Introducing LLM fine-tuning and evaluation in BigQuery
Vaibhav Sethi
Senior Product Manager
Eric Hao
Software Engineer
BigQuery allows you to analyze your data using a range of large language models (LLMs) hosted in Vertex AI including Gemini 1.0 Pro, Gemini 1.0 Pro Vision and text-bison. These models work well for several tasks such as text summarization, sentiment analysis, etc. using only prompt engineering. However, in some scenarios, additional customization via model fine-tuning is needed, such as when the expected behavior of the model is hard to concisely define in a prompt, or when prompts do not produce expected results consistently enough. Fine-tuning also helps the model learn specific response styles (e.g., terse or verbose), new behaviors (e.g., answering as a specific persona), or to update itself with new information.
Today, we are announcing support for customizing LLMs in BigQuery with supervised fine-tuning. Supervised fine-tuning via BigQuery uses a dataset which has examples of input text (the prompt) and the expected ideal output text (the label), and fine-tunes the model to mimic the behavior or task implied from these examples.Let’s see how this works.
Feature walkthrough
To illustrate model fine-tuning, let’s look at a classification problem using text data. We’ll use a medical transcription dataset and ask our model to classify a given transcript into one of 17 categories, e.g. ‘Allergy/Immunology’, ‘Dentistry’, ‘Cardiovascular/ Pulmonary’, etc.
Dataset
Our dataset is from mtsamples.com as provided on Kaggle. To fine-tune and evaluate our model, we first create an evaluation table and a training table in BigQuery using a subset of this data available in Cloud Storage as follows:
The training and evaluation dataset has an ‘input_text’ column that contains the transcript, and a ‘output_text’ column that contains the label, or ground truth.
Baseline performance of text-bison model
First, let’s establish a performance baseline for the text-bison model. You can create a remote text-bison model in BigQuery using a SQL statement like the one below. For more details on creating a connection and remote models refer to the documentation (1,2).
For inference on the model, we first construct a prompt by concatenating the task description for our model and the transcript from the tables we created. We then use the ML.GENERATE_TEXT function to get the output. While the model gets many classifications correct out of the box, it classifies some transcripts erroneously. Here’s a sample response where it classifies incorrectly.
