How GKE & Anthos Container-Aware Load balancing Increases Applications’ Reliability
Marwan Al shawi
Partner Customer Engineer, Google Cloud - Dubai
Abdel Sghiouar
Senior Cloud Developer Advocate
Reliability of a system can be measured based on several factors, including, but not limited to, performance, resilience and security. Nevertheless, resiliency is one of the key factors. For more information on how to architect and operate reliable services on a cloud platform, refer to the reliability category of Google Cloud Architecture Framework. This blog focuses on the optimization of network connectivity performance to containers hosted on Google Kubernetes Engine (GKE), as well as optimized resiliency of containerized applications with the direct visibility of a container's health from an external load balancer.
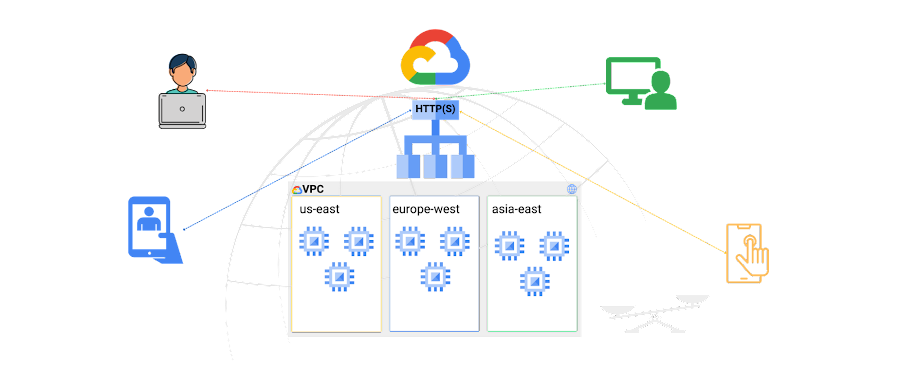
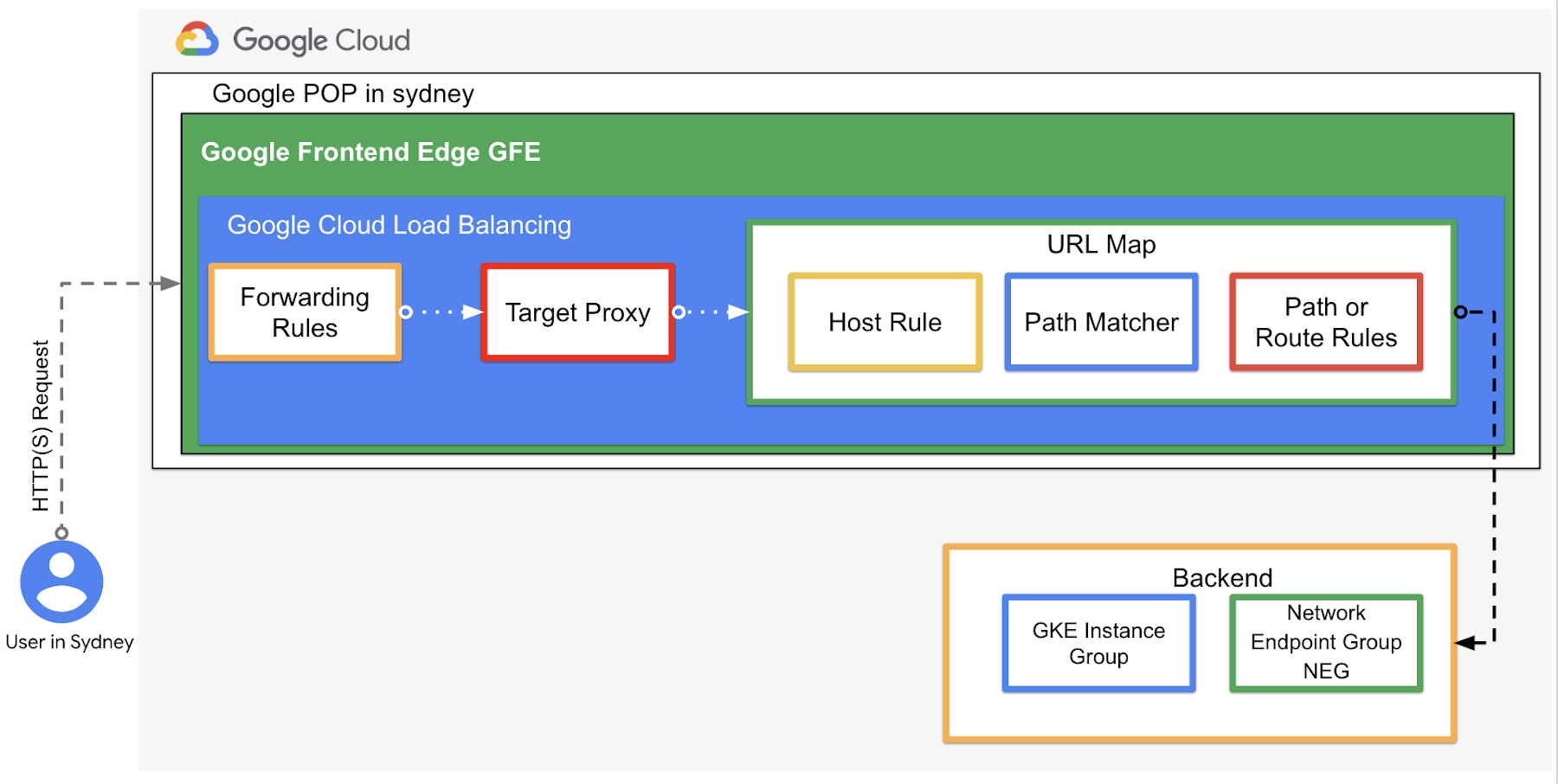
In a previous blog, we discussed the architecture components of Google Cloud HTTP(s) External Load Balancer, illustrated in Figure 1 below. This blog dives deeper into load balancing using a GKE cluster as the backend.
