is humans — not the machines the code runs on.
- Must be consistent across different products. It should feel like the same developer wrote each sample.
So we need to be intentional about each and every line that a user might read.
We had to be explicit about dozens of different rules in our prompts. For instance, even though our one-shot example sample doesn’t set a default value for the “projectId” parameter in our samples, Gemini did. We had to explicitly instruct Gemini not to do so.
Being specific in our prompts also meant:
-
We had to shift left some of the instructions that were embedded in the validation system’s feedback. In other words, early versions of our initial generation prompt were depriving the model of crucial instructions that the model would later learn through feedback from the validation system.
-
We, as humans, had to deepen our own expertise on the types of samples we were generating. Essentially, we had to answer questions about samples that we hadn’t previously answered systematically as a team before. We arrived at a consensus on more than a hundred different design decisions about our samples.
Takeaway 4: Evaluate your evaluator
Generally speaking, you can trust an evaluation system more than you can trust a generation system, but you must still carefully evaluate your evaluation system.
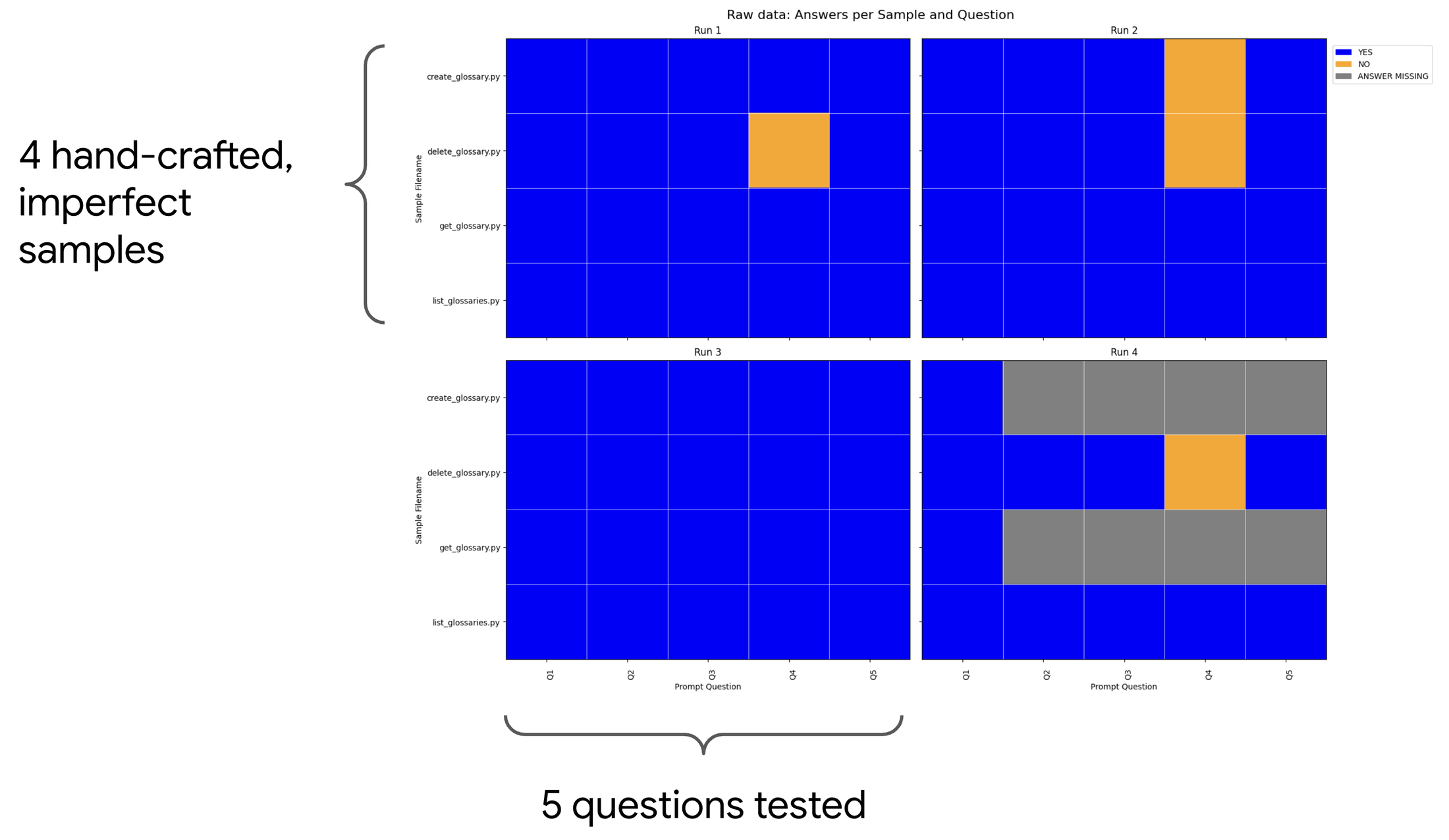
The generator-evaluator model works well because — similar to us, humans — LLMs are generally better at evaluating content than they are at creating the content to be evaluated. However, we wanted to be very confident with our evaluation system (or validation system), so we compared Gemini’s answers to some questions (from our LLM-as-a-judge evaluation prompts) against manually crafted datasets. We handcrafted a set of imperfect samples and the associated correct answers for a subset of our LLM-as-a-judge questions. In the diagram below, you can see 5 questions being evaluated across the 4 imperfect samples. The yellow (lighter) squares represent questions that Gemini didn’t answer correctly. We were able to identify “flaky” questions — questions LLMs cannot answer reliably. This process allowed us to discard these “flaky” questions and refine our evaluation prompts overall.
Takeaway 5: Scale everything else too
Ensure that non-LLM aspects of your system can scale too.