In the above case the correct classification should have been ‘Cardiovascular/ Pulmonary’.
Metrics-based evaluation for base modelTo perform a more robust evaluation of the model’s performance, you can use BigQuery’s ML.EVALUATE function to compute metrics on how the model responses compare against the ideal responses from a test/eval dataset. You can do so as follows:
In the above code we provided an evaluation table as input and chose ‘classification‘ as the task type on which we evaluate the model. We left other inference parameters at their defaults but they can be modified for the evaluation.
The evaluation metrics that are returned are computed for each class (label). The results look like following:
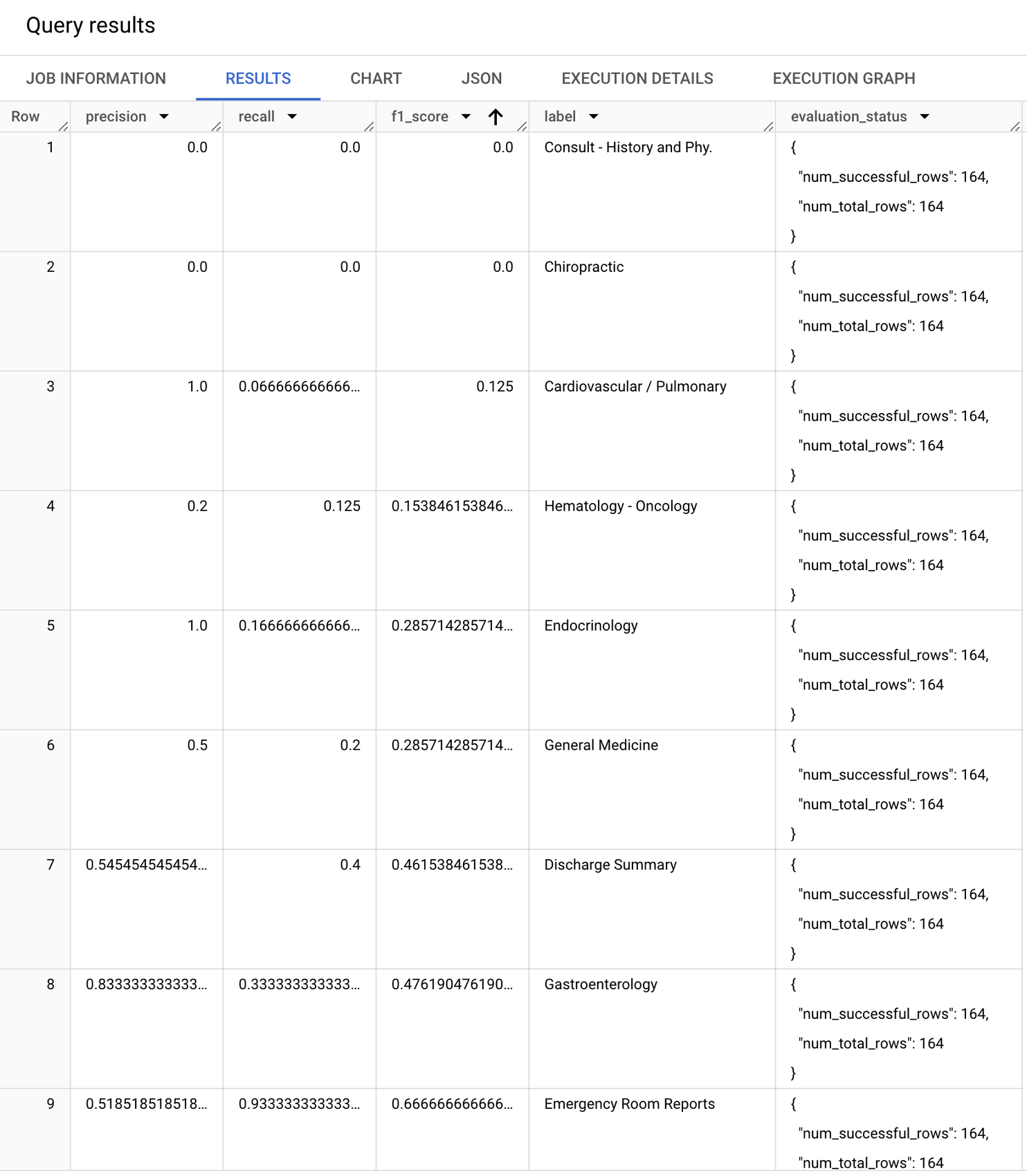
Focusing on the F1 score (harmonic mean of precision and recall), you can see that the model performance varies between classes. For example, the baseline model performs well for ‘Autopsy’, ‘Diets and Nutritions’, and ‘Dentistry’, but performs poorly for ‘Consult - History and Phy.’, ‘Chiropractic’, and ‘Cardiovascular / Pulmonary’ classes.
Now let’s fine-tune our model and see if we can improve on this baseline performance.
Creating a fine-tuned model
Creating a fine-tuned model in BigQuery is simple. You can perform fine-tuning by specifying the training data with ‘prompt’ and ‘label’ columns in it in the Create Model statement. We use the same prompt for fine-tuning that we used in the evaluation earlier. Create a fine-tuned model as follows:
The CONNECTION you use to create the fine-tuned model should have (a) Storage Object User and (b) Vertex AI Service Agent roles attached. In addition, your Compute Engine (GCE) default service account should have an editor access to the project. Refer to the documentation for guidance on working with BigQuery connections.
BigQuery performs model fine-tuning using a technique known as Low-Rank Adaptation (LoRA. LoRA tuning is a parameter efficient tuning (PET) method that freezes the pretrained model weights and injects trainable rank decomposition matrices into each layer of the Transformer architecture to reduce the number of trainable parameters. The model fine-tuning itself happens on a Vertex AI compute and you have the option to choose GPUs or TPUs as accelerators. You are billed by BigQuery for the data scanned or slots used, as well as by Vertex AI for the Vertex AI resources consumed. The fine-tuning job creates a new model endpoint that represents the learned weights. The Vertex AI inference charges you incur when querying the fine-tuned model are the same as for the baseline model.