GKE cluster overview
This blog assumes that you have a basic understanding of Kubernetes architecture components, specifically GKE cluster architecture. Still, a brief overview of Kubernetes networking on Google Cloud will be discussed first.
Having fully functional nodes and Pods has zero value without the ability to connect to the hosted applications as well as interconnect application tiers among each other. That’s why networking is a critical element when it comes to designing and building containerized applications with Kubernetes clusters. This blog will cover briefly how networking works within a GKE cluster and will then focus on the connectivity to external networks and users.
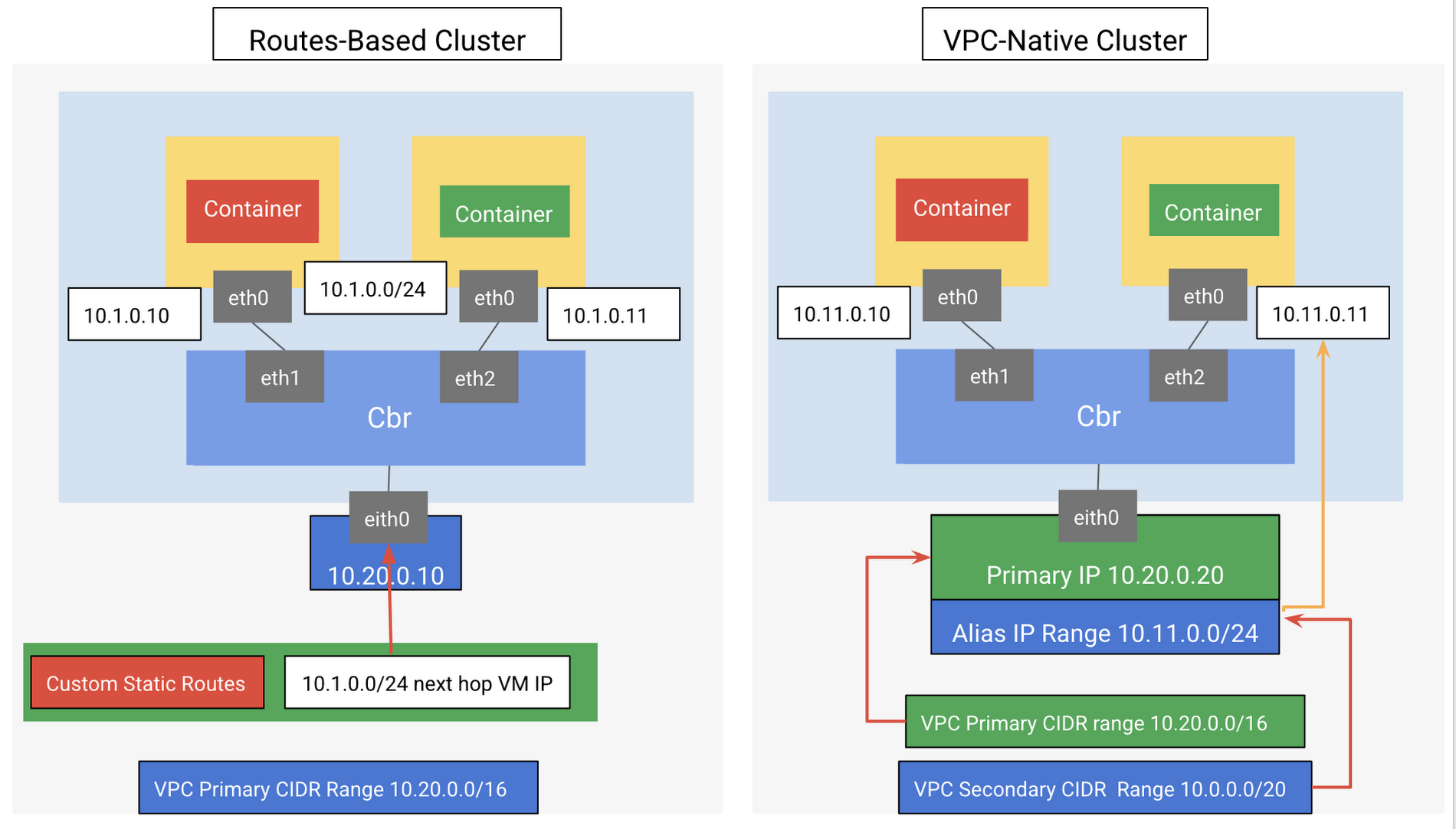
A GKE worker node is a GCE VM which commonly runs Linux (ideally Container-Optimized OS). This VM has its own root network namespace (root netns, eth0) used to connect the VM to the rest of the GCP network in a project. Similarly, each Pod has its own network namespace (eth0) from its perspective has its own root netns, although in reality it is from the underlying host (worker node). Each Pod in a worker node VM will have its eth0 connected to the worker node root netns ethxx. As illustrated in Figure 2 below, the VM (Node) network interface eth0 is attached to a custom bridge (cbr) and the bridged Pod(s) private IP range inside the is on a completely different network than the VM node eth0 IP.
GKE Node networking
Each node has at least one IP address assigned from the cluster's Virtual Private Cloud (VPC) network. Typically this IP is used to connect the node/VM to the VPC network in which it is used as the transport for all the communication with the GKE cluster control and data planes.
Each node also has a CIDR range that can be allocated in different ways to the Pods as illustrated in Figure 2 below. Each Pod uses a single IP address either taken from the Pod address range of the host node or from the assigned alias IP address ranges as shown in Figure 2. In either case, the Pod IP is ephemeral, as each time a pod starts or stops, the IP of a Pod changes.
