Build a reinforcement learning recommendation application using Vertex AI
Kathy Yu
SWE Intern
Amy Wu
Software Engineer
Reinforcement learning (RL) is a form of machine learning whereby an agent takes actions in an environment to maximize a given objective (a reward) over this sequence of steps. Applications of RL include learning-based robotics, autonomous vehicles and content serving. The fundamental RL system includes many states, corresponding actions, and rewards to those actions. Translate that into a movie recommender system: The ‘state’ is the user, the ‘action’ is the movie to recommend to the user, and the ‘reward’ is the user rating of the movie. RL is a great framework for optimizing ML models, as mentioned by Spotify in the keynote in the Applied ML Summit 2021.
In this article, we’ll demonstrate an RL-based movie recommender system executed in Vertex AI and built with TF-Agents, a library for RL in TensorFlow. This demo has two parts: (1) a step-by-step guide leveraging Vertex Training, Hyperparameter Tuning, and Prediction services; (2) a MLOps guide to build end-to-end pipelines using Vertex Pipelines and other Vertex services.
TF-Agents meets Vertex AI
In reinforcement learning (RL), an agent takes a sequence of actions in a given environment according to some policy, with the goal of maximizing a given reward over this sequence of actions. TF-Agents is a powerful and flexible library enabling you to easily design, implement and test RL applications. It provides you with a comprehensive set of logical modules that support easy customization:
Policy: A mapping from an environment observation to an action or a distribution over actions. It is the artifact produced from training, and the equivalent of a “Model” in a supervised learning setup.
Action: A move or behavior that is outputted by some policy, and chosen and taken by an agent.
Agent: An entity that encapsulates an algorithm to use one or more policies to choose and take actions, and trains the policy.
Observations: A characterization of the environment state.
Environment: Definition of the RL problem to solve. At each time step, the environment generates an observation, bears the effect of the agent action, and then given the action taken and the observation, the environment responds with a reward as feedback.
A typical RL training loop looks like the following:

A typical process to build, evaluate, and deploy RL applications would be:
- Frame the problem: While this blog post introduces a movie recommendation system, you can use RL to solve a wide range of problems. For instance, you can easily solve a typical classification problem with RL, where you can frame predicted classes as actions. One example would be digit classification: observations are digit images, actions are 0-9 predictions and rewards indicate whether the predictions match the ground truth digits.
- Design and implement RL simulated experiments: We will go into detail on simulated training data and prediction requests in the end-to-end pipeline demo.
- Evaluate performance of the offline experiments.
- Launch end-to-end production pipeline by replacing the simulation constituents with real-world interactions.
Now that you know how we’ll build a movie recommendation system with RL, let’s look at how we can use Vertex AI to run our RL application in the cloud. We’ll use the following Vertex AI products:
- Vertex AI training to train a RL policy (the counterpart of a model in supervised learning) at scale
- Vertex AI hyperparameter tuning to find the best hyperparameters
- Vertex AI prediction to serve trained policies at endpoints
- Vertex Pipelines to automate, monitor, and govern your RL systems by orchestrating your workflow in a serverless manner, and storing your workflow's artifacts using Vertex ML Metadata.
Step-by-step RL demo
This step-by-step demo showcases how to build the MovieLens recommendation system using TF-Agents and Vertex AI services, primarily custom training and hyperparameter tuning, custom prediction and endpoint deployment. This demo is available on Github, including a step-by-step notebook and Python modules.
The demo first walks through the TF-Agents on-policy (which is covered in detail in the demo) training code of the RL system locally in the notebook environment. It then shows how to integrate the TF-Agents implementation with Vertex AI services: It packages the training (and hyperparameter tuning) logic in a custom training/hyperparameter tuning container and builds the container with Cloud Build. With this container, it executes remote training and hyperparameter tuning jobs using Vertex AI. It also illustrates how to utilize the best hyperparameters learned from the hyperparameter tuning job during training, as an optimization.
The demo also defines the prediction logic, which takes in observations (user vectors) from prediction requests and outputs predicted actions (movie items to recommend), in a custom prediction container and builds the container with Cloud Build. It deploys the trained policy to a Vertex AI endpoint, and uses the prediction container as the serving container for the policy at the Vertex AI endpoint.
End-to-end workflow with a closed feedback loop: Pipeline demo
Pipeline architecture
Building upon our RL demo, we’ll now show you how to scale this workflow using Vertex Pipelines. This pipeline demo showcases how to build an end-to-end MLOps pipeline for the MovieLens recommendation system, using Kubeflow Pipelines (KFP) for authoring and Vertex Pipelines for orchestration.