This fine-tuning job may take a couple of hours to complete, varying based on training options such as ‘max_iterations’. Once completed, you can find the details of your fine-tuned model in the BigQuery UI, where you will see a different remote endpoint for the fine-tuned model.
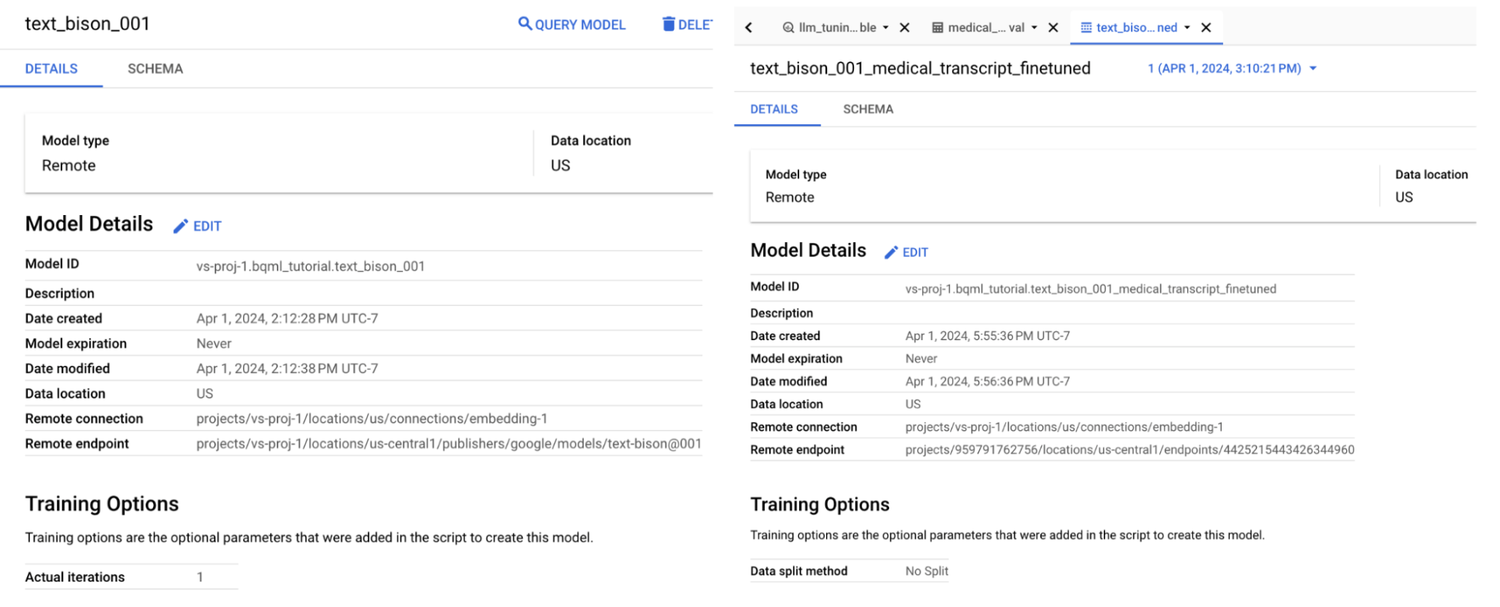
Endpoint for the baseline model vs a fine tuned model.
Currently, BigQuery supports fine-tuning of text-bison-001 and text-bison-002 models.
Evaluating performance of fine-tuned model
You can now generate predictions from the fine-tuned model using code such as following:
Let us look at the response to the sample prompt we evaluated earlier. Using the same prompt, the model now classifies the transcript as ‘Cardiovascular / Pulmonary’ — the correct response.
Metrics based evaluation for fine tuned model
Now, we will compute metrics on the fine-tuned model using the same evaluation data and the same prompt we previously used for evaluating the base model.