From a packet routing point of view, when a packet exits and enters the host node to communicate with another Pod on another node or external network, it has to pass through the VPC network as well as to be routed and forwarded by the Pod’s host node. Such communications require some IP routing setup. GKE can automatically set up the required routing for you. When deploying your GKE VPC network, you can deploy it as either routes-based or VPC-native cluster. It's recommended to use a VPC-native cluster because it uses alias IP address ranges on GKE nodes where Pod routing is handled by the VPC itself and there is no need to add manual routes to reach Pods IP range. VPC-native clusters also scale more easily than routes-based clusters and are more secure as you don’t need to disable anti-spoof protection for the Pod hosting VMs. Also, it is a prerequisite when using Network Endpoint Groups with load balancing as we will discuss later in this blog. In addition, VPC-native traffic routing is enabled by default with GKE Autopilot clusters.
Ever-changing clusters
A Kubernetes cluster is a living dynamic system, where Pods can be torn down and brought up manually and dynamically due to several factors, such as: scale up and down events, Pod crashes, rolling updates, worker node restart, image updates etc. The main issue here with regard to the Pods’ IP communications, is due to the ephemeral nature of a Pod, where Pod’s IP is not static and can change as a result to any of the aforementioned events above. This is a communication issue for both Pod to Pod and Pod to outside networks or users. Kubernetes addresses this by using objects known as Kubernetes Services, which act like a service abstraction that automatically maps a static virtual IP (VIP) to a group of Pods.
On each Kubernetes node there is a component (typically running as a DaemonSet) which takes care of network programming on the node. On GKE with Dataplane V2, this component is called anetd and is responsible for interpreting Kubernetes objects and programming the desired network topologies in eBPF. Some clusters might still use kube-proxy with iptables. We recommend creating clusters with Dataplane V2 enabled.
GKE offers the ability to expose applications as GKE Services in several ways to support different use cases. The abstraction provided by GKE services can be either deployed in the IPTables rules of the cluster nodes, depending on the type of the Service, or it can be provided by either Network Load Balancing (the default, when load balancing service type is used) or HTTP(S) Load Balancing (with the use of Ingress controller triggered by Ingress Object) also can be created by using Kubernetes Gateway API powered by GKE Gateway controller that reside out of band from traffic and manage various data planes that process traffic. Both GKE Ingress controller and GKE Service controller offer the ability to deploy Google Cloud load balancers on behalf of GKE users. Technically, it is the same as the VM load balancing infrastructure, except that the lifecycle is fully automated and controlled by GKE.
Kubernetes Ingress
In Kubernetes, an Ingress object defines rules for routing HTTP(S) traffic to applications running in a cluster. When you create an Ingress object, the Ingress controller creates a Cloud HTTP(S) External (Or optionally Internal) Load Balancer. Also the Ingress object is associated with one or more Service objects of type NodePort, each of which is associated with a set of Pods.
In turn, the backends for each backend service are associated with either Instance Groups or network endpoint groups (NEGs) when using container-native load balancing on GKE..
First let's analyze the life of a packet when HTTP(s) load balancer is used along with the backend service associated with the instance group.
One of the key design considerations here is that the Load balancer is node or VM aware only, while from Containerized application architecture point of view, it is almost always the mapping is not of VM-to-Pod is not 1:1. Therefore this may introduce an imbalanced load distribution issue here. Consequently, As illustrated in figure XX below, if traffic evenly distributed between the two available nodes (50:50) with Pods part of the targeted Service, the Pod on the left node will handle 50% of the traffic while each Pod hosted by the right node will receive about 25%. GKE Service and IPTables here deals with the distribution of the traffic to help considering all the Pods part of the specific Service across all nodes.