Highlights of this end-to-end demo include:
- RL-specific implementation that handles RL modules, training logic and trained policies as opposed to models
- Simulated training data, simulated environment for predictions and re-training
- Closing of the feedback loop from prediction results back to training
- Customizable and reproducible KFP components
An illustration of the pipeline structure is shown in the figure below.
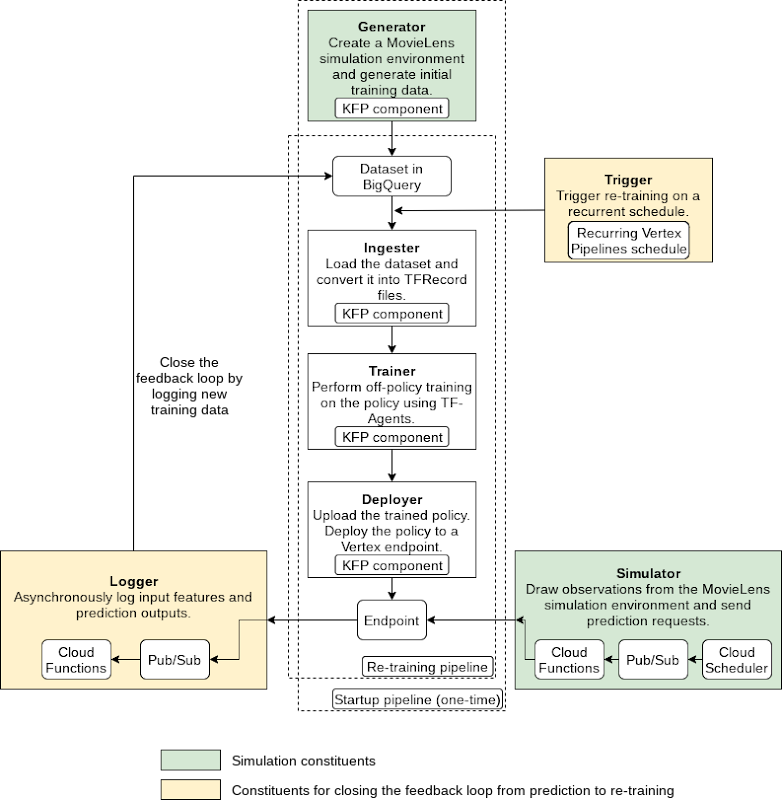
The pipeline consists of the following components:
- Generator: to generate MovieLens simulation data as the initial training dataset using a random data-collecting policy, and store in BigQuery [executed only once]
- Ingester: to ingest training data in BigQuery and output TFRecord files
- Trainer: to perform off-policy (which is covered in detail in the demo) training using the training dataset and output a trained RL policy
- Deployer: to upload the trained policy, create a Vertex AI endpoint and deploy the trained policy to the endpoint
In addition to the above pipeline, there are three components which utilize other GCP services (Cloud Functions, Cloud Scheduler, Pub/Sub):
- Simulator: to send recurring simulated MovieLens prediction requests to the endpoint
- Logger: to asynchronously log prediction inputs and results as new training data back to BigQuery, per prediction requests
- Trigger: to recurrently execute re-training on new training data
Pipeline construction with Kubeflow Pipelines (KFP)
You can author the pipeline using the individual components mentioned above:
The execution graph of the pipeline looks like the following:
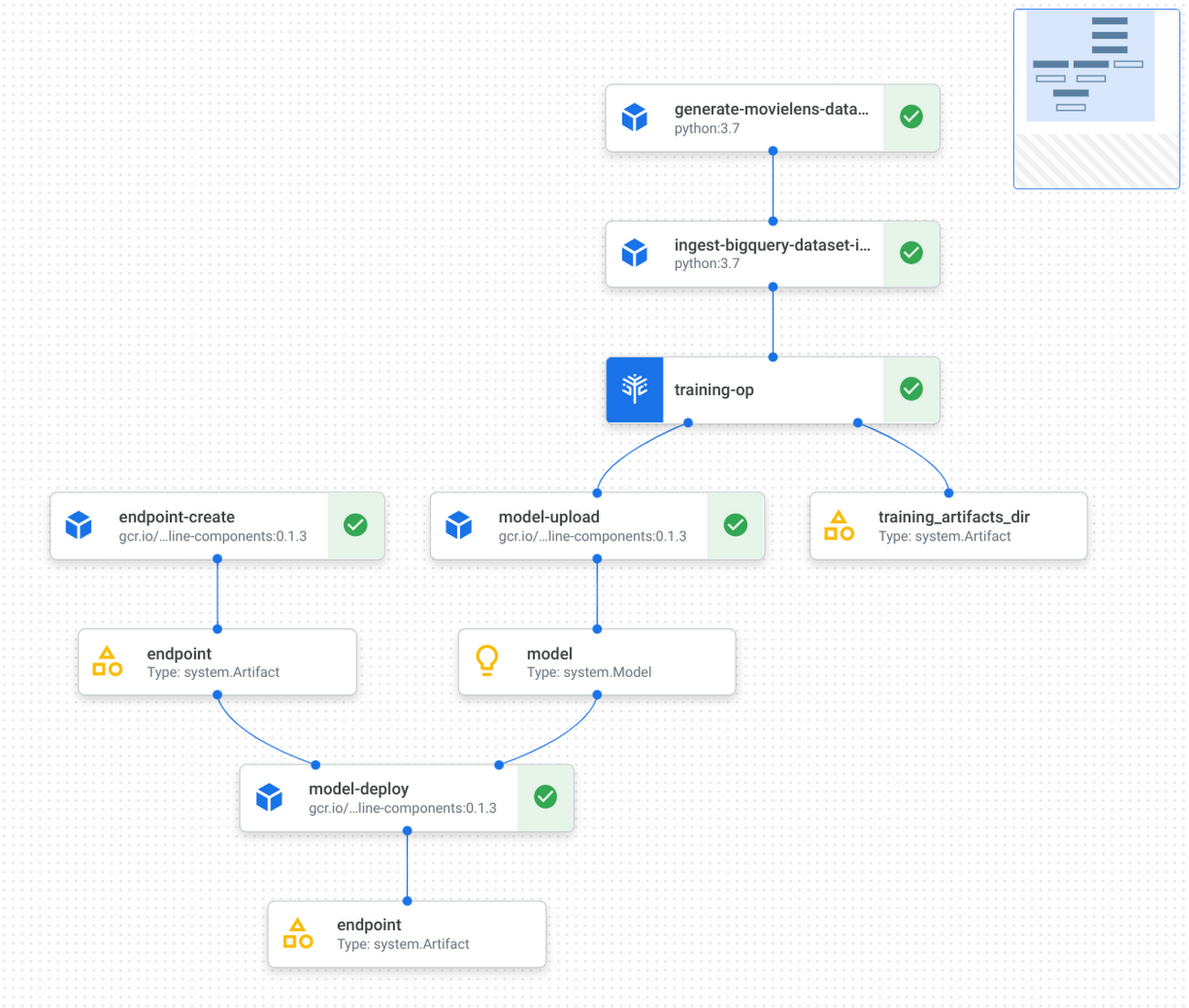
Refer to the GitHub repo for detailed instructions on how to implement and test KFP components, and how to run the pipeline with Vertex Pipelines.
Applying this demo to your own RL projects and production
You can replace the MovieLens simulation environment with a real-world environment where RL quantities like observations, actions and rewards capture relevant aspects of said real-world environment. Based on whether you can interact with the real world in real-time, you may choose either on-policy (showcased by the step-by-step demo) or off-policy (showcased by the pipeline demo) training and evaluation.