Unlike chat bots and code autocompletion, our use case doesn’t require immediate feedback from Gemini. We had the luxury of waiting a minute or so for a single sample, validation feedback, and its associated artifacts such as unit tests to complete generating. On top of that, Gemini kept costs low for our use case — even amidst the hundreds of samples we generated. So the LLM-related aspects of our system scaled well.
However, the tail end of our process didn’t grant us the same luck. Getting samples ready to be published took about 5-15 minutes per sample, our process became our biggest bottleneck as it involves human review of each sample and end-to-end testing.
Takeaway 6: End-to-end test the final output
If the code doesn't work, it's not publishable.
So it was important for us to end-to-end test the samples we were publishing. This is perhaps less of a takeaway and more of a philosophical consensus that we arrived at as a team.
The code we publish is designed to be run by our users. If we can't run it ourselves, in a situation similar to our users, then we can't deliver samples that are known to work for our users. Since day 1, our handwritten samples have been end-to-end tested before being published — either manually or programmatically. Altering the way in which we produce our samples should not lower our sample quality.
DORA describes this “trust but verify” approach as a sign of “mature AI adoption”. Our rigorous end-to-end testing isn't just for us, it's essential for maintaining the trust of developers who rely on our samples.
Takeaway 7: Do excellent engineering
Apply established engineering best practices, and everything else will follow.
If you really think about it, many of the takeaways we’ve presented above aren’t necessarily unique to the world of using LLMs at scale to generate content and code. Many of the positively impactful engineering decisions we made while building out these systems have nothing to do with LLMs at all and aren’t mentioned above in our takeaways.
Conclusion
In the journey of generating high-quality, educational code samples at scale, we learned that success hinges on more than just powerful LLMs. While Gemini and Genkit provided the necessary generative power, the true breakthrough came from building a specialized, end-to-end system. Our seven takeaways—from decomposing the problem and embracing determinism to end-to-end testing and scaling the entire pipeline—show how we successfully built a reliable, scalable generation system that combines LLMs with established engineering practices.