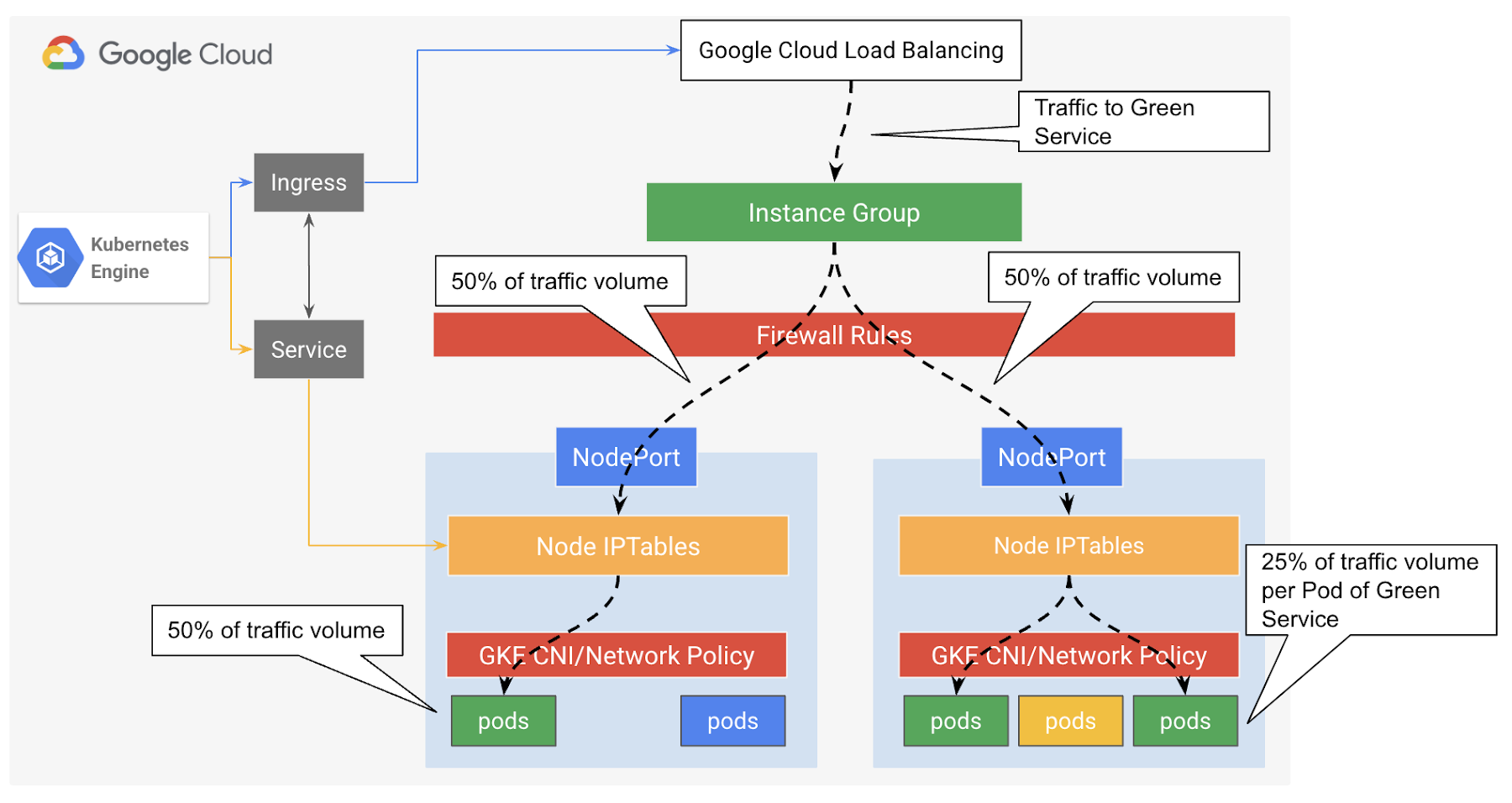
The load balancer sends a request to a node's IP address at the NodePort. After the request reaches the node, the node uses its IPTables NAT table to choose a Pod. kube-proxy manages the IPTables rules on the node
As illustrated in the Figure 4 below, after the load balancer sends traffic to a node, the traffic might get forwarded to a Pod on a different node, because the backend Service (IPTables) typically will randomly pick a Pod that potentially resides in a different node. Which will require extra network hops for the ingress and return traffic. As a result, this will create what is commonly known as “Traffic Trombone”. This potentially adds latency to the end to end data path.