If you were to implement a real-world recommendation system, here’s what you’d do:
You would represent users as some user vectors. The individual entries in the user vectors may have actual meanings like age. Alternatively, they may be generated through a neural network as user embeddings. Similarly, you would define what an action is and what actions are possible, likely all items available on your platform; you would also define what the reward is, such as whether the user has tried the item, how long/much the user has spent on the item, user rating of the item, and so on. Again, you have the flexibility to decide on representations for framing the problem that maximize performance. During training or data pre-collection, you may randomly sample users (and build the corresponding user vectors) from the real world, use those vectors as observations to query some policy for items to recommend, and then apply that recommendation to users and obtain their feedback as rewards.
This RL demo can also be extended to ML applications other than recommendation system. For instance, if your use case is to build an image classification system, then you can frame an environment, where observations are the image pixels or embeddings, actions are the predicted classes, and rewards are feedback on the predictions’ correctness.
Conclusion
Congratulations! You have learned how to build reinforcement learning solutions using Vertex AI in a fully managed, modularized and reproducible way. There is so much you can achieve with RL, and you now have many Vertex AI as well as Google Cloud services in your toolbox to support you in your RL endeavors, be it production systems, research or cool personal projects.
Additional resources
- [Recap] step-by-step demo link: GitHub link
- [Recap] end-to-end pipeline demo: GitHub link
- TF-Agents tutorial on bandits: Introduction to Multi-Armed Bandits
- Vertex Pipelines tutorial: Intro to Vertex Pipelines




