Distributed training and Hyperparameter tuning with TensorFlow on Vertex AI
Nikita Namjoshi
Developer Advocate
The values you select for your model’s hyperparameters can make all the difference. If you’re only trying to tune a handful of hyperparameters, you might be able to run experiments manually. However, with deep learning models where you’re often juggling hyperparameters for the architecture, the optimizer, and finding the best batch size and learning rate, automating these experiments at scale quickly becomes a necessity.
In this article, we’ll walk through an example of how to run a hyperparameter tuning job with Vertex Training to discover optimal hyperparameter values for an ML model. To speed up the training process, we’ll also leverage the tf.distribute Python module to distribute code across multiple GPUs on a single machine. All of the code for this tutorial can be found in this notebook.
To use the hyperparameter tuning service, you’ll need to define the hyperparameters you want to tune in your training application code as well as your custom training job request. In your training application code, you’ll define a command-line argument for each hyperparameter, and use the value passed in those arguments to set the corresponding hyperparameter in your code. You’ll also need to report the metric you want to optimize to Vertex AI using the cloudml-hypertune Python package.
The example provided uses TensorFlow, but you can use Vertex Training with a model written in PyTorch, XGBoost, or any other framework of your choice.
Using the tf.distribute.Strategy API
If you have a single GPU, TensorFlow will use this accelerator to speed up model training with no extra work on your part. However, if you want to get an additional boost from using multiple GPUs on a single machine or multiple machines (each with potentially multiple GPUs), then you'll need to use tf.distribute, which is TensorFlow's module for running a computation across multiple devices. The simplest way to get started with distributed training is a single machine with multiple GPU devices. A TensorFlow distribution strategy from the tf.distribute.Strategy API will manage the coordination of data distribution and gradient updates across all GPUs.
tf.distribute.MirroredStrategy is a synchronous data parallelism strategy that you can use with only a few code changes. This strategy creates a copy of the model on each GPU on your machine. The subsequent gradient updates will happen in a synchronous manner. This means that each worker device computes the forward and backward passes through the model on a different slice of the input data. The computed gradients from each of these slices are then aggregated across all of the GPUs and reduced in a process known as all-reduce. The optimizer then performs the parameter updates with these reduced gradients, thereby keeping the devices in sync.
The first step in using the tf.distribute.Strategy API is to create the strategy object.
strategy = tf.distribute.MirroredStrategy()
MirroredStrategy which variables to mirror across your GPU devices.Lastly, you’ll scale your batch size by the number of GPUs. When you do distributed training with the tf.distribute.Strategy API and tf.data, the batch size now refers to the global batch size. In other words, if you pass a batch size of 16, and you have two GPUs, then each machine will process 8 examples per step. In this case, 16 is known as the global batch size, and 8 as the per replica batch size. To make the most out of your GPUs, you’ll want to scale the batch size by the number of replicas.
GLOBAL_BATCH_SIZE = PER_REPLICA_BATCH_SIZE * strategy.num_replicas_in_sync
Note that distributing the code is optional. You can still use the hyperparameter tuning service by following the steps in the next section even if you do not want to use multiple GPUs.
Update training code for hyperparameter tuning
To use hyperparameter tuning with Vertex Training, there are two changes you’ll need to make to your training code.
First, you’ll need to define a command-line argument in your main training module for each hyperparameter you want to tune. You’ll then use the value passed in those arguments to set the corresponding hyperparameter in your application's code.
Let’s say we wanted to tune the learning rate, the optimizer momentum value, and the number of neurons in the model’s final hidden layer. You can use argparse to parse the command line arguments as shown in the function below.You can pick whatever names you like for these arguments, but you need to use the value passed in those arguments to set the corresponding hyperparameter in your application's code. For example, your optimizer might look like:
Now that we know what hyperparameters we want to tune, we need to determine the metric to optimize. After the hyperparameter tuning service runs multiple trials, the hyperparameter values we’ll pick for our model will be the combination that maximizes (or minimizes) the chosen metric.
We can report this metric with the help of the cloudml-hypertune library, which you can use with any framework.
import hypertune
In TensorFlow, the keras model.fit method returns a History object.
The History.history attribute is a record of training loss values and metrics values at successive epochs. If you pass validation data to model.fit the History.history attribute will include validation loss and metrics values as well.
For example, if you trained a model for three epochs with validation data and provided accuracy as a metric, the History.history attribute would look similar to the following dictionary.
To select the values for learning rate, momentum, and number of units that maximize the validation accuracy, we’ll define our metric as the last entry (or NUM_EPOCS - 1) of the 'val_accuracy' list.