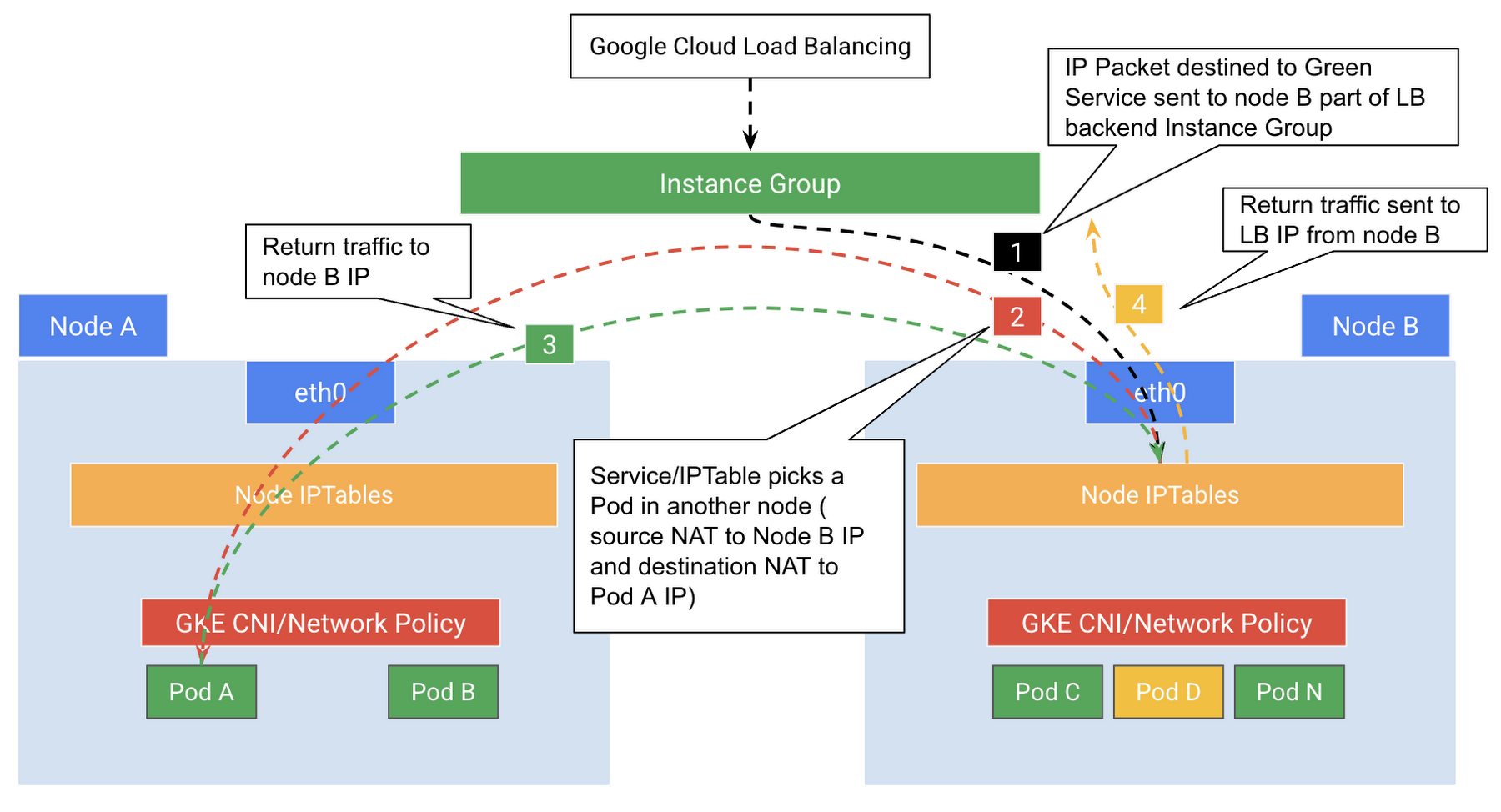
Note: in Figure 4 above there are source and destination NAT has been done. The destination NAT, is required to send traffic to the selected Pod, while the source NAT, is required to ensure return traffic will come back to the same originally selected node by the load balancer.