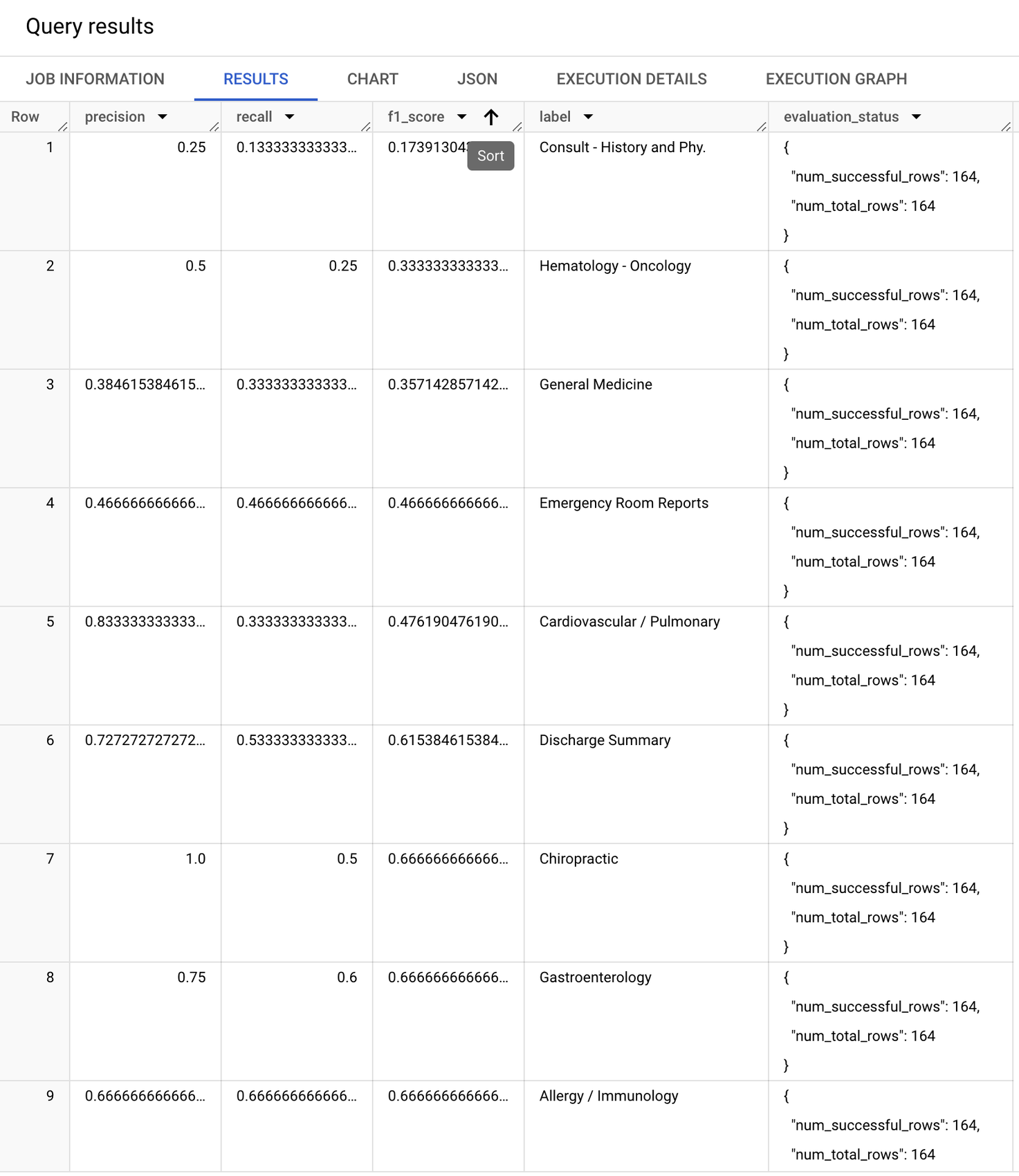
The metrics from the fine-tuned model are below. Even though the fine-tuning (training) dataset we used for this blog contained only 519 examples, we already see a marked improvement in performance. F1 scores on the labels, where the model had performed poorly earlier, have improved, with the “macro” F1 score (a simple average of F1 score across all labels) jumping from 0.54 to 0.66.
Ready for inference
The fine-tuned model can now be used for inference using the ML.GENERATE_TEXT function, which we used in the previous steps to get the sample responses. You don’t need to manage any additional infrastructure for your fine-tuned model and you are charged the same inference price as you would have incurred for the base model.
To try fine-tuning for text-bison models in BigQuery, check out the documentation. Have feedback or need fine-tuning support for additional models? Let us know at bqml-feedback@google.com>.
Special thanks to Tianxiang Gao for his contributions to this blog.

