Master Generative AI Evaluation: From Single Prompts to Complex Agents
Smitha Kolan
Senior Developer Relations
Building Generative AI applications has become accessible to everyone, but moving those applications from a prototype to a production-ready system requires one critical step: Evaluation.
How do you know if your LLM is safe? How do you ensure your RAG system isn't hallucinating? How do you test an agent that generates SQL queries on the fly?
At its core, GenAI Evaluation is about using data and metrics to measure the quality, safety, and helpfulness of your system's responses. It moves you away from "vibes-based" testing (just looking at the output) to a rigorous, metrics-driven approach using tools like Vertex AI Evaluation and the Agent Development Kit (ADK).
To guide you through this journey, we have released four hands-on labs that take you from the basics of prompt testing to complex, data-driven agent assessment.
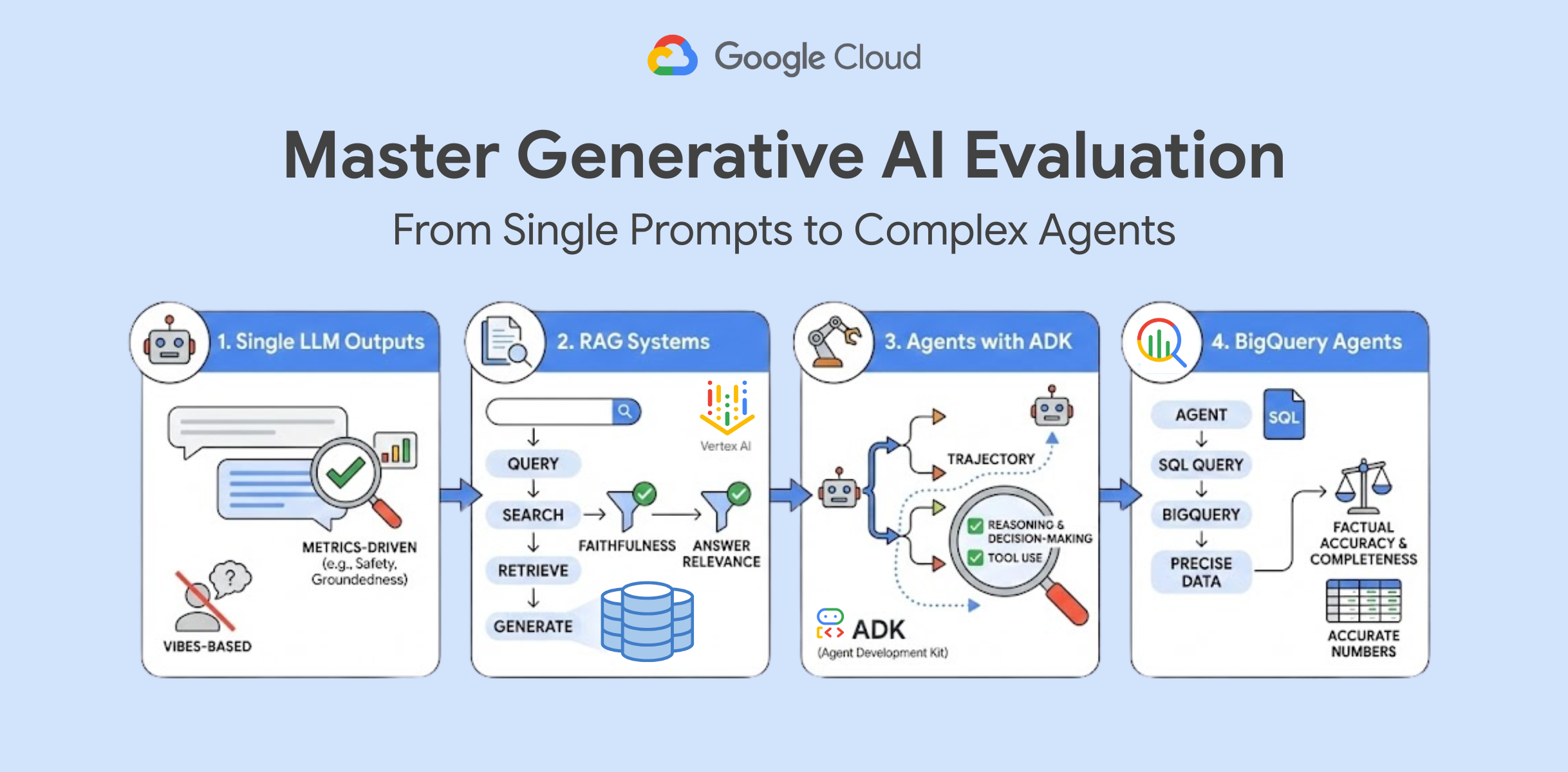
Evaluating Single LLM Outputs
Before you build complex systems, you must understand how to evaluate a single prompt and its response. This lab introduces you to GenAI Evaluation, a service that helps you automate the evaluation of your model's outputs.
You will learn how to define metrics, such as safety, groundedness, and instruction following. You will also learn how to run evaluation tasks against a dataset. This is the foundational step for any production-ready AI application.
Evaluate RAG Systems with Vertex AI
Retrieval Augmented Generation (RAG) is a powerful pattern, but it introduces new failure points: did the search fail to find the document, or did the LLM fail to summarize it?
This lab takes you deeper into the evaluation lifecycle. You will learn how to verify "Faithfulness" (did the answer come from the context?) and "Answer Relevance" (did it actually answer the user's question?). You will pinpoint exactly where your RAG pipeline needs improvement.
Evaluating Agents with ADK
Agents are dynamic; they choose tools and plan steps differently based on the input. This makes them harder to test than standard prompts. You aren't just grading the final answer; you are grading the trajectory, which is the path the agent took to get there.
This lab focuses on using the Agent Development Kit (ADK) to trace and evaluate agent decisions. You will learn how to define specific evaluation criteria for your agent's reasoning process and how to visualize the results to ensure your agent is using its tools correctly.
Build and Evaluate BigQuery Agents
When an agent interacts with data, precision is paramount. A SQL-generating agent must write syntactically correct queries and retrieve accurate numbers. A hallucination here doesn't just look bad, it might lead to bad business decisions.
In this advanced lab, you will build an agent capable of querying BigQuery and then use the GenAI Eval Service to verify the results. You will learn to measure Factual Accuracy and Completeness, ensuring your agent provides the exact data requested without omission.
Trust Your AI in Production
Ready to make your AI applications production-grade? Start evaluating your model’s outputs or the trajectory taken by your agents with these codelabs:
From Prototype to Production
These labs are part of the AI Evaluation module in our official Production-Ready AI with Google Cloud program. Explore the full curriculum for more content that will help you bridge the gap from a promising prototype to a production-grade AI application.