If you want to avoid the extra hops, you can specify that traffic must go to a Pod that is on the same node that initially receives the traffic. However this is not going to overcome the traffic imbalance issue mentioned above. Also this only works for TCP load balancers created via Service of type LoadBalancer.
Practically, this imbalance issue might not always be a big problem if there is a well balanced ratio of VM:Pod and the added latency is not a problem. However, if the solution scales and applications might be sensitive to latency, this could impact the overall performance of the hosted applications. Not to mention the load balancer health checks can’t check Pods since it's only node/VM aware.
Network Endpoint Groups
As mentioned earlier in this blog, there is another option to associate load balancer backend nodes by using network endpoint groups (NEGs), which is a grouping object of network endpoints or services, where each network endpoint can be targeted by its IP address or a pair of IP:Port. The IP:Port: provides the ability to resolve to an alias IP address on a NIC of Google Cloud VM's that can be a Pod IP address in VPC-native clusters.
Therefore, with NEGs the Google Cloud HTTP(s) External Load Balancer provides the ability to perfrom ‘container native load balancing’, in which the load balancer will be container aware, which means the load balancer will target containers directly and not the node/VM. This native container load balancing capability powered by VPC-native cluster that uses alias IP range(s), offers more efficient load distribution, and more accurate health checks (container level visibility), without the need for multiple NATing or additional network hops. From external clients’ point of view, this will provide better user experience, due to the optimized data path as there is no proxy or NAT in between which reduces the possible latency of multiple hopes packets’ forwarding. With this approach, the GKE Services for a container-native load balancer acts mainly as endpoint grouping object ( service selector) while the packet routing will be direct from the load balancer to the backend NEG then to the endpoints/Pod, in which the kube-proxy/IPTables of the node that hosts the target Pod is not involved in this process, as illustrated in the Figure 5 below. In Google Cloud there are different types of NEGs that can be used for different use cases, in this blog we are referring to the zonal NEG.