Then, we pass this metric to an instance of HyperTune, which will report the value to Vertex AI at the end of each training run.
And that’s it! With these two easy steps, your training application is ready.
Launch hyperparameter tuning Job
Once you’ve modified your training application code, you can launch the hyperparameter tuning job. This example demonstrates how to launch the job with the Python SDK, but you can also use the Cloud console UI.
You’ll need to make sure that your training application code is packaged up as a custom container. If you’re unfamiliar with how to do that, refer to this tutorial for detailed instructions.
In a notebook, create a new Python 3 notebook from the launcher.

In your notebook, run the following in a cell to install the Vertex AI SDK. Once the cell finishes, restart the kernel.
!pip3 install google-cloud-aiplatform --upgrade --user
After restarting the kernel, import the SDK:
To launch the hyperparameter tuning job, you need to first define the worker_pool_specs, which specifies the machine type and Docker image. The following spec defines one machine with two NVIDIA T4 Tensor Core GPUs.
Next, define the parameter_spec, which is a dictionary specifying the parameters you want to optimize. The dictionary key is the string you assigned to the command line argument for each hyperparameter, and the dictionary value is the parameter specification.
For each hyperparameter, you need to define the Type as well as the bounds for the values that the tuning service will try. If you select the type Double or Integer, you’ll need to provide a minimum and maximum value. And if you select Categorical or Discrete you’ll need to provide the values. For the Double and Integer types, you’ll also need to provide the Scaling value. You can learn more about how to pick the best scale in this video.
The final spec to define is metric_spec, which is a dictionary representing the metric to optimize. The dictionary key is the hyperparameter_metric_tag that you set in your training application code, and the value is the optimization goal.
metric_spec={'accuracy':'maximize'}
Once the specs are defined, you’ll create a CustomJob, which is the common spec that will be used to run your job on each of the hyperparameter tuning trials.
You'll need to replace{YOUR_BUCKET}with a bucket in your project for staging.
Lastly, create and run the HyperparameterTuningJob.
There are a few arguments to note:
max_trial_count: You’ll need to put an upper bound on the number of trials the service will run. More trials generally leads to better results, but there will be a point of diminishing returns, after which additional trials have little or no effect on the metric you’re trying to optimize. It is a best practice to start with a smaller number of trials and get a sense of how impactful your chosen hyperparameters are before scaling up.parallel_trial_count: If you use parallel trials, the service provisions multiple training processing clusters. The worker pool spec that you specify when creating the job is used for each individual training cluster. Increasing the number of parallel trials reduces the amount of time the hyperparameter tuning job takes to run; however, it can reduce the effectiveness of the job overall. This is because the default tuning strategy uses results of previous trials to inform the assignment of values in subsequent trials.search_algorithm: You can set the search algorithm to grid, random, or default (None). Grid search will exhaustively search through the hyperparameters, but is not feasible in high-dimensional space. Random search samples the search space randomly. The downside of random search is that it doesn’t use information from prior experiments to select the next setting. The default option applies Bayesian optimization to search the space of possible hyperparameter values and is the recommended algorithm. If you want to learn more about the details of how this Bayesian optimization works, check out this blog.
Once the job kicks off, you’ll be able to track the status in the UI under the HYPERPARAMETER TUNING JOBS tab.
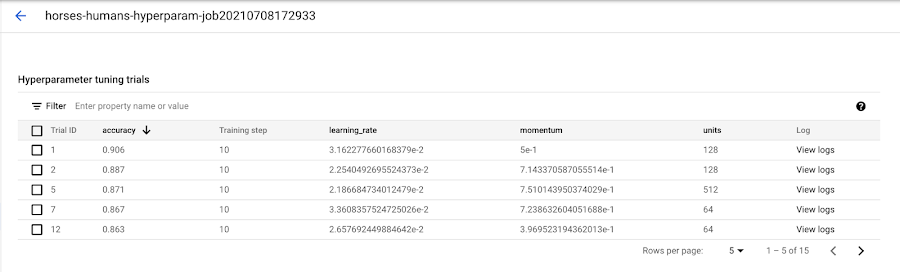
When it's finished, you'll be able to click on the job name and see the results of the tuning trials.
What’s next
You now know the basics of how to use hyperparameter tuning with Vertex Training. If you want to try out a working example from start to finish, you can take a look at this tutorial. Or if you’d like to learn about multi-worker training on Vertex, see this tutorial. It’s time to run some experiments of your own!