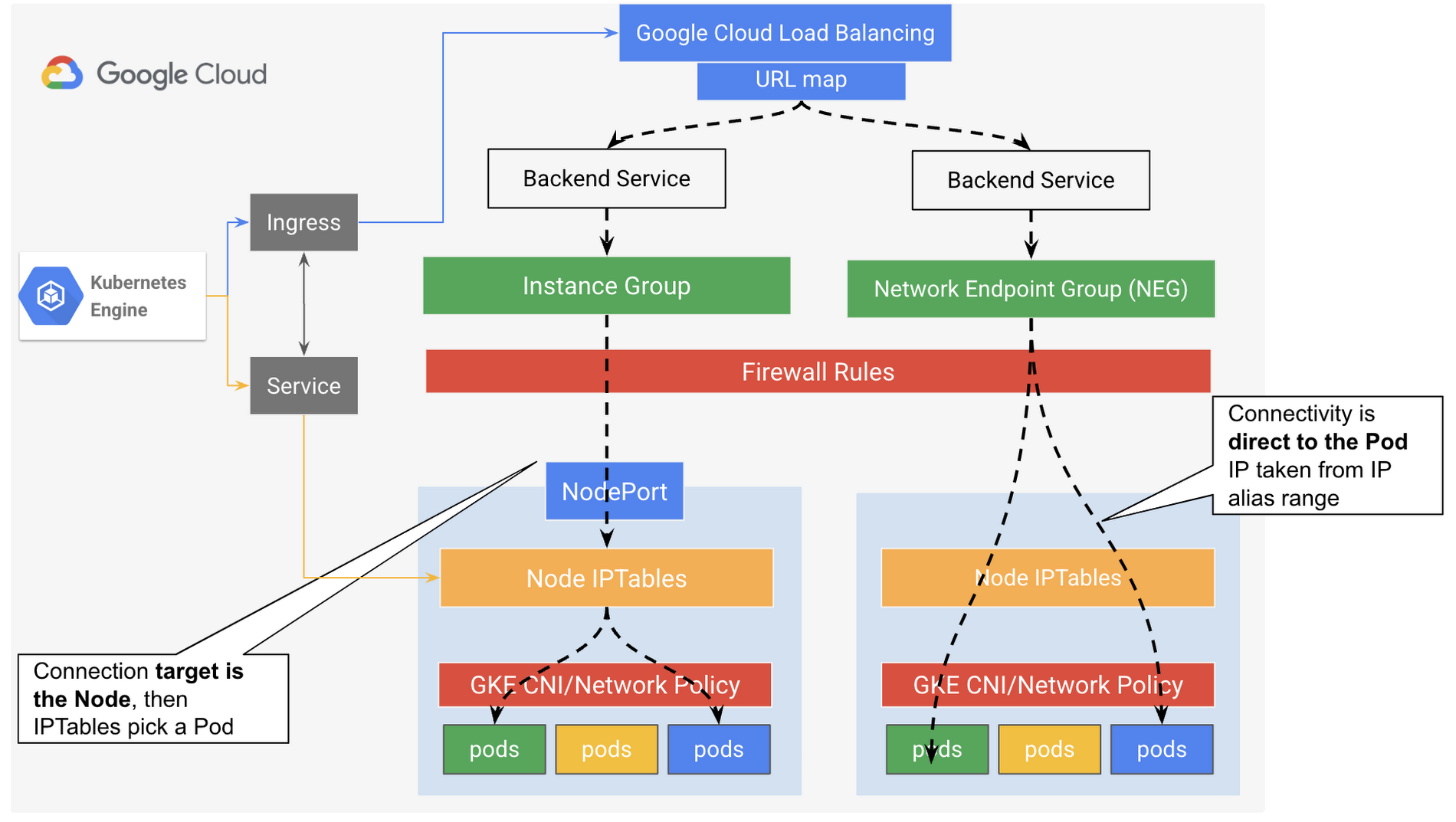
In Figure 5 above, the Backend Services associated with the load balancer URL map, helps to define how Cloud Load Balancing distributes traffic including steering traffic to the correct backends, which are instance groups or network endpoint groups (NEGs).
Similarly with Anthos registered clusters, you can deploy a Multi Cluster Ingress (MCI) controller for the external HTTP(S) load balancer to provide ingress for traffic coming from the internet across one or more clusters. Some enterprises consider more than one cluster in different Google Cloud regions to increase their overall solution or applications reliability by serving traffic to their application with minimum latency across different geographies, as well as increasing application’s availability. From the end user point of view it's a single DNS and IP of Google Cloud global external load balncer. When the MCI creates an external HTTP(S) load balancer in the Premium Tier. Client requests are served by Google frontends GFEs where the cluster that is closest to the client will be selected to reduce data path latency. MCI works using the same logic of GKE Ingress, described in this blog when using NEGs to track Pod endpoints dynamically so the Google load balancer can distribute traffic and send health checks directly to the Pods.
In summary
By optimizing data path latency, adding visibility at the Pods level to the load balancer to distribute load more efficiently, and using health checks to react faster to any Pod responsiveness issues, we are making the solution more performant and resilient. Collectively these optimizations lead to a more reliable containerized architecture. If you'd like to try out some of this yourself, get going with the container-native load balancing guide. You can also check the GKE Networking Recipes repository for more detailed examples.